Hadoop系列番外篇之一文搞懂Hadoop RPC框架及細節實現
@
Hadoop RPC 框架解析
網路通訊模組是分散式系統中最底層的模組。它直接支撐了上層分散式環境下複雜的進程間通訊(Inter-Process Communication, IPC)邏輯,是所有分散式系統的基礎。遠程過程調用(Remote Procedure Call, RPC)是一種常用的分散式網路通訊協議。它允許運行於一台電腦的程式調用另一台電腦的子程式,同時將網路的通訊細節隱藏起來,使得用戶無須額外地為這個交互作用編程。
作為一個分散式系統,Hadoop實現了自己的RPC通訊協議,它是上層多個分散式子系統(如MapReduce, HDFS, HBase等)公用的網路通訊模組。本文主要從框架設計和實現方面介紹Hadoop RPC,還有該RPC框架在MapReduce中的應用。
1.Hadoop RPC框架概述
1.1 RPC框架特點
RPC實際上是分散式計算中客戶機/伺服器(Client/Server)模型的一個應用實例。對於Hadoop RPC而言,它具有以下幾個特點。
1.透明性:這是所有RPC框架的最根本特徵,即當用戶在一台電腦的程式調用另外一台電腦上的子程式時,用戶自身不應感覺到其間涉及跨機器間的通訊,而是感覺像是在執行一個本地調用。
2.高性能:Hadoop各個系統(如HDFS, MapReduce)均採用了Master/Slave結構。其中,Master實際上是一個RPC server,它負責處理集群中所有Slave發送的服務請求。為了保證Master的並發處理能力,RPC server應是一個高性能伺服器,能夠高效地處理來自多個Client的並發RPC請求。
3.可控性:JDK中已經自帶了一個RPC框架——RMI(Remote Method Invocation,遠程方法調用)。之所以不直接使用該框架,主要是因為考慮到RPC是Hadoop最底層、最核心的模組之一,保證其輕量級、高性能和可控性顯得尤為重要,而RMI過於重量級且用戶可控之處太少(如網路連接、超時和緩衝等均難以訂製或者修改)。
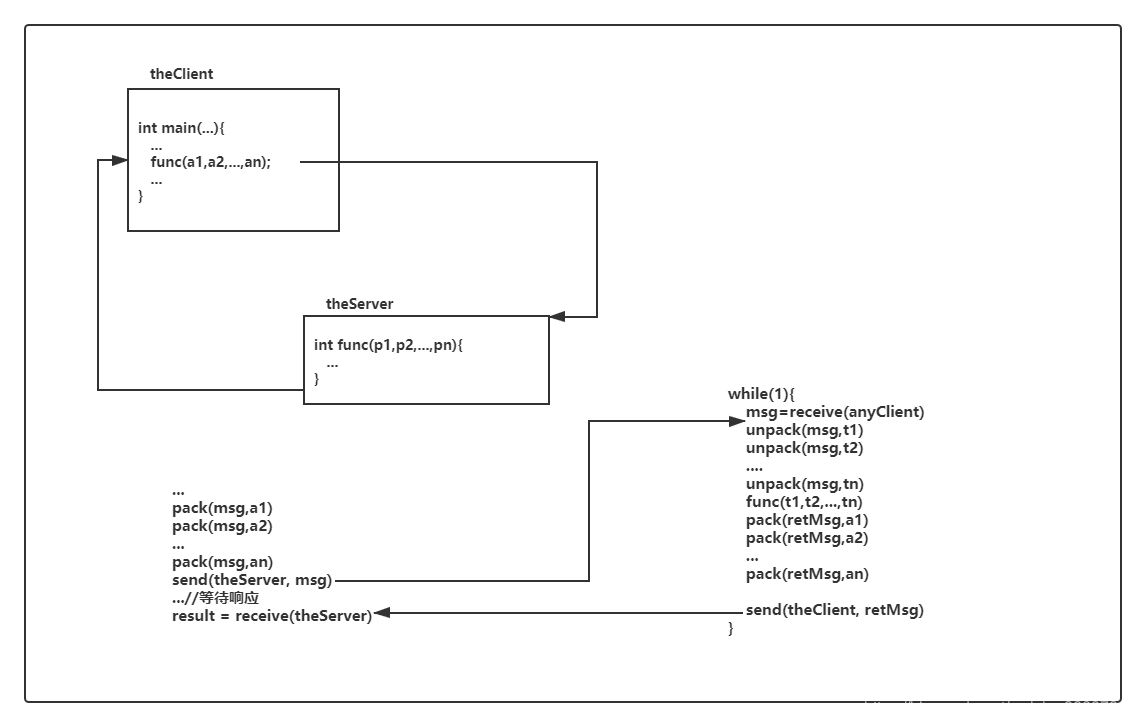
1.2 Hadoop RPC框架
與其他RPC框架一樣,Hadoop RPC主要分為四個部分,分別是序列化層、函數調用層、網路傳輸層和伺服器端處理框架,具體實現機制如下:
序列化層:序列化層的主要作用是將結構化對象轉為位元組流以便於通過網路進行傳輸或寫入持久存儲。在RPC框架中,它主要用於將用戶請求中的參數或者應答轉化成位元組流以便跨機器傳輸。Hadoop自己實現了序列化框架,一個類只要實現Writable介面,即可支援對象序列化與反序列化。
函數調用層:函數調用層的主要功能是定位要調用的函數並執行該函數。HadoopRPC採用Java反射機制與動態代理實現了函數調用。
網路傳輸層:網路傳輸層描述了Client與Server之間消息傳輸的方式,Hadoop RPC採用了基於TCP/IP的Socket機制。
伺服器端處理框架:伺服器端處理框架可被抽象為網路I/O模型。它描述了客戶端與伺服器端間資訊交互的方式。它的設計直接決定著伺服器端的並發處理能力。常見的網路I/O模型有阻塞式I/O、非阻塞式I/O、事件驅動I/O等,而Hadoop RPC採用了基於Reactor設計模式的事件驅動I/O模型。
Hadoop RPC總體架構自下而上可分為兩層。
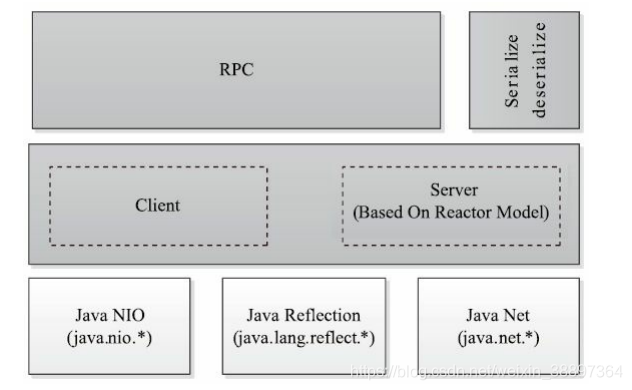
第一層是一個基於Java NIO(New IO)實現的客戶機/伺服器(Client/Server)通訊模型。其中,客戶端將用戶的調用方法及其參數封裝成請求包後發送到伺服器端。伺服器端收到請求包後,經解包、調用函數、打包結果等一系列操作後,將結果返回給伺服器端。為了增強Server端的擴展性和並發處理能力,Hadoop RPC採用了基於事件驅動的Reactor設計模式,在具體實現時,用到了JDK提供的各種功能包,主要包括java.nio(NIO)、java.lang.reflect(反射機制和動態代理)、java.net(網路編程庫)等。
第二層是供更上層程式直接調用的RPC介面,這些介面底層即為客戶機/伺服器通訊模型。
看到這裡有些小夥伴說我對於這些Java基礎知識都不是很記得了,沒關係,暖男的我現在就和大家一起來看看相關的這些Java基礎內容。又有一些小夥伴說我沒學過啊,那也沒關係,我們知識大致去了解一些類和這些類有哪些方法可以幫助我們理解RPC就夠了。我們使用Hadoop的時候不也不必關注RPC的細節么,那Java細節不會影響我們使用。對Java基礎反射、網路編程和NIO很熟悉的小可愛可以直接跳過第二章節
2.Java基礎知識回顧
我們簡要介紹Hadoop RPC中用到的JDK開發工具包中的一些類。了解和掌握這些類的功能和使用方法是深入學習Hadoop RPC的基礎。這些類主要來自以下三個Java包:java.lang.reflect(反射機制和動態代理相關類)、java.net(網路編程庫)和java.nio(NIO)。
2.1 Java反射機制與動態代理
反射機制是Java語言的一個重要特性,它的重要性也不用多說,在很多的框架中,反射撐起了半邊天。簡言之其作用:允許用戶動態獲取類的資訊和動態調用對象的方法。
我們先來看看它提供的主要的類和類對應的功能:
| 類名&介面 | 功能描述 |
|---|---|
| Class | 代表一個Java類 |
| Field | 代表Java類的屬性 |
| Method | 代表Java類的方法 |
| Constructor | 代表Java類的構造函數 |
| Array | 提供了動態創建數組,以及訪問數組元素的靜態方法 |
| Proxy類以及InvocationHandler介面 | 提供了動態生成代理類以及實例的方法 |
我們重點關注Java動態代理。在動態代理之前,我們先一起回顧一下代理概念及代理模式。有小可愛說不知道動態代理我只聽過名字啊,具體是個什麼,我不知道呀。沒關係,我先簡單說一下動態代理的核心思想:是為其他對象提供一種代理以控制對這個對象的訪問。代理類負責為委託類進行預處理(如安全檢查,許可權檢查等)或者執行完後的後續處理(如轉發給其他代理等)。動態代理的好處就是開發人員通過簡單的指定一組介面及委託類對象,便能動態地獲得代理類,這大大簡化了編寫代理類的步驟。
2.1.1 代理關鍵類&介面資訊
在此我們先來了解一下代理的一些關鍵類&介面以及其主要方法:
1)java. lang.reflect.Proxy
這是Java動態代理機制的主類,它提供了一組靜態方法,用於為一組介面動態地生成代理類及其對象。
// Returns the invocation handler for the specified proxy instance.
// Params:proxy – the proxy instance to return the invocation handler for
// Returns:the invocation handler for the proxy instance
// 獲取指定代理對象所關聯的調用處理器
public static InvocationHandler getInvocationHandler(Object proxy)
// 獲取關聯於指定類裝載器和一組介面的動態代理類的對象
public static Class<?> getProxyClass(ClassLoader loader, Class<?>... interfaces)
// 判斷指定的類是不是一個動態代理類
public static boolean isProxyClass(Class<?> cl)
// 為指定類裝載器一組介面及調用處理器生成動態代理類實例
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
2)java. lang.reflect.InvocationHandler
這是調用處理器介面。它定義了一個invoke方法,用於處理在動態代理類對象上的方法調用。通常開發人員需實現該介面,並在invoke方法中實現對委託類的代理訪問。
// 該方法負責處理動態代理類上的所有方法調用
// 參數:代理類實例,被調用的方法對象,調用參數
// 調用處理器根據這三個參數進行預處理或分派到委託類實例上執行
public Object invoke(Object proxy, Method method, Object[] args)
2.1.2 動態代理創建對象的過程
一個典型的動態代理創建對象的過程可分為以下4個步驟:
- 步驟1 通過實現InvocationHandler介面創建自己的調用處理器:
- 步驟2 通過為Proxy類指定ClassLoader對象和一組interface創建動態代理類:
- 步驟3 通過反射機制獲取動態代理類的構造函數,其參數類型是調用處理器介面類型:
- 步驟4 通過構造函數創建動態代理類實例,此時需將調用處理器對象作為參數
被傳入:
// step 1通過實現InvocationHandler介面創建自己的調用處理器
InvocationHandler handler=new InvocationHandlerImpl(...);
// 2 通過為Proxy類指定ClassLoader對象和一組interface創建動態代理類
Class clazz=Proxy.getProxyClass(classLoader, new Class[]{……});
// 3 通過反射機制獲取動態代理類的構造函數,其參數類型是調用處理器介面類型
Constructor constructor=clazz.getConstructor(new Class[]{InvocationHandler.class});
// 4通過構造函數創建動態代理類實例,此時需將調用處理器對象作為參數
Interface Proxy=(Interface)constructor.newInstance(new Object[]{handler});
Proxy類中的newInstance方法封裝了步驟2~步驟4,只需兩步即可完成代理對象的創建。
我們通過一個動態代理的例子來加深對於動態代理的理解;
目錄結構如下
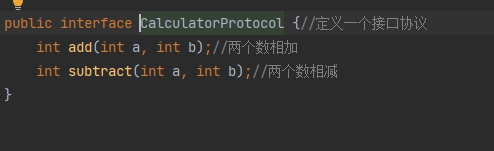
定義一個介面協議
實現介面協議 Server類
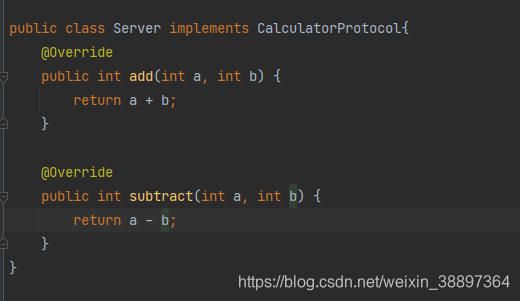
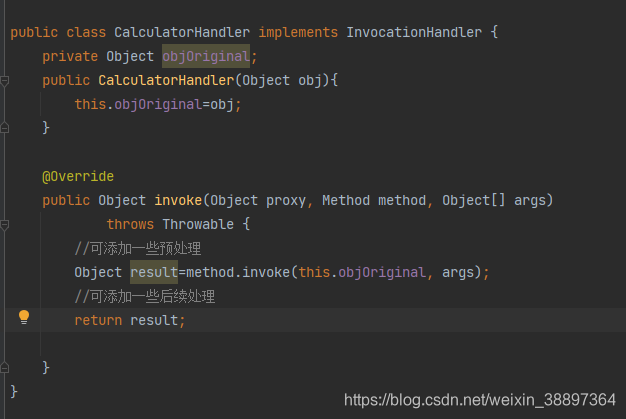
實現調用處理器介面
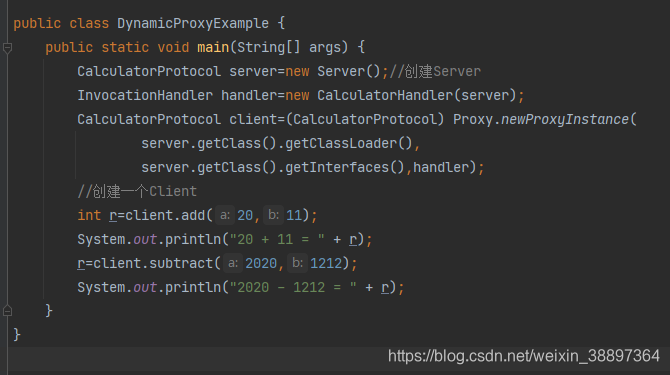
測試用例
2.2 Java網路編程
通常,Java網路程式建立在TCP/IP協議基礎上,致力於實現應用層。傳輸層嚮應用層提供了套接字Socket介面,它封裝了下層的數據傳輸細節;應用層的程式可通過Socket與遠程主機建立連接和進行數據傳輸。
JDK提供了3種套接字類:java.net.Socket、java.net.ServerSocket和java.net.DatagramSocket。其中,java.net.Socket和java.net.ServerSocket類建立在TCP協議基礎上,而java.net.DatagramSocket類則建立在UDP協議基礎上。Java網路程式均採用客戶機/伺服器通訊模式。下面介紹如何使用java.net.Socket和java.net.ServerSocket編寫客戶端和伺服器端程式。
編寫一個客戶端程式需要以下3個步驟
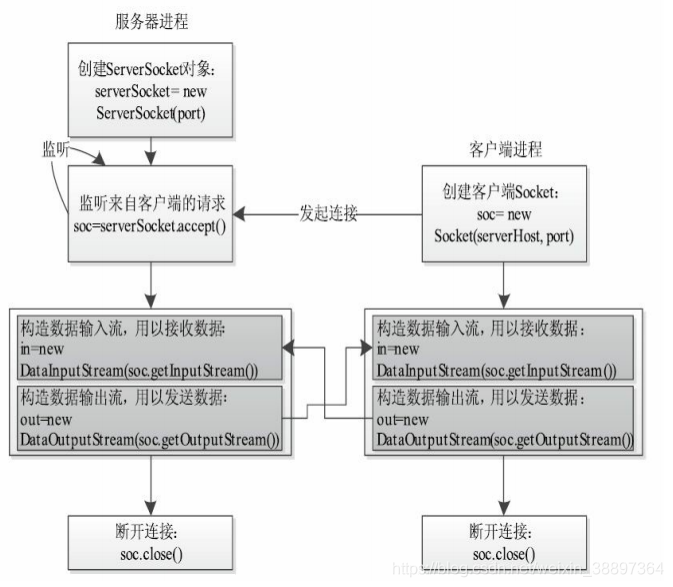
步驟1 創建客戶端Socket:
其中,serverHost為伺服器端的host, port為伺服器端的監聽埠號。一旦Socket創建成功,則表示客戶端連接伺服器成功。
Socket soc=new Socket(serverHost, port);
步驟2 創建輸出、輸入流以向伺服器端發送數據和從伺服器端接收數據:
//構造數據輸入流,用以接收數據
DataInputStream in=new DataInputStream(soc.getInputStream());
//構造數據輸出流,用以發送數據
DataOutputStream out=new DataOutputStream(soc.getOutputStream());
……
//應用程式發送和接收數據
步驟3 斷開連接:
soc.close();
編寫一個伺服器端程式需要以下4個步驟:
步驟1 創建ServerSocket對象:
ServerSocket serverSocket=new ServerSocket(port);
其中,port為伺服器端的監聽埠號。當客戶端向伺服器端建立連接時,需要知道該埠號。創建ServerSocket對象成功後,作業系統將把當前進程註冊為伺服器進程。
步驟2 監聽埠號,等待新連接到達:
Socket soc=serverSocket.accept();
運行函數accept()後,ServerSocket對象會一直處於監聽狀態,等待客戶端的連接請求。一旦有客戶端請求到達,該函數會返回一個Socket對象,該Socket對象與客戶端Socket對象形成一條通訊鏈路。
步驟3 創建輸出、輸入流以向客戶端發送數據和從客戶端接收數據。此處的程式和客戶端的一樣,故不再贅述。
步驟4 斷開連接。此處的程式和客戶端的一樣,故不再贅述。
在Client/Server模型中,Server往往需要同時處理大量來自Client的訪問請求,因此Server端需採用支援高並發訪問的架構。一種簡單而又直接的解決方案是「one thread-perconnection」。這是一種基於阻塞式I/O的多執行緒模型,如下圖所示。在該模型中,Server為每個Client連接創建一個處理執行緒,每個處理執行緒阻塞式等待可能到達的數據,一旦數據到達,則立即處理請求、返回處理結果並再次進入等待狀態。由於每個Client連接有一個單獨的處理執行緒為其服務,因此可保證良好的響應時間。但當系統負載增大(並發請求增多)時,Server端需要的執行緒數會增加,這將成為系統擴展的瓶頸所在。
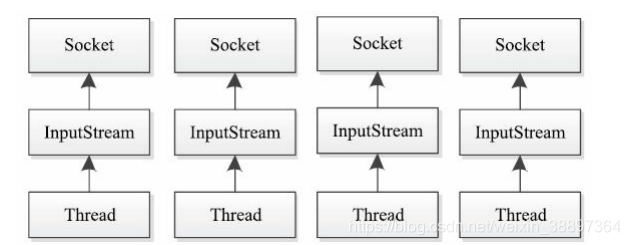
2.3 Java NIO
2.3.1 簡介
從J2SE 1.4版本以來,JDK發布了全新的I/O類庫,簡稱NIO(New IO)。它不但引入了全新的高效的I/O機制,同時引入了基於Reactor設計模式的多路復用非同步模式。NIO的包中主要包含了以下幾種抽象數據類型:
Channel(通道):NIO把它支援的I/O對象抽象為Channel。它模擬了通訊連接,類似於原I/O中的流(Stream),用戶可以通過它讀取和寫入數據。目前已知的實例類有SocketChannel、ServerSocketChannel、DatagramChannel、FileChannel等。
Buffer(緩衝區):Buffer是一塊連續的記憶體區域,一般作為Channel收發數據的載體出現。所有數據都通過Buffer對象來處理。用戶永遠不會將位元組直接寫入通道中,相反,需將數據寫入包含一個或者多個位元組的緩衝區;同樣,也不會直接從通道中讀取位元組,而是將數據從通道讀入緩衝區,再從緩衝區獲取這個位元組。
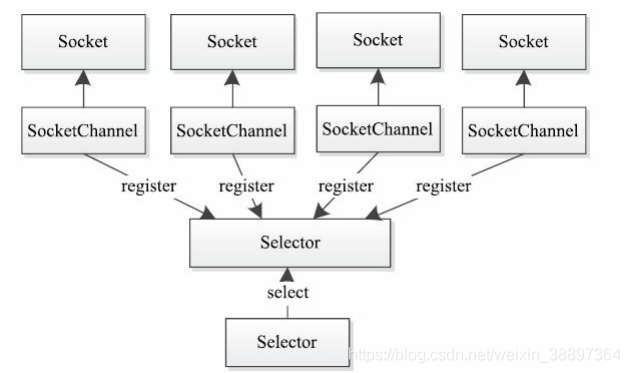
Selector(選擇器):Selector類提供了監控一個或多個通道當前狀態的機制。只要Channel向Selector註冊了某種特定事件,Selector就會監聽這些事件是否會發生,一旦發生某個事件,便會通知對應的Channel。使用選擇器,藉助單一執行緒,就可對數量龐大的活動I/O通道實施監控和維護,如下圖所示:
2.3.2 常用類
1)Buffer相關類
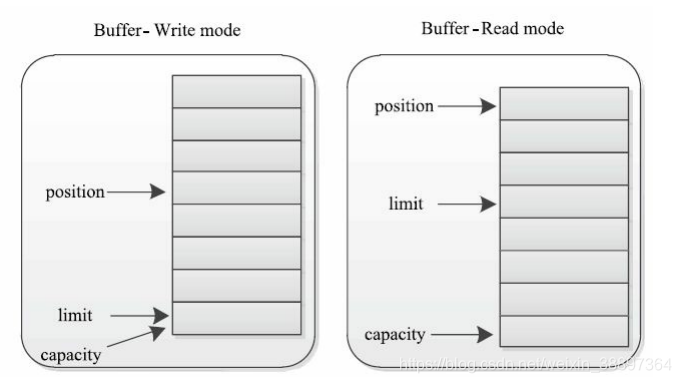
所有緩衝區包含以下3個屬性:
capacity:緩衝區的末位值。它表明了緩衝區最多可以保存多少數據;
limit:表示緩衝區的當前存放數據的終點。不能對超過limit的區域進行讀寫數據;
position:下一個讀寫單元的位置。每次讀寫緩衝區時,均會修改該值,為下一次讀寫數據做準備。
這三個屬性的大小關係是capacity≥limit≥position≥0
Buffer有兩種不同的工作模式——寫模式和讀模式。在寫模式下,limit與capacity相同,position隨著寫入數據增加,逐漸增加到limit,因此,0到position之間的數據即為已經寫入的數據;在讀模式下,limit初始指向position所在位置,position隨著數據的讀取,逐漸增加到limit,則0到position之間的數據即為已經讀取的數據。
2)Channel相關類
java. nio提供了多種Channel實現,其中,最常用的是以SelectableChannel為基類的通道。SelectableChannel是一種支援阻塞I/O和非阻塞I/O的通道,它的主要方法如下:
- SelectableChannel configureBlocking(boolean block)throws IOException。
- 作用:設置當前SelectableChannel的阻塞模式。
- 參數含義:block表示是否將SelectableChannel設置為阻塞模式。
- 返回值:SelectableChannel對象本身的引用,相當於「return this」。
- SelectionKey register(Selector sel, int ops)throws ClosedChannelException。
- 作用:將當前Channel註冊到一個Selector中。
- 參數含義:sel表示要註冊的Selector;ops表示註冊事件。
- 返回值:與註冊Channel關聯的SelectionKey對象,用於跟蹤被註冊事件。
SelectableChannel的兩個子類是ServerSocketChannel和SocketChannel,它們分別是ServerSocket和Socket的替代類。
ServerSocketChannel主要用於監聽TCP連接,
SocketChannel可看作Socket的替代類,但功能比Socket更加強大。同ServerSocket-Channel類似,它提供了靜態工廠方法open()(創建對象)和socket()方法(返回與SocketChannel關聯的Socket對象)。
3)Selector類
Selector可監聽ServerSocketChannel和SocketChannel註冊的特定事件,一旦某個事件發生,則會通知對應的Channel。SelectableChannel的register()方法負責註冊事件,該方法返回一個SelectionKey對象,該對象即為用於跟蹤這些註冊事件的句柄。
Selector中常用的方法如下。
- static Selector open():一個靜態工廠方法,可用於創建Selector對象。
- int select(long timeout):該方法等待並返回發生的事件。一旦某個註冊的事件發生,就會返回對應的SelectionKey的數目,否則,一直處於阻塞狀態,直到以下四種情況之一發生:
- 至少一個事件發生;
- 其他執行緒調用了Selector的wakeup()方法;
- 當前執行select()方法的執行緒被中斷;
- 超出等待時間timeout,如果不設置等待時間,則表示永遠不會超時。
- set selectedKeys():Selector捕獲的已經發生事件對應的SelectionKey集合。
- Selector wakeup():立刻喚醒當前處於阻塞狀態的Selector。常見應用場景是,執行緒A調用Selector對象的select()方法,阻塞等待某個註冊事件發生,執行緒B通過調用wakeup()函數可立刻喚醒執行緒A,使其從select()方法中返回。
4)SelectionKey類
ServerSocketChannel或SocketChannel通過register()方法向Selector註冊事件時,register()方法會創建一個SelectionKey對象,用於跟蹤註冊事件。在SelectionKey中定義了4種事件,分別用以下4個整型常量表示:
- [ ] SelectionKey. OP_ACCEPT:接收(accept)連接就緒事件,表示伺服器端接
收到了客戶端連接。 - [ ] SelectionKey. OP_CONNECT:連接就緒事件,表示客戶端與伺服器端的連接
已經建立成功。 - [ ] SelectionKey. OP_READ:讀就緒事件,表示通道中已經有了可讀數據,可執行
讀操作了。 - [ ] SelectionKey. OP_WRITE:寫就緒事件,表示可向通道中寫入數據了。
通常而言,ServerSocketChannel對象向Selector中註冊SelectionKey.OP_ACCEPT事件,而SocketChannel對象向Selector中註冊SelectionKey.OP_CONNECT、SelectionKey.OP_READ和SelectionKey.OP_WRITE三種事件。
3.Hadoop RPC基本框架分析
3.1 RPC基本概念
RPC是一種通過網路從遠程電腦上請求服務,但不需要了解底層網路技術的協議。RPC協議假定某些傳輸協議已經存在,如TCP或UDP等,並通過這些傳輸協議為通訊程式之間傳遞訪問請求或者應答資訊。在OSI網路通訊模型中,RPC跨越了傳輸層和應用層。RPC使得開發分散式應用程式更加容易。
3.1.1 RPC組成部分
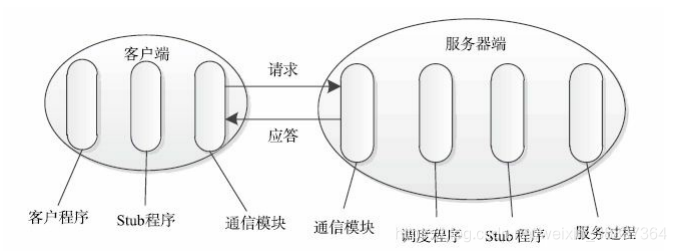
RPC通常採用客戶機/伺服器模型。請求程式是一個客戶機,而服務提供程式則是一個伺服器。一個典型的RPC框架主要包括以下幾個部分:
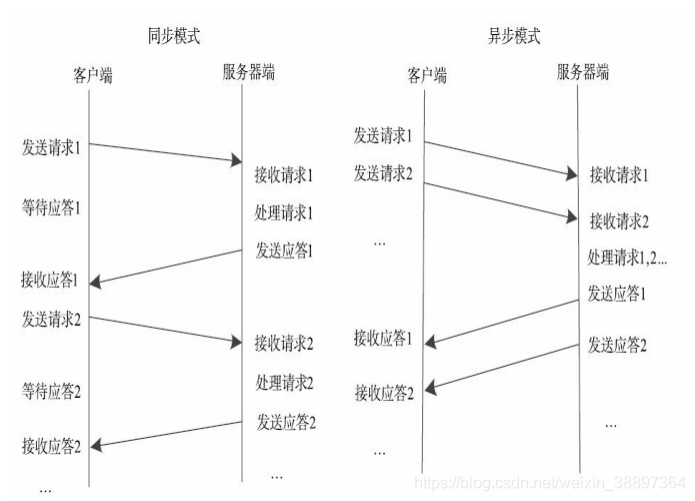
通訊模組:兩個相互協作的通訊模組實現請求-應答協議。它們在客戶機和伺服器之間傳遞請求和應答消息,一般不會對數據包進行任何處理。
請求-應答協議的實現方式有兩種,分別是同步方式和非同步方式。如下圖同步模式下客戶端程式一直阻塞到伺服器端發送的應答請求到達本地;而非同步模式則不同,客戶端將請求發送到伺服器端後,不必等待應答返回,可以做其他事情,待伺服器端處理完請求後,主動通知客戶端。在高並發應用場景中,一般採用非同步模式以降低訪問延遲和提高頻寬利用率。
Stub程式:客戶端和伺服器端均包含Stub程式,可將之看作代理程式。它使得遠程函數調用表現的跟本地調用一樣,對用戶程式完全透明。在客戶端,它表現的就像一個本地程式,但不直接執行本地調用,而是將請求資訊通過網路模組發送給伺服器端。此外,當伺服器端發送應答後,它會解碼對應結果。在伺服器端,Stub程式依次進行以下處理:解碼請求消息中的參數、調用相應的服務過程和編碼應答結果的返回值。
調度程式:調度程式接收來自通訊模組的請求消息,並根據其中的標識選擇一個Stub程式處理。通常客戶端並發請求量比較大時,會採用執行緒池提高處理效率。
客戶程式/服務過程:請求的發出者和請求的處理者。如果是單機環境,客戶程式可直接通過函數調用訪問服務過程,但在分散式環境下,需要考慮網路通訊,這不得不增加通訊模組和Stub程式(保證函數調用的透明性)。
3.1.2 RPC工作流程
通常而言,一個RPC請求從發送到獲取處理結果,所經歷的步驟如下:
步驟1 客戶程式以本地方式調用系統產生的Stub程式;
步驟2 該Stub程式將函數調用資訊按照網路通訊模組的要求封裝成消息包,並交給通訊模組發送到遠程伺服器端;
步驟3 遠程伺服器端接收此消息後,將此消息發送給相應的Stub程式;
步驟4 Stub程式拆封消息,形成被調過程要求的形式,並調用對應的函數;
步驟5 被調用函數按照所獲參數執行,並將結果返回給Stub程式;
步驟6 Stub程式將此結果封裝成消息,通過網路通訊模組逐級地傳送給客戶程式。
3.2 Hadoop RPC基本框架
在正式介紹Hadoop RPC基本框架之前,先介紹怎麼樣使用它。Hadoop RPC主要對外提供了兩種介面。正所謂知其然,然後知其所以然。
- public static VersionedProtocol getProxy/waitForProxy():構造一個客戶端代理對象(該對象實現了某個協議),用於向伺服器端發送RPC請求。
- public static Server getServer():為某個協議(實際上是Java介面)實例構造一個伺服器對象,用於處理客戶端發送的請求。
3.2.1 構建一個簡單的Hadoop RPC
通常而言,Hadoop RPC使用方法可分為以下幾個步驟。
步驟1 定義RPC協議。RPC協議是客戶端和伺服器端之間的通訊介面,它定義了伺服器端對外提供的服務介面。
步驟2 實現RPC協議。Hadoop RPC協議通常是一個Java介面,用戶需要實現
該介面。
步驟3 構造並啟動RPC Server。
步驟4 構造RPC Client,並發送RPC請求。
這四步沒有實操總覺得比較遙遠,那我們就動手編碼試一下。
// 1. 定義RPC協議
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol{
//版本號。默認情況下,不同版本號的RPC Client和Server之間不能相互通訊
public static final long versionID=1L;
String echo(String value)throws IOException;
int add(int v1,int v2)throws IOException;
}
// 2.實現RPC協議
public static class ClientProtocolImpl implements ClientProtocol{
public long getProtocolVersion(String protocol, long clientVersion){
return ClientProtocol.versionID;
}
public String echo(String value)throws IOException{
return value;
}
public int add(int v1,int v2)throws IOException{
return v1+v2;
}
}
// 3.構造並啟動RPC Server 新建一個類,主方法如下
public static void main(String[] args){
server=RPC.getServer(new ClientProtocolImpl(),serverHost, serverPort,
numHandlers, false, conf);
server.start();
}
// 4.構造RPC Client ,構建客戶端類,方法如下
public static void main(String[] args){
proxy=(ClientProtocol)RPC.getProxy(
ClientProtocol.class, ClientProtocol.versionID, addr, conf);
int result=proxy.add(5,6);
String echoResult=proxy.echo("result");
}
3.2.2 Hadoop RPC 組成類分析
Hadoop RPC主要由三個大類組成,分別是RPC、Client和Server,分別對應對外編程介面、客戶端實現和伺服器端實現。
3.2.2.1 RPC類分析
RPC類實際上是對底層客戶機/伺服器網路模型的封裝,以便為程式設計師提供一套更方便簡潔的編程介面。
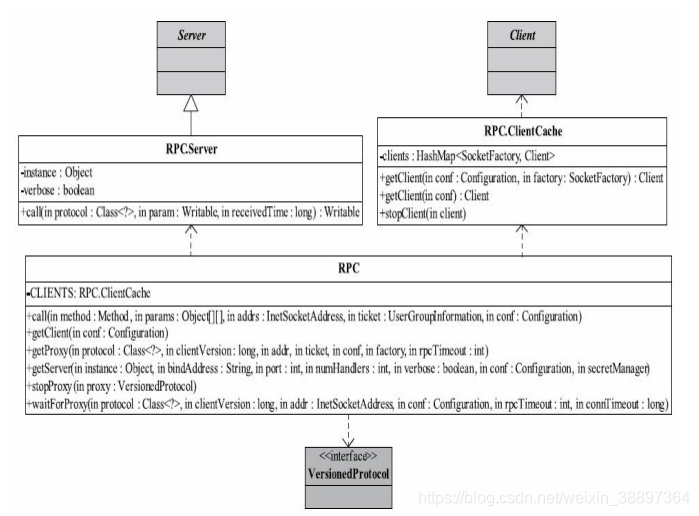
RPC類自定義了一個內部類RPC.Server。它繼承Server抽象類,並利用Java反射機制實現了call介面(Server抽象類中並未給出該介面的實現),即根據客戶端請求中的調用方法名稱和對應參數完成方法調用。RPC類包含一個ClientCache類型的成員變數,它根據用戶提供的SocketFactory快取Client對象,以達到重用Client對象的目的。
3.2.2.2 Client類分析
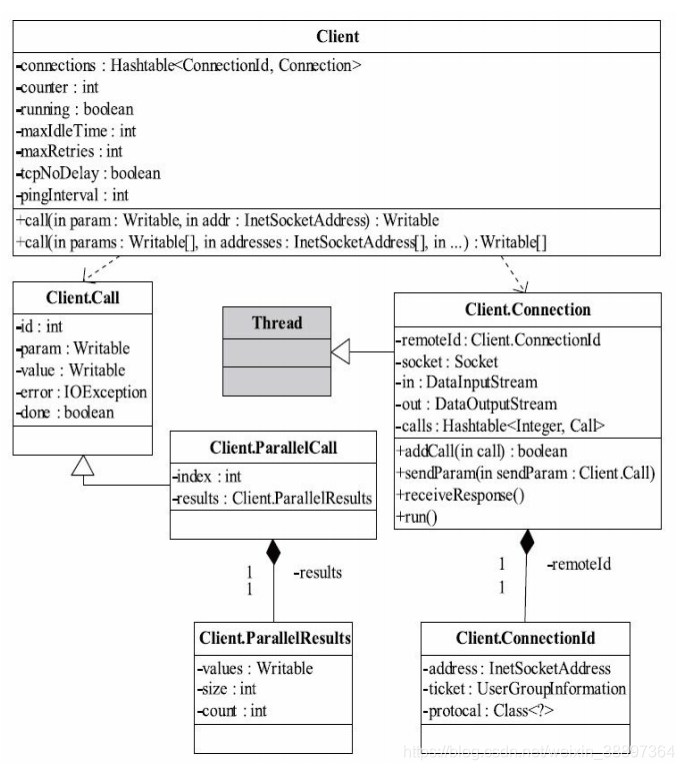
Client主要完成的功能是發送遠程過程調用資訊並接收執行結果。Client類對外提供了兩種介面,一種用於執行單個遠程調用。另外一種用於執行批量遠程調用。
Client內部有兩個重要的內部類,分別是Call和Connection:
Call類:該類封裝了一個RPC請求,它包含五個成員變數,分別是唯一標識id、函數調用資訊param、函數執行返回值value、出錯或者異常資訊error和執行完成標識符done。由於Hadoop RPC Server採用了非同步方式處理客戶端請求,這使得遠程過程調用的發生順序與結果返回順序無直接關係,而Client端正是通過id識別不同的函數調用。當客戶端向伺服器端發送請求時,只需填充id和param兩個變數,而剩下的三個變數:value, error和done,則由伺服器端根據函數執行情況填充。
Connection類:Client與每個Server之間維護一個通訊連接。該連接相關的基本資訊及操作被封裝到Connection類中。其中,基本資訊主要包括:通訊連接唯一標識(remoteId),與Server端通訊的Socket(socket),網路輸入數據流(in),網路輸出數據流(out),保存RPC請求的哈希表(calls)等
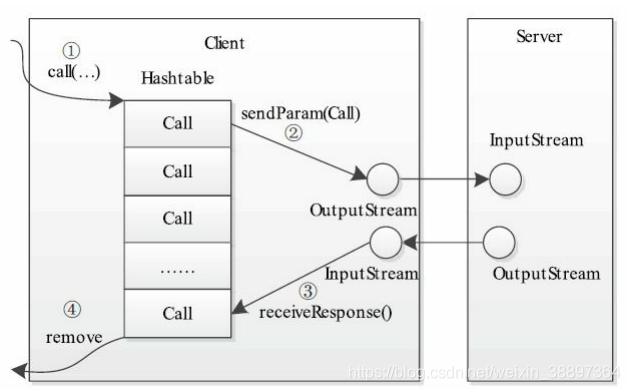
當調用call函數執行某個遠程方法時,Client端需要進行如下幾個步驟:
步驟1 創建一個Connection對象,並將遠程方法調用資訊封裝成Call對象,放到Connection對象中的哈希表calls中;
步驟2 調用Connetion類中的sendParam()方法將當前Call對象發送給Server端;
步驟3 Server端處理完RPC請求後,將結果通過網路返回給Client端,Client端通過receiveResponse()函數獲取結果;
步驟4 Client端檢查結果處理狀態(成功還是失敗),並將對應的Call對象從哈希表中刪除。
3.2.2.3 Server類分析
Hadoop採用了Master/Slave結構。其中,Master是整個系統的單點,如NameNode或JobTracker,這是制約系統性能和可擴展性的最關鍵因素之一,而Master通過ipc.Server接收並處理所有Slave發送的請求,這就要求ipc.Server將高並發和可擴展性作為設計目標。為此,ipc.Server採用了很多具有提高並發處理能力的技術,主要包括執行緒池、事件驅動和Reactor設計模式等。這些技術均採用了JDK自帶的庫實現。
Reactor是並發編程中的一種基於事件驅動的設計模式。它具有以下兩個特點:
①通過派發/分離I/O操作事件提高系統的並發性能;
②提供了粗粒度的並發控制,使用單執行緒實現,避免了複雜的同步處理。
一個典型的Reactor模式中主要包括以下幾個角色。
- [ ] Reactor:IO事件的派發者。
- [ ] Acceptor:接受來自Client的連接,建立與Client對應的Handler,並向Reactor註冊此Handler。
- [ ] Handler:與一個Client通訊的實體,並按一定的過程實現業務的處理。Handler內部往往會有更進一步的層次劃分,用來抽象諸如read, decode, compute,encode和send等的過程。在Reactor模式中,業務邏輯被分散的IO事件所打破,所以Handler需要有適當的機制在所需的資訊還不全(讀到一半)的時候保存上下文,並在下一次IO事件到來的時候(另一半可讀了)能繼續上次中斷的處理。
- [ ] Reader/Sender:為了加速處理速度,Reactor模式往往構建一個存放數據處理執行緒的執行緒池,這樣,數據讀出後,立即扔到執行緒池中等待後續處理即可。為此,Reactor模式一般分離Handler中的讀和寫兩個過程,分別註冊成單獨的讀事件和寫事件,並由對應的Reader和Sender執行緒處理。
Server的主要功能是接收來自客戶端的RPC請求,經過調用相應的函數獲取結果後,返回給對應的客戶端。為此,ipc.Server被劃分成三個階段:接收請求,處理請求和返回結果。各階段實現細節如下:
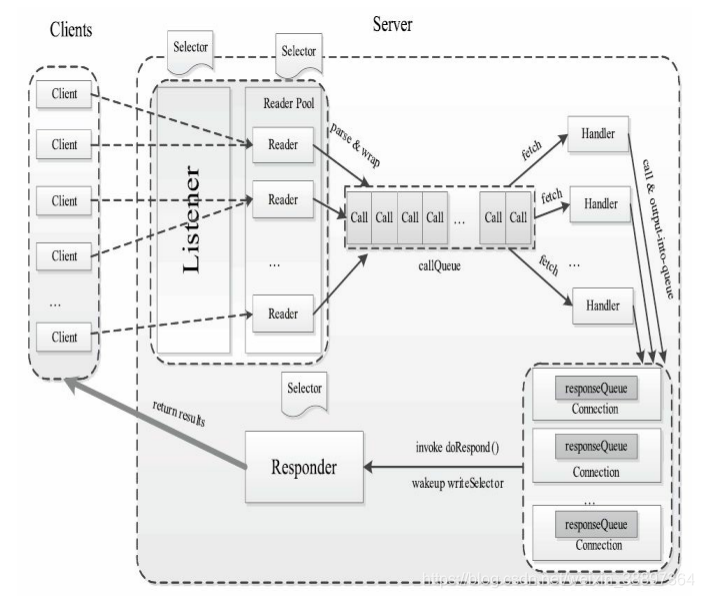
1)接收請求
該階段的主要任務是接收來自各個客戶端的RPC請求,並將它們封裝成固定的格式(Call類)放到一個共享隊列(callQueue)中,以便進行後續處理。該階段內部又分為兩個子階段:建立連接和接收請求,分別由兩種執行緒完成:Listener和Reader。
整個Server只有一個Listener執行緒,統一負責監聽來自客戶端的連接請求。一旦有新的請求到達,它會採用輪詢的方式從執行緒池中選擇一個Reader執行緒進行處理。而Reader執行緒可同時存在多個,它們分別負責接收一部分客戶端連接的RPC請求。至於每個Reader執行緒負責哪些客戶端連接,完全由Listener決定。當前Listener只是採用了簡單的輪詢分配機制。
Listener和Reader執行緒內部各自包含一個Selector對象,分別用於監聽SelectionKey.OP_ACCEPT和SelectionKey.OP_READ事件。對於Listener執行緒,主循環的實現體是監聽是否有新的連接請求到達,並採用輪詢策略選擇一個Reader執行緒處理新連接;對於Reader執行緒,主循環的實現體是監聽(它負責的那部分)客戶端連接中是否有新的RPC請求到達,並將新的RPC請求封裝成Call對象,放到共享隊列callQueue中。
2)處理請求
該階段的主要任務是從共享隊列callQueue中獲取Call對象,執行對應的函數調用,並將結果返回給客戶端,這全部由Handler執行緒完成。Server端可同時存在多個Handler執行緒。它們並行從共享隊列中讀取Call對象,經執行對應的函數調用後,將嘗試著直接將結果返回給對應的客戶端。但考慮到某些函數調用返回的結果很大或者網路速度過慢,可能難以將結果一次性發送到客戶端,此時Handler將嘗試著將後續發送任務交給Responder執行緒。
3)返回結果
每個Handler執行緒執行完函數調用後,會嘗試著將執行結果返回給客戶端,但對於特殊情況,比如函數調用返回的結果過大或者網路異常情況(網速過慢),會將發送任務交給Responder執行緒。
Server端僅存在一個Responder執行緒。它的內部包含一個Selector對象,用於監聽SelectionKey.OP_WRITE事件。當Handler沒能夠將結果一次性發送到客戶端時,會向該Selector對象註冊SelectionKey.OP_WRITE事件,進而由Responder執行緒採用非同步方式繼續發送未發送完成的結果。
4. Hadoop RPC的發展與展望
當前存在非常多的開源RPC框架,比較有名的有Thrift, Protocol Buffers和Avro。與Hadoop RPC一樣,它們均由兩部分組成:對象序列化和遠程過程調用。相比於Hadoop RPC,它們有以下幾個特點。
- [ ] 跨語言特性:前面提到,RPC框架實際上是客戶機/伺服器模型的一個應用實例。對於Hadoop RPC而言,由於Hadoop採用Java語言編寫,因而其RPC客戶端和伺服器端僅支援Java語言;但對於更通用的RPC框架,如Thrift或者Protocol Buffers等,其客戶端和伺服器端可採用任何語言編寫,如Java, C++,Python等,這給用戶編程帶來極大的方便。
- [ ] 引入IDL:開源RPC框架均提供了一套介面描述語言(Interface DescriptionLanguage,IDL)。它提供一套通用的數據類型,並以這些數據類型來定義更為複雜的數據類型和對外服務介面。一旦用戶按照IDL定義的語法編寫完介面文件後,即可根據實際應用需要生成特定的程式語言(如Java, C++,Python等)的客戶端和伺服器端程式碼。
- [ ] 協議兼容性:開源RPC框架在設計上均考慮到了協議兼容性問題,即當協議格式發生改變時,比如某個類需要添加或者刪除一個成員變數(欄位)後,舊版本程式碼仍然能識別新格式的數據,也就是說,具有向後兼容性。
隨著Hadoop版本的不斷演化,Hadoop RPC在跨語言支援和協議兼容性兩個方面存在不足,具體表現為:
1)從長遠發展看,Hadoop RPC應允許某些協議的客戶端或者伺服器端採用其他語言實現,比如用戶希望直接使用C/C++語言讀寫HDFS中的文件,這就需要有C/C++語言的HDFS客戶端。
2)當前Hadoop版本較多,而不同版本之間不能通訊。
從0.21.0版本開始,Hadoop嘗試著將RPC中的序列化部分剝離開,以便將現有的開源RPC框架集成進來。RPC類變成了一個工廠,它將具體的RPC實現授權給RpcEngine實現類,而現有的開源RPC只要實現RpcEngine介面,便可以集成到Hadoop RPC中。
正如當前的YARN使用的事件處理的方式,能夠大大增強並發性,從而提高系統整體性能。
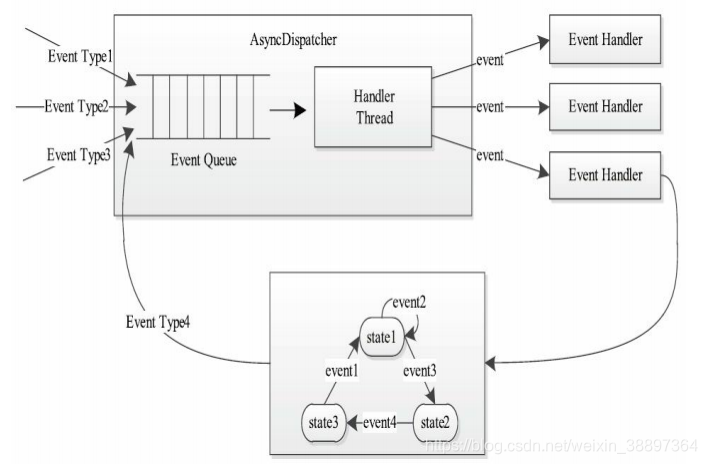
以及Yarn的RPC通訊方式: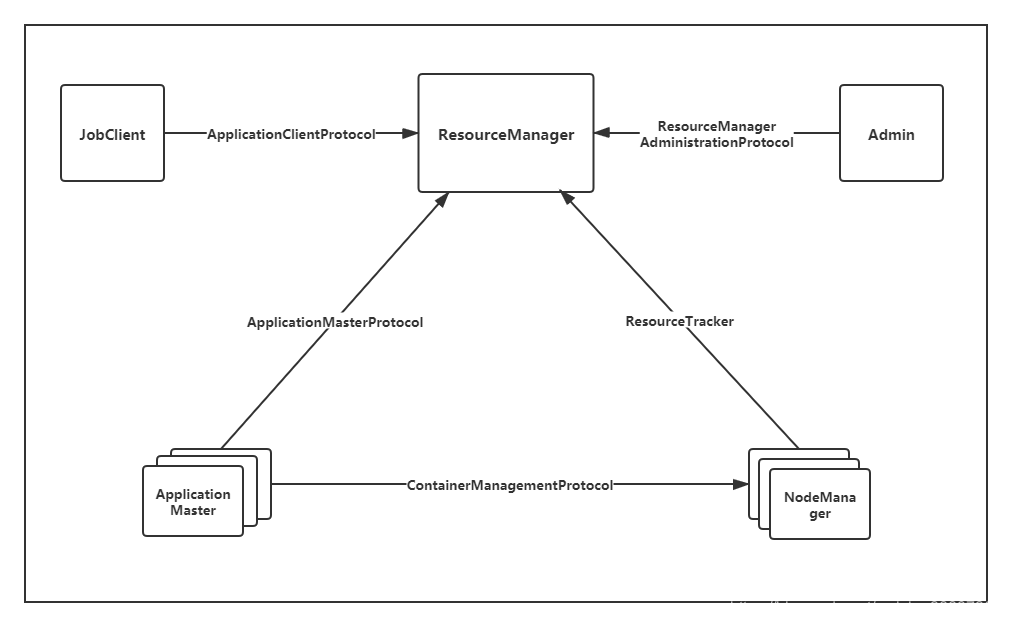
YARN中的序列化框架採用了Google開源的Protocol Buffers。Protocol Buffers的引入使得YARN在兼容性方面向前邁進了一大步。
總結
Hadoop RPC是Hadoop多個子系統公用的網路通訊模組。其性能和可擴展性直接影響其上層系統的性能和可擴展性,因此扮演著極其重要的角色。
Hadoop RPC分為兩層:上層是直接供外面使用的公共RPC介面;下層是一個客戶機/伺服器模型,該模型在實現過程中用到了Java自帶的多個工具包,包括java.lang.reflect(反射機制和動態代理相關類)、java.net(網路編程庫)和java.nio(NIO)等。
Hadoop RPC主要由三個大類組成,分別是RPC、Client和Server,分別對應對外編程介面、客戶端實現和伺服器端實現。其中,Server具有高性能和良好的可擴展性等特點,在具體實現時採用了執行緒池、事件驅動和Reactor設計模式等機制。
Hadoop MapReduce基於RPC框架實現了6個通訊協議,分別是JobSubmissionsProtocol, RefreshUserMappingsProtocol,RefreshAuthorizationPolicyProtocol, AdminOperationsProtocol,InterTrackerProtocol和TaskUmbilicalProtocol。這些協議像是系統的「骨架」,支撐起整個MapReduce系統。隨著Hadoop的不斷演化,更多開源的RPC框架不斷和現有RPC機制進行整合,更好的提升Hadoop的並發和處理能力。
好了,今天的文章到這裡就結束了,希望對小可愛們有所幫助。
路漫漫其修遠兮,吾將上下而求索。讓我們一起在不斷學習的道路上漸行漸遠漸無書。


