sklearn中,數據集劃分函數 StratifiedShuffleSplit.split() 使用踩坑
在SKLearn中,StratifiedShuffleSplit 類實現了對數據集進行洗牌、分割的功能。但在今晚的實際使用中,發現該類及其方法split()僅能夠對二分類樣本有效。
一個簡單的例子如下:
1 import numpy as np 2 from sklearn.model_selection import StratifiedShuffleSplit 3 4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]]) 5 l5 = np.array([0,1,0,2]) 6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1) 7 for train_idx, valid_idx in splt.split(l4, l5): 8 print(train_idx,valid_idx) 9 print('=======') 10 print(l4[train_idx],l4[valid_idx]) 11 print('=======') 12 print(l5[train_idx],l5[valid_idx])
l4 為樣本輸入列表,l5 為樣本輸出列表,其中,樣本輸出(l5)共有3類:[0,1,2] 此時,運行程式會報錯:
ValueError: The least populated class in y has only 1 member, which is too few. The minimum number of groups for any class cannot be less than 2.

報錯資訊的字面意思是:我樣本輸出僅有1類,需要最少2類。但問題是我實際上有3類輸出樣本。這個問題百度了半天也沒找到合適的解答。
後面將3類樣本改為2類,該函數就能正常運行了。
1 import numpy as np 2 from sklearn.model_selection import StratifiedShuffleSplit 3 4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]]) 5 l5 = np.array([0,1,0,1]) 6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1) 7 for train_idx, valid_idx in splt.split(l4, l5): 8 print(train_idx,valid_idx) 9 print('=======') 10 print(l4[train_idx],l4[valid_idx]) 11 print('=======') 12 print(l5[train_idx],l5[valid_idx])
注意,在上方程式碼第5行,將 l5 的值進行修改,樣本輸出僅有[0,1]兩類。
此時運行程式,運行無誤。
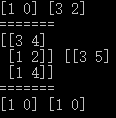
StratifiedShuffleSplit.split() 函數對於多分類問題還是無法正確適配。


