管中窺豹-ssh鏈接過多的問題分析及復盤
緣起
某一天,產品側同事聯繫過來,回饋話單傳輸程式報錯,現象如下:
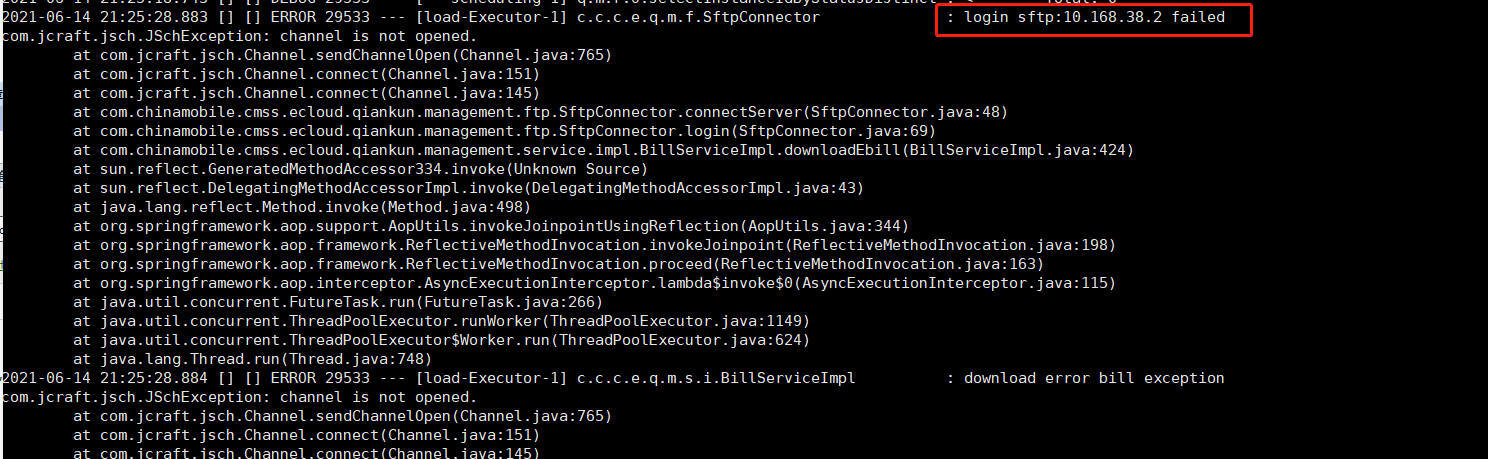
實際上,該節點僅提供了一個sftp服務,供產品側傳輸話單過來進行臨時存儲,由計費部門取走而已。
分析
於是找運維同事上伺服器看了下情況,發現有以下幾個問題:
-
ssh進程過高(由於前期給各個部門分配的sftp帳號不同,正好可以以帳號名辨別來源)

-
根據以上資訊,檢查了TCP鏈接狀態,發現絕大多數都是ESTABLISHED連接:
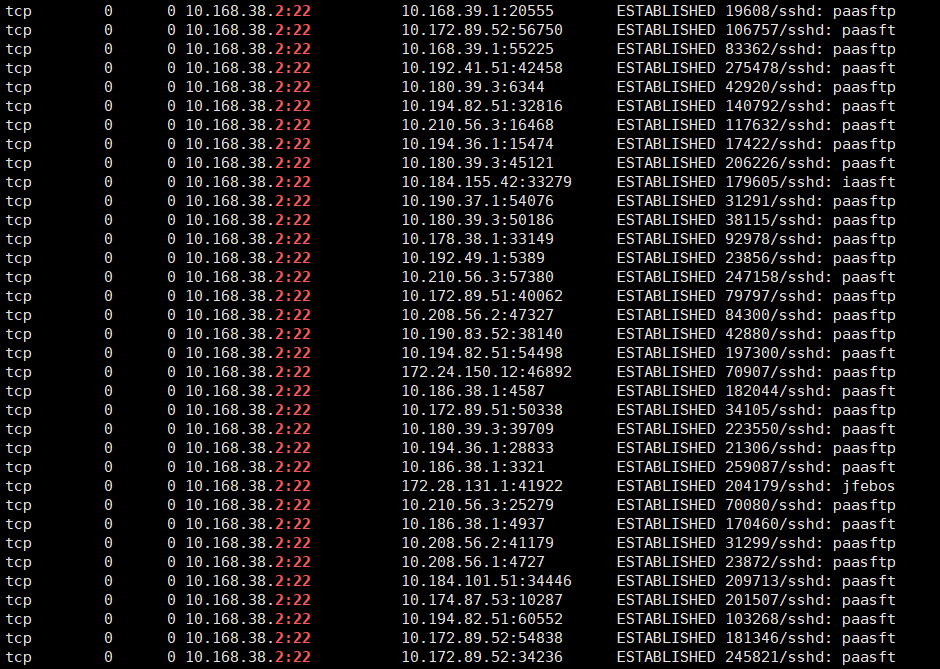
-
於是統計了一下TCP鏈接來源


#/bin/bash
for i in `netstat -ant | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort |uniq`
do
count=`netstat -ant | grep ESTABLISHED | grep $i|wc -l`
if [[ ${count} -ge 30 ]] ;then
echo "$i的連接數是$count"
#else
# continue
fi
done
-
發現鏈接主要集中於部分IP:
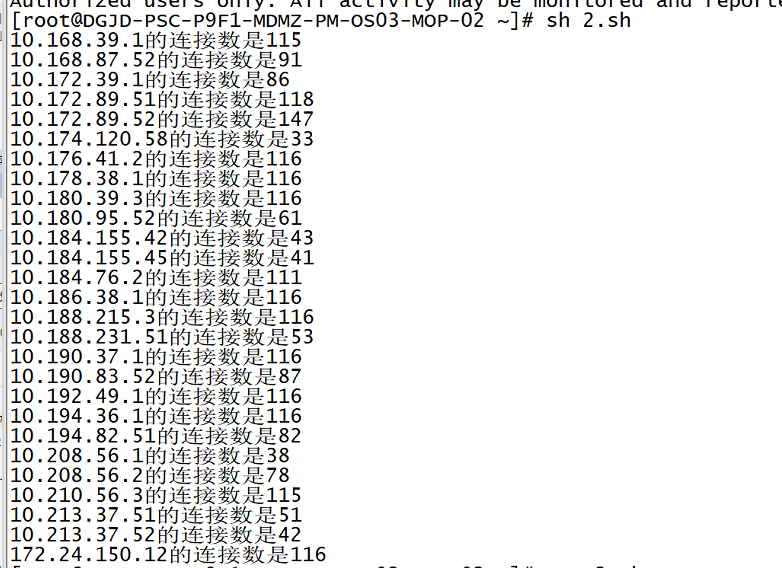
-
由於鏈接持續上漲,結合業務場景推測為ssh連接未正常釋放的問題引發。

拓展
首先,鏈接在多天的時間內積攢到幾萬,並且不進行自動釋放,幾乎可以斷定是由於客戶端未釋放,原因如下:
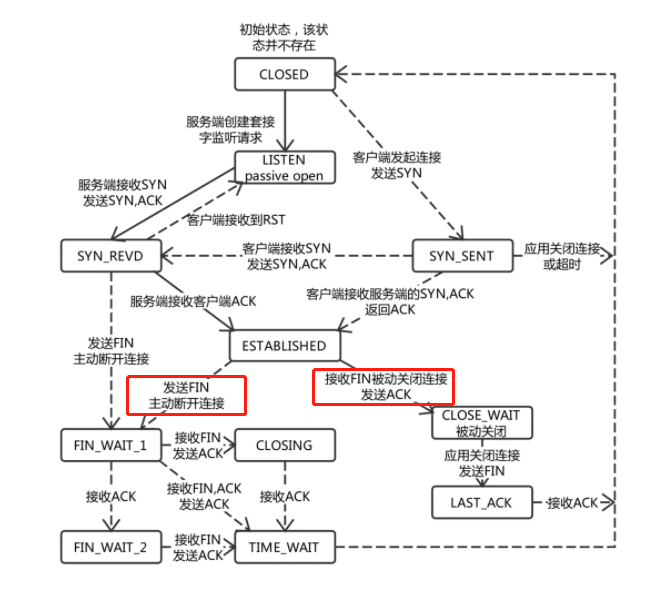
根據TCP請求的狀態機,ESTABLISHED狀態的鏈接,只有在發送FIN,或者收到FIN的時候,才會主動斷開TCP鏈接(也就是意味著沒有人發FIN);
而假設一種場景,客戶端發送了FIN,但服務端因為網路或者某種原因未收到的話,TCP keepalive機制會進行多次探測,將其斷開(也就是意味著keepalive機制一直存在響應)。
補充:下一篇將對TCP請求的keepalive機製做一個介紹。
根因
於是組織產品側進行排查,最終找到原因:
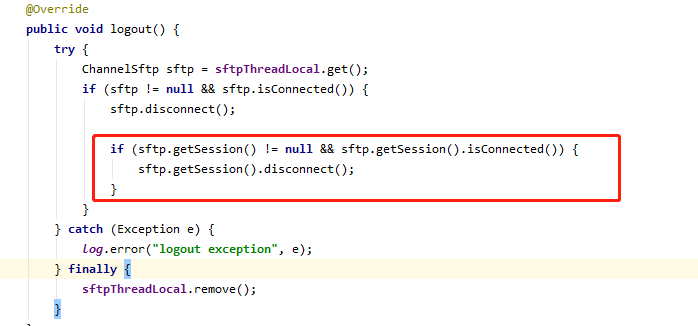
原程式碼中,在退出sftp任務之後,只關閉了channel,而未關閉對應的session(缺少紅框內容)
根據官方example://www.jcraft.com/jsch/examples/Sftp.java.html ,最終關閉的應該是session,這樣就不會有殘留了。

復盤
至此問題解決,那麼需要復盤分析了:
前期是否有做過sshd服務的性能限制配置?
經了解,前期為了限制產品側的鏈接個數,已經有過配置對應的限制配置:

這裡解釋下這兩個配置:
MaxSessions 1000 限制最大會話個數;
MaxStartups 1000:30:1200 會話個數達到1000之後的鏈接,有30%幾率失敗;會話個數達到1200後,全部失敗;
可是為何實際生產中連接數達到了幾十萬都沒有釋放呢?
經過一番調查最終找到原因:每次登錄會在ssh服務新建一個連接,每次程式碼層面進行sftp操作,會生成一個新的會話/session。
所以這個maxsession,實際上限制的是每一個連接能新建出多少個會話的個數。
對應到各種ssh工具上,有一個複製會話,有一個複製渠道(channel),對應的即是這兩個概念。
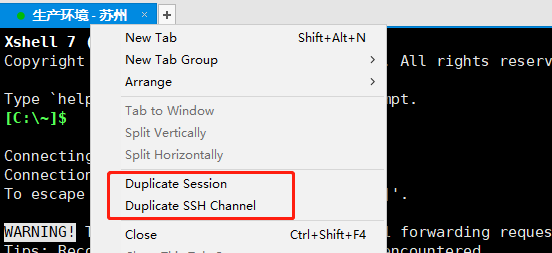
因此配置是存在的,只是沒有起到預期的效果。
那麼應該如何正確的配置呢?
實際上,在ulimit裡面是可以配置針對用戶級別的登錄連接個數限制的:
/etc/security/limits.conf 文件實際是 Linux PAM(插入式認證模組,Pluggable Authentication Modules)中 pam_limits.so 的配置文件,而且只針對於單個會話。
# /etc/security/limits.conf
#
#This file sets the resource limits for the users logged in via PAM.
該文件為通過PAM登錄的用戶設置資源限制。
#It does not affect resource limits of the system services.
#它不影響系統服務的資源限制。
#Also note that configuration files in /etc/security/limits.d directory,
#which are read in alphabetical order, override the settings in this
#file in case the domain is the same or more specific.
請注意/etc/security/limits.d下按照字母順序排列的配置文件會覆蓋 /etc/security/limits.conf中的
domain相同的的配置
#That means for example that setting a limit for wildcard domain here
#can be overriden with a wildcard setting in a config file in the
#subdirectory, but a user specific setting here can be overriden only
#with a user specific setting in the subdirectory.
這意味著,例如使用通配符的domain會被子目錄中相同的通配符配置所覆蓋,但是某一用戶的特定配置
只能被字母路中用戶的配置所覆蓋。其實就是某一用戶A如果在/etc/security/limits.conf有配置,當
/etc/security/limits.d子目錄下配置文件也有用戶A的配置時,那麼A中某些配置會被覆蓋。最終取的值是 /etc/security/limits.d 下的配置文件的配置。
#
#Each line describes a limit for a user in the form:
#每一行描述一個用戶配置,配置格式如下:
#<domain> <type> <item> <value>
#Where:
#<domain> can be:
# - a user name 一個用戶名
# - a group name, with @group syntax 用戶組格式為@GROUP_NAME
# - the wildcard *, for default entry 默認配置為*,代表所有用戶
# - the wildcard %, can be also used with %group syntax,
# for maxlogin limit
#
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
有soft,hard和-,soft指的是當前系統生效的設置值,軟限制也可以理解為警告值。
hard表名系統中所能設定的最大值。soft的限制不能比hard限制高,用-表名同時設置了soft和hard的值。
#<item> can be one of the following: <item>可以使以下選項中的一個
# - core - limits the core file size (KB) 限制內核文件的大小。
# - data - max data size (KB) 最大數據大小
# - fsize - maximum filesize (KB) 最大文件大小
# - memlock - max locked-in-memory address space (KB) 最大鎖定記憶體地址空間
# - nofile - max number of open file descriptors 最大打開的文件數(以文件描敘符,file descripter計數)
# - rss - max resident set size (KB) 最大持久設置大小
# - stack - max stack size (KB) 最大棧大小
# - cpu - max CPU time (MIN) 最多CPU佔用時間,單位為MIN分鐘
# - nproc - max number of processes 進程的最大數目
# - as - address space limit (KB) 地址空間限制
# - maxlogins - max number of logins for this user 此用戶允許登錄的最大數目
# - maxsyslogins - max number of logins on the system 系統最大同時在線用戶數
# - priority - the priority to run user process with 運行用戶進程的優先順序
# - locks - max number of file locks the user can hold 用戶可以持有的文件鎖的最大數量
# - sigpending - max number of pending signals
# - msgqueue - max memory used by POSIX message queues (bytes)
# - nice - max nice priority allowed to raise to values: [-20, 19] max nice優先順序允許提升到值
# - rtprio - max realtime pr iority
因此解就很明顯了,只要在limit中配置
testssh - maxlogins 1
即可,即時生效。
etc. 可以結合以上的maxsession,為某個用戶的連接/session數做一個更精確的控制。
前期是如何測試上線的呢?
此處不作展開,測試工作之重要不容質疑;然而也不能為了測試而測試,上一個小功能就需要把所有的測試run一遍;
個中文章攤開來說恐怕小小篇幅不足討論。
為何沒有提前發現呢?
前期曾做過監控告警的接入,但接入內容僅限於openssh進程消失,22埠丟失的場景;
很顯然,此處缺少進程數量,TCP鏈接數量,埠消耗數量監控;
一言以蔽之,也就是只有1/0監控,沒有health/err的監控;
同樣是以上的道理,既不能被動等待故障發現後做單個的補充,也不能因為過多細節監控項帶來整體運維的複雜度;
因此個人的理解是要加上通用指標的監控項,即監控指標需要反應系統級的普遍問題或者服務級的健康度,落實到ssh服務,建議如下:
進程數量監控(no),TCP鏈接數量監控(yes,百分比監控),埠消耗數量監控(yes,百分比),ssh服務響應時長撥測(yes,模擬ssh登錄及scp操作監控)

