字元串之————圖文講解字元串排序(LSD、MSD)
- 2019 年 10 月 3 日
- 筆記
本篇文章圍繞字元串排序的核心思想,通過圖示例子和程式碼分析的方式講解了兩個經典的字元串排序方法,內容很詳細,完整程式碼放在文章的最後。
一、鍵索引計數法
在一般排序中,都要用裡面的元素不斷比較,而字元串這玩意兒大可不必比較,有另外一種思想。在鍵索引計數法中,可以突破NlongN的排序演算法運行時間下限,它的時間級別是線性的!
引入字母表概念:
想要不對字元串裡面的字元進行對比,我們需要引入字母表的概念,比如將‘a’看作1,‘b’看作2,‘c’看作3,這樣下去,26個字母只需要一個長度為27的數組就能夠表示(下標為0不用),而且按數字來看他們是有序的(從a到z對應1到26)。
所以“abcdefg..”這些字元轉換為整型時(使用charAt()函數),自然有一個對應的順序,所以我們只需要找到一個合適大小的數組來保存每個將會用到的字元的資訊即可。現在我們創建count[]數組,大小為256,用來保存對應字元出現的頻率和排序時的索引。
索引計數法共分為四步,下面進行說明並舉例。(用R來表示字元的種類,r表示字元在R中的順序)
1、計算頻率:
for(int i=0;i<N;i++){//計算頻率 count[a[i].charAt(d)+1]++; }
遍歷所有字元串,d為字元串的第d個字元(下面例子中字元串都為單個數字)。
出現什麼字元,我們就將對應的count[r+1]加一(裡面為什麼是r+1,看到下一步你自然會明白)。
2、計算索引:
for(int r=0;r<R;r++){//將頻率轉換為索引 count[r+1]+=count[r]; }
需要在我們計算出頻率的基礎上進行:count[r+1]+=count[r]
將count數組中後一位總是加上前一位。
例子:
老師組織了一次遊玩,把同學們分為四組,需要做的是將同學按組號排序(這裡R為4,count數組大小為R+2,下標為0不用)
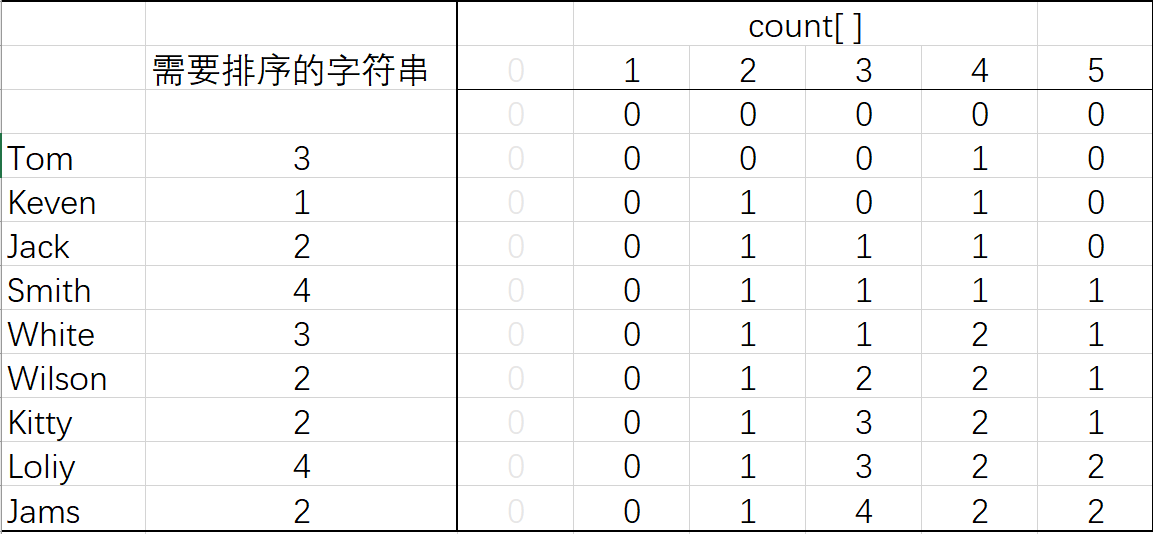
圖1 計算出現頻率

圖2 將頻率轉換為起始索引
可以從圖二最後一行看到,r為1對應索引為0,即一組從0開始排序。
r為2對應索引1,即二組從1開始排序。
而第三組索引為5,說明從一到四全是第二組的位置。
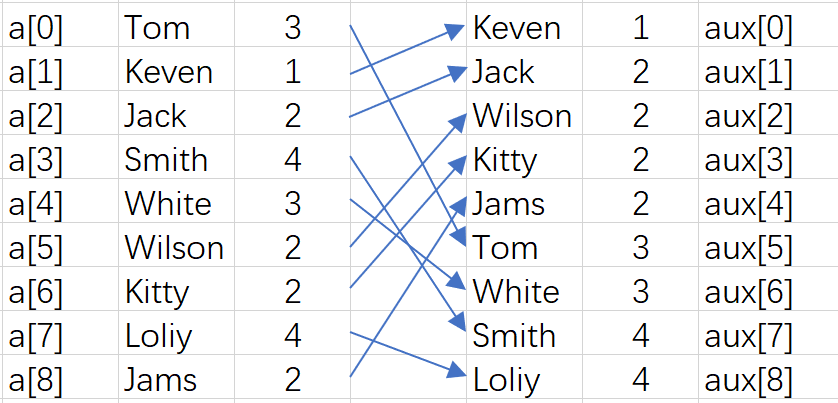
3、數據分類
for(int i=0;i<N;i++){//數據分類 aux[count[a[i].charAt(d)]++]=a[i]; }
進行數據分類我們需要一個輔助數組aux,用來暫時儲存排序的數據。
把數據放入輔助字元串數組,全部放入時已經形成有序。
4、回寫
for(int i=0;i<N;i++){//回寫 a[i]=aux[i]; }
把輔助字元串數組的內容搬回去就行了。
到此為止鍵索引計數法就完成了,接下來利用它來實現LSD/MSD。
二、低位優先排序(LSD)
第位優先排序與高位優先排序的主要區別在於排序的方向,核心思想演算法都是通過鍵索引計數法。低位優先演算法是從字元串的右到左來排序(這可能會出現一些問題,在高位優先排序的介紹中將會提到)。
下圖為一個地位優先排序的完整過程:

利用索引計數法,從左到右對每一位進行索引計數,這就形成了第位優先排序。
for (int d=W-1;d>=0;d--){//從右到左對所有字元串的每位判斷 int count[]=new int[R+1]; for(int i=0;i<N;i++){//計算頻率 count[a[i].charAt(d)+1]++; } for(int r=0;r<R;r++){//將頻率轉換為索引 count[r+1]+=count[r]; } for(int i=0;i<N;i++){//排序 aux[count[a[i].charAt(d)]++]=a[i]; } for(int i=0;i<N;i++){//回寫 a[i]=aux[i]; } }
三、高位優先排序(MSD)
在低位優先排序中,可能會出現一點問題。比如字元串“ab”與“ba”,長度為2需要進行兩次排序,第一次排序結果為“ba”、“ab”,第二次排序結果為“ab”、“ba”,第一次排序的結果對第二次毫無意義,這就造成了時間上的浪費。
而在高位優先排序中,只會進行一次排序。結果為“ab”、“ba”。
不同之處:
在高位排序中又引入了分組的概念,即用首字母來切分下一個排序組。

在程式碼中我們使用遞歸的方式來不斷切分排序組。
1 public static void sort(String[] a,int lo,int hi,int d){ 2 if(lo>=hi){ 3 return; 4 } 5 int[] count=new int[R+2]; 6 for(int i=lo;i<=hi;i++){ 7 count[charAt(a[i],d)+2]++; 8 } 9 for(int r=0;r<R+1;r++){ 10 count[r+1]+=count[r]; 11 } 12 for(int i=0;i<=hi;i++){ 13 aux[count[charAt(a[i],d)+1]++]=a[i]; 14 } 15 for(int i=0;i<=hi;i++){ 16 a[i]=aux[i]; 17 } 18 for(int r=0;r<R;r++){ 19 sort(a,lo+count[r],lo+count[r+1]-1,d+1); 20 } 21 }
上面這段程式碼非常簡潔,但其中有一些地方是複雜的,請研究下面例子的調用過程確保你理解了演算法。

圖3 sort(a,0,9,0)的頂層調用
在下一期帶來另一種字元串排序方法,三向字元串快速排序,相比於這兩種方法,將會有更廣的受用面!
四、完整程式碼
1 public class LSD { 2 public static void sort(String[] a,int W){//W表示字元串的長度 3 int N=a.length; 4 int R=256;//依字元的種類數目而定 5 String aux[]=new String[N]; 6 for (int d=W-1;d>=0;d--){//從右到左對所有字元串的每位判斷 7 int count[]=new int[R+1]; 8 for(int i=0;i<N;i++){//計算頻率 9 count[a[i].charAt(d)+1]++; 10 } 11 for(int r=0;r<R;r++){//將頻率轉換為索引 12 count[r+1]+=count[r]; 13 } 14 for(int i=0;i<N;i++){//排序 15 aux[count[a[i].charAt(d)]++]=a[i]; 16 } 17 for(int i=0;i<N;i++){//回寫 18 a[i]=aux[i]; 19 } 20 } 21 } 22 }
1 public class MSD { 2 private static int R=256; 3 private static String[] aux; 4 5 public static int charAt(String s,int d){ 6 if(d<s.length()){ 7 return s.charAt(d); 8 }else{ 9 return -1; 10 } 11 } 12 13 public static void sort(String[] a){ 14 int N=a.length; 15 aux=new String[N]; 16 sort(a,0,N-1,0); 17 } 18 19 public static void sort(String[] a,int lo,int hi,int d){ 20 if(lo>=hi){ 21 return; 22 } 23 int[] count=new int[R+2]; 24 for(int i=lo;i<=hi;i++){ 25 count[charAt(a[i],d)+2]++; 26 } 27 for(int r=0;r<R+1;r++){ 28 count[r+1]+=count[r]; 29 } 30 for(int i=0;i<=hi;i++){ 31 aux[count[charAt(a[i],d)+1]++]=a[i]; 32 } 33 for(int i=0;i<=hi;i++){ 34 a[i]=aux[i]; 35 } 36 for(int r=0;r<R;r++){ 37 sort(a,lo+count[r],lo+count[r+1]-1,d+1); 38 } 39 } 40 }
