日常問題排查-調用超時
日常問題排查-調用超時
前言
日常Bug排查系列都是一些簡單Bug排查,筆者將在這裡介紹一些排查Bug的簡單技巧,同時順便積累素材_。
Bug現場
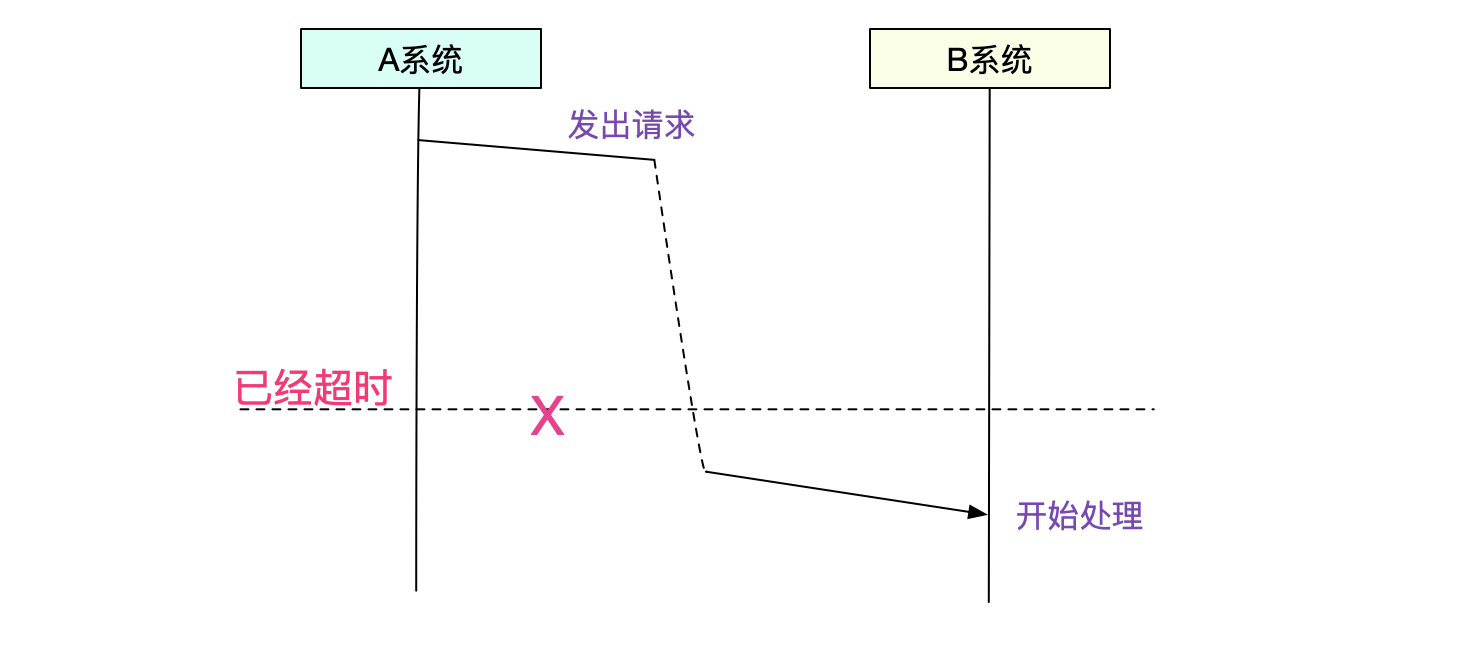
這次的Bug是大家喜聞樂見的調用超時。即A調用B超過了5s

搜索一下日誌,發現A系統在發出5s後超時。B系統在將近8s後才收到請求,也就是說B系統還沒開始處理,A系統就超時了。
開始排查
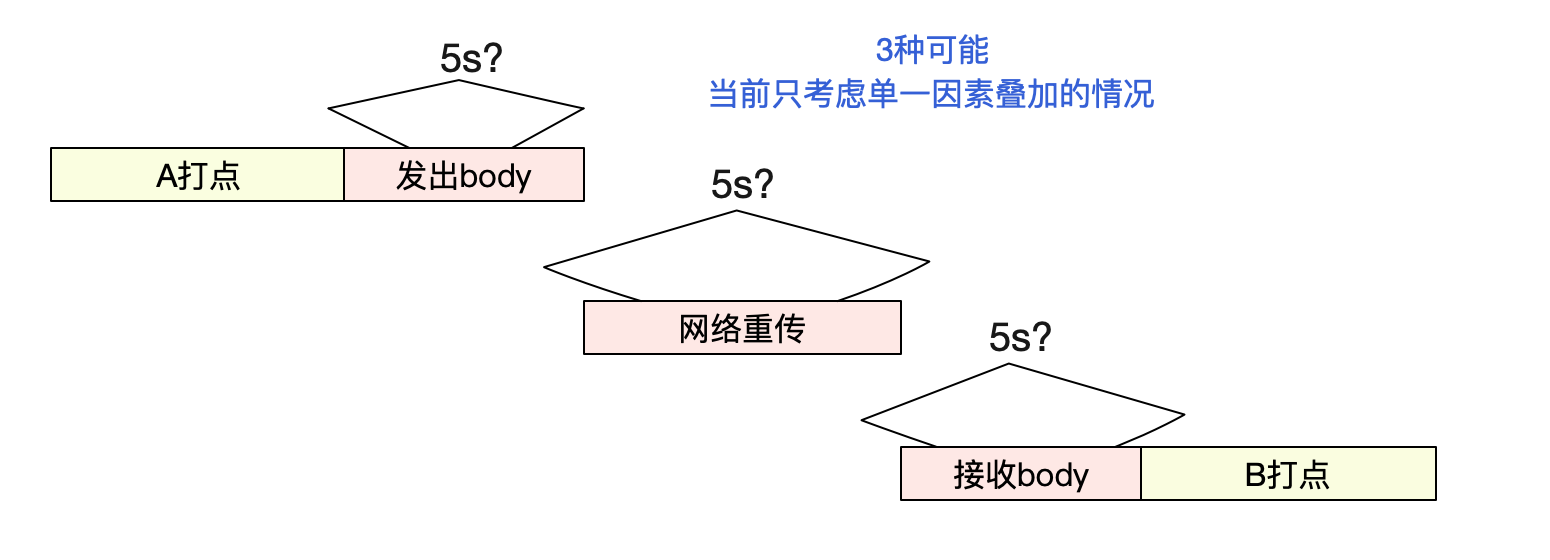
那麼這5秒鐘時間到底消失在哪裡呢?有3個可能的點:
1)A日誌打點到真正發出請求包
2)網路上
3)B真正接收請求包到B日誌打點。
網路check
首先筆者檢查了當時此機器的Net Traffic,發現非常平穩,考慮不是網路的鍋。
Full GC
對於Java應用,第二個考慮的點應該是GC,畢竟是Stop The World!筆者於是翻了下對應
A/B系統兩台
發現A系統okay,B系統在當時有Full GC,而且長達6s:
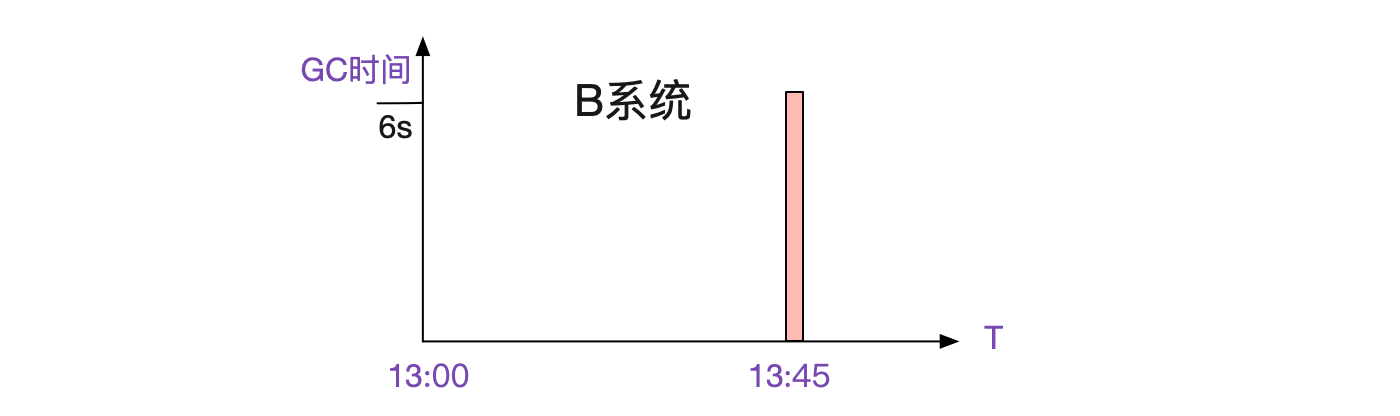
既然監控到了,那麼問題基本就是B系統的Full GC了,這個長達6s的full gc讓B系統5s後才列印出請求。可是這又引入了一個新的問題,為什麼一次Full GC能達到6s之巨。
為什麼這麼慢
觀察監控,筆者發現Full GC有時候快有時候慢。翻出對應6s的那條gc監控日誌。
B系統
[Full GC(Metadata GC Thresold) ...... (class unloading,5.5285249 secs]......[Times: user=0.85 sys=0.07 real=6.26 secs]
class unloading...
發現class unloading竟然會有將近5s。再進一步用awk過濾,最高有10s的,最短有0.1s的,而他們回收的記憶體大小確差不多。正常Full GC應該不會有這麼久,那個0.1s才感覺是正常的,難道當時機器有什麼事情發生?帶著疑問,筆者繼續觀察監控曲線,看看能不能找到些蛛絲馬跡,找到當時的時間點,發現:

GC慢的時候,對應機器記憶體的swap in很高。緊接著找了其它慢的Full GC。發現非常有規律,只要swap in很高Full GC就慢!
於是筆者,就嘗試著搜索了一下
//blogs.oracle.com/poonam/long-class-unloading-pauses-with-jdk8
發現,官方也發現了這個問題,並給予了解釋。
為什麼會有swap
實際上對應機器的記憶體使用率並不高,一共8G的記憶體,JVM只佔用到了4G左右。但swap的邏輯並僅僅是記憶體吃緊了才使用swap分區。如果有一塊記憶體長期不用,也有可能被交換到swap分區。
例如,JVM的class資訊,如果一個class MetaData僅僅是存在那裡,並不被用到的話。
可能被kernel扔到swap裡面。但這時候在GC可達性分析的時候,又會去訪問這個MetaData資訊,就導致雖然記憶體利用率不高,但依舊發生使用swap導致慢的情況!
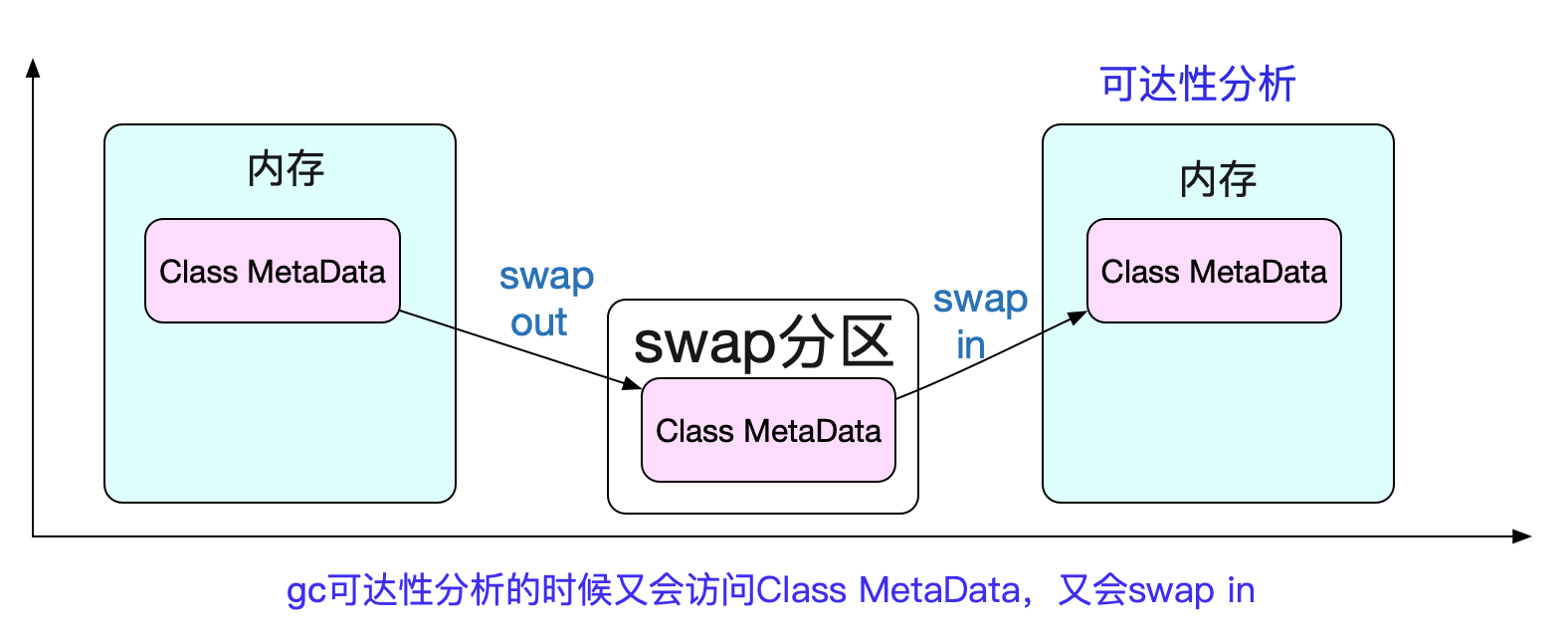
但是swap裡面到底是什麼內容,是不是和jvm相關就很難知曉了。所以看上去是概率上出現GC慢的問題。
另一個機房沒出問題
這時候巧的是,業務開發向筆者反映,另一個機房的相同應用確不會出現此問題。撈了下對應日誌,發現其class unloading只有0.9s左右。筆者觀察了下,發現另一個機房的機器並沒有用swap。於是筆者比較了一下兩個機房關於swap相關的內核參數:
GC慢機器 cat /proc/sys/vm/swappiness 60
GC正常機器 cat /proc/sys/vm/swappiness 1
發現我們新建機房的,我們SA已經預先把swappiness調成了1,意思是告訴kernel盡量不要使用swap,這樣就不會有這種swap導致的坑爹問題了。
總結
對於非記憶體瓶頸的應用,我們應該基於實際情況決定是否把swap禁用掉,以免因swap造成卡頓!另外,
對於一個偶發性的問題,我們應該通過監控等手段去尋找規律,這樣就很容易找到突破點。


