Rethinking Training from Scratch for Object Detection
Rethinking Training from Scratch for Object Detection
一. 概述
正常訓練目標檢測的流程分為以下幾種:
- 在imagenet上進行預訓練,然後在特定數據集進行tune
- 直接在數據集上進行從頭訓練
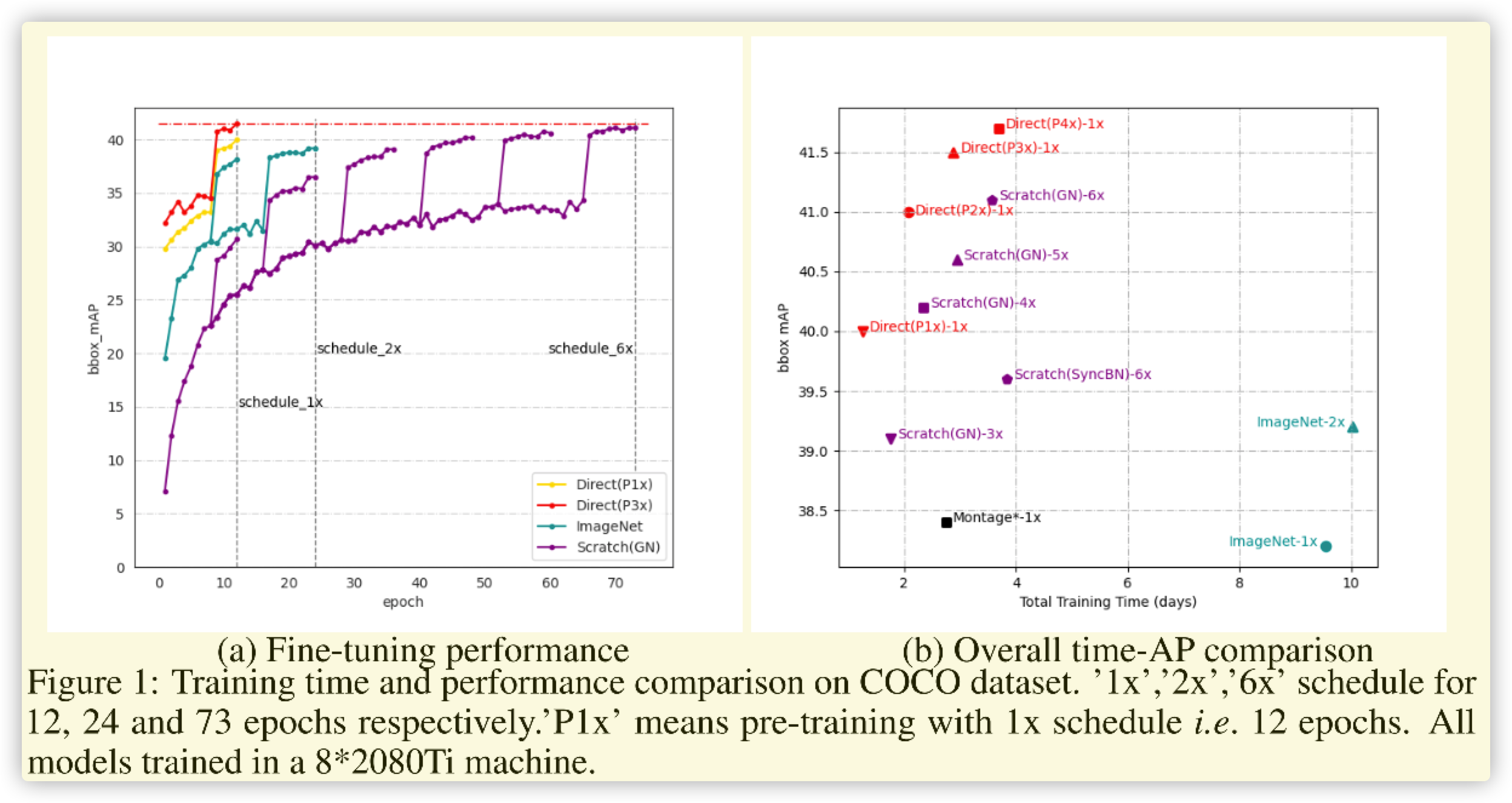
兩種方式各有千秋,前者可以很快收斂(在特定數據集收斂快),但是訓練複雜(預訓練實際長)。後者直接訓練較為容易(尤其在修改模型結構時),但是訓練周期較長(比tune階段長很多)。這篇文章就是解決從頭訓練的時長問題,從而達到集成兩者的優點(誇大其詞的說法)。
二. 流程
論文比較簡單,這裡進行總結如下:
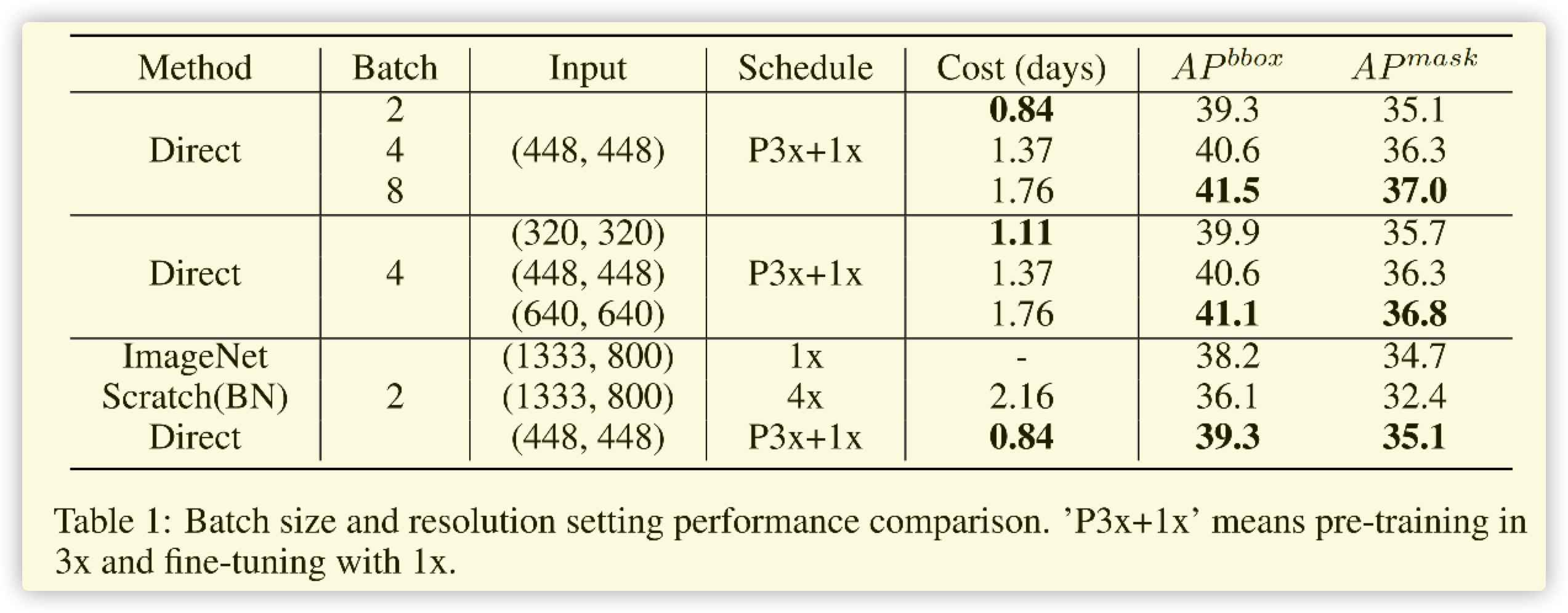
- 精度和 \(batchsize\) 有關,且在一定範圍內,越大越好。
- 精度和影像的解析度(大小)有關,且影像越大解析度越好,影像過小對精度影響較小。
- 精度和縮放有關,按照分類的縮放進行,不僅提高速度,且精度也比正常縮放效果好。
- 精度和BN層有關,正相關。
按照上述的總結,論文進行改進的訓練如下:
-
使用BN層(當前網路基礎結構)
-
Pretrained先用小尺度影像進行訓練,\(batchsize\)設置較大
-
數據處理部分–>先將影像縮放到 \((H,W)\times(1.0,1.2)\) ,隨機RandomCrop–>\((H,W)\),最後進行Padding到 \((h,W)\)
-
Finetune階段按照正常訓練即可
三. 總結
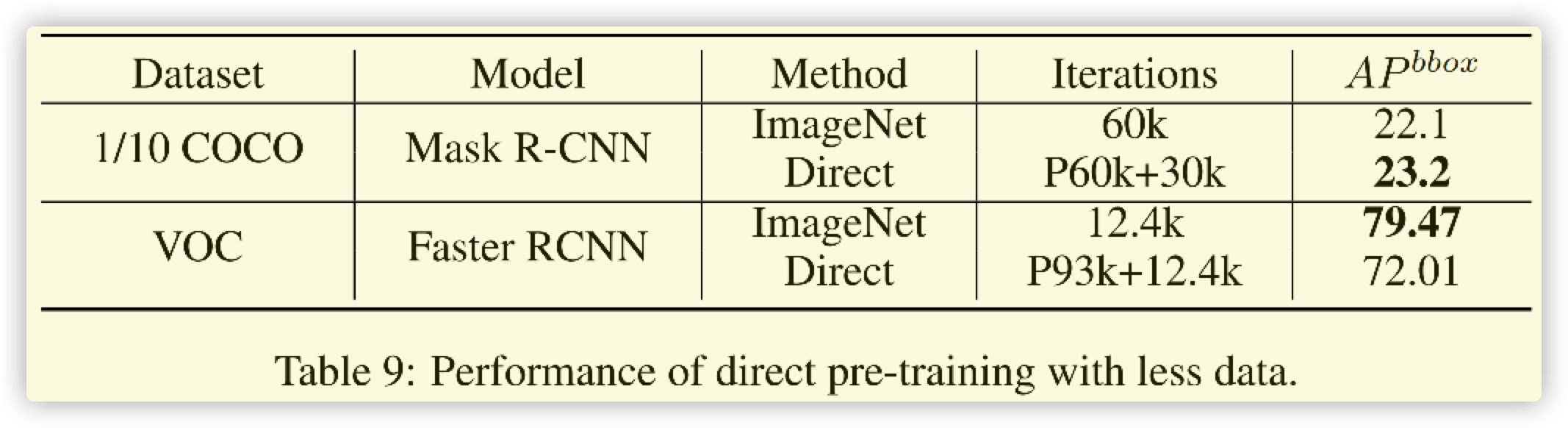
- 有一定使用意義,對於大數據集,直接使用此方法較好。
- 對於小的數據集,還是重新訓練imagenet比較好
- VOC的數據集太小,而且分布較為散亂,這裡對比意義不大。
- 筆者會在實際數據集上嘗試之後進行補充(TODO)