揭秘有狀態服務上 Kubernetes 的核心技術
- 2021 年 6 月 4 日
- 筆記
- Kubernetes介紹&性能優化系列
背景
隨著 Kubernetes 成為雲原生的最熱門的解決方案,越來越多的傳統服務從虛擬機、物理機遷移到 Kubernetes,各雲廠商如騰訊自研上雲也主推業務通過Kubernetes來部署服務,享受 Kubernetes 帶來的彈性擴縮容、高可用、自動化調度、多平台支援等益處。然而,目前大部分基於 Kubernetes 的部署的服務都是無狀態的,為什麼有狀態服務容器化比無狀態服務更難呢?它有哪些難點?各自的解決方案又是怎樣的?
本文將結合我對 Kubernetes 理解、豐富的有狀態服務開發、治理、容器化經驗,為你淺析有狀態容器化的疑難點以及相應的解決方案,希望通過本文,能幫助你理解有狀態服務的容器化疑難點,並能基於自己的有狀態服務場景能靈活選擇解決方案,高效、穩定地將有狀態服務容器化後跑在 Kubernetes 上,提高開發運維效率和產品競爭力。
有狀態服務容器化挑戰
為了簡化問題,避免過度抽象,我將以常用的 Redis 集群為具體案例,詳解如何將一個 Redis 集群進行容器化,並通過這個案例進一步分析、拓展有狀態服務場景中的共性問題。
下圖是 Redis 集群解決方案 codis 的整體架構圖(引用自 Codis項目)。
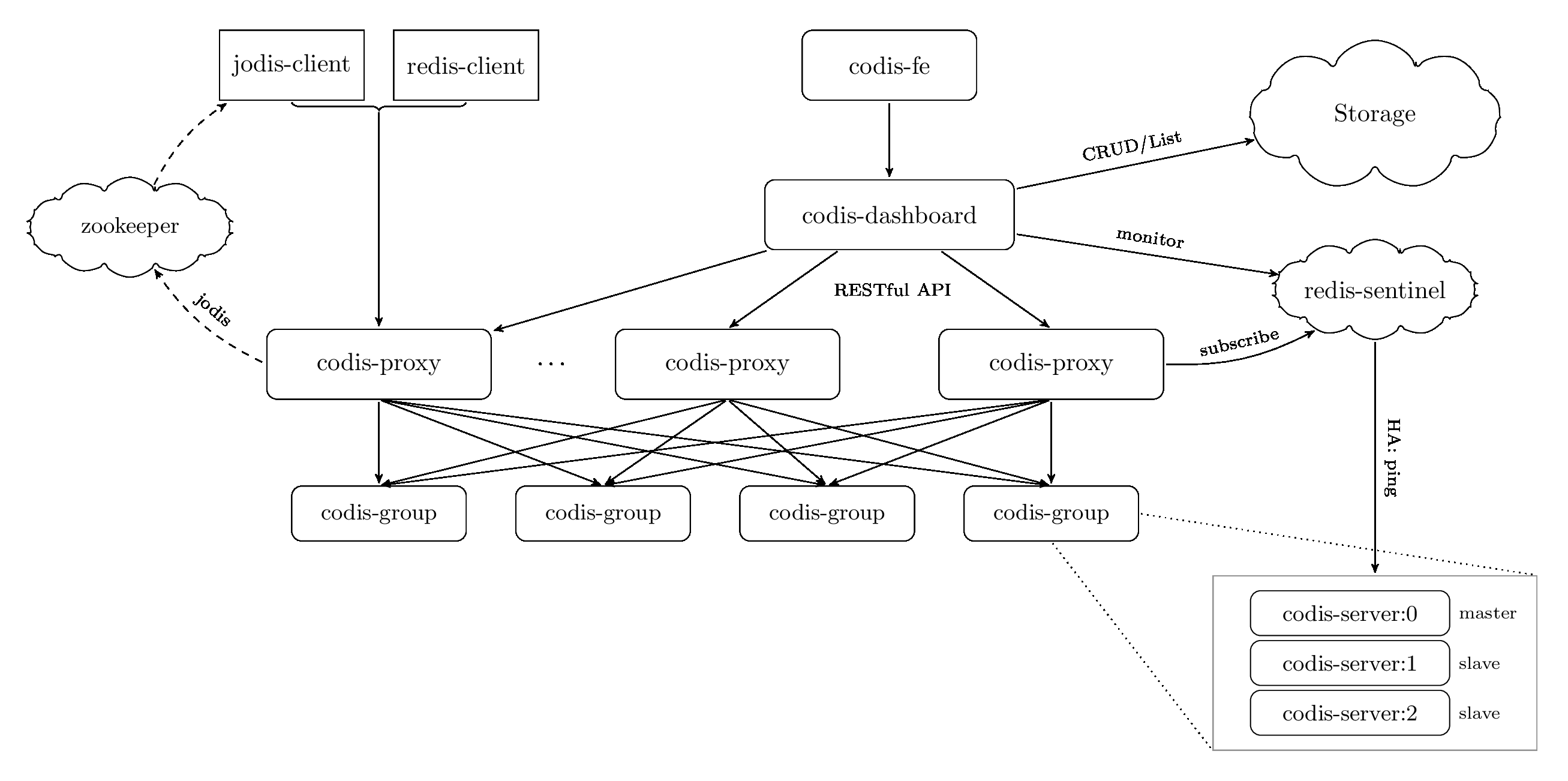
codis 是一個基於 proxy 的分散式 Redis 集群解決方案,它由以下核心組件組成:
- zookeeper/etcd, 有狀態元數據存儲,一般奇數個節點部署
- codis-proxy, 無狀態組件,通過計算 key 的 crc16 哈希值,根據保存在 zookeeper/etcd 內的 preshard 路由表資訊,將key轉發到對應的後端 codis-group
- codis-group 由一組 Redis 主備節點組成,一主多備,負責數據的讀寫存儲
- codis-dashboard 集群控制面API服務,可以通過它增刪節點、遷移數據等
- redis-sentinel,集群高可用組件,負責探測、監聽 Redis 主的存活,主故障時發起備切換
那麼我們如何基於 Kubernetes 容器化 codis 集群,通過 kubectl 操作資源就能一鍵創建、高效管理 codis 集群呢?
在容器化類似 codis 這種有狀態服務案例中,我們需要解決以下問題:
- 如何用 Kubernetes 的語言描述你的有狀態服務?
- 如何為你的有狀態服務選擇合適的 workload 部署?
- 當 kubernetes 內置的 workload 無法直接描述業務場景時,又該選擇什麼樣的 Kubernetes 擴展機制呢?
- 如何對有狀態服務進行安全變更?
- 如何確保你的有狀態服務主備實例 Pod 調度到不同故障域?
- 有狀態服務實例故障如何自愈?
- 如何滿足有狀態服務的容器化後的高網路性能需求?
- 如何滿足有狀態服務的容器化後的高存儲性能需求?
- 如何驗證有狀態服務容器化後的穩定性?
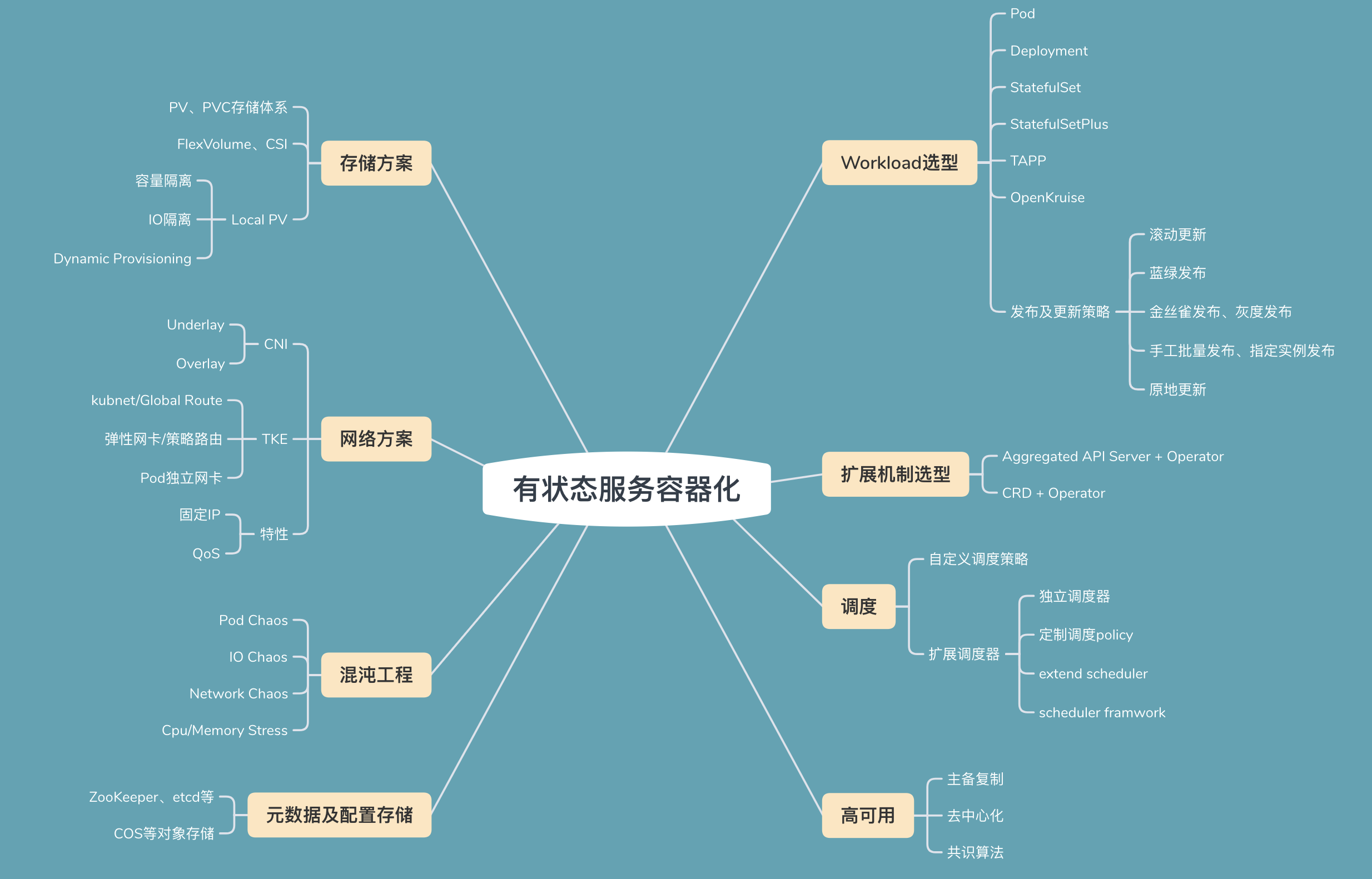
下方是我用思維導圖系統性的梳理了容器化有狀態的服務的技術難點,接下來我分別從以上幾個方面為你闡述容器化的解決方案。
負載類型
有狀態服務的容器化首要問題是如何用 Kubernetes 式的 API、語言來描述你的有狀態服務?
Kubernetes 為複雜軟體世界中的各類業務場景抽象、內置了 Pod、Deployment、StatefulSet 等負載類型(Workload), 那麼各個 Workload 的使用場景分別是什麼呢?
Pod,它是最小的調度、部署單位,由一組容器組成,它們共享網路、數據卷等資源。為什麼 Pod 設計上它是一組容器組成而不是一個呢? 因為在實際複雜業務場景中,往往一個業務容器無法獨立完成某些複雜功能,比如你希望使用一個輔助容器幫助你下載冷備快照文件、做日誌轉發等,得益於 Pod 的優秀設計,輔助容器可以和你的 Redis、MySQL、etcd、zookeeper 等有狀態容器共享同個網路命名空間、數據卷,幫助主業務容器完成以上工作。這種輔助容器在 Kubernetes 裡面叫做 sidecar, 廣泛應用於日誌、轉發、service mesh 等輔助場景,已成為一種 Kubernetes 設計模式。Pod 優秀設計來源於 Google 內部 Borg 十多年運行經驗的總結和升華,可顯著地降低你將複雜的業務容器化的成本。
通過 Pod 成功將業務進程容器化了,然而 Pod 本身並不具備高可用、自動擴縮容、滾動更新等特性,因此為了解決以上挑戰,Kubernetes 提供了更高級的 Workload Deployment, 通過它你可以實現Pod故障自愈、滾動更新、並結合 HPA 組件可實現按 CPU、記憶體或自定義指標實現自動擴縮容等高級特性,它一般是用來描述無狀態服務場景的,因此特別適合我們上面討論的有狀態集群中的無狀態組件,比如 codis 集群的 proxy 組件等。
那麼 Deployment 為什麼不適合有狀態呢?主要原因是 Deployment 生成的 Pod 名稱是變化、無穩定的網路標識身份、無穩定的持久化存儲、滾動更新中過程中也無法控制順序,而這些對於有狀態而言,是非常重要的。一方面有狀態服務彼此通過穩定的網路身份標識進行通訊是其高可用、數據可靠性的基本要求,如在 etcd 中,一個日誌提交必須要經過集群半數以上節點確認並持久化,在 Redis 中,主備根據穩定的網路身份建立主從同步關係。另一方面,不管是 etcd 還是 Redis 等其他組件,Pod 異常重建後,業務往往希望它對應的持久化數據不能丟失。
為了解決以上有狀態服務場景的痛點,Kubernetes 又設計實現了 StatefulSet 來描述此類場景,它可以為每個 Pod 提供唯一的名稱、固定的網路身份標識、持久化數據存儲、有序的滾動更新發布機制。基於 StatefulSet 你可以比較方便的將 etcd、zookeeper 等組件較單一的有狀態服務進行容器化部署。
通過 Deployment、StatefulSet 我們能將大部分現實業務場景的服務進行快速容器化,但是業務訴求是多樣化的,各自的技術棧、業務場景也是迥異的,有的希望實現 Pod 固定IP的,方便快速對接傳統的負載均衡,有的希望實現發布過程中,Pod不重建、支援原地更新的,有的希望能指定任意 Statefulset Pod 更新的,那麼 Kubernetes 如何滿足多樣化的訴求呢?
擴展機制
Kubernetes 設計上對外提供了一個強大擴展體系,如下圖所示(引用自 kubernetes blog),從 kubectl plugin 到 Aggreated API Server、再到 CRD、自定義調度器、再到 operator、網路插件(CNI)、存儲插件(CSI)。一切皆可擴展,充分賦能業務,讓各個業務可基於Kubernetes擴展機制進行訂製化開發,滿足大家的特定場景訴求。
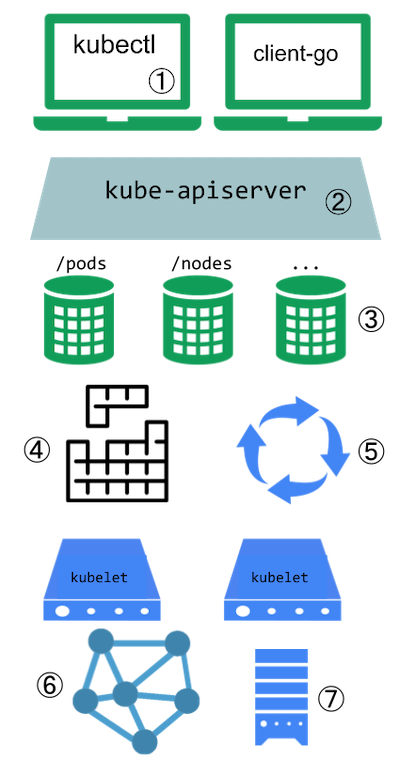
CRD 和 Aggreated API Server
當你遇到 Deployment、StatefulSet 無法滿足你訴求的時候,Kubernetes 提供了 CRD 和 Aggreated API Server、Operator 等機制給你擴展 API 資源、結合你特定的領域和應用知識,實現自動化的資源管理和運維任務。
CRD 即 CustomResourceDefinition,是 Kubernetes 內置的一種資源擴展方式,在 apiserver 內部集成了 kube-apiextension-server, 不需要在 Kubernetes 集群運行額外的 Apiserver,負責實現 Kubernetes API CRUD、Watch 等常規API操作,支援 kubectl、認證、授權、審計,但是不支援 SubResource log/exec 等訂製,不支援自定義存儲,存儲在 Kubernetes 集群本身的 etcd 上,如果涉及大量 CRD 資源需要存儲則對 Kubernetes 集群etcd 性能有一定的影響,同時限制了服務從不同集群間遷移的能力。
Aggreated API Server,即聚合 ApiServer, 像我們常用的 metrics-server 屬於此類,通過此特性 Kubernetes 將巨大的單 apiserver 按資源類別拆分成多個聚合 apiserver, 擴展性進一步加強,新增API無需依賴修改 Kubernetes 程式碼,開發人員自己編寫 ApiServer 部署在 Kubernetes 集群中, 並通過 apiservice 資源將自定義資源的 group name 和 apiserver 的 service name 等資訊註冊到 Kubernetes 集群上,當 Kubernetes ApiServer 收到自定義資源請求時,根據 apiservice 資源資訊轉發到自定義的 apiserver, 支援 kubectl、支援配置鑒權、授權、審計,支援自定義第三方 etcd 存儲,支援 subResource log/exec 等其他高級特性訂製化開發。
總體來說,CRD提供了簡單、無需任何編程的擴展資源創建、存儲能力,而 Aggreated API Server 提供了一種機制,讓你能對 API 行為有更精細化的控制能力,允許你自定義存儲、使用 Protobuf 協議等。
增強型 Workload
為了滿足業務上述的原地更新、指定Pod更新等高級特性需求,騰訊內部及社區都提供了相應的解決方案。騰訊內部有經過大規模生產環境檢驗的 StatefulSetPlus(未開源的)和 tkestack TAPP(已開源),社區也還有有阿里的開源項目 Openkruise,pingcap 為了解決 StatefulSet 指定 Pod 更新問題也推出了一個目前還處於試驗狀態的 advanced-statefulset 項目。
StatefulSetPlus 是為了滿足騰訊內部大量傳統業務上 Kubernetes 而設計的, 它在兼容 StatefulSet 全部特性的基礎上,支援容器原地升級,對接了 TKE 的 ipamd 組件,實現了固定IP,支援 HPA,支援 Node 不可用時,Pod 自動漂移實現自愈,支援手動分批升級等特性。
Openkruise 包含一系列 Kubernetes 增強型的控制器組件,包括 CloneSet、Advanced StatefulSet、SideCarSet等,CloneSet 是個專註解決無狀態服務痛點的 Workload,支援原地更新、指定 Pod 刪除、滾動更新過程中支援Partition, Advanced StatefulSet 顧名思義,是個加強版的 StatefulSet, 同時支援原地更新、暫停和最大不可用數。
使用增強版的 workload 組件後,你的有狀態服務就具備了傳統虛擬機、物理機部署模式下的原地更新、固定IP等優越特性。不過,此時你是直接基於 StatefulSetPlus、TAPP 等 workload 容器化你的服務還是基於 Kubernetes 擴展機制定義一個自定義資源, 專門用於描述你的有狀態服務各個組件,並基於 StatefulSetPlus、TAPP 等workload 編寫自定義的 operator 呢?
前者適合於簡單有狀態服務場景,它們組件少、管理方便,同時不需要你懂任何 Kubernetes 編程知識,無需開發。後者適用於較複雜場景,要求你懂 Kubernetes 編程模式,知道如何自定義擴展資源、編寫控制器。 你可以結合你的有狀態服務領域知識,基於 StatefulSetPlus、TAPP 等增強型 workload 編寫一個非常強大的控制器,幫助你一鍵完成一個複雜的、多組件的有狀態服務創建和管理工作,並具備高可用、自動擴縮容等特性。
基於 operator 擴展
在我們上文的 codis 集群案例中,就可以選擇通過 Kubernetes 的 CRD 擴展機制,自定義一個 CRD 資源來描述一個完整的 codis 集群,如下圖所示。

通過 CRD 實現聲明式描述完你的有狀態業務對象後,我們還需要通過 Kubernetes 提供的 operator 機制來實現你的業務邏輯。Kubernetes operator 它的核心原理就是控制器思想,從 API Server 獲取、監聽業務對象的期望狀態、實際狀態,對比期望狀態與實際狀態的差異,執行一致性調諧操作,使實際狀態符合期望狀態。
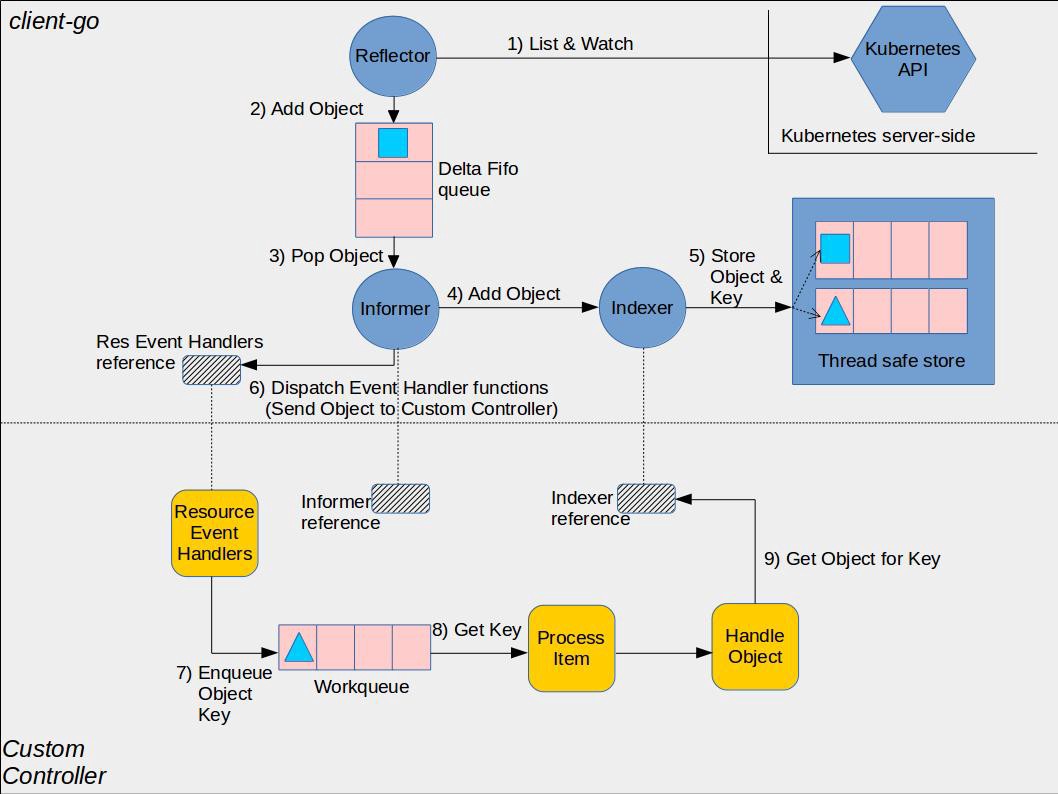
它的核心工作原理如上圖(引用自社區)所示。
- 通過 Reflector 組件的 List 操作,從 kube-apiserver 獲取初始狀態數據(CRD等)。
- 從 List 請求返回結構中獲取資源的 ResourceVersion,通過 Watch 機制指定 ResourceVersion 實時監聽 List之後的數據變化。
- 收到事件後添加到 Delta FIFO 隊列,由 Informer 組件進行處理。
- Informer 將 delta FIFO 隊列中的事件轉發給 Indexer 組件,Indexer 組件將事件持久化存儲在本地的快取中。
- operator開發者可通過 Informer 組件註冊 Add、Update、Delete 事件的回調函數。Informer 組件收到事件後會回調業務函數,比如典型的控制器使用場景,一般是將各個事件添加到 WorkQueue 中,operator 的各個協調 goroutine 從隊列取出消息,解析 key,通過 key 從 Informer 機制維護的本地 Cache 中讀取數據。
- 比如當收到創建一個 Codis CRD 對象的事件後,發現實際無這個對象相關的 Deployment/TAPP 等組件在運行,這時候你就可以通過的 Deployment API 創建 proxy 服務,TAPP API創建Redis服務等。
調度
在解決完如何基於 Kubernetes 內置的 workload 和其擴展機制描述、承載你的有狀態服務後,你面臨的第二個問題就是如何確保有狀態服務中「等價」Pod跨故障域部署,確保有狀態服務的高可用性?
首先如何理解「等價」 Pod 呢? 在 codis、TDSQL 集群中,一組 Redis/MySQL 主備實例,負責處理同一個數據分片的請求,通過主備實現高可用。因主備實例 Pod 負責的是同數據分片,因此我們稱之為等價 Pod,生產環境期望它們應跨故障域部署。
其次如何理解故障域?故障域表示潛在的故障影響範圍,可按範圍分為主機級、機架級、交換機級、可用區級等。一組 Redis 主備案例,至少應該實現主機級高可用,任意一個分片所在的主實例所在的節點故障,備實例應自動提升為主,整個 Redis 集群所有分片仍可提供服務。同樣,在 TDSQL 集群中,一組 MySQL 實例,至少應該實現交換機、可用區級別容災,以確保核心的存儲服務高可用。
那麼如何實現上面所述等價 Pod 跨故障域部署呢?
答案是調度。 Kubernetes 內置的調度器可根據你的Pod所需資源和調度策略,自動化的將 Pod 分配到最佳節點,同時它還提供了強大的調度擴展機制,讓你輕鬆實現自定義調度策略。一般情況下,在簡單的有狀態服務場景下,你可以基於 Kubernetes 提供的親和和反親和高級調度策略,實現 Pod 跨故障域部署。
假設希望通過容器化、高可用部署一個含三節點的 etcd 集群,故障域為可用區,每個etcd節點要求分布在不同可用區節點上,我們如何基於 Kubernetes 提供的親和 (affinity) 和反親和 (anti affinity) 特性實現跨可用區部署呢?
親和與反親和
很簡單,我們可以通過給部署 etcd 的 workload 添加如下的反親和性配置,聲明目的 etcd 集群 Pod 的標籤,拓撲域為 node 可用區,同時是硬親和規則,若 Pod不 滿足規則將無法調度。
那麼調度器又遇到被添加了反親和配置的 Pod 後是如何調度的呢?
affinity:
PodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: etcd_cluster
operator: In
values: ["etcd-test"]
topologyKey: failure-domain.beta.Kubernetes.io/zone
首先調度器監聽到 etcd workload 生成的的待調度 Pod 後,通過反親和配置中的標籤查詢出已調度 Pod 的節點、可用區資訊,然後在調度器的篩選階段,若候選節點可用區與已調度 Pod 可用區一致,則淘汰,最後進入評優階段的節點都是滿足 Pod 跨可用區部署等條件限制的節點,根據調度器配置的評優策略,選擇出一個最優節點,將 Pod 綁定到此節點上,最終實現 Pod 跨可用區部署、容災。
然而在 codis 集群、TDSQL 分散式集群等複雜場景中,Kubernetes 自帶的調度器可能就無法滿足你的訴求了,但是它提供了如下的擴展機制幫助你自定義調度策略,實現各種複雜場景的調度訴求。
自定義調度策略、extend scheduler 等
首先你可以修改調度器的篩選/斷言 (predicates) 和評分/優先順序 (priorities) 策略, 配置滿足你業務訴求的調度策略。比如你希望降低成本,用最小的節點數支撐集群所有服務,那麼我們需要讓 Pod 盡量優先往滿足其資源訴求、已分配資源較多的節點上調度。 此場景,你就可以通過修改 priorities 策略,配置 MostRequestedPriority 策略,調大權重。
然後你可以基於 Kubernetes 調度器實現 extend scheduler, 在調度器的 predicates 和 priorities 階段,回調你的擴展調度服務,已滿足你的調度訴求。比如你希望負責同一個數據分片的一組 MySQL 或 Redis 主備實例實現跨節點容災,那麼你就可以實現自己的predicates 函數,將同組已調度 Pod 的節點從候選節點中刪除,保證進入 priorities 流程的節點都是滿足你業務訴求的。
接著你可以基於 Kubernetes 的調度器實現自己獨立的調度器,部署獨立的調度器到集群後,你只需要通過將 Pod的 schedulerName 聲明為你獨立的調度器即可。
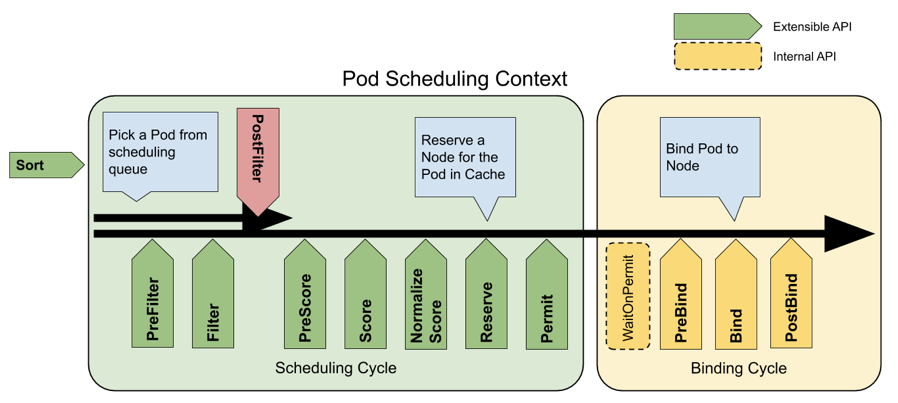
scheduler framwork
最後 Kubernetes 在1.15版本中推出了一個新的調度器擴展框架,它在調度器的核心流程前後都增加了 hook。選擇待調度 Pod,支援自定義排隊演算法,篩選流程提供了 PreFilter 和 Filter 介面,評分流程增加了 PreScore,Score,NormalizeScore 等介面,綁定流程提供 PreBind 和 Bind,PostBind 三個介面。基於新的調度器擴展框架,業務可更加精細化、低成本的控制調度策略,自定義調度策略更加簡單、高效。
高可用
解決完調度問題後,我們的有狀態服務已經可以高可用的部署了。然而高可用部署不代表服務能高可用的對外的提供服務,容器化後我們也許會遇到比傳統物理機、虛擬機模式部署更多的穩定性挑戰。穩定性挑戰可能來自業務編寫的 operator、Kubernetes 組件、docker/containerd 等運行時組件、linux 內核等,那如何應對以上各種因素導致的穩定性問題呢?
我們在設計上應把 Pod 異常當作常態化案例處理,任一 Pod 異常後,在容器化場景中,我們應當具備自愈的機制。若是無狀態服務,我們只需為業務Pod添加合理的存活和就緒檢查即可,Pod 異常後自動重建,節點故障 Pod 自動漂移到其他節點。然而在有狀態服務場景中,即便承載你有狀態服務的 workload,支援節點故障後 Pod 自動漂移功能,卻也可能會因 Pod 自愈時間過長和數據安全性等無法滿足業務訴求,為什麼呢?
假設在 codis 集群中,一個 Redis 主節點所在node突然」失聯「了,此時若等待5分鐘才進入自愈流程,那麼對外將造成5分鐘的不可用性, 顯然對重要的有狀態服務場景是無法接受的。即便你縮小節點失聯自愈時間,你也無法保證其數據安全性,萬一此時集群網路出現了腦裂,失聯節點也在對外提供服務,那麼將出現多個 master 雙寫,最終可能導致數據丟失。
那麼有狀態的服務安全的高可用解決方案是什麼呢? 這取決於有狀態服務本身高可用實現機制,Kubernetes 容器平台層是無法提供安全的解決方案。常用的有狀態服務高可用解決方案有主備複製、去中心化複製、raft/paxos 等共識演算法,下面我分別簡易闡述三者的區別和優劣勢,以及介紹在容器化過程中的注意事項。
主備複製
像我們上面討論的 codis 集群案例、TDSQL 集群案例都是基於主備複製實現的高可用,實現上相比去中心化複製、共識演算法較簡單。主備複製又可分為主備全同步複製、非同步複製、半同步複製。
全同步複製是指主收到一個寫請求後,必須等待全部從節點確認返回後,才能返回給客戶端成功,因此若一個從節點故障,整個系統就會不可用,這種方案為了保證多副本集的一致性,而犧牲了可用性,一般使用不多。
非同步複製是指主收到一個寫請求後,可及時返回給 client,非同步將請求轉發給各個副本, 但是若還未將請求轉發到副本前就故障了,則可能導致數據丟失,但可用性是最高的。
半同步複製介於全同步複製、非同步複製之間,它是指主收到一個寫請求後,至少有一個副本接收數據後,就可以返回給客戶端成功,在數據一致性、可用性上實現了平衡和取捨。
基於主備複製模式實現的有狀態服務,業務需要實現、部署主備切換的 HA 服務,HA服務按實現架構,可分為主動上報型和分散式探測型。主動上報型以 TDSQL 中 MySQL 主備切換為例,各個 MySQL 節點上部署有 agent, 向元數據存儲集群 (zookeeper/etcd) 上報心跳,若 master 心跳丟失, HA 服務將快速發起主備切換。分散式探測型以 Redis sentinel 為例,部署奇數個哨兵節點,各個哨兵節點定時探測Redis主備實例的可用性,彼此之間通過 gossip 協議交互探測結果,若對一個主 Redis 節點故障達到多數派認可,那麼就由其中一個哨兵發起主備切換流程。
總體來說,基於主備複製的有狀態服務,在傳統的部署模式,節點故障後,依賴運維、人工替換節點。容器化後的有狀態服務,可通過 operator 實現故障節點自動替換、快速垂直擴容等特性,顯著降低運維複雜度,但是 Pod 可能會發生重建等,應部署負責主備切換的HA服務,負責主備 Pod 的切換,以提高可用性。若業務對數據一致性非常敏感,較頻繁的切換的可能會導致增大丟失數據的概率,可通過使用 dedicated 節點、穩定及較新的運行時和Kubernetes 版本等減少不穩定因素。
去中心化複製
跟主從複製相反的就是去中心化複製,它是指在一個n副本節點集群中,任意節點都可接受寫請求,但一個成功的寫入需要w個節點確認,讀取也必須查詢至少r個節點。你可以根據實際業務場景對數據一致性的敏感度,設置合適w/r參數。比如你希望每次寫入後,任意client都能讀取到新值,若n是3個副本,你可以將w和r設置為2,這樣當你讀兩個節點時候,必有一個節點含有最近寫入的新值,這種讀我們稱之為法定票數讀 (quorum read)。
AWS 的 dynamo 系統就是基於無中心化的複製演算法實現的,它的優點是節點角色都是平等的,降低運維複雜度,可用性更高,容器化難度更低,無需部署HA組件等,但缺陷是去中心化複製,務必會導致各種寫入衝突,業務需要關注衝突處理等。
共識演算法
基於複製演算法實現的資料庫,為了保證服務可用性,大多數提供的是最終一致性,不管是主從複製還是去中心化複製,都存在一定的缺陷,無法滿足數據強一致、高可用的訴求。
如何解決以上複製演算法的困境呢?
答案就是 raft/paxos 共識演算法,它最早是基於複製狀態機背景下提出來的,由共識模組、日誌模組、狀態機組成, 如下圖(引用自 Raft 論文)。通過共識模組保證各個節點日誌的一致性,然後各個節點基於同樣的日誌、順序執行指令,最終各個複製狀態機的結果是一致性的。這裡我以 raft 演算法為例,它由 leader 選舉、日誌複製、安全性組成,leader 節點故障後,follower 節點可快速發起新的 leader 選舉,並確保數據安全性,follwer 節點故障後,只要多數節點存活,就不影響集群整體可用性。
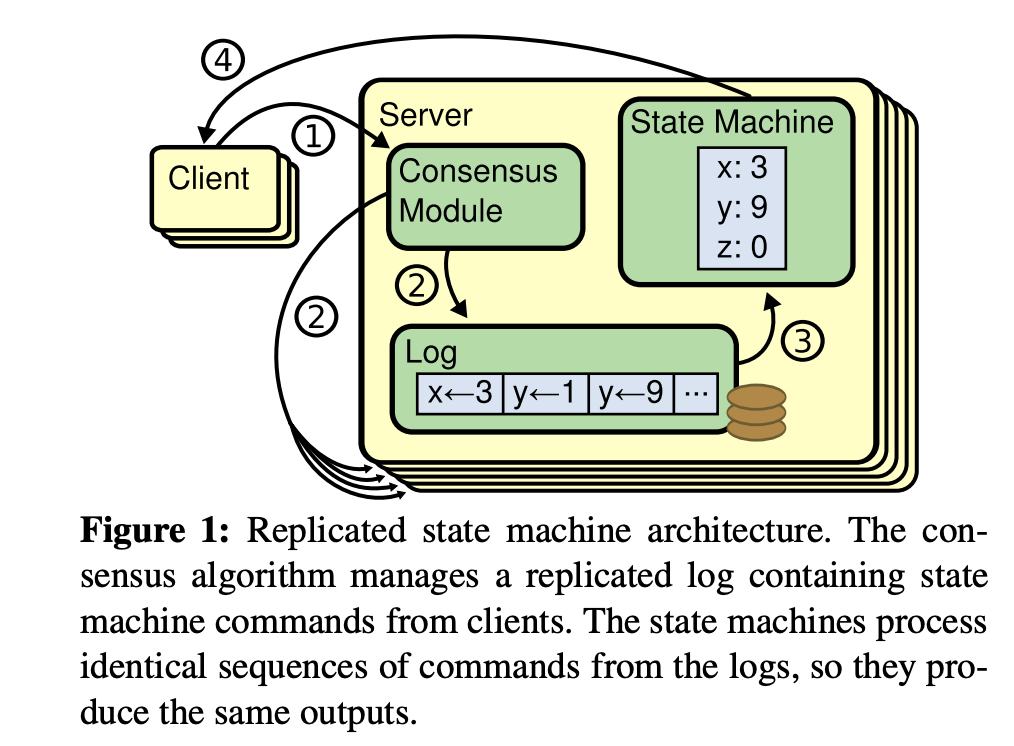
基於共識演算法實現的有狀態服務,典型案例是 etcd/zookeeper/tikv 等,在此架構中,服務本身集成了 leader 選舉演算法、數據同步機制,使得運維和容器化複雜度相比主備複製的服務要顯著降低,容器化更加安全。即便容器化過程中遇上 Bug 導致 leader 節點故障,得益於共識演算法,數據安全和服務可用性幾乎不受任何影響,因此優先推薦將使用共識演算法的有狀態服務進行容器化。
高性能
實現完有狀態服務在 Kubernetes 中更穩的運行的目標後,下一步目標則是追求高性能、更快,而有狀態服務的高能又依託底層容器化網路方案、磁碟 IO 方案。在傳統的物理機、虛擬機部署模式中,有狀態服務擁有固定的IP、高性能的 underlay 網路、高性能的本地 SSD 磁碟,那麼在容器化後,如何達到傳統模式的性能呢? 我將分別從網路和存儲分別簡易闡述 Kubernetes 的解決方案。
可擴展的網路解決方案
首先是可擴展、插件化的網路解決方案。得益於 Google 多年的 Borg 容器化運行經驗和教訓,在 Kubernetes 的網路模型中,每個 Pod 擁有獨立的IP,各個 Pod 可以跨主機通訊而需NAT, 同時 Pod 也可以與 Node 節點實現網路互通。Kubernetes 優秀的網路模型良好的兼容了傳統的物理機、虛擬機業務的網路方案,讓傳統業務上Kubernetes 更加簡單。最重要的是,Kubernetes 提供了開放的 CNI 網路插件標準,它描述了如何為 Pod 分配 IP和實現 Pod 跨節點容器互通,各個開源、雲廠商可以基於自己業務業務場景、底層網路,實現高性能、低延遲的CNI插件,最終達到跨節點容器互通。
在基於 CNI 實現的各種 Kubernetes 的網路解決方案中,按數據包的收發模式實現可分為 underlay 和 overlay 兩類。前者是直接基於底層網路,實現互聯互通,擁有良好的性能,後者是基於隧道轉發,它是在底層網路的基礎上,加上隧道技術,構建一個虛擬的網路,因此存在一定的性能損失。
這裡我分別以開源的 flannel 和 tke 集群網路方案為例,闡述各自的解決方案、優缺點。
在 flannel 中,它設計上後端支援 udp、vxlan、host-gw 等多種轉發模式。udp 和 vxlan 轉發模式是基於 overlay隧道轉發模式實現,它支援將原始請求封裝在 udp、vxlan 數據包內,然後基於 underlay 網路轉發給目的容器。udp 是在用戶態進行數據的封解包操作,性能較差,一般用於debug和不支援 vxlan 協議的低版本內核。vxlan 是在內核態完成了數據的封解包操作,性能損失較小。host-gw 模式則是直接通過下發每個子網的IP路由資訊到各個節點上,實現跨主機的 Pod 網路通訊,無需數據包的封解包操作,相比 udp/vxlan,性能最佳,但要求各主機節點的二層網路是連通的。
在tke集群網路方案中,我們也支援多種網路通訊方案,經歷了從 global route、VPC-CNI 到 Pod 獨立網卡的三種模式的演進。global route 即全局路由,每個節點加入集群時,會分配一個唯一的 Pod cidr, tke 會通過 VPC 的介面下發全局路由到用戶 VPC 的子機所在的母機上。當用戶 VPC 的容器、節點訪問的ip屬於此 Pod cir 時,就會匹配到此全局路由規則,轉發到目標節點上。此方案中 Pod CIDR 並不屬於VPC資源,因此它不是 VPC 的一等公民,無法使用 VPC 的安全組等特性,但是其簡單、同時在用戶VPC層不需要任何的數據解封包操作,性能無較大的損失。
為了解決容器 Pod IP 不是 VPC 一等公民而導致一系列 VPC 特性無法使用的問題,tke 集群實現了 VPC-CNI 網路模式,Pod IP 來自用戶 VPC 的子網,跨節點容器網路通訊、節點與容器通訊與 VPC 內的 CVM 節點通訊原理一致,底層都是基於 VPC 的 GRE 隧道路由轉發實現,數據包在節點內通過策略路由轉發到目標容器。基於此方案,容器 Pod IP 可享受 VPC 的特性,實現CLB直連Pod,固定IP等一系列高級特性。
近期為了滿足遊戲、存儲等業務對容器網路性能更加極致的要求,TKE 團隊又推出了下一代網路方案,Pod 獨佔彈性網卡的 VPC-CNI 模式,不再經過節點的網路協議棧,極大縮短容器訪問鏈路和延時,並使 PPS 可以達到整機上限。基於此方案我們實現了 Pod 綁定 EIP/NAT,不再依賴節點的外網訪問能力,支援 Pod 綁定安全組,實現Pod級別的安全隔離,詳細可閱讀文章末尾的相關文章。
基於 Kubernetes 的可擴展網路模型,業務可以實現特定場景的高性能網路插件。比如騰訊內部的 tenc 平台,基於 SR-IOV 技術的實現了 sriov-cni CNI 插件,它可以給 Kubernetes 提供高性能的二層VLAN網路解決方案。特別是對網路性能要求高的場景,比如分散式機器學習訓練,遊戲後端服務等。
可擴展的存儲解決方案
介紹完可擴展的網路解決方案後,有狀態服務的另一大核心瓶頸則是高性能存儲IO訴求。 在傳統的部署模式中,有狀態服務一般使用的是本地硬碟,並根據服務的類型、規格、對外的 SLA,選擇 HDD、SSD 等不同類型的磁碟。 那麼在 Kubernetes 中如何滿足不同場景下的存儲訴求呢?
在 Kubernetes 存儲體系中,此問題被拆分成若干個子問題來優雅解決,並具備良好的可擴展性、可維護性,無論是本地盤、還是雲盤、NFS等文件系統都可基於其擴展實現相應的插件, 並實現了開發、運維職責分離。
那麼 Kubernetes 的存儲體系是如何構建的呢?
我通過如何給你的有狀態Pod應用掛載一個數據存儲盤為案例,來介紹 Kubernetes 的可擴展存儲體系,它可以分為以下步驟:
-
應用如何申請一個存儲盤呢?(消費者)
-
Kubernetes 存儲體系是如何描述一個存儲盤的呢?人工創建存儲盤呢還是自動化按需創建存儲盤?(生產者)
-
如何將存儲資源池的盤與存儲盤申請者的訴求進行匹配?(控制器)
-
如何描述存儲盤的類型、數據刪除策略、以及此類型盤的服務提供者資訊呢?(storageClass)
-
如何實現對應的存儲數據卷插件?(FlexVolume、CSI)
首先 Kubernetes 中提供了一個名為PVC的資源,描述應用申請的存儲盤的類型、訪問模式、容量規格,比如你想給etcd服務申請一個存儲類為cbs, 大小100G的雲盤,你可以創建一個如下的PVC。
apiVersion: v1
kind: PersistentVolumeClaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: cbs
其次 Kubernetes 中提供了一個名為 PV 的資源,描述存儲盤的類型、訪問模式、容量規格,它對應一塊真實的磁碟,支援通過人工和自動創建兩種模式。下圖描述的是一個 100G 的 cbs 硬碟。
apiVersion: v1
kind: PersistentVolume
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 100Gi
persistentVolumeReclaimPolicy: Delete
qcloudCbs:
cbsDiskId: disk-r1z73a3x
storageClassName: cbs
volumeMode: Filesystem
接著,當應用創建一個 PVC 資源時,Kubernetes 的控制器就會嘗試將其與PV進行匹配,存儲盤的類型是否一致、PV的容量大小是否滿足 PVC 的訴求,若匹配成功,此 PV 的狀態會變成綁定, 控制器會進一步的將此PV對應的存儲資源attach到應用 Pod 所在節點上,attach 成功後,節點上的 kubelet 組件會將對應的數據目錄掛載到存儲盤上,進而實現讀寫。
以上就是應用申請一個盤的流程,那麼在容器中如何通過 PV/PVC 這套體系實現支援多種類型的塊存儲和網路文件系統呢?比如塊存儲服務支援普通 HHD 雲盤,SSD 高性能雲盤,SSD 雲盤,本地盤等,遠程網路文件系統支援NFS等。其次是Kubernetes控制器如何按需動態的去創建PV呢?
為了支援多種類型的存儲訴求,Kubernetes 提供了一個 StorageClass 的資源來描述一個存儲類。它描述了存儲盤的類別、綁定和刪除策略、由什麼服務組件提供資源創建。比如高性能版和基礎版的 MySQL 服務依賴不同類型的存儲磁碟,你只需要創建 PVC 的時候填寫相應的 storageclass 名字即可。
最後,Kubernetes 為了支援開源社區、雲廠商眾多的存儲數據卷,提供了存儲數據卷擴展機制,從早期的 in-tree 的內置數據卷、到 FlexVolume 插件、再到現在已經 GA 的的容器化存儲 CSI 插件機制, 存儲服務提供商可將任意的存儲系統集成到Kubernetes存儲體系中。比如 storage cbs 的 provisioner 是騰訊雲的 TKE 團隊,我們會基於 Kubernetes 的 flexvolume/CSI 擴展機制,通過騰訊雲 CBS 的 API 實現創建、刪除cbs硬碟。
apiVersion: storage.Kubernetes.io/v1
kind: StorageClass
parameters:
type: cbs
provisioner: cloud.tencent.com/qcloud-cbs
reclaimPolicy: Delete
volumeBindingMode: Immediate
為了滿足有狀態等服務對磁碟IO性能的極致追求,Kubernetes 基於以上介紹的 PV/PVC 存儲體系,實現了 local pv 機制,它可避免網路 IO 開銷,讓你的服務擁有更高的IO讀寫性能。local pv 核心是通過將本地盤、lvm 分區抽象成 PV,使用 local pv 的 Pod,依賴延遲綁定特性實現準確調度到目標節點。
local pv的關鍵核心技術點是容量隔離(lvm、xfs quota)、IO隔離(cgroup v1一般要訂製內核,cgroup v2支援buffer io等)、動態provision等問題,為了解決以上或部分痛點,社區也誕生了一系列的開源項目,如TopoLVM(支援動態provision、lvm),sig-storage-local-static-provisioner等項目,各雲廠商如騰訊內部也有相應的local pv解決方案。總體而言,local pv適用於磁碟io敏感型的etcd、MySQL、tidb等存儲服務,如pingcap的tidb項目就推薦在生產環境使用local pv。
local pv 的缺點是節點故障後,數據無法訪問、可能丟失、無法垂直擴容(受限於節點磁碟容量等)。 因此這對有狀態服務本身和其 operator 提出了更高要求,服務本身需要通過主備複製協議和共識演算法,保證數據安全性。任一節點故障後,operator 能及時擴容新節點,從冷備、leader 快照進行數據恢復。如 tidb 的 tikv 服務,當檢測到實例有異常後,會自動擴容新實例,通過 raft 協議完成數據的複製等。
混沌工程
通過以上技術方案,解決了負載類型選型、自定義資源擴展、調度、高可用、高性能網路、高性能存儲、穩定性測試等一系列痛點後,我們可基於 Kubernetes 的構建穩定、高可用、彈性伸縮的有狀態服務。
那麼如何驗證容器化後的有狀態服務穩定性呢?
社區提供了多個基於 Kubernetes 實現的混沌工程開源項目,比如 pingcap 的 chaos-mesh, 提供了 Pod chaos/Network chaos/IO chaos 等多種故障注入。基於 chaos mesh,你可以快速注入 Pod 故障、磁碟IO、網路IO等異常到集群中任意 Pod,幫助你快速發現有狀態服務本身和 operator Bug、檢驗集群的穩定性。 在 TKE 團隊中,我們基於 chaos mesh 排查、復現 etcd Bug, 壓測 etcd 集群的穩定性,極大的降低了我們復現複雜 Bug 的難度,幫助我們提升 etcd 內核的穩定性。
總結
本文通過從有狀態集群中的各個組件 workload 選型、擴展機制的選擇,介紹了如何使用 Kubernetes 的描述、部署你的有狀態服務。有狀態服務出於其特殊性,數據安全、高可用、高性能是其核心目標,為了保證服務的高可用,可通過調度和HA服務來實現。通過 Kubernetes 的多種調度器擴展機制,你可以將你的有狀態服務的等價 Pod 完成跨故障域部署。通過主備切換服務和共識演算法,你可以完成主節點故障後,備節點自動提升為主,以保證服務的高可用性。高性能主要取決於網路和存儲性能,Kubernetes 提供了 CNI 網路模型和 PV/PVC 存儲體系、CSI 擴展機制來滿足各種業務場景下的訂製需求。最後介紹了混沌工程在有狀態服務中的應用,通過混沌工程你可以模擬各類異常場景下,你的有狀態服務容錯性,幫助你檢驗和提升系統的穩定性。

