一次容器化springboot程式OOM問題探險
- 2019 年 10 月 3 日
- 筆記
背景
運維人員回饋一個容器化的java程式每跑一段時間就會出現OOM問題,重啟後,間隔大概兩天後復現。
問題調查
一查日誌
由於是容器化部署的程式,登上主機後使用docker logs ContainerId查看輸出日誌,並沒有發現任何異常輸出。 使用docker stats查看容器使用的資源情況,分配了2G大小,也沒有發現異常。
二缺失的工具
打算進入容器內部一探究竟,先使用docker ps 找到java程式的ContainerId
,再執行docker exec -it ContainerId /bin/bash進入容器。進入後,本想著使用jmap、jstack 等JVM分析命令來診斷,結果發現命令都不存在,顯示如下:
bash: jstack: command not found bash: jmap: command not found bash: jps: command not found bash: jstat: command not found突然意識到,可能打鏡像的時候使用的是精簡版的JDK,並沒有這些jVM分析工具,但是這仍然不能阻止我們分析問題的腳步,此時docker cp命令就派上用場了,它的作用是:在容器和宿主機之間拷貝文件。這裡使用的思路是:拷貝一個新的jdk到容器內部,目的是為了執行JVM分析命令,參照用法如下:
Usage: docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|- docker cp [OPTIONS] SRC_PATH|- CONTAINER:DEST_PATH [flags]有了JVM工具,我們就可以開始分析咯。
三查GC情況
通過jstat查看gc情況
bin/jstat -gcutil 1 1s
看樣子沒有什麼問題,full gc也少。再看一下對象的佔用情況,由於是容器內部,進程號為1,執行如下命令:
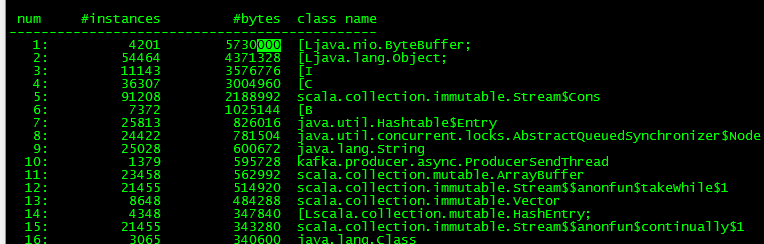
bin/jmap -histo 1 |more 發現ByteBuffer對象佔用最高,這是異常點一。
四查執行緒快照情況
- 通過jstack查看執行緒快照情況。
bin/jstack -l 1 > thread.txt下載快照,這裡推薦一個在線的執行緒快照分析網站。
https://gceasy.io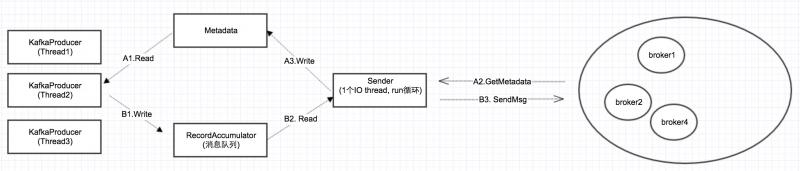
上傳後,發現創建的執行緒近2000個,且大多是TIMED_WAITING狀態。感覺逐漸接近真相了。 點擊詳情發現有大量的kafka-producer-network-thread | producer-X 執行緒。如果是低版本則是大量的ProducerSendThread執行緒。(後續驗證得知),可以看出這個是kafka生產者創建的執行緒,如下是生產者發送模型:
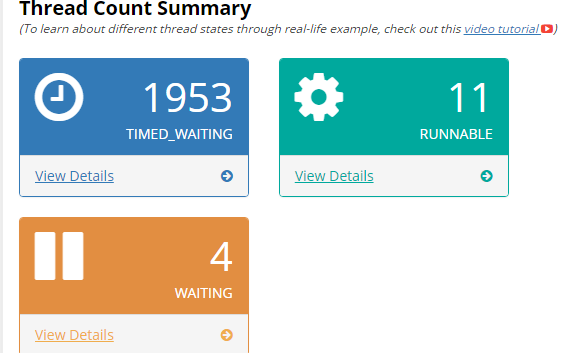
根據生產者的發送模型,我們知道,這個sender執行緒主要做兩個事,一是獲取kafka集群的Metadata共享給多個生產者,二是把生產者送到本地消息隊列中的數據,發送至遠端集群。而本地消息隊列底層的數據結構就是java NIO的ByteBuffer。
這裡發現了異常點二:創建過多kafka生產者。
由於沒有業務程式碼,決定寫一個Demo程式來驗證這個想法,定時2秒創建一個生產者對象,發送當前時間到kafka中,為了更好的觀察,啟動時指定jmx埠,使用jconsole來觀察執行緒和記憶體情況,程式碼如下:
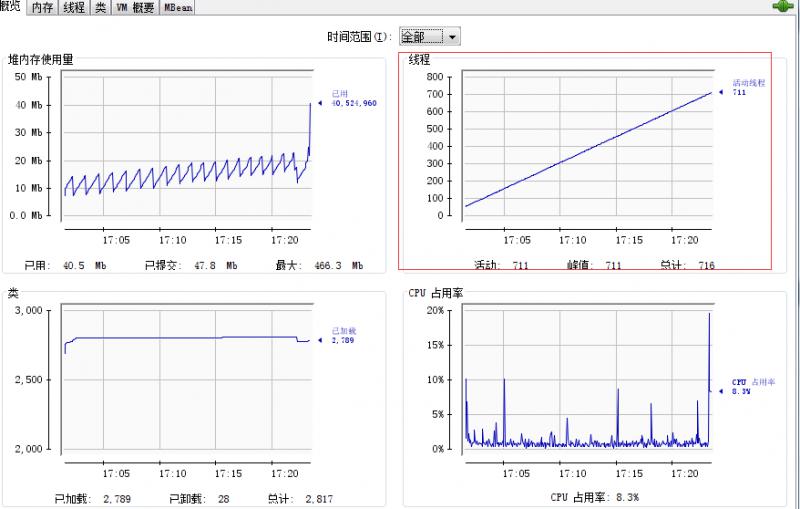
nohup java -jar -Djava.rmi.server.hostname=ip -Dcom.sun.management.jmxremote.port=18099 -Dcom.sun.management.jmxremote.rmi.port=18099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar com.hyq.kafkaMultipleProducer-1.0.0.jar 2>&1 &連接jconsole後觀察,發現執行緒數一直增長,使用記憶體也在逐漸增加,具體情況如下圖:
故障原因回顧
分析到這裡,基本確定了,應該是業務程式碼中循環創建Producer對象導致的。
在kafka生產者發送模型中封裝了 Java NIO中的 ByteBuffer 用來保存消息數據,ByteBuffer的創建是非常消耗資源的,儘管設計了BufferPool來複用,但也經不住每一條消息就創建一個buffer對象,這也就是為什麼jmap顯示ByteBuffer佔用記憶體最多的原因。
總結
在日常的故障定位中,多多使用JDK自帶的工具,來幫助我們輔助定位問題。一些其他的知識點:
jmap -histo顯示的對象含義:
[C 代表 char[] [S 代表 short[] [I 代表 int[] [B 代表 byte[] [[I 代表 int[][]如果導出的dump文件過大,可以將MAT上傳至伺服器,分析完畢後,下載分析報告查看,命令為:
./mat/ParseHeapDump.sh active.dump org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components 可能儘快觸發Full GC的幾種方式
1) System.gc();或者Runtime.getRuntime().gc(); 2 ) jmap -histo:live或者jmap -dump:live。 這個命令執行,JVM會先觸發gc,然後再統計資訊。 3) 老生代記憶體不足的時候 