JVM-垃圾收集演算法基礎
目錄
JVM-運行時數據區域
JVM-對象及其記憶體布局
JVM-垃圾收集演算法基礎
前言
上一篇文章對JVM的對象的記憶體布局以及對象創建邏輯等內容進行了梳理,本篇文章對常見的垃圾回收演算法以及HotSpot垃圾回收器進行深入解析。
手動釋放記憶體導致的問題
在託管程式碼出現之前,我們申請一片記憶體使用完後,需要手動釋放記憶體。手動釋放有以下幾個問題。
- 忘記釋放
忘記釋放記憶體,會導致記憶體溢出。程式長時間申請的記憶體一直不釋放。最終可能導致進程記憶體佔滿。
- 重複釋放
忘記釋放對程式本身的執行的正確性不會產生影響,另一種更嚴重的問題是重複釋放。當已經釋放過後,該地址被其他地方重新分配。此時又再次釋放或使用了該記憶體,可能會導致無法預料的現象。
int* p = new int(5);
*p = 5;
delete p;
delete p;//此時p指向的地址可能被重新分配使用
部分編譯器會阻止重複釋放的問題,良好的編碼是在delete後將指針置空。
- 釋放類型錯誤
創建的是數組,釋放的不是數組。這種情況若創建的時基本類型,那麼不會有什麼問題,但是創建元素不是基本類型而是對象,由於new T[n]實際分配的記憶體空間是n*sizeof(T) + 4,額外的4個位元組用於存放數組元素個數。在調用delete []時,前面4個位元組記錄的元素個數分別執行各個元素的析構函數,然後調用free (p-4)釋放記憶體。
Tclass * p = new Tclass[20];
p[0] = 1;
delete p; //應該使用delete []
- 記憶體釋放錯誤
int a = 200;
int b = 500;
int *p = new int(a);
p = &b; //(1)
delete p;
p = NULL;
在delete p時會有2個問題。
- p原來指向的地址成了記憶體泄漏(new int產生的地址) ,因為沒釋放。
- p原先指向的是堆記憶體, 後續操作已經指向局部變數(棧空間)對象地址了,而棧空間是無須進行delete的,因此delete 棧空間時會報錯。
垃圾判定方法
由於手動釋放記憶體可能導致各種問題,因此在C、C++等非託管語言中,程式設計師手動進行記憶體管理,需要非常小心。
為了避免上述手動記憶體管理造成的問題,因此出現了自動管理記憶體的GC演算法。把記憶體管理交給電腦,避免了手動釋放記憶體導致的問題。
自動記憶體管理做了2件事情:找出垃圾和回收垃圾,使得該記憶體可以重複使用。通常不需要再使用(不被引用)的對象被稱為垃圾,發現和釋放被垃圾佔用的空間稱為垃圾收集。
那麼如何才能確定哪些對象是垃圾?目前主要有2種方法,引用計數法和可達性分析法。
哪些對象是垃圾?
引用計數演算法
1960年,George E. Collins 在論文中發布了叫作引用計數的GC演算法。引用計數法中引入了一個概念,那就是「計數器」。計數器表示的是對象引用了這個對象(被引用數)。計數器是無符號的整數,用於存儲計數器的空間大小根據演算法和實現而有所不同。每當有一個對象引用自己,就把自己的引用計數+1。每當一個對象不再引用自己,就把自己的引用計數-1,當引用計數為0時,則表示對象成為垃圾,記憶體就可以被回收。
假設一開始有ABC三個對象,其中A引用了B,A和C被根(比如棧幀中的局部變數表)引用。此時他們的計數都為1。
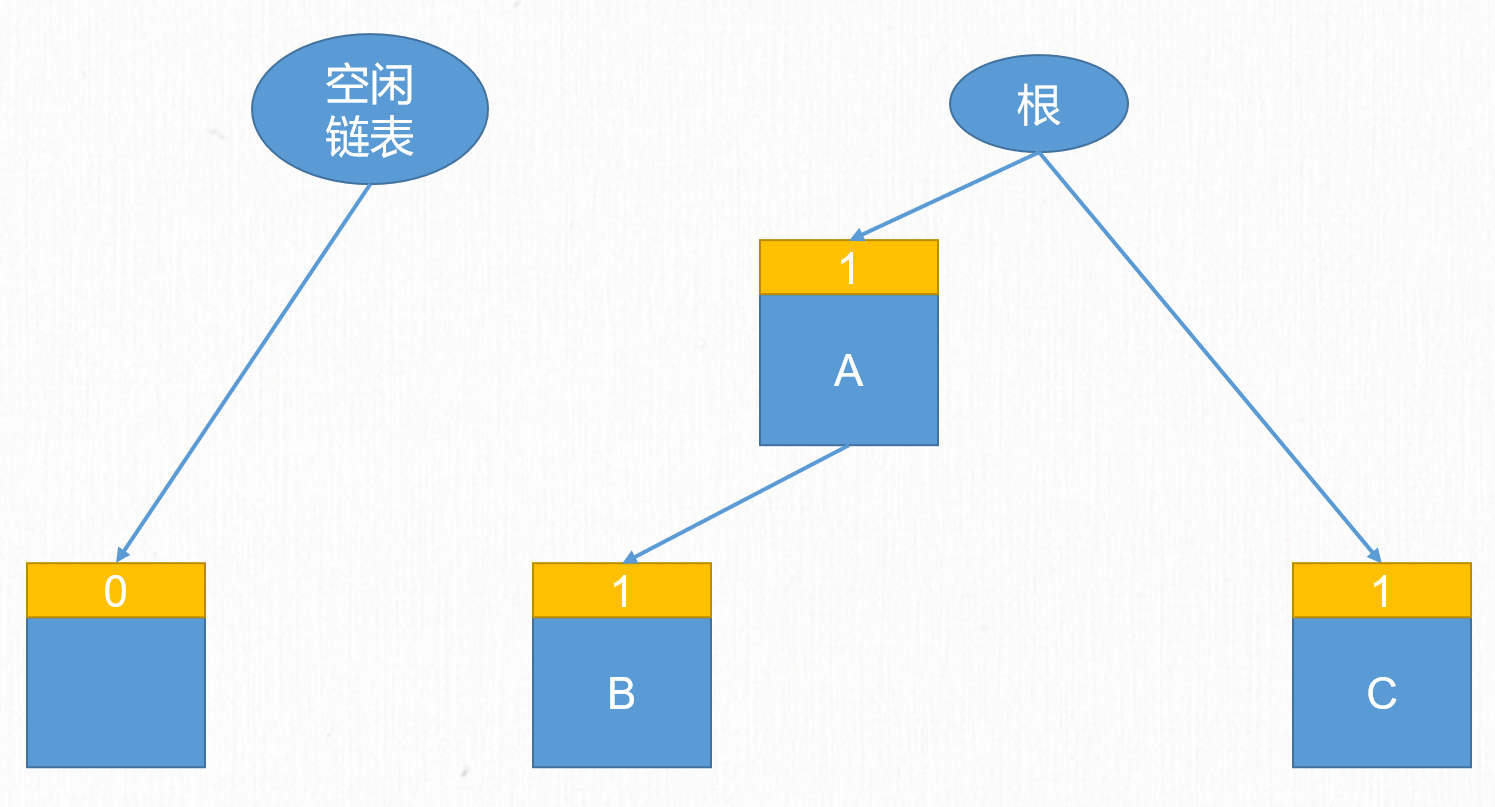
接下來A引用了C,B不再被A引用。此時B的引用計數歸0,B的記憶體就被空閑鏈表所連接,下次B的記憶體可以被重新分配重複使用。而C的引用計數從1變為2。
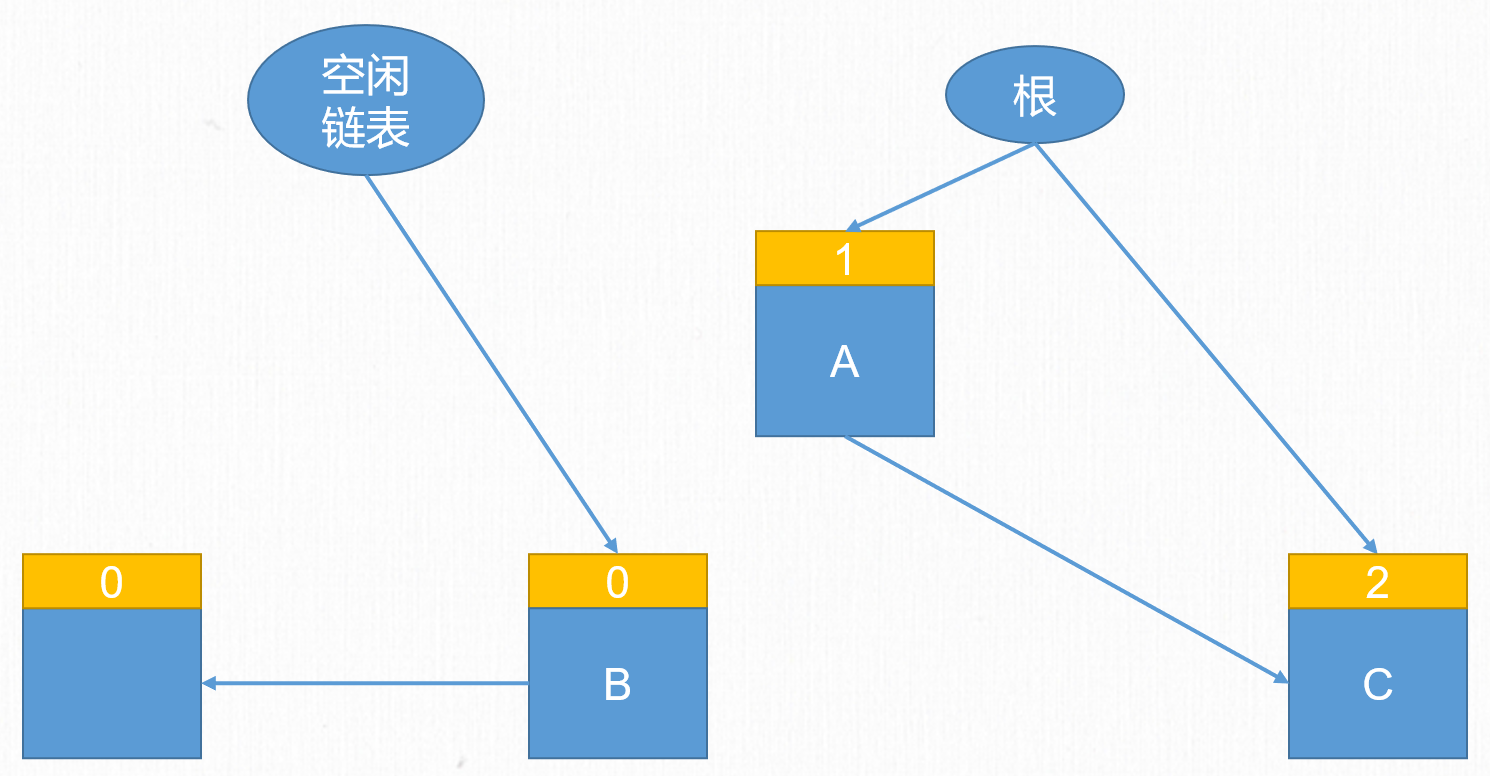
在引用計數法中,每個對象始終都知道自己的被引用數。當被引用數的值為0時,對象馬上就會把自己作為空閑空間連接到空閑鏈表。也就是對象的記憶體空間可以被立即回收,垃圾回收效率非常高。但是引用計數法有個致命缺點,就是無法處理循環引用。
假設A和B對象存在循環引用,在方法執行的時候他們的引用計數都為2。
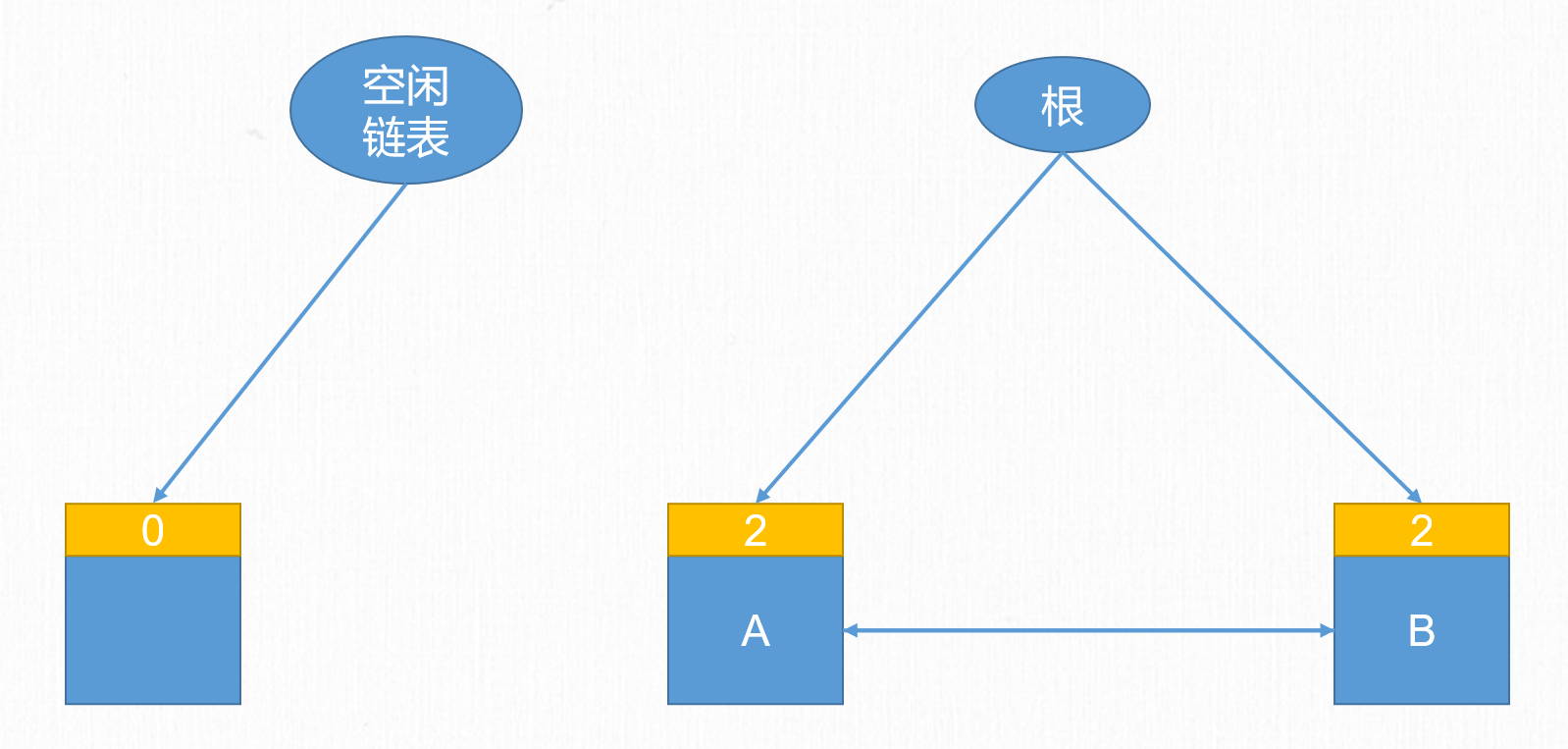
當方法執行完,棧幀彈出後,A和B對象的引用計數減為1,此時由於他們計數永遠無法到0,因此他們的記憶體無法被釋放。

引用計數法除了無法處理循環引用的問題外,還有幾個其他的問題,比如每次指針更新都需要更新計數器,計數器需要佔用空間等。為了解決引用計數法的一些缺點,衍生出許多其他的引用計數法,比如延遲引用計數法、Sticky引用計數法、Sticky引用計數法等,這裡不做具體討論。
由於引用計數法無法解決循環引用問題,因此Hotspot VM的堆區域的垃圾收集演算法並沒有採用引用計數法。而方法區中的運行時常量池(比如字元串表)因為不存在循環引用的問題,因此採用了引用計數法。
可達性分析法
當前主流的商用程式語言(Java、C#,上溯至前面提到的古老的Lisp)的記憶體管理系統,都是通過可達性分析(Reachability Analysis) 演算法來判定對象是否存活的。這個演算法的基本思路就是通過一系列稱為GC Roots的根對象作為起始節點集,從這些節點開始,根據引用關係向下搜索,搜索過程所走過的路徑稱為「引用鏈」(Reference Chain),如果某個對象到GC Roots間沒有任何引用鏈相連,或者用圖論的話來說就是從GC Roots到這個對象不可達時,則證明此對象是不可能再被使用的。
在JVM中GC Roots包括以下幾種:
- 虛擬機棧引用的對象(實際是棧幀中的局部變數表引用的對象),如某方法的參數、局部變數等。
- 方法區中靜態變數引用的對象,如類中的靜態引用類型變數。
- 方法區中常量引用的對象,比如字元串表的引用。
- 本地方法棧中JNI引用的對象。Java方法需要調用Native方法都需要通過JVM提供的JNI進行調用。
- 以及其他JVM內部的引用,比如如klass對象,一些常駐的異常對象(比如NullPointExcepiton、OutOfMemoryError)等,系統類載入器,被同步鎖(synchronized關鍵字)持有的對象,本地程式碼快取等。
垃圾收集演算法
通過引用計數法和可達性分析法,我們可以找出哪些是垃圾。找出垃圾,需要將垃圾清除。
前面說了引用計數法的垃圾清除非常簡單,只要計數為0時,就可以將對象佔用的記憶體空間加入到空閑鏈表中。記憶體就可以被回收利用。但是可達性分析法的垃圾清除並不容易。可達性分析並不是對象變為垃圾時就能立即回收。它需要一個查找的過程,通過查找整個堆空間或部分堆空間找出垃圾。然後才能對垃圾進行清除。19世紀60年代產生了幾種垃圾收集演算法,一直使用到現在。這些演算法包括標記-清除、標記-複製和標記-整理。
標記-清除
最早出現的垃圾收集演算法是 標記-清除(Mark-Sweep) 演算法,Lisp之父和人工智慧之父John McCarthy在1960年在其論文中首次提到了該GC演算法。
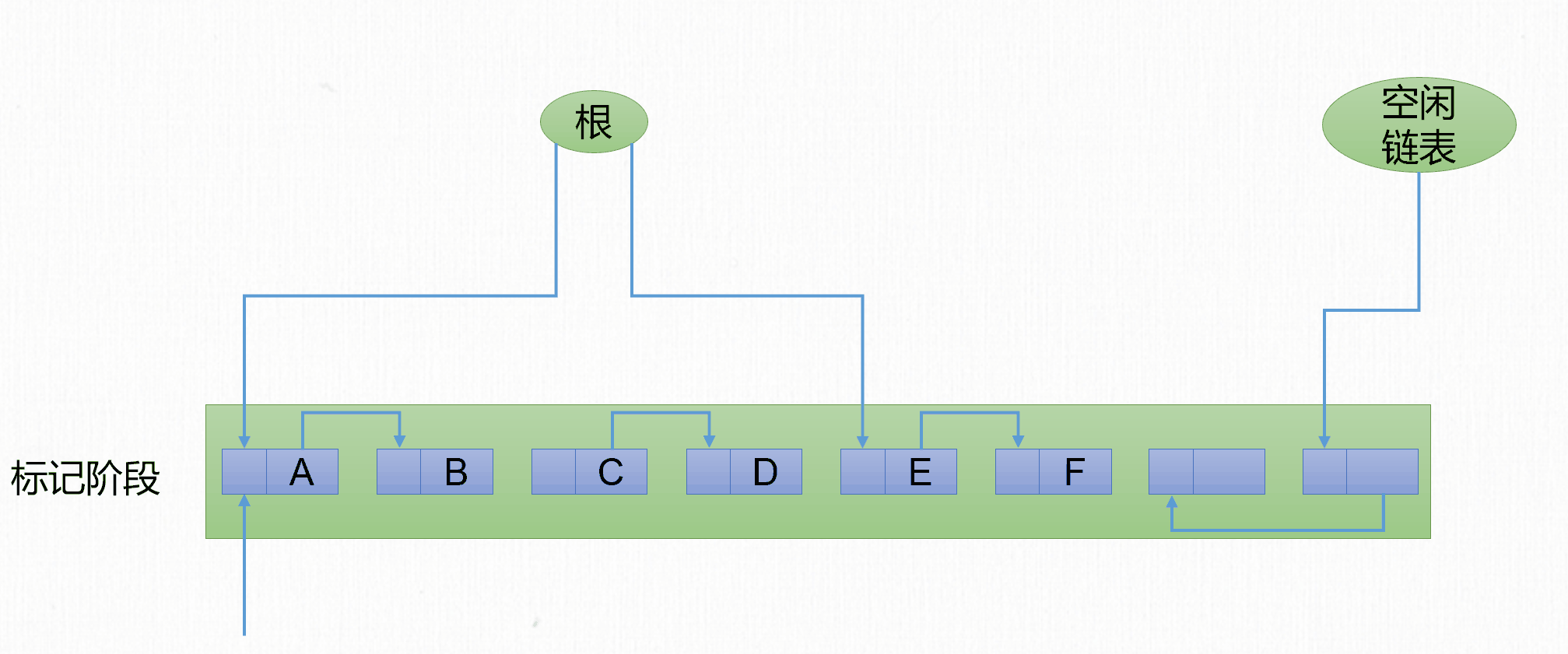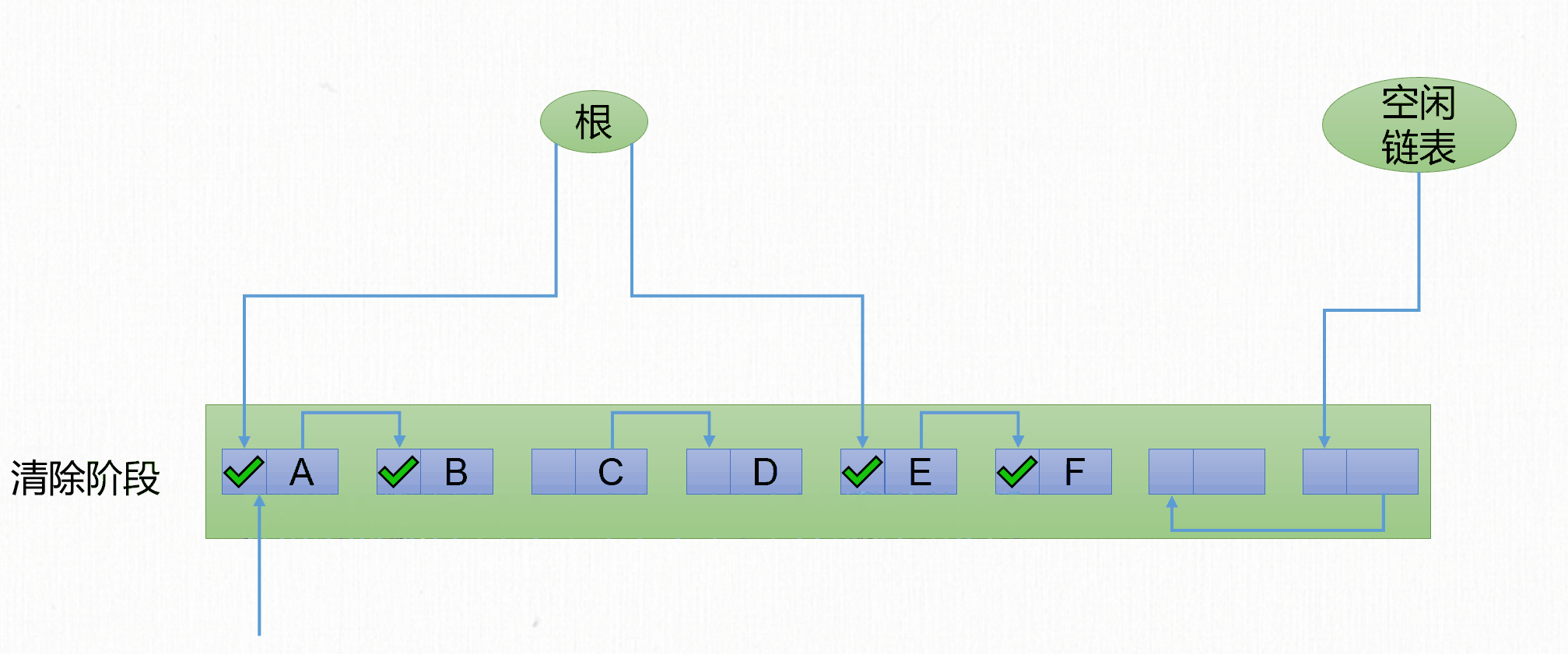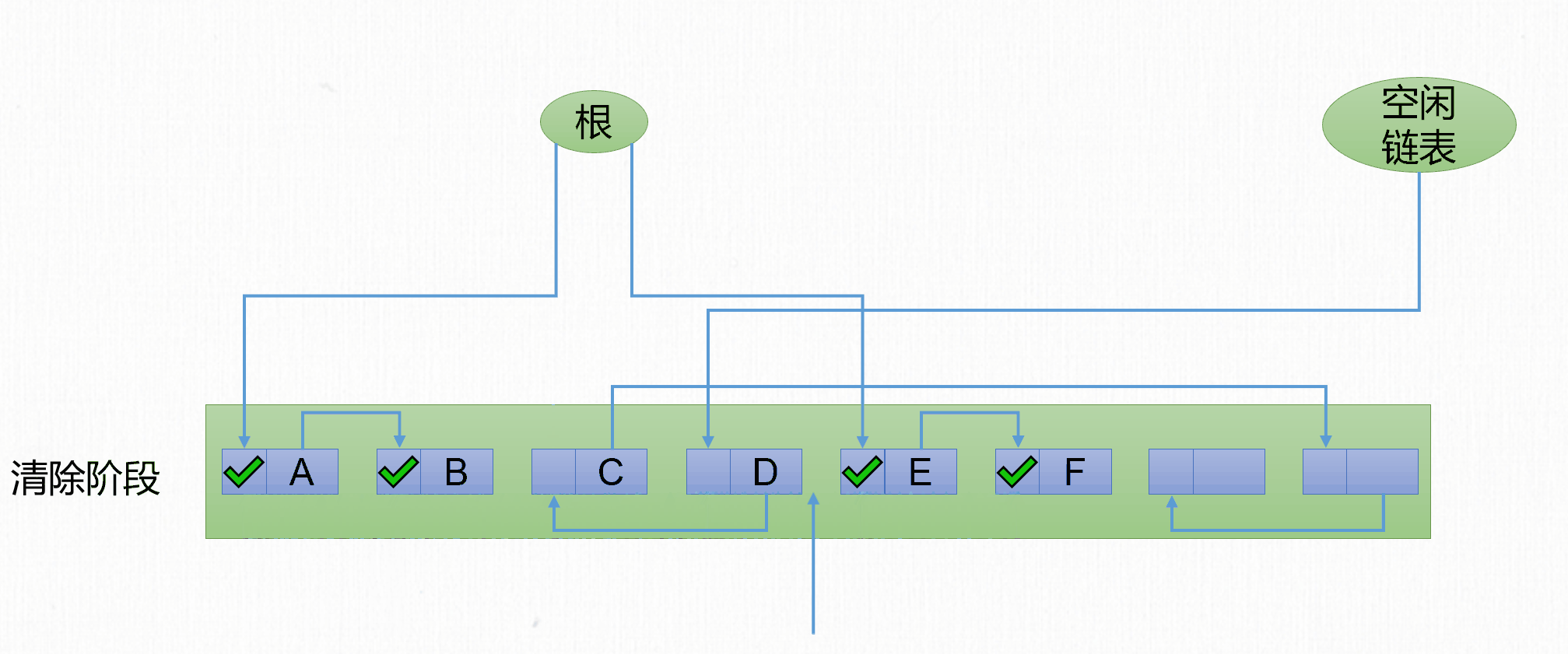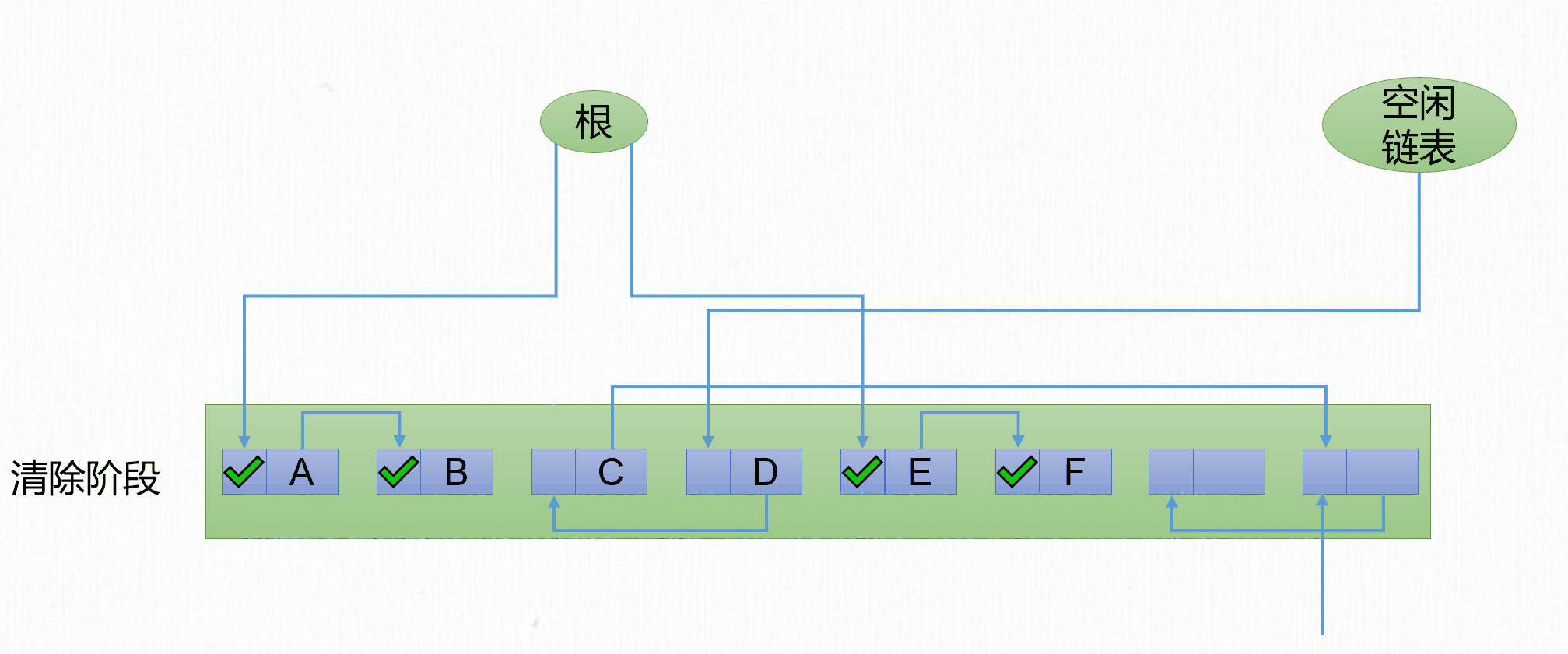
標記-清除演算法和名字一樣,包含2個步驟:
- 標記階段:遍歷
GC Roots標記所有存活對象。 - 清除階段:遍歷整個堆,回收所有沒有被標記的對象,將垃圾對象的記憶體空間連接到空閑鏈表。
當然也可以標記所有不存活對象,清理所有被標記對象。
回收前記憶體

回收後記憶體

優點
- 無需移動指針
由於標記-清除演算法只清除記憶體,而不壓縮記憶體,因此對象地址不會發生改變,對象不移動時可以與其他GC演算法相互組合使用。 - 實現簡單
標記-清除只需要2個步驟,實現非常簡單,與其他GC演算法組合起來也就很簡單了。
在Hotspot虛擬機中,標記-清除演算法通常用在老年代。比如CMS垃圾收集器的老年代就是使用標記-清除演算法。
缺點
-
記憶體碎片
可以發現標記-清除有個嚴重的問題就是會造成記憶體碎片。當清理階段時,會將垃圾對象空間插入到空閑鏈表中,若多個回收區域記憶體是連續的,還會將他們合併成一個空間。另外由於標記-清除演算法會出現記憶體碎片,還會導致分配對象的效率降低。
-
對象分配速度慢
當分配對象的時候,需要則遍歷每個空閑鏈表的節點。通常使用空閑鏈表有三種分配方式:First-fit、Best-fit和Worst-fit。
- First-fit: First-fit優先找到第一塊大於或等於需要分配記憶體大小的空閑塊。如果空閑塊大於所需分配的記憶體時將其分割為2塊。
- Best-fit: Best-fit會遍歷整個空閑鏈表,儘可能找到最適合的記憶體塊,它會找到大於或等於需要分配記憶體大小的最小分塊。
- Worst-fit: Worst-fit會找出空閑鏈表中最大的分塊,將其分割成mutator申請的大小和分割後剩餘的大小,目的是將分割後剩餘的分塊最大化。但因為Worst-fit很容易生成大量小的分塊,一般不推薦使用。
-
與寫時複製技術不兼容
標記-清除 演算法除了會產生記憶體碎片以外,還無法和寫時複製技術一起使用。由於 標記-清除 演算法需要修改對象頭部的標記用於記錄對象是否存活,因此,發生GC時,存活的對象頭部的標記就會被修改,從而導致出現記憶體複製。寫時複製可以通過共享記憶體的方式將同一份記憶體空間共享給多個進程使用,而當記憶體被修改時,則需要複製進程私有的記憶體空間並修改。發生寫時複製後該進程只能訪問私有的空間。從而在只讀的情況下提高記憶體使用效率。
-
吞吐量與堆大小相關
標記-清除 演算法在清除階段需要遍歷整個堆,找到沒有標記的對象進行清除。因此隨著堆增大,GC效率就會降低。
優化
為了解決 標記-清除 演算法由於記憶體碎片導致對象分配速度慢的問題,衍生出一些優秀的演算法。
- 多個空閑鏈表:將不同大小的空閑塊分組,提高記憶體分配速度。
- BiBOP(Big Bag Of Pages)法:把堆分割成固定大小的塊,讓每個塊只能配置同樣大小的對象。分配指定大小的對象,直接找到對應的塊進行分配。
- 點陣圖標記:將對象標記從對象頭提取出,放在一個單獨的點陣圖表格種,使得標記-清除演算法與寫時複製技術兼容。
- 延遲清除法:由於清除演算法需要遍歷整個堆,因此將清除步驟延遲到創建對象的步驟處理,降低最大暫停時間。清除演算法會記錄上一次清除的位置,當創建對象的時候,會從上一次清除的位置繼續向後清除,因此不會遍歷整個堆。
標記-複製
標記-清除 演算法高效的同時帶來了記憶體碎片的問題,而引用計數法又無法回收循環引用的對象。
1963年,也有「人工智慧之父」之稱的Marvin L. Minsky在論文中發布了複製演算法。
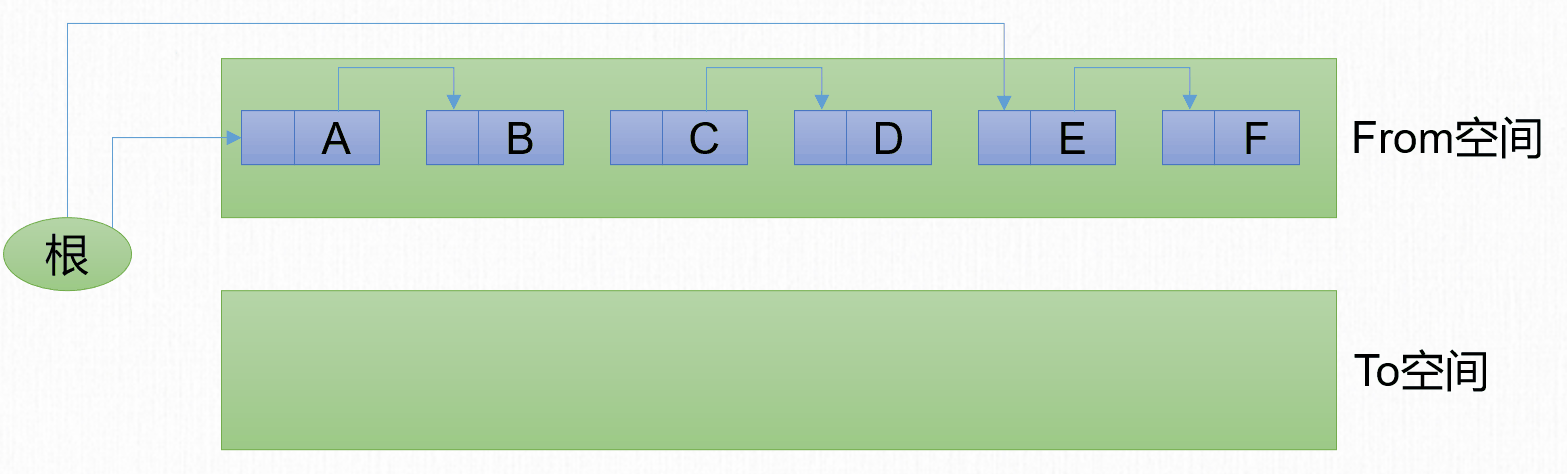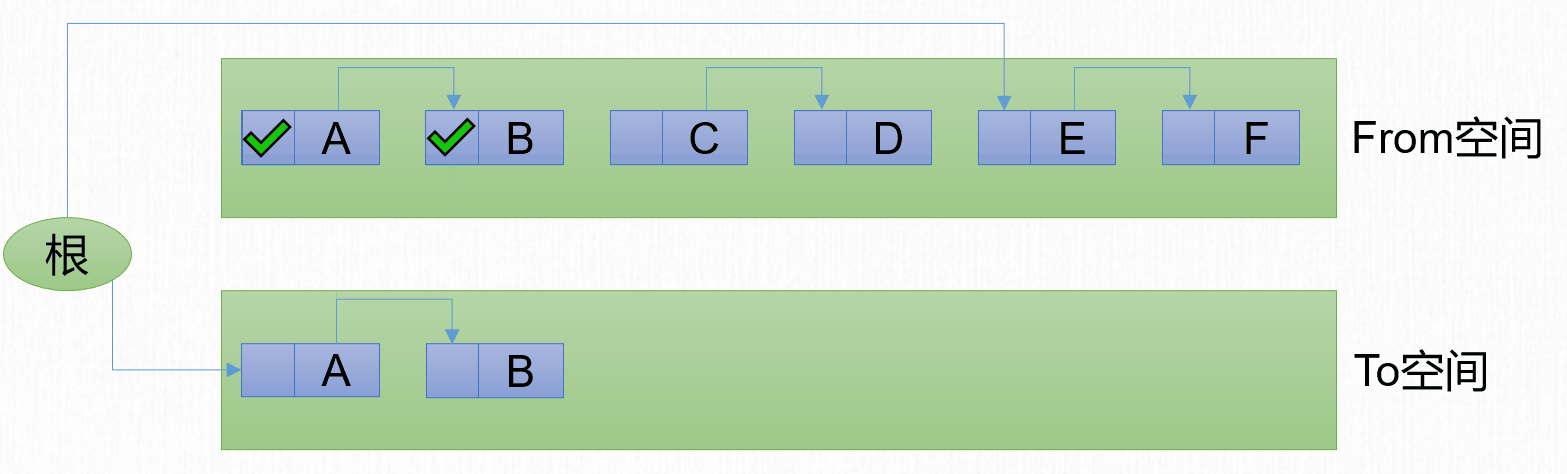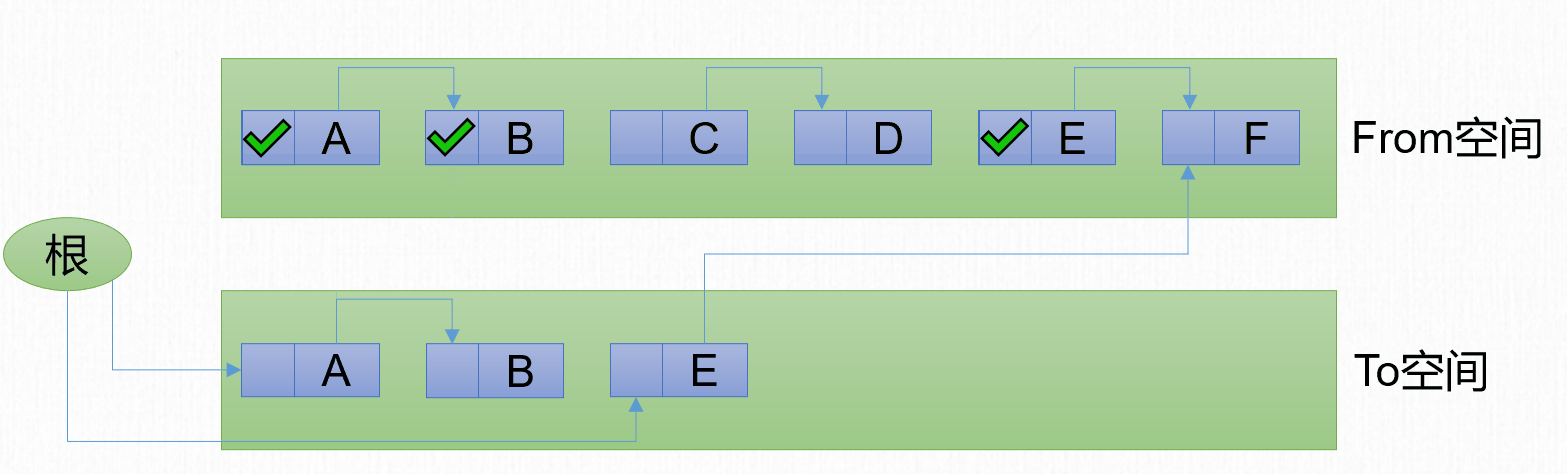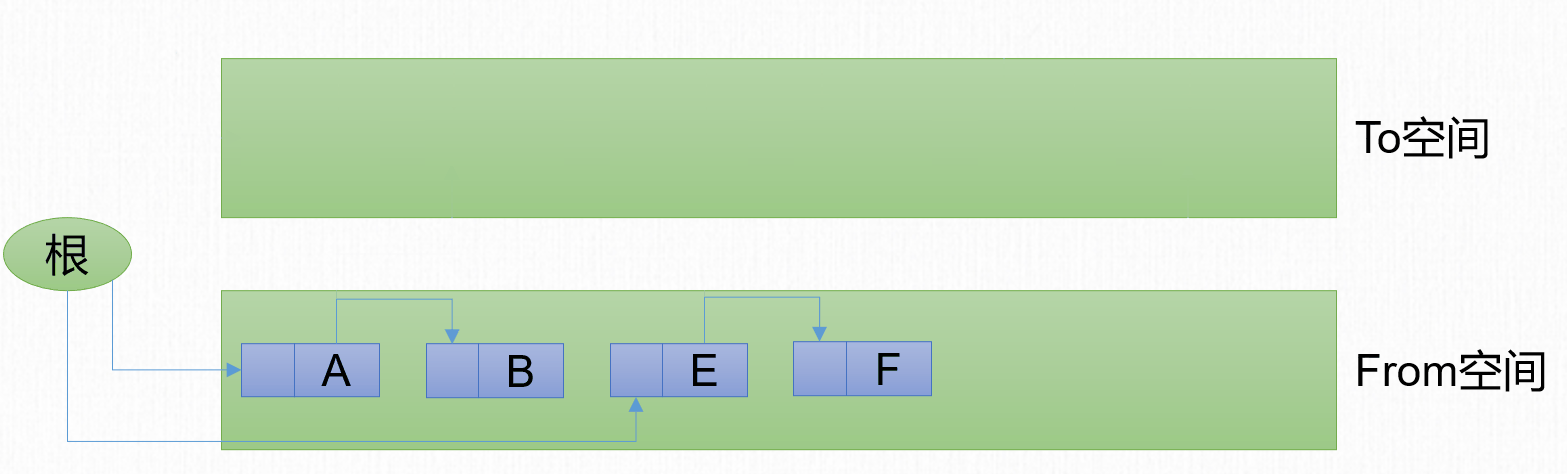
1969年,Fenichel提出了一種稱為「半區複製」(Semispace Copying)的垃圾收集演算法,它將可用記憶體按容量劃分為大小相等的兩塊。一塊稱為From空間,另一塊稱為To空間。將From空間的內容複製到To空間,然後把From空間進行清理。
標記-複製演算法包含3個步驟:
- 劃分區域:將記憶體分為2塊等大的區域。
- 複製:將存活的對象從From區域複製到To區域。
- 清除:將From區域進行整體清除。
- 互換:將From區域和To區域互換。原來的To區域變為新的From區域,原來的From區域變為新的To區域。
回收前記憶體

回收後記憶體

優點
-
無碎片化
從上面的過程可以發現,標記-複製 演算法處理完後,記憶體就處於規整狀態。就不會發生實際可用記憶體足夠,但是卻沒有足夠的記憶體塊分配大對象的情況。
-
對象分配速度快
由於標記-複製演算法不會產生碎片,因此分配對象的邏輯就非常簡單快速。在JVM-對象及其記憶體布局也提到了,當記憶體規整時,可以使用 指針碰撞 的方式快速的分配對象。而無需遍歷空閑鏈表。
-
GC吞吐量高
標記-複製 演算法使用深度優先搜索的方式遍歷每個
GC Roots對象。先將根對象和根對象的所有引用的子對象複製到To區域,再處理下一個根對象。在清理時直接清理整個From區域,無需遍歷整個堆。因此 標記-複製 演算法的效率與堆大小無關,只與存活對象(被GC根引用的對象)數量相關。 -
與快取兼容
標記-複製 演算法會將引用相關的對象按續排放,可以充分利用快取實現高速訪問。
缺點
-
記憶體利用率低
由於 標記-複製 演算法將區域分為兩半,只有一半可以使用,因此會造成記憶體的浪費。相當於使用空間換時間,且空間的成本相對較高。
-
對象移動
標記-複製演算法每次都會移動對象,因此與一些要求對象不移動的GC演算法不兼容。
比如某個地址上存的不是對象地址而是具體的數值時,複製演算法會導致該地址更新為新的值(地址)。
-
遞歸調用
普通的 標記-複製 演算法會遞歸調用子對象重複 標記-複製 操作,就會存在執行新的方法而創建棧幀,增加額外的資源消耗。不過在1970年出現了迭代式的 標記-複製 演算法,解決了這個問題。
優化
- 1970年,C. J. Cheney研究出了迭代式標記-複製GC演算法,優化了傳統遞歸調用導致的資源佔用問題。
- 1991年,Paul R. Wilson、Michael S. Lam和Thomas G. Moher提出的近似深度優先搜索法,解決了迭代式標記-複製GC演算法由於廣度優先搜索策略造成無法重複使用快取的問題。
- 另外還出現了多空間複製演算法,優化了堆使用率。傳統的複製演算法只能利用一半的堆空間。而多空間複製演算法採用組合演算法方式進行垃圾收集,該演算法將堆分為10份,其中2份使用複製演算法,另外8份採用標記-清除演算法。
- 在JVM中,採用的是1989年Andrew Appel針對具備「朝生夕滅」特點的對象,研究出的半區複製分代策略,現在稱為「Appel式回收」。它僅僅使用整個堆中的一小塊使用標記-複製演算法,從而提高記憶體使用率。
標記-整理
標記-複製 演算法解決了 標記-清除 演算法記憶體碎片的問題,但是也同時帶來另一個問題,就是記憶體使用率低的問題。1974年Edward Lueders提出了另外一種有針對性的 標記-整理(Mark-Compact) 演算法(也可以叫標記-壓縮演算法)。
標記-整理 演算法包含2個步驟:
- 標記階段:標記所有可回收的對象。
- 整理階段:分為3個步驟
- 查找新地址
- 更新指針
- 移動對象。
在最基本的 標記-整理 演算法,每個步驟都需要遍歷整個堆。
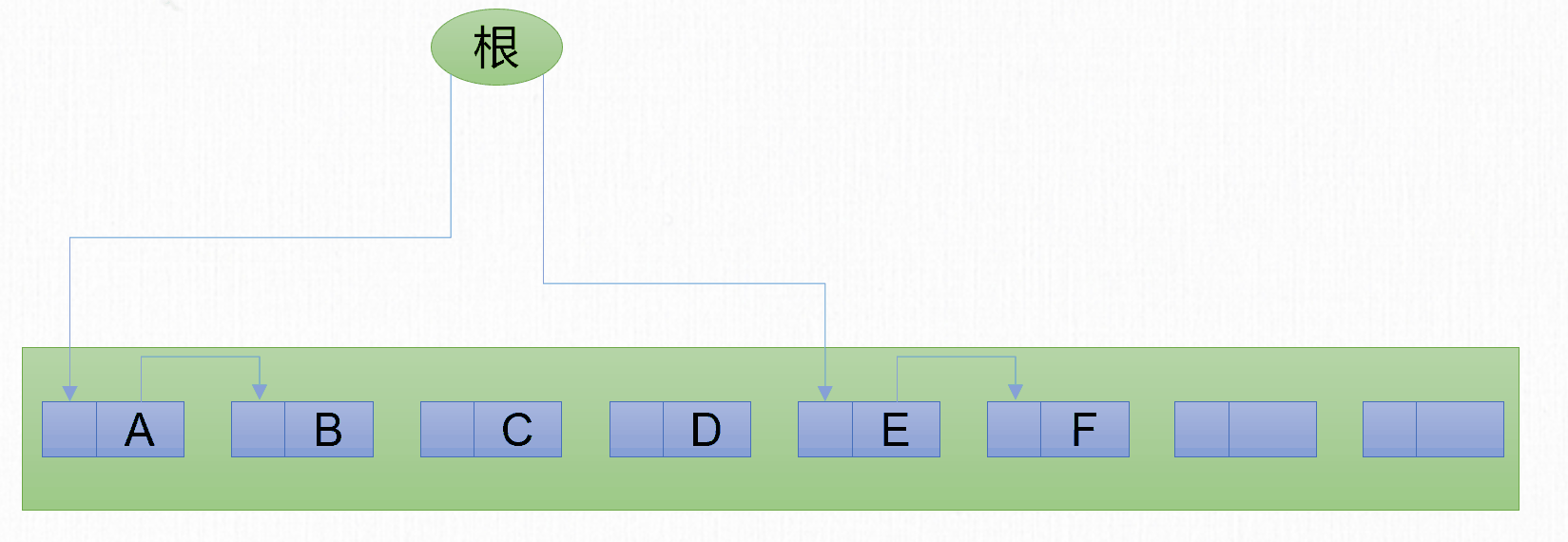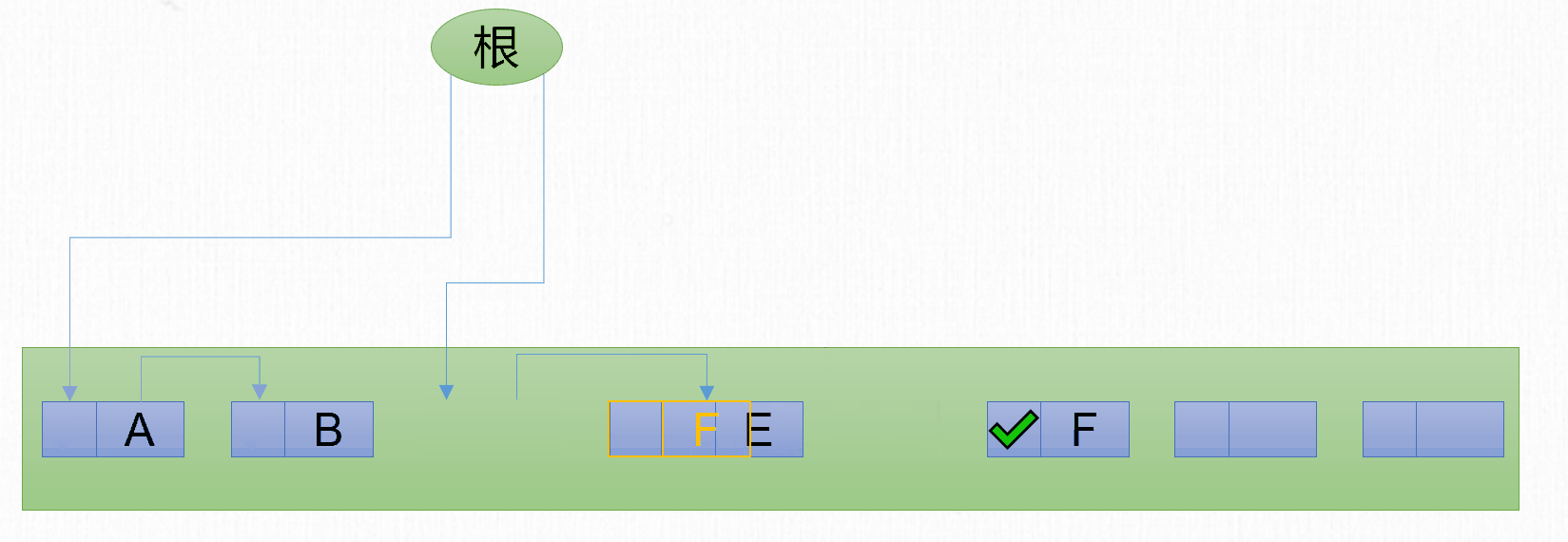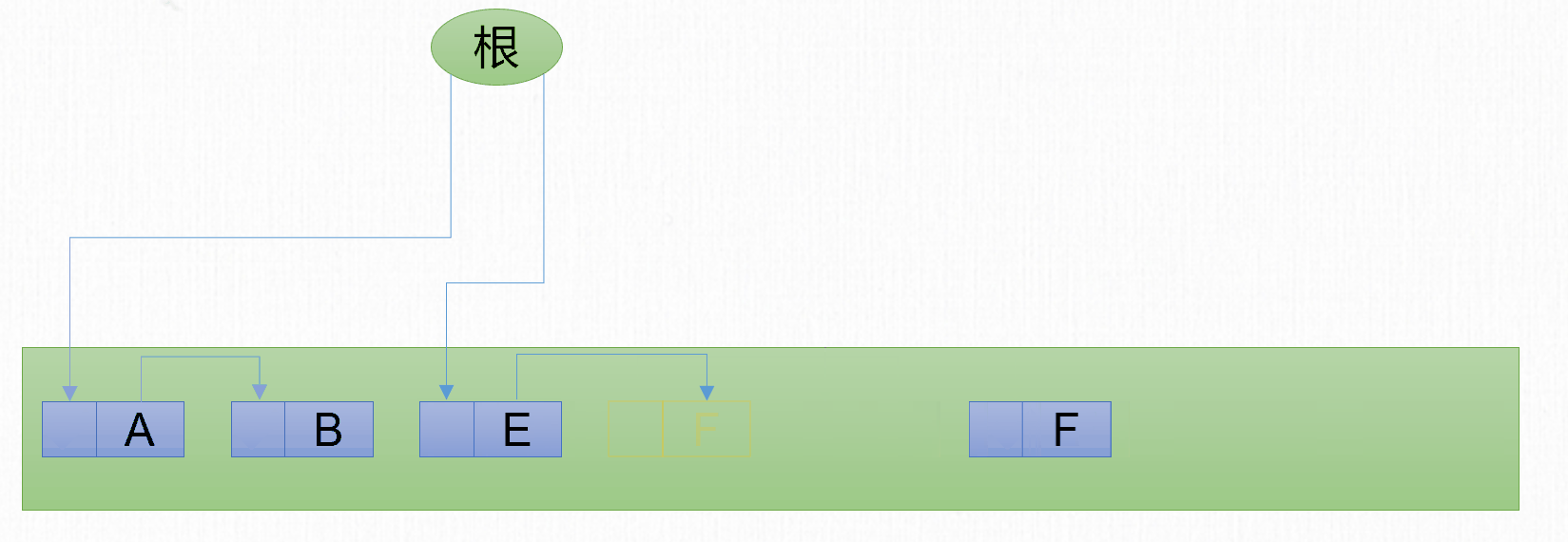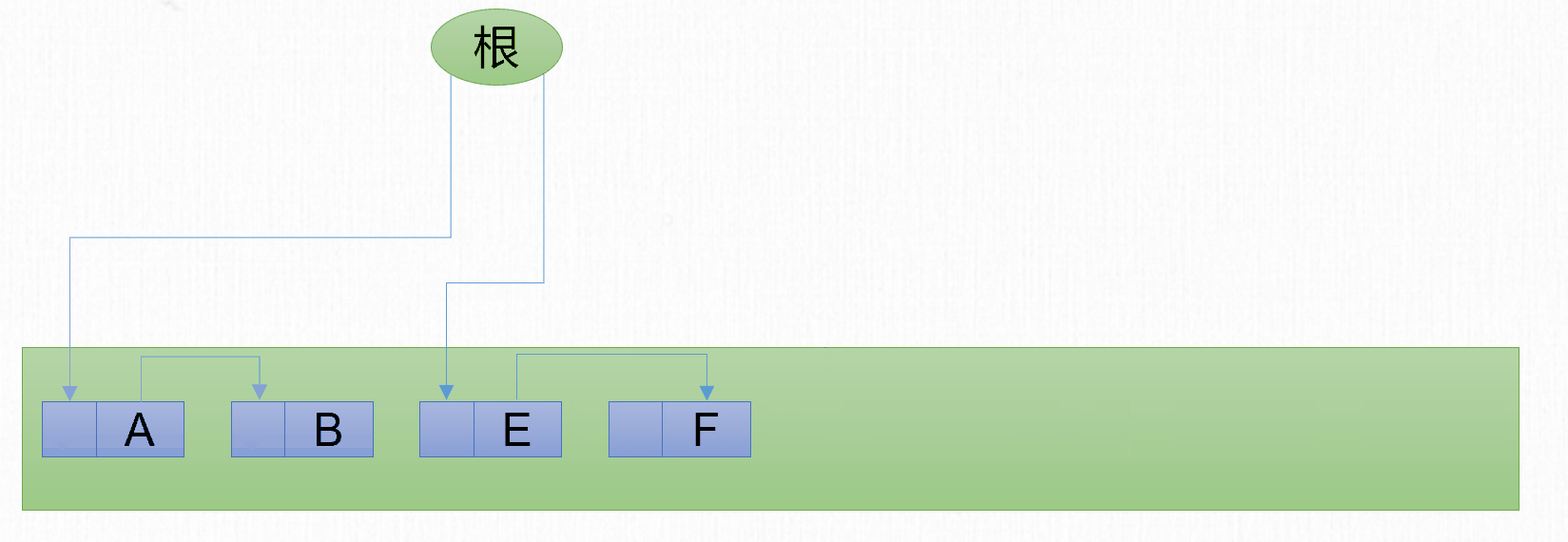
標記-整理 演算法解決了 標記-複製 演算法的空間佔用問題,但是由於整理階段需要遍歷多次堆,因此性能相比其他兩種GC演算法,也會差很多。可以發現每種垃圾回收演算法都有自己的優點和缺點。並不存在一個完美的演算法能夠同時兼顧空間和時間。
回收前記憶體

回收後記憶體

優點
- 堆利用率高
能夠使用全部的堆記憶體。不像 標記-清除 和 標記-複製 演算法只能使用部分堆記憶體。 - 不會產生記憶體碎片
由於 標記-整理 會整理堆,使其變為規整。因此不會產生記憶體碎片,另外對象的分配速度也很快。
缺點
由於整理階段,需要多次遍歷整個堆。因此GC性能較差,甚至可能長時間出現停頓(STW)現象。
優化
- Robert A. Saunders研究出來的名為Two-Finger的壓縮演算法,只需要搜索兩次堆,比傳統的演算法少一次堆的搜索,但是該演算法要求所有對象大小必須一致,且不會按對象原來的順序進行壓縮(無法使用CPU高速快取)。
- B. K. Haddon和W. M. Waite於1967年研究出來的表格演算法,該演算法比較複雜,但是解決了
Two-Finger會導致對象順序改變的問題,可以通過快取提高訪問速度。 - Stephen M. Blackburn和Kathryn S. McKinley於2008年研究出來的ImmixGC演算法,將標記-清除演算法和壓縮組合使用。由於存在標記-清除演算法,因此存在記憶體碎片的情況。另外該演算法堆記憶體分塊處理,在極端情況可能會導致一個塊只能存一個對象導致記憶體使用率不高,另外該演算法在壓縮的時候也不會顧及對象原始順序。
參考文檔
- 《垃圾回收演算法與實現》
- 《深入理解Java虛擬機》
微信掃一掃二維碼關注訂閱號傑哥技術分享
出處://www.cnblogs.com/Jack-Blog/p/14853396.html
作者:傑哥很忙
本文使用「CC BY 4.0」創作共享協議。歡迎轉載,請在明顯位置給出出處及鏈接。


