《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》論文閱讀
- 2021 年 6 月 18 日
- 筆記
《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》論文閱讀
(i)問題背景:
工業界的推薦系統/廣告系統現在都會用embedding技術生成物品/用戶的向量。通俗點講就是build一個向量嵌入層,把帶有原始特徵的輸入向量轉換成一個低維度的dense向量表示。推薦系統的模型一般有向量嵌入層和深度模型層兩部分組成,向量嵌入層的輸出或作為深度學習模型的輸入。因此embedding過程的好壞會影響後面深度學習模型的學習和預測效果。物品的ID的向量表示稱為ID embedding。每個物品都有一個獨特的ID,因此ID embedding也是物品獨一無二的向量表示。所以學習到一個好的ID embedding對於提升整個系統的效果是非常關鍵的。
但是embedding技術是海量數據驅動的模型,數據量越大,學習到的向量表示效果才越好。並且學ID embedding的時候還會遇到冷啟動的問題,冷啟動的意思就是說一個新的物品進來,系統里沒有關於它的歷史資訊,對它了解很少,因此是個比較新的未知數據。並且它和環境交互的數據也很少,在冷啟動的情況下,現有的embedding技術要表示這種類型的物品ID embedding效果就會不好(這個時候學到的embedding叫Cold ID embedding),所以要想辦法解決這個問題。
分析問題:
|
Cold ID embedding面臨的問題 |
解決的方案 |
|
在deep model和cold ID embedding 之間存在一個gap。這裡gap的意思接近於bias。和「二八定律」有點類似,少量的熱門物品因為點擊關注率很高,往往佔據了整個訓練數據集的大部分數據樣本。因此模型學習embedding 向量的時候,會對熱門物品的學習效果好,能學到很多熱門物品的知識,但冷啟動的物品因為缺乏足夠量的data,訓練出來的向量就會效果不好。 |
1.提出MWUF(Meta Warm Up Framework)網路去warm up cold ID embedding,其實本質上就是做個映射,把cold start embedding 映射到warm up空間里. MWUF框架包含一種公共初始化ID embedding以及兩個meta networks。對於任何新來的物品,我們使用現有的物品embedding的均值來作為初始化。另外,Meta Scaling Network使用物品的特徵作為輸入,生成一個訂製化的拉伸函數將冷啟動ID embedding轉化為warmer embedding。 |
|
Cold ID embedding 會被噪音的interaction數據影響。Cold ID embedding本來就缺乏足夠的數據量來訓練和學習,如果這個時候用戶有一些錯誤的點擊,即使是很小的雜訊,也會對整個embedding的學習造成很嚴重的影響,bias會比較大。 |
Meta Shifting Network使用全局的交互過的用戶作為輸入,來生成一個偏移函數,來加強物品表示。 |
(ii)具體的演算法流程和思路:
1.MWUF架構主要做的兩點工作
第一個改變了初始化ID embedding的方法,原來對於新物品,都是採用隨機初始化(randomly initialize),現在改為由MWUF初始化ID embedding。其實這個方法的本質就是採用元學習(meta learning)的思想,通過公共初始化ID embedding來生成common initial ID embedding。元學習的思想和遷移學習有點類似,就是通過把模型對已知任務的訓練學到的經驗和知識能在新任務上應用。在本文裡面,就是通過對所有現有已知物品學習到的通識(common knowledge)應用於新物品的ID embedding初始化。啊再說的low一點,它就是把現有所有物品學到的ID embedding做個算數平均值作為新物品的初始化ID embedding。其實吹了這麼多····· 什麼元學習,高大上,冷啟動,warm up,common knowledge,就是把隨機賦值變成算個算數平均數再賦值而已··
第二個就是訓練了兩個meta network(Meta Shifting Network , Meta Scaling)並且加入了拉伸函數(Scaling Function)。本質上就是訓練了一個映射函數,然後把Cold ID embedding 映射成一個新的 ID embedding,他把這個叫做warmer embedding,咋一看很高大上,其實就是訓練了一個映射函數罷了··,相當於再加了一層預處理或者說數學變換。
2.模型框架
話不多說,上圖:
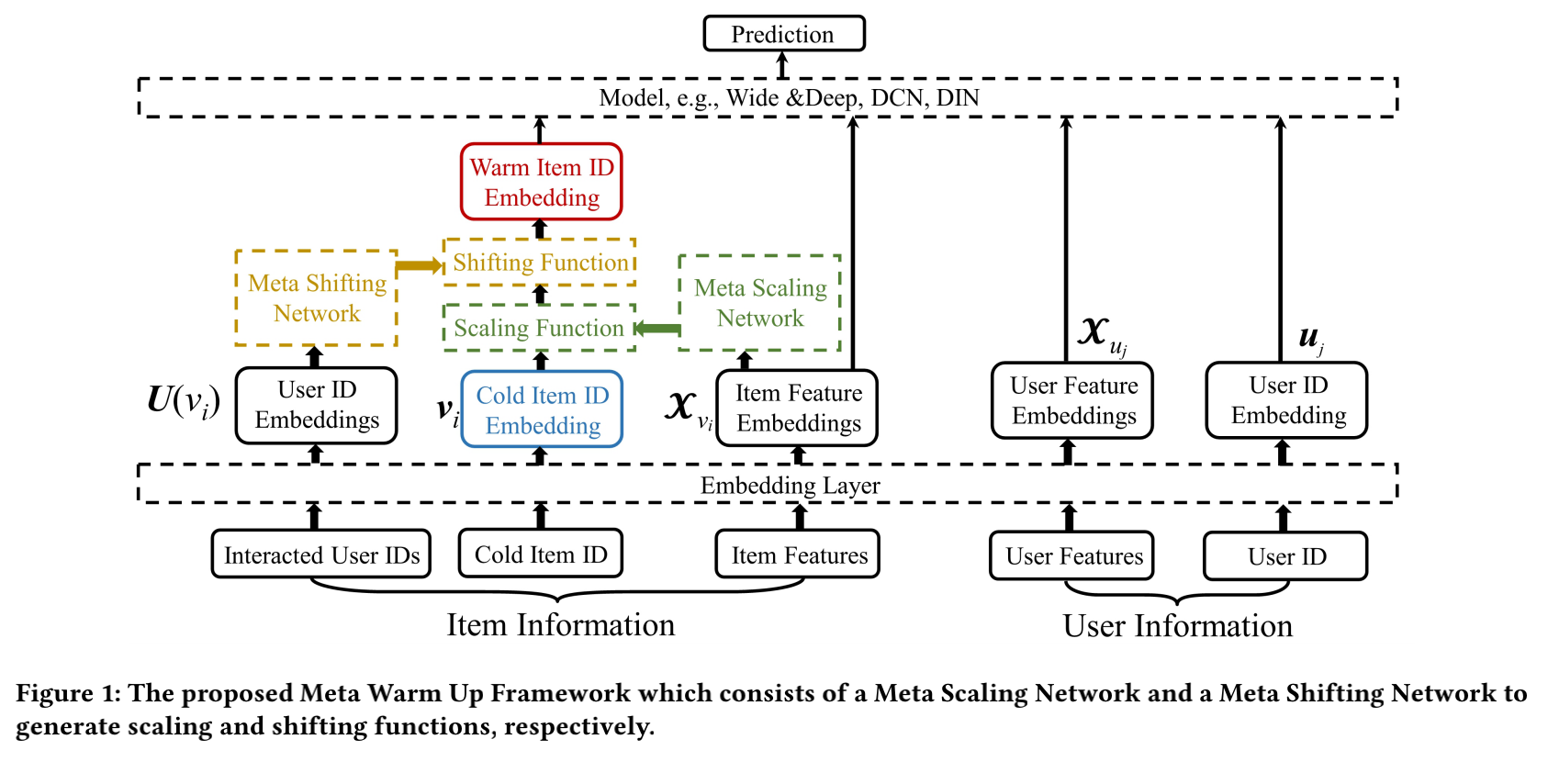
整體框架如上所示,深度模型的輸入包含4個部分,物品ID embedding,物品其他特徵embedding,用戶ID embedding,用戶其他特徵embedding:
Common Initial Embeddings: 提出了一種公共初始化embedding,使用現有的所有物品的ID embedding均值作為新加入的物品的初始化embedding。
Meta Scaling Network:希望將冷啟動物品ID embedding轉換到一個更好的特徵空間,能更好地擬合深度模型。對於每一個物品,冷啟動ID embedding和warm ID embedding之間存在一定的聯繫,認為相似的物品,這個聯繫也應該相似,因此Meta Scaling Network以物品的其他特徵做為輸入,輸出一個拉伸函數:
Meta Shifting Network: 所有交互過的用戶均值可以有效的減輕異常用戶的影響,因此Meta Shifting Network以交互過的用戶的均值表示作為輸入,輸出一個偏移函數
3.演算法流程:

這裡假設是一個推薦系統的二分類問題,比如CTR預估。每個樣本包括一個user,一個item和一個對應的label(0或者1).
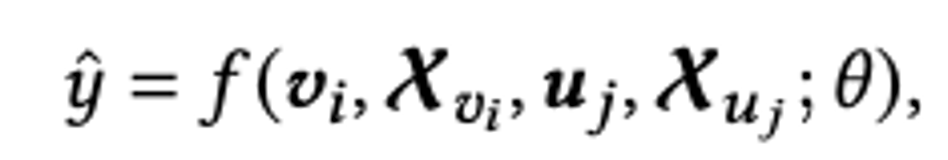
第i個物品的Item ID embedding 就是。各種item的feature做embedding 就是。同理可得第j個用戶的User ID embedding為。各種user的feature做embedding為 。y是模型預測的結果。θ是整個模型網路的參數集合。損失函數採用對數損失的形式,為:
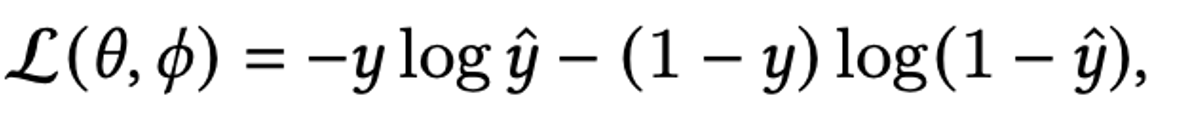
Φ 為embedding層的參數集合。
Overall Procedure:
整個演算法流程分兩步走,第一步先用已有的數據進行線上訓練,學習整個模型的參數集合和。第二步固定參數和迭代取樣訓練兩個meta network。生成Shift function和Scaling Function來解決gap和噪音的問題。
其實整個模型主要就是解決冷啟動裡面gap的問題,之後可能會魔改我們現有的model,引入本文的idea,看能不能改善線上模型的gap問題。如果之後確實用到,會接下來會把相關的coding部分也貼出來。

