『心善淵』Selenium3.0基礎 — 5、XPath路徑表達式詳細介紹
- 2021 年 6 月 24 日
- 筆記
- 測試基礎 - Selenium測試框架
1、XPath介紹
- XPath (
XML Path Language) 是一門在 XML 文檔中查找資訊的語言。XPath 用於在 XML 文檔中通過元素和屬性進行導航。 - XPath 包含一個標準函數庫:XPath 含有超過 100 個內建的函數。這些函數用於字元串值、數值、日期和時間比較、節點和 QName 處理、序列處理、邏輯值等等。
- XPath 路徑表達式:XPath 使用路徑表達式來選取 XML 文檔中的節點或者節點集。這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似。
- XPath 是一個 W3C 標準。
W3School官方文檔://www.w3school.com.cn/xpath/index.asp。 - HTML是標準的XML,所以HTML也可以使用XPath。
2、什麼是XML
(1)XML介紹:
XML是指擴展標記語言,是標準通用標記語言的一個子集;與HTML類似,但它並非HTML的替代品,它們為不同的目的而設計。
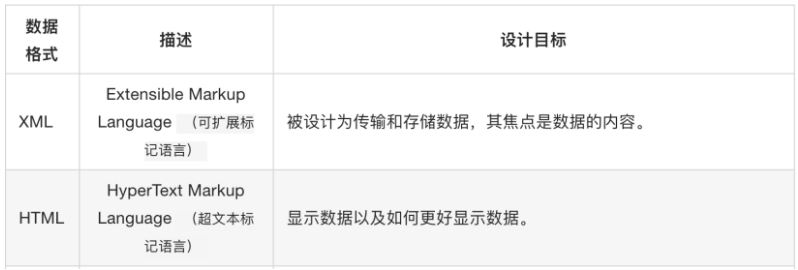
HTML被設計用來顯示數據,其焦點是數據的外觀。XML被設計為傳輸和存儲數據,其焦點是數據的內容。
總結:
- XML 指可擴展標記語言(
EXtensible Markup Language)。 - XML 是一種標記語言,很類似 HTML 。
- XML 的設計宗旨是傳輸數據,而非顯示數據。
(2)XML實例:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
(3)XML使用:
如上所示,進行下面的選取:
# 1.選取屬於 bookstore 子元素的第一個 book 元素。
/bookstore/book[1]
# 2.選取屬於 bookstore 子元素的最後一個 book 元素。
/bookstore/book[last()]
# 3.選取屬於 bookstore 子元素的倒數第二個 book 元素。
/bookstore/book[last()-1]
3、XML與HTML對比
如下圖所示:
4、為什麼使用XPath定位頁面中的元素
- 當元素沒有
id,name,class屬性該如何定位? - 當元素
id,name,class屬性為動態時如何定位?也就是相同的元素,每次載入頁面時,該元素id屬性的值是不同的。
這個時候就需要使用XPath,css_selector來定位。
這兩種方式可以解決90%左右的元素定位。
5、XPath中節點之間的關係
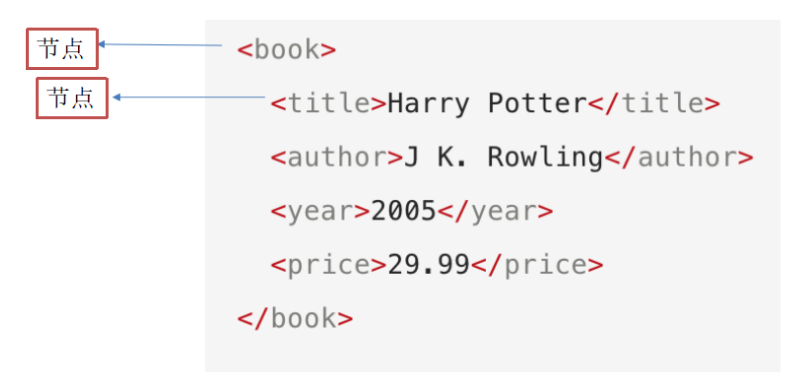
(1)節點的概念
每個XML/HTML的標籤我們都稱之為節點。
如下圖所示:
(2)節點之間的關係類型
如下圖所示:

1)父節點(Parent)
在上圖中:book元素是 title、author、year 以及 price 元素的父節點。
2)子節點(Children)
每個元素節點可有零個、一個或多個子節點。
在上圖中:title、author、year 以及 price 元素都是 book元素的子節點。
3)同胞(Sibling)
擁有相同的父的節點的元素。
在上圖中:title、author、year 以及 price 元素都是同胞節點。
4)先輩(Ancestor)
某個節點的父節點、父的父節點,以此類推。
在上圖中:title 元素的先輩是 book 元素和 bookstore 元素。
5)後代(Descendant)
某個節點的子節點,子的子節點,以此類推。
在上圖中:bookstore 的後代是 book、title、author、year 以及 price 元素。
6)基本值(或稱原子值,Atomic value)
基本值是無父或無子的節點。
即:基本值是以上節點的文本內容或者屬性值。
在上圖中,基本值的例子:
J K. Rowling
"en"
6、XPath路徑表達式語法
XPath 使用路徑表達式來選取 XML 文檔中的節點或者節點集,這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似。
示例程式碼:
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
(1)基本定位語法:
XPath 使用路徑表達式在 XML 文檔中選取節點。節點是通過沿著路徑或者 step 來選取的。
下面列出了最常用的路徑表達式:
| 表達式 | 描述 |
|---|---|
nodename |
選取此節點的所有子節點。 |
/ |
從根節點選取。 |
// |
從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置。 |
. |
選取當前節點。 |
.. |
選取當前節點的父節點。 |
@ |
選取屬性。 |
(2)實例:
| 路徑表達式 | 結果 |
|---|---|
bookstore |
選取 bookstore 元素的所有子節點。 |
/bookstore |
選取根元素 bookstore。注釋:假如路徑起始於正斜杠( / ),則此路徑始終代表到某元素的絕對路徑! |
bookstore/book |
選取屬於 bookstore 的子元素的所有 book 元素。 |
//book |
選取所有 book 子元素,而不管它們在文檔中的位置。 |
bookstore//book |
選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore 之下的什麼位置。 |
//@lang |
選取名為 lang 的所有屬性。 |
(3)路徑表達式總結:
- 絕對路徑(一般不用)
/開頭表示,如:# 查找帳號A輸入框路徑 /html/body/form/div/fieldset/p/input - 相對路徑
//開頭表示 ,如:# 標籤名[@屬性名="屬性值"](總結就是:標籤+屬性定位) # 例如: //input[@type="textA"]
注意:我們在適用XPath定位頁面中元素的時候,很少使用絕對路徑。因為有時候使用絕對路徑,我們的XPath路徑表達式會很長,其中只要有一個標籤有變動,這個定位就會失效,所以在絕大多數的時候,都直接使用相對路徑來定位元素。