Python網路爬蟲實戰(四)模擬登錄
- 2019 年 10 月 3 日
- 筆記
對於一個網站的首頁來說,它可能需要你進行登錄,比如知乎,同一個URL下,你登錄與未登錄當然在右上角個人資訊那裡是不一樣的。

(登錄過)
(未登錄)
那麼你在用爬蟲爬取的時候獲得的頁面究竟是哪個呢?
肯定是第二個,不可能說你不用登錄就可以訪問到一個用戶自己的主頁資訊,那麼是什麼讓同一個URL在爬蟲訪問時出現不同內容的情況呢?
在第一篇中我們提到了一個概念,cookie,因為HTTP是無狀態的,所以對方伺服器並不知道這次請求到底來自於誰,就好像突然你收到了一封信,上面讓你給他寄一些東西,但是信上卻沒有他的聯繫方式。
在HTTP中也是如此,我們普通的請求都類似於匿名信,而cookie的出現,就是讓這封信上蓋上了你自己的名字。
在請求時附帶上你的cookie,伺服器放就會知道這次請求來自於誰,然後你點擊個人資訊頁,伺服器就知道是要返回這個cookie對應的用戶的資訊頁了。
在Google瀏覽器中,你可以在控制台Application裡面找到當前網站的所有cookie鍵值對。一般來說用於確認你個人資訊的只有一個鍵值對,但是你也可以把所有的都用上,並不能保證對方伺服器是不是對某些鍵值對也進行檢查了。
很多網站在你沒有登錄的情況下並不會給過多的數據讓你看,所以你的爬蟲需要進行一次模擬登錄。
模擬登錄需要從一個網站的登錄介面開始,因為我們要在這裡用爬蟲發送post請求附帶帳號密碼來登錄對方網站。
拿人人網來舉例。
人人網登錄地址:http://www.renren.com/
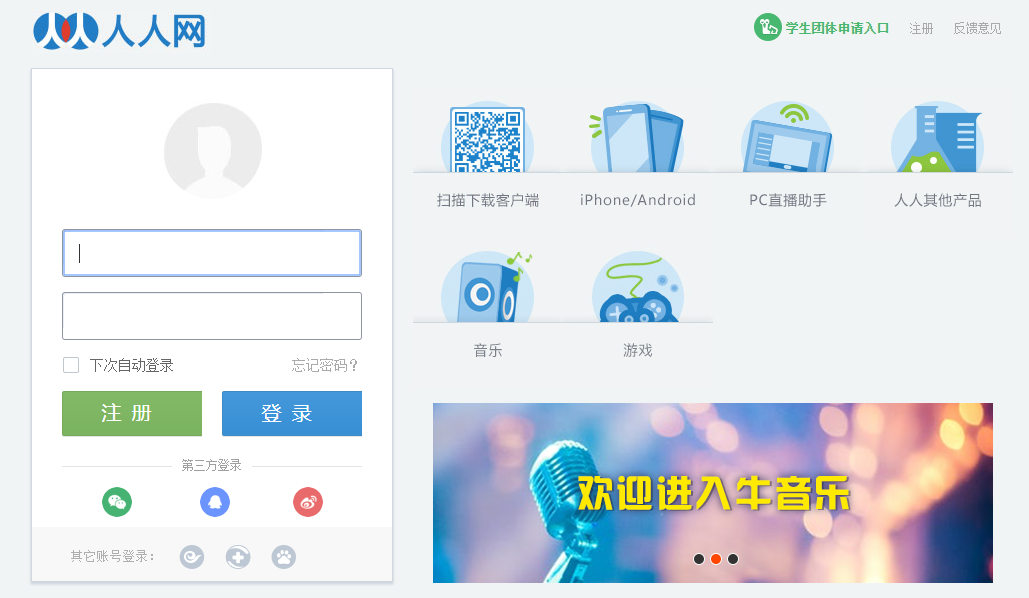
打開控制台,我們可以先嘗試觀察一次登錄的網路請求。很容易就能在裡面找到一個/login的POST請求,登錄的請求都會是POST,因為GET請求的參數會放在URL上,很容易被人攔截看到你的帳號密碼。
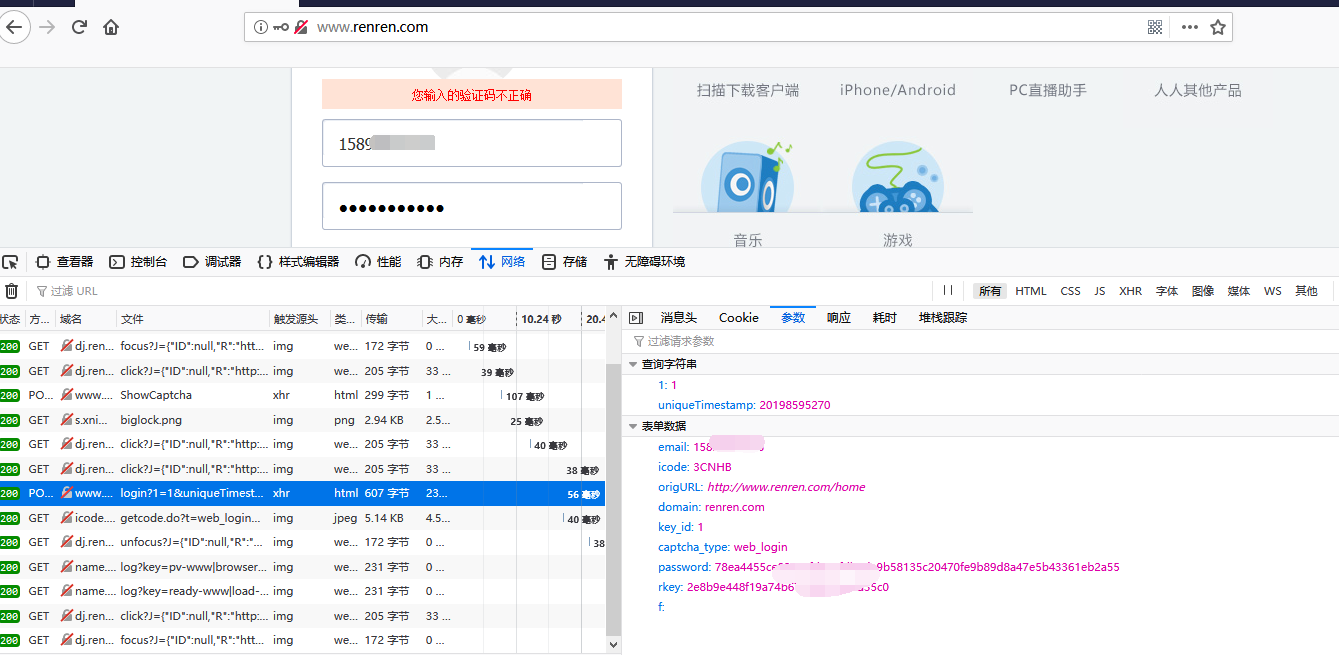
在表單參數中,我們需要注意的就只有email,password和rkey了,其他的照填即可。
email是我們的帳號名,可以是郵箱也可以是電話號。
password是密碼,這個密碼明顯是加密過的,對於這種情況,我們在請求時也要用同樣的演算法對密碼進行加密,但是我們如何知道對方採用了什麼加密演算法呢?
這種情況大多數你都可以在控制台sources裡面找到,在這裡你可以找到網站載入過的所有文件,而加密演算法一般會在js文件中。
sources裡面很明顯有一個叫login.js的文件,那麼它一定和登錄有關係,因為在sources裡面打開js太難看了,會縮成一行,所以我就在控制台打開它了。
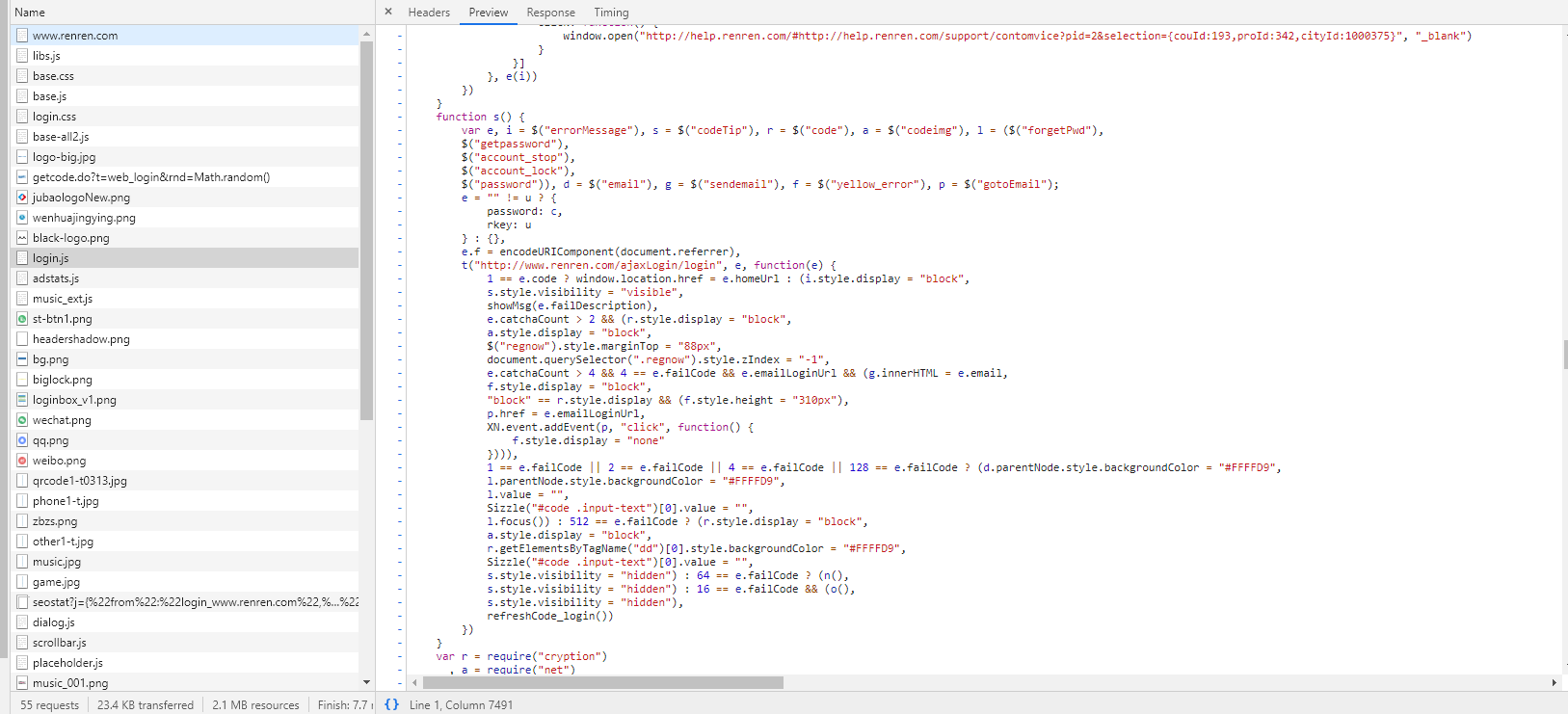
根據password定位到這裡。

可以找到關於登錄時密碼加密的演算法,順便一提,人人網這個login.js的函數命名真的是沒救了,abcd…xyz用了個遍,不知道是為了噁心自己人還是噁心別人寫爬蟲分析它這個login。但是很遺憾的是人人網給爬蟲留下了一個很方便的登錄途徑,我們甚至可以不用自己加密密文!!!
雖然說這裡可以不用自己轉義加密演算法了,但是其實很多網站並不會像人人網這樣暴露出一個action的do事件讓我們可以直接調用的,所以最好還是掌握一些密文加密的那部分。
再來看人人網暴露出的爬蟲便捷登錄的介面。
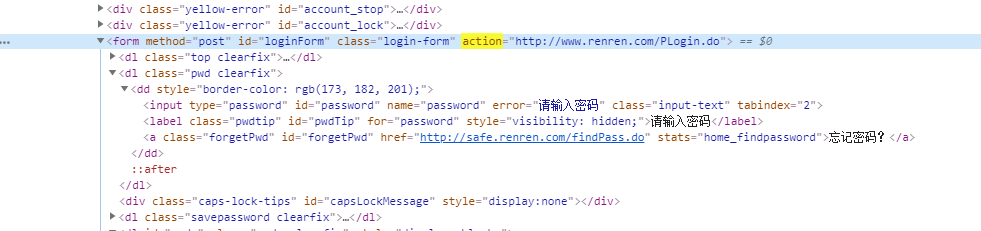
我們只需要調用這個do即可完成登錄。
也就是說,我們模擬這個form來完成請求,在請求前,我們需要把資訊裝填到form中。
先安裝scrapy依賴
pip install scrapy
import scrapy url = "http://www.renren.com/PLogin.do" data = {"email": "xxxxx", "password": "xxxxx"} response = scrapy.FormRequest(url,formdata=data,callback=self.parse_page)登錄成功之後,我們就可以從response中拿到cookie,然後在之後的請求中都附帶上cookie,這樣對方伺服器就知道我們是誰了。
如果之前在網頁登錄失敗次數過多,可能會導致爬蟲模擬登錄需要驗證碼,而此處是考慮不需要驗證碼的情況,所以可能會登錄失敗,解決方法可以是清理本機Cookie。
