Spark比MR快是因為在記憶體中計算?錯!
- 2019 年 10 月 3 日
- 筆記
MapReduce 就像一台又慢又穩的老爺車,雖然距離 MapReduce 面市到現在已經過去了十幾年的時間,但它始終沒有被淘汰,任由大數據技術日新月異、蓬蓬勃勃、花里胡哨地發展,這個生態圈始終有它的一席之地。
不過 Spark 的到來確實給了 MapReduce 不小的衝擊,它比 MapReduce 理論上要快兩個數量級,所以近幾年不斷有人討論 Spark 是否可以完全替代 MapReduce ,但是為什麼說是不斷有人討論呢?因為這些年 Spark 始終是無法完全取代 MapReduce 。
我們今天關注的問題是Spark為什麼比 MapReduce 快?如果沒有看文章的標題,你是不是會脫口而出:
「因為 Spark 是在記憶體中計算,而 MapReduce 是基於磁碟。」
這話乍一聽沒毛病,但是作為一個對技術很嚴謹的人,這讓我忍不住想杠一下,
「那麼 MapReduce 計算的時候不需要把數據載入到記憶體,在記憶體中計算嗎?」
其實要對數據做計算,必然得把數據載入到記憶體, MapReduce 也不例外,Spark只是在計算模型和調度上做了更多的優化,不需要過多地和磁碟交互。
說到這裡不得不提的就是 Spark 的 DAG(有向無環圖),這個 DAG 就相當於改進版的 MapReduce,它可以說是由多個 MapReduce 組成,當數據處理流程中存在多個map和多個Reduce操作混合執行時,MapReduce只能提交多個Job執行,而Spark可以只提交一次,在一個任務中完成。
這就導致了 MapReduce 會存在多次耗時的資源申請和資源釋放,另外 MapReduce 每次shuffle 操作後,必須寫到磁碟,而 Spark 在 shuffle 後不一定落盤,如果Shuffle後的數據是需要反覆用到的,則可以cache到記憶體中,方便迭代時使用,所以Spark對於需要對數據進行反覆迭代的操作(比如跑機器學習演算法或者有中間結果的複雜計算等)是非常友好的。
這裡還有一個誤區,很多人會認為 Spark 在計算時的所有過程都是在記憶體中完成的不用寫磁碟,但是實際上不是這樣的,在 shuffle 過程中 Spark 同樣需要寫磁碟,研究過 Sorted-Based Shuffle 的同學對這個寫盤操作一定不陌生,如下圖。
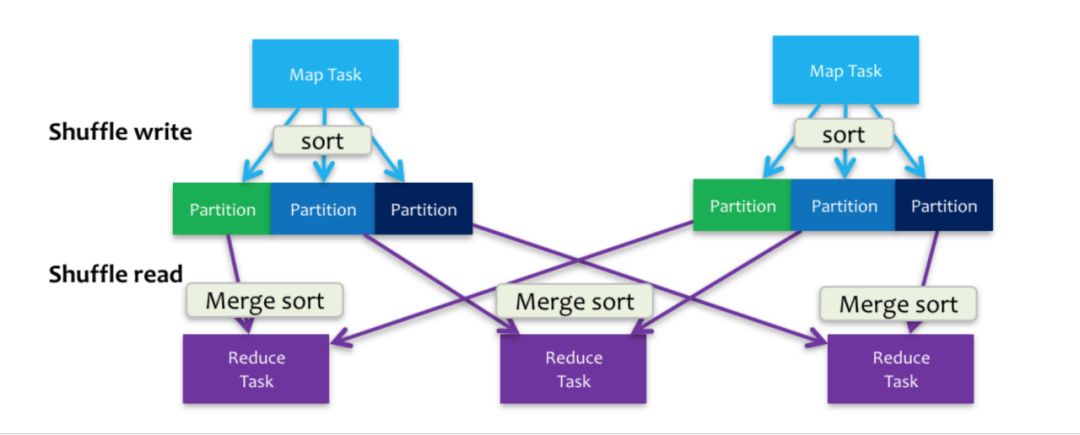
簡單地說下,shuffle分成write和read兩個階段,write的過程不僅會寫需要發向下一個Stage的數據到磁碟,還需要寫一份數據的Index記錄下游每個分區獲取的數據範圍。這裡就不詳細說了,有興趣的同學可以去研究下。

另外,剛才提到了Spark儘管比MapReduce快兩個數量級但是它始終沒有被淘汰,這是因為它在每個階段都落盤,雖然慢但是可以保證計算過程的穩定性,不會像Spark一樣,一旦中間結果太大,記憶體裝不下整個計算任務就崩了,這對於不講究時效性的後台任務來說無疑是增加了維護成本,所以現在構建數據倉庫的主要SQL工具還是Hive(Hive的底層是MapReduce),你見過用SparkSQL來跑數據量大的數倉任務的嗎?
看完這篇,希望下次有人問你 Spark 為什麼比 MapReduce 快的時候不要再說 Spark 在記憶體中計算了。
覺得有價值請關注 ▼

