elasticsearch集群擴容和容災
- 2019 年 10 月 3 日
- 筆記
elasticsearch專欄:https://www.cnblogs.com/hello-shf/category/1550315.html
一、集群健康
Elasticsearch 的集群監控資訊中包含了許多的統計數據,其中最為重要的一項就是集群健康,它在 status 欄位中展示為 green 、 yellow 或者 red。
在kibana中執行:GET /_cat/health?v
1 epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 2 1568794410 08:13:30 my-application yellow 1 1 47 47 0 0 40 0 - 54.0%
其中我們可以看到當前我本地的集群健康狀態是yellow ,但這裡問題來了,集群的健康狀況是如何進行判斷的呢?
green(很健康) 所有的主分片和副本分片都正常運行。 yellow(亞健康) 所有的主分片都正常運行,但不是所有的副本分片都正常運行。 red(不健康) 有主分片沒能正常運行。
注意:
我本地只配置了一個單節點的elasticsearch,因為primary shard和replica shard是不能分配到一個節點上的所以,在我本地的elasticsearch中是不存在replica shard的,所以健康狀況為yellow。
二、shard和replica
為了將數據添加到Elasticsearch,我們需要索引(index)——一個存儲關聯數據的地方。實際 上,索引只是一個用來指向一個或多個分片(shards)的“邏輯命名空間(logical namespace)”. 一個分片(shard)是一個最小級別“工作單元(worker unit)”,它只是保存了索引中所有數據的一 部分。道分片就是一個Lucene實例,並且它本身就是一個完整的搜索引擎。我們的文檔存儲在分片中,並且在分片中被索引,但是我們的應用程式不會直接與它們通訊,取而代之的是,直接與索引通訊。 分片是Elasticsearch在集群中分發數據的關鍵。把分片想像成數據的容器。文檔存儲在分片中,然後分片分配到你集群中的節點上。當你的集群擴容或縮小,Elasticsearch將會自動在你的節點間遷移分片,以使集群保持平衡。 分片可以是主分片(primary shard)或者是複製分片(replica shard)。
你索引中的每個文檔屬於一個單獨的主分片,所以主分片的數量決定了索引最多能存儲多少數據。 理論上主分片能存儲的數據大小是沒有限制的,限制取決於你實際的使用情況。分片的最大容量完全取決於你的使用狀況:硬體存儲的大小、文檔的大小和複雜度、如何索引 和查詢你的文檔,以及你期望的響應時間。
複製分片只是主分片的一個副本,它可以防止硬體故障導致的數據丟失,同時可以提供讀請 求,比如搜索或者從別的shard取迴文檔。 當索引創建完成的時候,主分片的數量就固定了,但是複製分片的數量可以隨時調整。 讓我們在集群中唯一一個空節點上創建一個叫做 blogs 的索引。默認情況下,一個索引被分配5個主分片,一個主分片默認只有一個複製分片。
重點: shard分為兩種: 1,primary shard --- 主分片 2,replica shard --- 複製分片(或者稱為備份分片或者副本分片)
需要注意的是,在業界有一個約定俗稱的東西,單說一個單詞shard一般指的是primary shard,而單說一個單詞replica就是指的replica shard。
另外一個需要注意的是replica shard是相對於索引而言的,如果說當前index有一個複製分片,那麼相對於主分片來說就是每一個主分片都有一個複製分片,即如果有5個主分片就有5個複製分片,並且主分片和複製分片之間是一一對應的關係。
很重要的一點:primary shard不能和replica shard在同一個節點上。重要的事情說三遍:
primary shard不能和replica shard在同一個節點上
primary shard不能和replica shard在同一個節點上
primary shard不能和replica shard在同一個節點上
所以es最小的高可用配置為兩台伺服器。
三、master節點、協調節點和節點對等特性
elasticsearch同大多數的分散式架構,也會進行主節點的選舉,elasticsearch選舉出來的主節點主要承擔一下工作:
1 集群層面的設置 2 集群內的節點維護 3 集群內的索引、映射(mapping)、分詞器的維護 4 集群內的分片維護
不同於hadoop、mysql等的主節點,elasticsearch的master將不會成為整個集群環境的流量入口,即其並不獨自承擔文檔級別的變更和搜索(curd),也就意味著當流量暴增,主節點的性能將不會成為整個集群環境的性能瓶頸。這就是elasticsearch的節點對等特性。
節點對等:
所謂的節點對等就是在集群中每個節點扮演的角色都是平等的,也就意味著每個節點都能成為集群的流量入口,當請求進入到某個節點,該節點就會暫時充當協調節點的角色,對請求進行路由和處理。這是一個區別於其他分散式中間件的很重要的特性。節點對等的特性讓elasticsearch具備了負載均衡的特性。在後面對document的寫入和搜索會詳細介紹該牛叉的特性。
協調節點:
通過上面的分析,我們可以得出一個結論,協調節點其實就是請求命中的那個節點。該節點將承擔當前請求的路由工作。
四、擴容
一般的擴容模式分為兩種,一種是水平擴容,一種是垂直擴容。
4.1、垂直擴容:
所謂的垂直擴容就是升級伺服器,買性能更好的,更貴的然後替換原來的伺服器,這種擴容方式不推薦使用。因為單台伺服器的性能總是有瓶頸的。
4.2、水平擴容:
水平擴容也稱為橫向擴展,很簡單就是增加伺服器的數量,這種擴容方式可持續性強,將眾多普通伺服器組織到一起就能形成強大的計算能力。水平擴容 VS 垂直擴容用一句俗語來說再合適不過了:三個臭皮匠賽過諸葛亮。
4.3、垂直擴容的過程分析
上面我們詳細介紹了分片,master和協調節點,接下來我們通過畫圖的方式一步步帶大家看看橫向擴容的過程。
首先呢需要鋪墊一點關於自定義索引shard數量的操作
1 PUT /student 2 { 3 "settings" : { 4 "number_of_shards" : 3, 5 "number_of_replicas" : 1 6 } 7 }
以上程式碼意味著我們創建的索引student將會分配三個primary shard和三個replica shard(至於上面為什麼是1,那是相對於索引來說的,前面解釋過)。
4.3.1、一台伺服器
當我們只有一台伺服器的時候,shard是怎麼分布的呢?
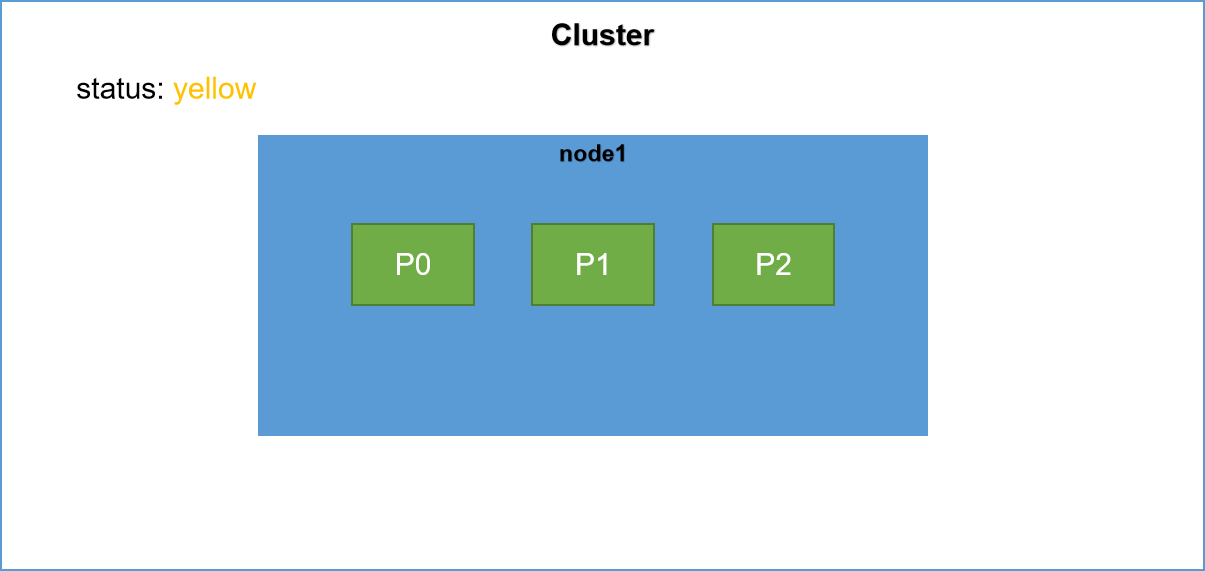
註:P代表primary shard, R代表replica shard。明確一點在後面的描述中默認一個es節點在一台伺服器上。
分析一下上面的過程,首先需要明確的兩點:
1,primary shard和replica shard不能再同一台機器上,因為replica和shard在同一個節點上就起不到副本的作用了。
2,當集群中只有一個節點的時候,node1節點將成為主節點。它將臨時管理集群級別的一些變更,例如新建或 刪除索引、增加或移除節點等。
明確了上面兩點也就很簡單了,因為集群中只有一個節點,該節點將直接被選舉為master節點。其次我們為student索引分配了三個shard,由於只有一個節點,所以三個primary shard都被分配到該節點,replica shard將不會被分配。此時集群的健康狀況為yellow。
4.3.2、增加一台伺服器
接著上面繼續,我們增加一台伺服器,此時shard是如何分配的呢?
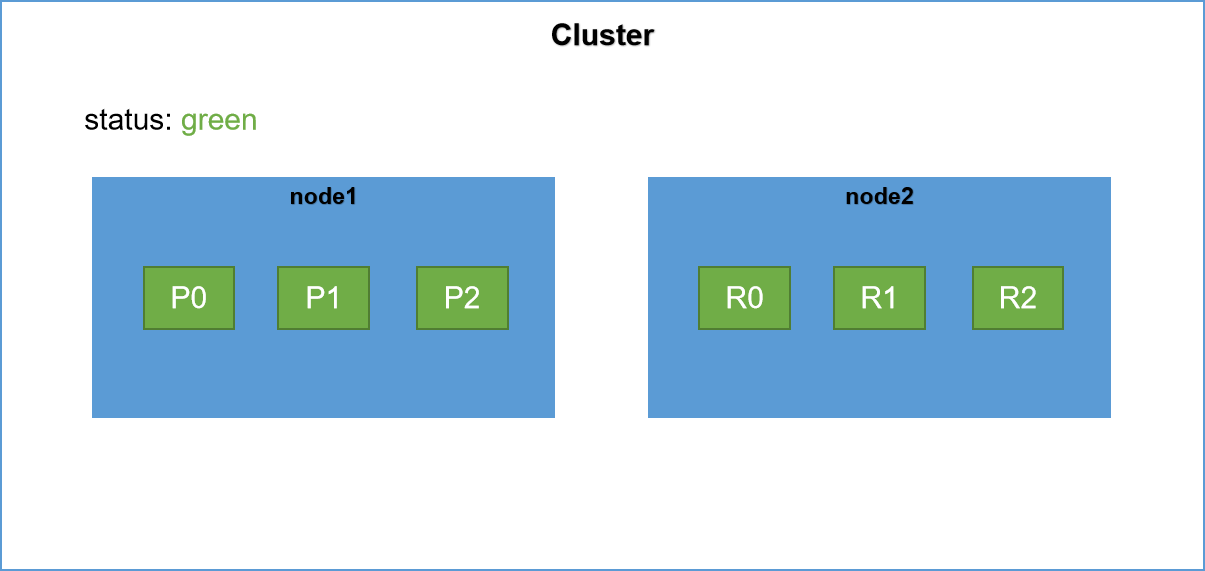
Rebalance(再平衡),當集群中節點數量發生變化時,將會觸發es集群的rebalance,即重新分配shard。Rebalance的原則就是盡量使shard在節點中分布均勻,達到負載均衡的目的。
原先node1節點上有p0、p1、p2三個primary shard,另外三個replica shard還未分配,當集群新增節點node2,觸發集群的Rebalance,另外三個replica shard將被分配到node2上,即如上圖所示。
此時集群中所有的primary shard和replica shard都是active(可用)狀態的所以此時集群的健康狀況為yellow。可見es集群的最小高可用配置就是兩太伺服器。
4.3.3、繼續新增伺服器
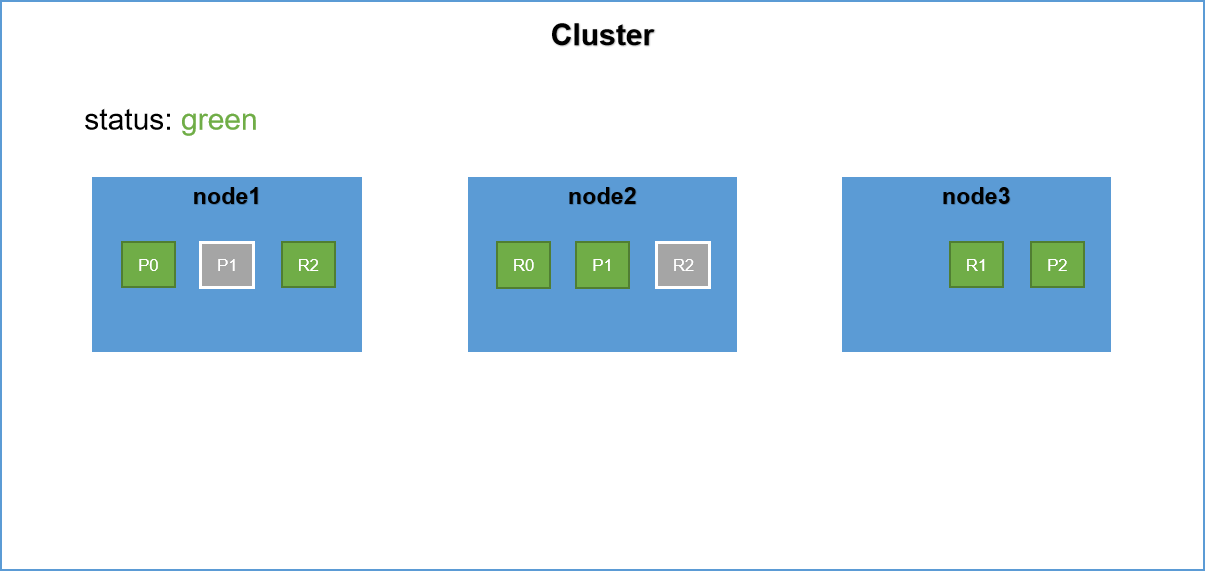
繼續新增伺服器,集群將再次進行Rebalance,在primary shard和replica shard不能分配到一個節點上的原則,這次rebalance同樣本著使shard均勻分布的原則,將會從node1上將P1,P2兩個primary shard分配到node1,node2上面,然後將node2在primary shard和replica shard不能分配到一台機器上的原則上將另外兩個replica shard分配到node1和node2上面。
注意:具體的分配方式上,可能是P0在node2上面也有可能在node3上面,但是只要本著Rebalance的原則將shard均勻分布達到負載均衡即可。
五、集群容災
分散式的集群是一定要具備容災能力的,對於es集群同樣如此,那es集群是如何進行容災的呢?接下來聽我娓娓道來。
在前文我們詳細講解了primary shard和replica shard。replica shard作為primary shard的副本當集群中的節點發生故障,replica shard將被提升為primary shard。具體的演示如下
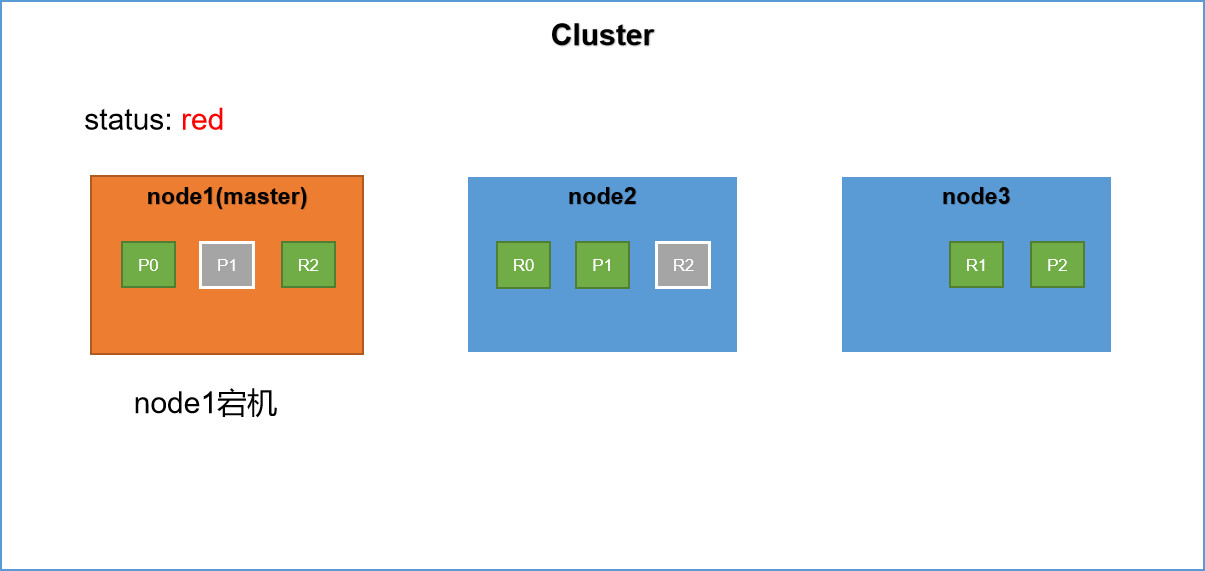
集群中有三台伺服器,其中node1節點為master節點,primary shard 和 replica shard的分布如上圖所示。此時假設node1發生宕機,也就是master節點發生宕機。此時集群的健康狀態為red,為什麼呢?因為不是所有的primary shard都是active的。
具體的容災過程如下:
1,重新選舉master節點,當es集群中的master節點發生故障,此時es集群將再次進行master的選舉,選舉出一個新的master節點。假設此時新的主節點為node2。
2,node2被選舉為新的master節點,node2將作為master行駛其分片分配的任務。
3,replica shard升級,此時master節點會尋找node1節點上的P0分片的replica shard,發現其副本在node2節點上,然後將R0提升為primary shard。這個升級過程是瞬間完成的,就像按下一個開關一樣。因為每一個shard其實都是lucene的實例。此時集群如下所示,集群的健康狀態為yellow,因為不是每一個replica shard都是active的。

容災的過程如上所示,其實這也是一般分散式中間件容災備份的一般手段。如果你很了解kafka的話,這個就很容易理解了。
參考文獻:
《elasticsearch-權威指南》
如有錯誤的地方還請留言指正。
原創不易,轉載請註明原文地址:https://www.cnblogs.com/hello-shf/p/11543468.html
