oracle 碎片管理和數據文件resize釋放表空間和磁碟空間(以及sys.wri$_optstat_histgrm_history過大處理)
因此,只能將數據文件縮小到高水位線,因為高水位線以下有一些空白。
因此,在這種情況下(刪除太多),要在數據文件上佔用更多空間,首先,重組表,重置高水位線,然後再次縮小數據文件。
這樣我們可以在磁碟級別上釋放更多的空間。

文檔資料和腳本來自support文獻編號:
2348230.1,1019709.6,1020182.6,186826.1等。
一.遇到的案例
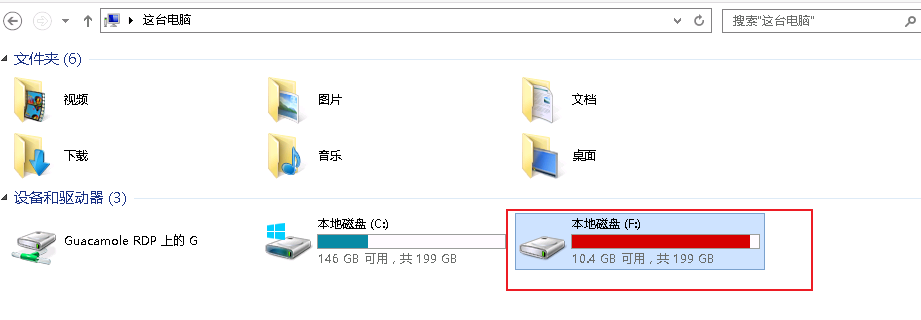
windows oracle 11.2.0.4空間不太夠,然後查看實際表占的空間不足40G,但是數據文件佔用了100多G,業務表名空間數據文件用的都是ASSM管理;除了處理碎片之外,還需要收縮數據文件(縮小所佔用的空間)。
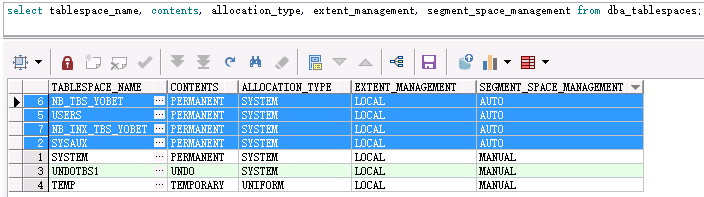
查看錶空間數據文件管理方式:
select tablespace_name, contents, allocation_type, extent_management, segment_space_management from dba_tablespaces;
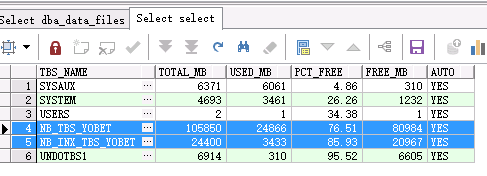
--查看錶空間使用和剩餘大小:
select a.TABLESPACE_NAME tbs_name, round(a.BYTES/1024/1024) Total_MB, round((a.BYTES-nvl(b.BYTES, 0)) /1024/1024) Used_MB, round((1-((a.BYTES-nvl(b.BYTES,0))/a.BYTES))*100,2) Pct_Free, nvl(round(b.BYTES/1024/1024), 0) Free_MB , auto from (select TABLESPACE_NAME, sum(BYTES) BYTES, max(AUTOEXTENSIBLE) AUTO from sys.dba_data_files group by TABLESPACE_NAME) a, (select TABLESPACE_NAME, sum(BYTES) BYTES from sys.dba_free_space group by TABLESPACE_NAME) b where a.TABLESPACE_NAME = b.TABLESPACE_NAME (+) order by ((a.BYTES-b.BYTES)/a.BYTES) desc
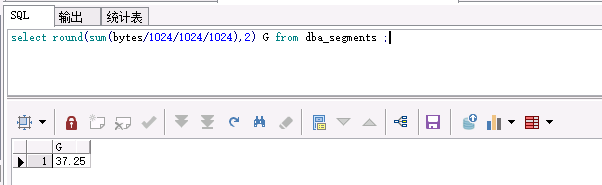
實力上表使用的空間約37GB
select round(sum(bytes/1024/1024/1024),2) G from dba_segments ;
但是數據文件佔用的表空間約144GB
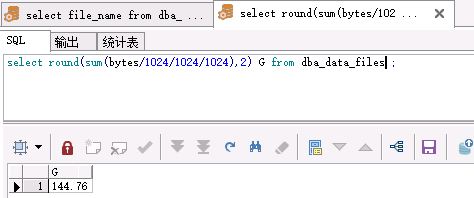
comp sum of nfrags totsiz avasiz on report break on report col tsname format a16 justify c heading 'Tablespace' col nfrags format 999,990 justify c heading 'Free|Frags' col mxfrag format 999,999,990 justify c heading 'Largest|Frag (KB)' col totsiz format 999,999,990 justify c heading 'Total|(KB)' col avasiz format 999,999,990 justify c heading 'Available|(KB)' col pctusd format 990 justify c heading 'Pct|Used' select total.tablespace_name tsname, count(free.bytes) nfrags, nvl(max(free.bytes)/1024,0) mxfrag, total.bytes/1024 totsiz, nvl(sum(free.bytes)/1024,0) avasiz, (1-nvl(sum(free.bytes),0)/total.bytes)*100 pctusd from dba_data_files total, dba_free_space free where total.tablespace_name = free.tablespace_name(+) and total.file_id=free.file_id(+) group by total.tablespace_name, total.bytes /
--這個是support腳本,檢查表空間碎片數
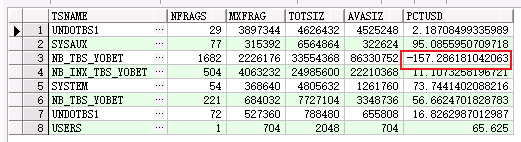
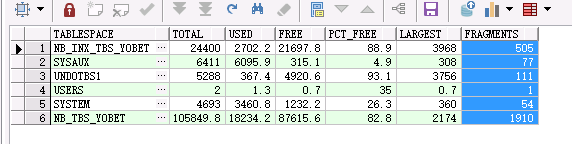
select substr(a.tablespace_name,1,20) tablespace, round(sum(a.total1)/1024/1024, 1) Total, round(sum(a.total1)/1024/1024, 1)-round(sum(a.sum1)/1024/1024, 1) used, round(sum(a.sum1)/1024/1024, 1) free, round(round(sum(a.sum1)/1024/1024, 1)*100/round(sum(a.total1)/1024/1024, 1),1) pct_free, round(sum(a.maxb)/1024/1024, 1) largest, max(a.cnt) fragments from (select tablespace_name, 0 total1, sum(bytes) sum1, max(bytes) MAXB, count(bytes) cnt from dba_free_space group by tablespace_name union select tablespace_name, sum(bytes) total1, 0, 0, 0 from dba_data_files group by tablespace_name ) a group by a.tablespace_name;
–查看錶空間計算FSFI(Free Space Fragmentation Index)值
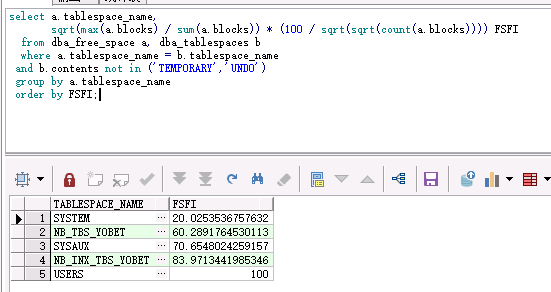
select a.tablespace_name, sqrt(max(a.blocks) / sum(a.blocks)) * (100 / sqrt(sqrt(count(a.blocks)))) FSFI from dba_free_space a, dba_tablespaces b where a.tablespace_name = b.tablespace_name and b.contents not in ('TEMPORARY','UNDO') group by a.tablespace_name order by FSFI;

這兩個表空間是業務表空間,如果FSFI值 < 30%,則該表空間的碎片較多(該資料庫每天都有定時任務收集統計資訊,不會存在統計資訊的偏差);
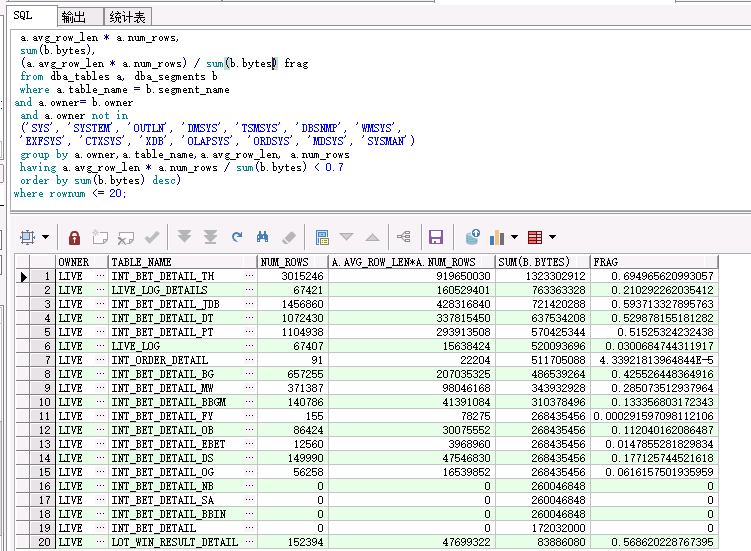
–檢查碎片最嚴重的前100張表,實際我只檢查了前20張表就夠了
col frag format 999999.99 col owner format a30; col table_name format a30; select * from ( select a.owner, a.table_name, a.num_rows, a.avg_row_len * a.num_rows, sum(b.bytes), (a.avg_row_len * a.num_rows) / sum(b.bytes) frag from dba_tables a, dba_segments b where a.table_name = b.segment_name and a.owner= b.owner and a.owner not in ('SYS', 'SYSTEM', 'OUTLN', 'DMSYS', 'TSMSYS', 'DBSNMP', 'WMSYS', 'EXFSYS', 'CTXSYS', 'XDB', 'OLAPSYS', 'ORDSYS', 'MDSYS', 'SYSMAN') group by a.owner,a.table_name,a.avg_row_len, a.num_rows having a.avg_row_len * a.num_rows / sum(b.bytes) < 0.7 order by sum(b.bytes) desc) where rownum <= 100;
–檢查Oracle在索引碎片
col tablespace_name format a20; col owner format a10; col index_name format a30; select id.tablespace_name, id.owner, id.index_name, id.blevel, sum(sg.bytes) / 1024 / 1024, sg.blocks, sg.extents from dba_indexes id, dba_segments sg where id.owner = sg.owner and id.index_name = sg.segment_name and id.tablespace_name = sg.tablespace_name and id.owner not in ('SYS', 'SYSTEM', 'USER', 'DBSNMP', 'ORDSYS', 'OUTLN') and sg.extents > 100 and id.blevel >= 3 group by id.tablespace_name, id.owner, id.index_name, id.blevel, sg.blocks, sg.extents having sum(sg.bytes) / 1024 / 1024 > 100;
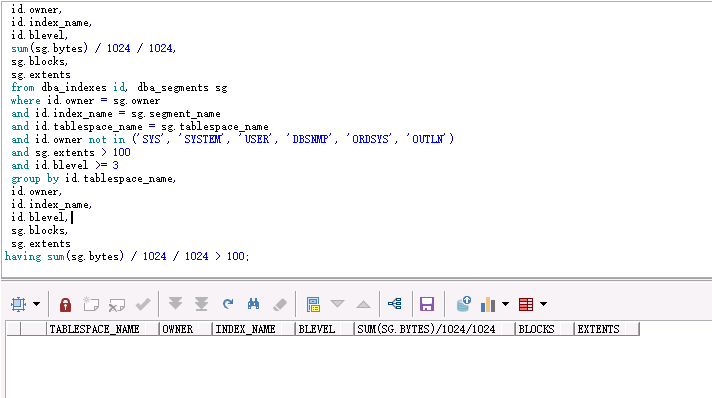
如果有索引層級未Blevel >=3,並且索引大小超過100M的索引。則需要進行Analyze index。
- Analyze index方法
analyze index <Index_name> validate structure;
select DEL_LF_ROWS * 100 / decode(LF_ROWS, 0, 1, LF_ROWS) PCT_DELETED from index_stats;
二.碎片處理方式
2.1.首選shrink
alter table <表名> enable row movement;
alter table <表名> shrink space compact; — 只壓縮數據不下調HWM
alter table <表名> shrink space; — 下調HWM;
alter table <表名> shrink space cascade; — 壓縮表及相關數據段並下調HWM
alter table <表名> disable row movement;
select * from (
select
a.table_name,
‘alter table ‘||a.table_name||’ enable row movement ; ‘,
‘alter table ‘||a.table_name||’ shrink space compact ; ‘,
‘alter table ‘||a.table_name||’ shrink space cascade ; ‘,
‘alter table ‘||a.table_name||’ disable row movement ;’,
a.num_rows,
a.avg_row_len * a.num_rows,
round(sum(b.bytes/1024/1024/1024),2) G,
(a.avg_row_len * a.num_rows) / sum(b.bytes) frag
from dba_tables a, dba_segments b
where a.table_name = b.segment_name
and a.owner= b.owner
and a.owner not in
(‘SYS’, ‘SYSTEM’, ‘OUTLN’, ‘DMSYS’, ‘TSMSYS’, ‘DBSNMP’, ‘WMSYS’,
‘EXFSYS’, ‘CTXSYS’, ‘XDB’, ‘OLAPSYS’, ‘ORDSYS’, ‘MDSYS’, ‘SYSMAN’)
group by a.owner,a.table_name,a.avg_row_len, a.num_rows
having a.avg_row_len * a.num_rows / sum(b.bytes) < 0.7
order by round(sum(b.bytes/1024/1024/1024),2) desc)
where rownum <= 20;
把生產的shrink語句執行一下。

進行shrink之後,進行數據文件的收縮如下。
執行後進行數據文件的收縮:
SELECT a.tablespace_name, 'alter database datafile ''' || a.file_name || ''' resize ' || round(ceil(b.resize_to / 1024 / 1024 / 1024), 2) || 'G;' AS "resize_SQL", round(a.bytes / 1024 / 1024 / 1024, 2) AS "current_bytes(GB)", round(a.bytes / 1024 / 1024 / 1024 - b.resize_to / 1024 / 1024 / 1024, 2) AS "shrink_by_bytes(GB)", round(ceil(b.resize_to / 1024 / 1024 / 1024), 2) AS "resize_to_bytes(GB)" FROM dba_data_files a, (SELECT file_id, MAX((block_id + blocks - 1) * (select value from v$parameter where name = 'db_block_size')) AS resize_to FROM dba_extents GROUP by file_id) b WHERE a.file_id = b.file_id ORDER BY a.tablespace_name, a.file_name;

可以看到數據文件還是下不去,微乎其微的影響,後面就嘗試了move 操作。
2.2進行move到新的表空間操作(全局索引會失效)
create tablespace tbs_move datafile ‘F:\APP\ADMINISTRATOR\ORADATA\TTFC\tbd_move.DBF’ size 5g autoextend on next 256m;
select b.owner,
b.segment_name,
ROUND(sum(bytes / 1024 / 1024 / 1024), 2) G
from dba_segments b
where segment_type like ‘TABLE%’ having
sum(b.BYTES / 1024 / 1024 / 1024) >= 1
group by b.owner, b.segment_name;

with d as ( select b.owner, b.segment_name from dba_segments b where b.segment_type like 'TABLE%' having sum(b.BYTES / 1024 / 1024 / 1024) >= 1 group by b.owner, b.segment_name ) select a.segment_name,a.owner,a.segment_type, case when a.segment_type='TABLE' then 'alter table ' || a.owner || '.' || a.segment_name || ' move tablespace tbs_move;' when segment_type='TABLE PARTITION' then 'alter table '|| a.owner || '.' || a.segment_name || ' move partition '|| a.PARTITION_NAME ||' tablespace tbs_move;' when segment_type='TABLE SUBPARTITION' then 'alter table ' || a.owner || '.' || a.segment_name || ' move subpartition '|| a.PARTITION_NAME ||' tablespace tbs_move;' end as sqltext from dba_segments a inner join d on a.segment_name=d.segment_name and a.owner=d.owner where a.segment_type like 'TABLE%';
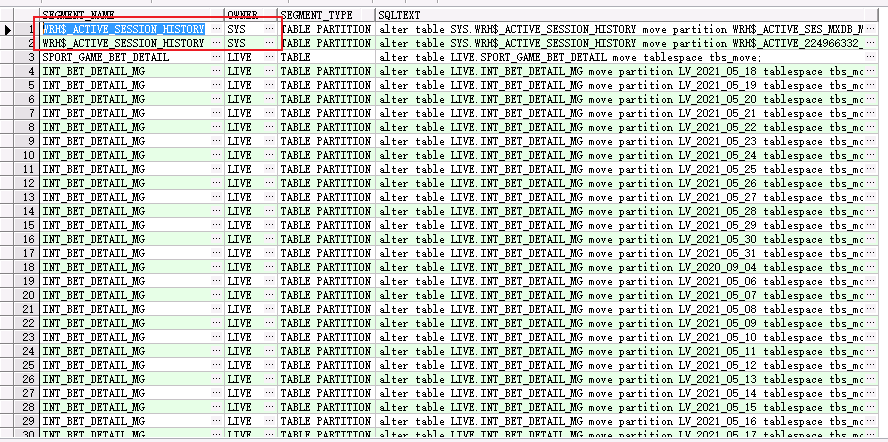
sys用戶開頭的表後面解決,非SYS得先move,move到tbs_move 表空間。
全局索引move後失效,進行重建:
--所有非分區和全局索引重建
select a.status, 'alter index ' || A.owner || '.' || a.index_name || ' rebuild tablespace TBS_MOVE online nologging ;' AS REBUILD_SQL from dba_indexes a WHERE --a.STATUS = 'UNUSABLE' and a.PARTITIONED = 'NO' AND A.TABLE_NAME IN ('INT_BET_DETAIL_CQ', 'INT_BET_DETAIL_KY', 'INT_BET_DETAIL_HB', 'INT_BET_DETAIL_MG', 'SPORT_GAME_BET_DETAIL', 'INT_BET_DETAIL_AG') AND A.OWNER = 'LIVE'
alter index LIVE.SPORT_GAME_BET_DETAIL_CODE rebuild tablespace TBS_MOVE online nologging ;
alter index LIVE.SYS_C0011675 rebuild tablespace TBS_MOVE online nologging ;
--一級主分區索引重建 select distinct 'alter index ' || A.INDEX_OWNER || '.' || a.index_name || ' rebuild PARTITION ' || a.partition_name || ' tablespace TBS_MOVE online nologging;' from dba_ind_partitions a INNER JOIN dba_part_indexes t ON T.owner = A.INDEX_OWNER AND a.index_name = T.index_name where -- a.STATUS ='UNUSABLE' and INDEX_OWNER = 'LIVE' and T.SUBPARTITIONING_TYPE ='NONE' AND T.TABLE_NAME IN ('INT_BET_DETAIL_CQ', 'INT_BET_DETAIL_KY', 'INT_BET_DETAIL_HB', 'INT_BET_DETAIL_MG', 'SPORT_GAME_BET_DETAIL', 'INT_BET_DETAIL_AG');
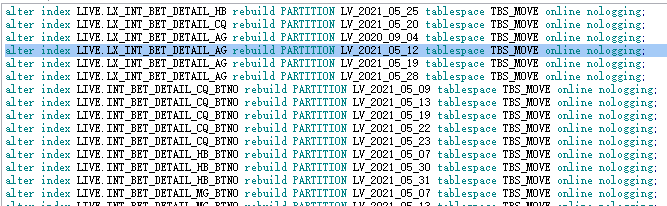
--二級分區索引重建
select distinct a.STATUS,
‘alter index ‘ || A.INDEX_OWNER || ‘.’ || a.index_name ||
‘ rebuild SUBPARTITION ‘ || a.subpartition_name ||
‘ tablespace TBS_MOVE online nologging;’
from dba_ind_subpartitions a
INNER JOIN dba_part_indexes t
ON T.owner = A.INDEX_OWNER
AND a.index_name = T.index_name
where
— a.STATUS =’UNUSABLE’ and
INDEX_OWNER = ‘LIVE’
AND T.SUBPARTITIONING_TYPE <> ‘NONE’
AND T.TABLE_NAME IN (‘INT_BET_DETAIL_CQ’,
‘INT_BET_DETAIL_KY’,
‘INT_BET_DETAIL_HB’,
‘INT_BET_DETAIL_MG’,
‘SPORT_GAME_BET_DETAIL’,
‘INT_BET_DETAIL_AG’);
注意,分區欄位的組合索引需要重新刪除重建,不能rebuild。
通過上面的move操作。
以及分區表索引重建(move後,分區表本地索引繼續有效,但是為了壓縮原索引表空間,我重建到新的表空間)

經過一系列操作,發現數據文件回收不了也是微乎其微。

Move會移動高水位,但不會釋放申請的空間,是在高水位以下(below HWM)的操作;
而shrink space 同樣會移動高水位,但也會釋放申請的空間,是在高水位上下(below and above HWM)都有的操作,表段所在表空間的段空間管理(segment space management)必須為auto還要開啟行移動。
由於業務佔用數據文件較大的是分區表,我查看分區參數,進行調整後,看看是否數據文件可以resize.
SELECT A.KSPPINM NAME, B.KSPPSTVL VALUE, A.KSPPDESC DESCRIPTION
FROM sys.X$KSPPI A, sys.X$KSPPCV B
WHERE A.INDX = B.INDX
AND A.KSPPINM LIKE ‘_partition_large_extents’;
查看隱含參數,從11.2.0.2開始創建分區表,每個分區默認大小為8M,是由_partition_large_extents參數控制,可以算是11.2.0.2開始的一個新特性,為了減少extent數量,提高分區表性能,而引入的一個參數,默認為true,即分區表的每個extent為8M。
當參數_partition_large_extents等於true時(此時可能不可見),創建分區表默認佔用空間大小為每個分區8m,而普通表默認佔據空間大小僅0.0625m(64k)。而當_index_partition_large_extents為true時,創建分區索引時,默認分區大小為8m,而創建普通索引默認大小為64k。
alter system set “_partition_large_extents”=false scope=spfile sid=’*’;
alter system set “_index_partition_large_extents”=false scope=spfile sid=’*’;
由於我使用的是分區表,進行參數修改後重啟資料庫。後續發現仍然不能resize 數據文件,resize微乎其微。
2.3 expdp/impdp 導入導出方式
由於上面shrink,move方式都失敗,索引進行第三中導入導出方式(按照用戶導出),後續刪除表空間,然後新建表空間,還好數據量不大,停機時間不久。
expdp system/XXX dumpfile=live0515.dmp logfile=live0515.log directory=BET_DIR schemas=live compression=all
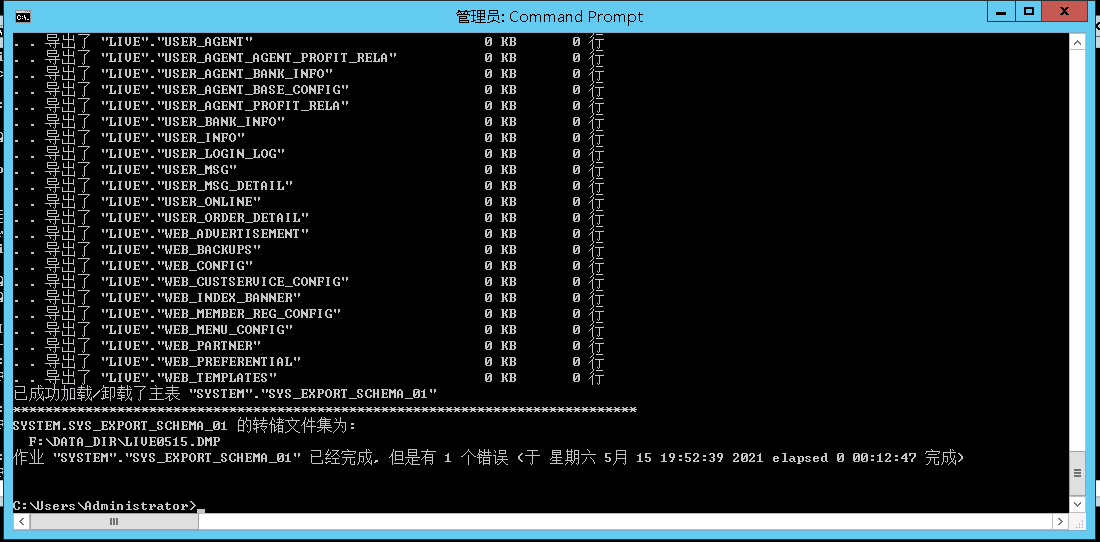
drop tablespace NB_TBS_YOBET including contents and datafiles;
drop tablespace NB_INX_TBS_YOBET including contents and datafiles;
並且手動的刪除數據文件後重新建表空間。
create tablespace NB_TBS_YOBET datafile ‘F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_TBS_YOBET01.DBF’ size 5g autoextend on next 256M;
create tablespace NB_INX_TBS_YOBET datafile ‘F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_INX_TBS_YOBET01.DBF’ size 2g autoextend on next 256M;
alter tablespace NB_TBS_YOBET add datafile ‘F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_TBS_YOBET02.DBF’ size 5g autoextend on next 256M;
在進行數據導入。
impdp system/XXX directory=BET_DIR dumpfile=LIVE0515.DMP logfile=imp.log table_exists_action=replace
查看導入後的的表空間計算FSFI
select a.tablespace_name,
sqrt(max(a.blocks) / sum(a.blocks)) * (100 / sqrt(sqrt(count(a.blocks)))) FSFI
from dba_free_space a, dba_tablespaces b
where a.tablespace_name = b.tablespace_name
and b.contents not in (‘TEMPORARY’,’UNDO’)
group by a.tablespace_name
order by FSFI;
select
total.tablespace_name tsname,
count(free.bytes) nfrags,
nvl(max(free.bytes)/1024,0) mxfrag,
total.bytes/1024 totsiz,
nvl(sum(free.bytes)/1024,0) avasiz,
(1-nvl(sum(free.bytes),0)/total.bytes)*100 pctusd
from
dba_data_files total,
dba_free_space free
where
total.tablespace_name = free.tablespace_name(+)
and total.file_id=free.file_id(+)
group by
total.tablespace_name,
total.bytes
/
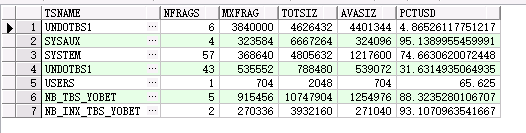
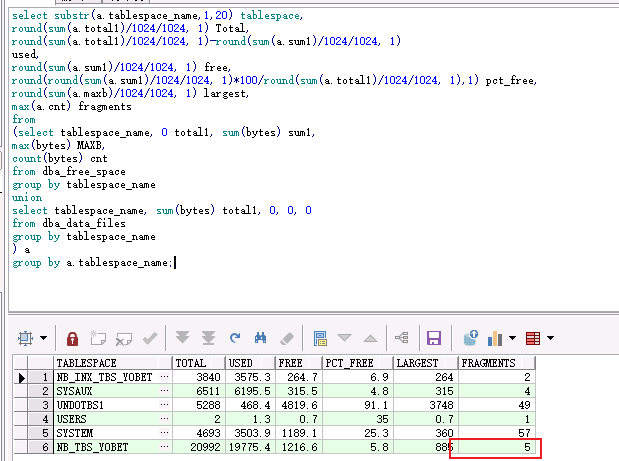
在為進行expdp 和重建表空間,impdp之後,明顯碎片數減少,之前是1910.
三.WRH$_ACTIVE_SESSION_HISTORY 過大
SYS.WRH$_ACTIVE_SESSION_HISTORY 達到了2G,Oracle根據保留策略決定需要清除哪些行。在AWR表的情況下,有一種特殊的機制可以將快照數據存儲在分區中。從這些表中清除數據的一種方法是通過刪除僅包含超出保留條件的行的分區。在夜間清除任務期間,僅當分區中的所有數據均已到期時才刪除分區。如果分區包含至少一行,根據保留策略,不應刪除該行,則不會刪除該分區,因此該表將包含舊數據。
如果沒有發生分區拆分(出於某種原因),那麼我們最終將不得不等待最新的條目到期,然後才能刪除它們所在的分區。這可能意味著一些較舊的條目可以在其到期日期之後保留很長時間。結果是數據沒有按預期清除。
清除參照support Doc ID 387914.1,Doc ID 1965061.1
@F:\app\Administrator\product\11.2.0.4\dbhome\RDBMS\ADMIN\awrinfo.sql

可以查看awr 佔了大部分內容。
select systimestamp – min(savtime) from sys.wri$_optstat_histgrm_history;

exec dbms_stats.purge_stats(sysdate – 1);

刪除昨天前的awr的保留的資訊。
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name=’WRH$_ACTIVE_SESSION_HISTORY’;
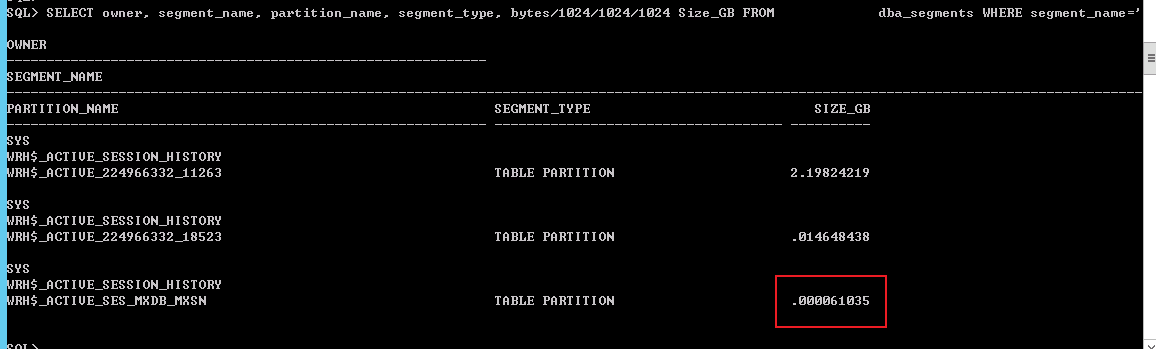
把awr分區分割成更小的分區。
alter session set “_swrf_test_action” = 72;
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name=’WRH$_ACTIVE_SESSION_HISTORY’;

set serveroutput on declare CURSOR cur_part IS SELECT partition_name from dba_tab_partitions WHERE table_name = 'WRH$_ACTIVE_SESSION_HISTORY'; query1 varchar2(200); query2 varchar2(200); TYPE partrec IS RECORD (snapid number, dbid number); TYPE partlist IS TABLE OF partrec; Outlist partlist; begin dbms_output.put_line('PARTITION NAME SNAP_ID DBID'); dbms_output.put_line('--------------------------- ------- ----------'); for part in cur_part loop query1 := 'select min(snap_id), dbid from sys.WRH$_ACTIVE_SESSION_HISTORY partition ('||part.partition_name||') group by dbid'; execute immediate query1 bulk collect into OutList; if OutList.count > 0 then for i in OutList.first..OutList.last loop dbms_output.put_line(part.partition_name||' Min '||OutList(i).snapid||' '||OutList(i).dbid); end loop; end if; query2 := 'select max(snap_id), dbid from sys.WRH$_ACTIVE_SESSION_HISTORY partition ('||part.partition_name||') group by dbid'; execute immediate query2 bulk collect into OutList; if OutList.count > 0 then for i in OutList.first..OutList.last loop dbms_output.put_line(part.partition_name||' Max '||OutList(i).snapid||' '||OutList(i).dbid); dbms_output.put_line('---'); end loop; end if; end loop; end; /

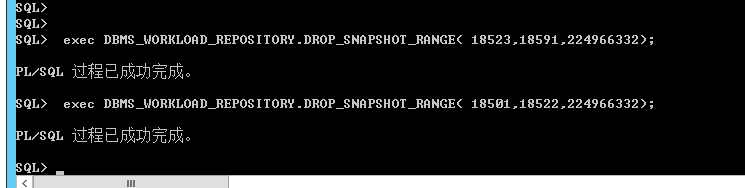
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( low_snap_id IN NUMBER,high_snap_id IN NUMBER, dbid IN NUMBER DEFAULT NULL);
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( 18523,18591,224966332);
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( 18501,18522,224966332);
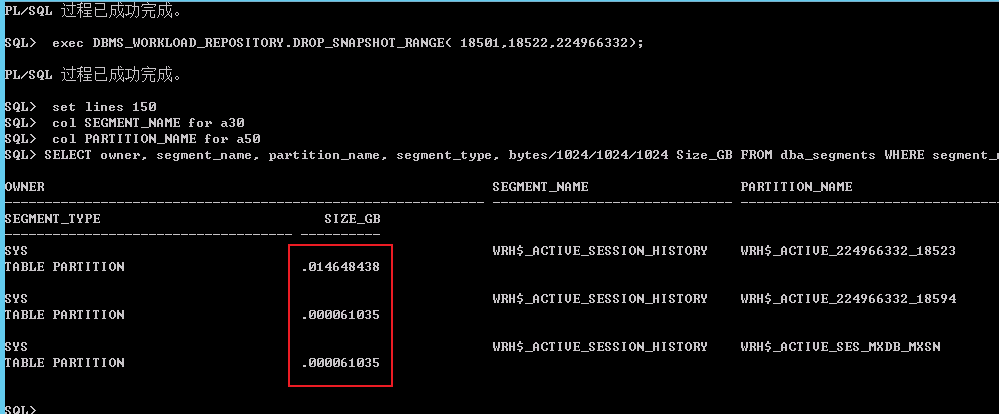
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name=’WRH$_ACTIVE_SESSION_HISTORY’;
進行awrinfo 再次查看:
@F:\app\Administrator\product\11.2.0.4\dbhome\RDBMS\ADMIN\awrinfo.sql

明顯的看到下降了。
四.總結
表空間碎片大多數資料庫都會存在,可以定時的監控,在業務範圍允許的情況下,進行處理,達到節約空間的目的。
以下是經常用的方法總結。
表級別碎片整理方法:
1.首選shrink
2.導入導出 exp/imp expdp/impdp
3.CATS
4.table move tablespace
5.Online Redefinition
其中注意的是:
1.Move會移動高水位,但不會釋放申請的空間,是在高水位以下(below HWM)的操作,同時分區表的全局索引需要重建,且有分區欄位的組合索引也要刪除後重建(組合索引不能rebuild);
2.shrink space 同樣會移動高水位,但也會釋放申請的空間,是在高水位上下(below and above HWM)都有的操作,表段所在表空間的段空間管理(segment space management)必須為auto還要開啟行移動。
3.導入導出對業務的影響程度較大,24*7的話比較難使用該方法;但是這個方法也有優點,就是表段沒有佔用那麼多數據文件時,導入表空間數據文件只會站表段的大小,我就是採取的這種方法縮小數據文件,而move,和shrink 並不能讓我resize數據文件,釋放磁碟空間。
4.cast 只適合單個表,多表的話操作比較麻煩。
5.在線重定義這個方法已經落後,不推薦了。


