JDBC核心技術(獲取資料庫鏈接、資料庫事務、資料庫鏈接池)
@
前言
數據的持久化
- 持久化(
persistence):數據持久化意味著把記憶體中的數據保存到硬碟上加以「固化」,而持久化的實現過程大多通過各種關係資料庫來完成。 - 持久化的主要應用是將記憶體中的數據存儲在關係型資料庫、磁碟文件以及XML數據文件中。
Java數據存儲技術
JDBC直接訪問資料庫。JDO(java Data Object)- 第三方O/R工具:如
Hibernate,MyBatis等。
JDBC是java訪問資料庫的基石,JDO、Hibernate、MyBatis等只是更好的封裝了JDBC。
JDBC介紹
JDBC(Java Database Connectivity)是一個獨立於特定資料庫管理系統、通用的SQL資料庫存取和操作的公共介面(一組API),定義了用來訪問資料庫的標準Java類庫,(java.sql,javax.sql)使用這些類庫可以以一種標準的方法、方便地訪問資料庫資源。JDBC為訪問不同的資料庫提供了一種統一的途徑,為開發者屏蔽了一些細節問題。JDBC的目標是使Java程式設計師使用JDBC可以連接任何提供了JDBC驅動程式的資料庫系統,這樣就使得程式設計師無需對特定的資料庫系統的特點有過多的了解,從而大大簡化和加快了開發過程。
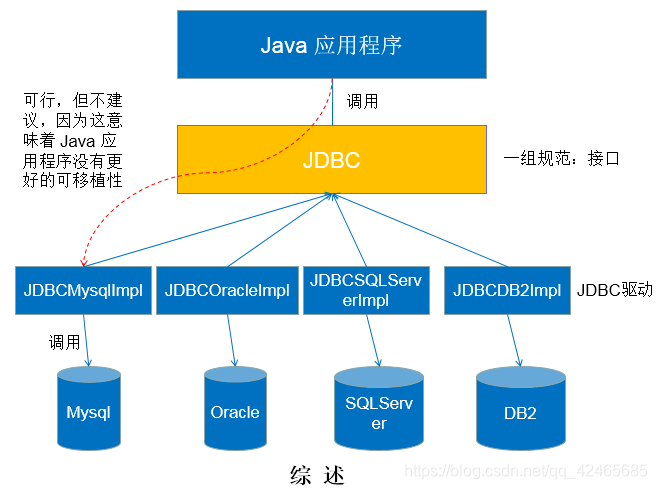
JDBC體系結構
JDBC介面(API)包括兩個層次:- 面嚮應用的API:
Java API,抽象介面,供應用程式開發人員使用(連接資料庫,執行SQL語句,獲得結果)。 - 面向資料庫的API:
Java Driver API,供開發商開發資料庫驅動程式用。
- 面嚮應用的API:
JDBC是sun公司提供一套用於資料庫操作的介面,java程式設計師只需要面向這套介面編程即可。
不同的資料庫廠商,需要針對這套介面,提供不同實現。不同的實現的集合,即為不同資料庫的驅動。 ————面向介面編程
獲取資料庫鏈接
Driver介面
java.sql.Driver介面是所有JDBC驅動程式需要實現的介面。這個介面是提供給資料庫廠商使用的,不同資料庫廠商提供不同的實現。- 在程式中不需要直接去訪問實現了
Driver介面的類,而是由驅動程式管理器類(java.sql.DriverManager)去調用這些Driver實現。 - MySql驅動:
com.mysql.jdbc.Driver
載入註冊JDBC驅動
-
載入驅動:載入
JDBC驅動可有通過Class類的forName()靜態方法,向其傳遞要載入的JDBC驅動的類名(com.mysql.jdbc.Driver)。Class.forName("com.mysql.jdbc.Driver"); -
註冊驅動:
DriverManager類是驅動程式管理類,負責管理驅動程式。DriverManager.registerDriver(new Driver());//註冊驅動一般情況下,我們不會顯示的去調用
DriverManager類下的registerDriver()方法來註冊驅動程式實例,因為在Driver靜態程式碼塊中已經包含了,當我們載入Driver後就註冊了驅動。/*源碼:*/ public class Driver extends NonRegisteringDriver implements java.sql.Driver { static { try { java.sql.DriverManager.registerDriver(new Driver()); } catch (SQLException E) { throw new RuntimeException("Can't register driver!"); } } ... }
獲取資料庫鏈接
- 通過
DriverManager.getConnection(String url,String user, String password)得到Connection的資料庫的鏈接對象。url資料庫鏈接地址:jdbc:mysql://localhost:3306/testjdbc::協議。myslq:子協議;用於標識一個資料庫驅動localhost:3306/test:子名稱;對應伺服器的IP地址、埠號、資料庫名稱
- 幾種常見資料庫的
JDBC URL。MySql的鏈接URL:jdbc:mysql://主機名稱:mysql服務埠號/資料庫名稱?參數=值&參數=值jdbc:mysql://localhost:3306/testjdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8(如果JDBC程式與伺服器端的字符集不一致,會導致亂碼,那麼可以通過參數指定伺服器端的字符集)jdbc:mysql://localhost:3306/test?user=root&password=root
Oracle 9i的連接URL:jdbc:oracle:thin:@主機名稱:oracle服務埠號:資料庫名稱jdbc:oracle:thin:@localhost:1521:test
SQLServer的連接URL:jdbc:sqlserver://主機名稱:sqlserver服務埠號:DatabaseName=資料庫名稱jdbc:sqlserver://localhost:1433:DatabaseName=test
資料庫鏈接方式(實例)
方式一:程式碼中顯示出現了第三方資料庫API(不推薦)
public void testConnection() {
Driver driver = null;
Connection connect = null;
try {
//獲取Driver實現類對象
Driver driver = new com.mysql.jdbc.Driver();
//提供資料庫鏈接
String url = "jdbc:mysql://localhost:3306/test";
//用戶名和密碼封裝在Properties
Properties info = new Properties();
info.setProperty("user","root");
info.setProperty("password","root");
//獲取鏈接
connect = driver.connect(url,info);
} catch (SQLException e) {
e.printStackTrace();
}
//業務處理
System.out.println(connect);
...
//關閉鏈接釋放資源
try {
if (connect != null) connect.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
方式二:程式碼中不體現第三方資料庫API(推薦)
-
創建
jdbc.properties配置文件# 配置資料庫鏈接基本資訊 user=root password=root url=jdbc:mysql://localhost:3306/test?useUnicode=true&cahracterEncoding=utf8 driverClass=com.mysql.jdbc.Driver -
同過反射實現資料庫連接
public class ConnectionTest { public void testConnection() { Connection connection = null; try { //1.通過類的載入器來指明配置文件 InputStream resourceAsStream = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties"); //2.配置文件中基本配置資訊 Properties properties = new Properties(); // 2.1載入文件 properties.load(resourceAsStream); String user = properties.getProperty("user"); String password = properties.getProperty("password"); String url = properties.getProperty("url"); String driverClass = properties.getProperty("driverClass"); //3.載入Driver Class.forName(driverClass); //4.獲取鏈接 connection = DriverManager.getConnection(url, user, password); } catch (Exception e) { e.printStackTrace(); } //業務處理 System.out.println(connection); ... //5.關閉鏈接釋放資源 try { if (connection != null) connection.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } } }
使用配置文件的好處:
- 實現了程式碼和數據的分離,如果需要修改配置資訊,直接在配置文件中修改,不需要深入程式碼
- 如果修改了配置資訊,省去重新編譯的過程。
- 實現了數據與程式碼的分離;實現了解耦。
PreparedStatement實現CRUD操作
兩種技術
JDBC結果集的元數據:ResultSetMetaData。- 獲取列數:
getColumnCount() - 獲取列的別名:
getColumnLabel()
- 獲取列數:
- 通過反射,創建指定類的對象,獲取指定的屬性並賦值。
PreparedStatement介紹
-
資料庫連接被用於向資料庫伺服器發送命令和
SQL語句,並接受資料庫伺服器返回的結果。其實一個資料庫連接就是一個Socket連接。 -
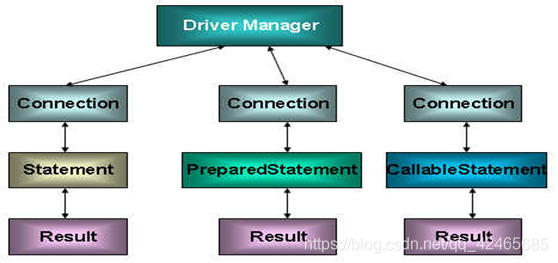
在
java.sql包中有 3 個介面分別定義了對資料庫的調用的不同方式:-
Statement:用於執行靜態SQL語句並返回它所生成結果的對象。 -
PrepatedStatement:SQL語句被預編譯並存儲在此對象中,可以使用此對象多次高效地執行該語句。 -
CallableStatement:用於執行SQL存儲過程。
-
使用Statement操作數據表的弊端(不推薦)
-
通過調用
Connection對象的createStatement()方法創建該對象。該對象用於執行靜態的SQL語句,並且返回執行結果。 -
Statement介面中定義了下列方法用於執行SQL語句://執行更新操作INSERT、UPDATE、DELETE int excuteUpdate(String sql) throws SQLException; //執行查詢操作SELECT ResultSet executeQuery(String sql) throws SQLException; -
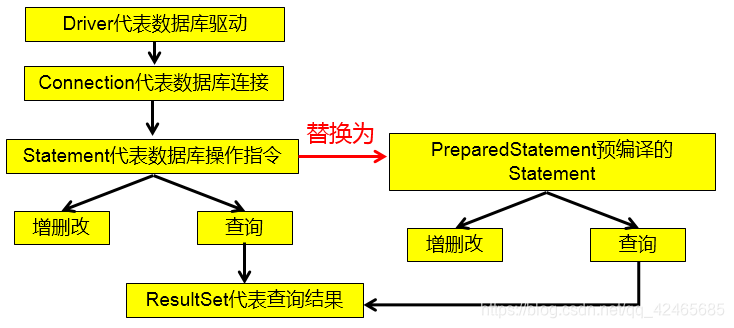
但是使用
Statement操作數據表存在弊端:- 問題一:存在拼串操作,繁瑣。
- 問題二:存在
SQL注入問題。
-
SQL注入是利用某些系統沒有對用戶輸入的數據進行充分的檢查,而在用戶輸入數據中注入非法的SQL語句段或命令(如:SELECT * FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1') ,從而利用系統的SQL引擎完成惡意行為的做法。 -
對於
Java而言,要防範SQL注入,只要用PreparedStatement(繼承於Statement) 取代Statement就可以了。
PreparedStatement的使用
PreparedStatement介紹
-
調用
Connection對象里的preparedStatement(String sql)方法得到PreparedStatement對象。-
預編譯
SQL語句:PreparedStatement preparedStatement = connection.prepareStatement(sql); -
PreparedStatement對象所代表的SQL語句中的參數用問號(?)來表示,調用PreparedStatement對象的setXxx()(Xxx:Object、String、int...)方法來設置這些參數。setXxx()(Xxx:Object、String、int...) 方法有兩個參數,第一個參數是要設置的SQL語句中的參數的索引(從 1 開始),第二個是設置的SQL語句中的參數的值。
案例:
String sql = "update user_table set name = ?, email= ?, age = ?, birth = ? where id = ?"; //預編譯SQL語句,返回PreparedStatement的實例 PreparedStatement preparedStatement = connection.prepareStatement(sql); //填充佔位符 preparedStatement.setString(1,"托馬斯·克里斯特"); //name preparedStatement.setString(2,"[email protected]"); //email preparedStatement.setInt(3,21); //age SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); java.util.Date parse = simpleDateFormat.parse("2000-01-01"); preparedStatement.setDate(4,new Date(parse.getTime())); //birth preparedStatement.setObject(5,1); //id -
PreparedStatement VS Statmenet
-
程式碼的可讀性和可維護性。
-
PreparedStatement能最大可能提高性能:DBServer會對預編譯語句提供性能優化。因為預編譯語句有可能被重複調用,所以語句在被DBServer的編譯器編譯後的執行程式碼被快取下來,那麼下次調用時只要是相同的預編譯語句就不需要編譯,只要將參數直接傳入編譯過的語句執行程式碼中就會得到執行。- 在
statement語句中,即使是相同操作但因為數據內容不一樣,所以整個語句本身不能匹配,沒有快取語句的意義.事實是沒有資料庫會對普通語句編譯後的執行程式碼快取。這樣每執行一次都要對傳入的語句編譯一次。 - (語法檢查,語義檢查,翻譯成二進位命令,快取)
-
PreparedStatement可以防止SQL注入
JAVA於SQL對應數據類型轉換
| Java類型 | SQL類型 |
|---|---|
| boolean | BIT |
| byte | TINYINT |
| short | SMALLINT |
| int | INTEGER |
| long | BIGINT |
| String | CHAR,VARCHAR,LONGVARCHAR |
| byte array | BINARY , VAR BINARY |
| java.sql.Date | DATE |
| java.sql.Time | TIME |
| java.sql.Timestamp | TIMESTAMP |
ResultSet 於 ResultSetMetaData
兩種思想
- 面向介面編程的思想
- ORM思想(Object Relational Mapping)
- 一個數據表對應一個Java類(JavaBean)。
- 表中的一條記錄對應Java類的一個對象。
- 表中的一個欄位對應Java類的一個屬性。
注意:在Java類的屬性名與SQL欄位不同時要起別名
ResultSet
-
查詢需要調用
PreparedStatement的executeQuery()方法,查詢結果是一個ResultSet對象。 -
ResultSet對象以邏輯表格的形式封裝了執行資料庫操作的結果集,ResultSet介面由資料庫廠商提供實現。 -
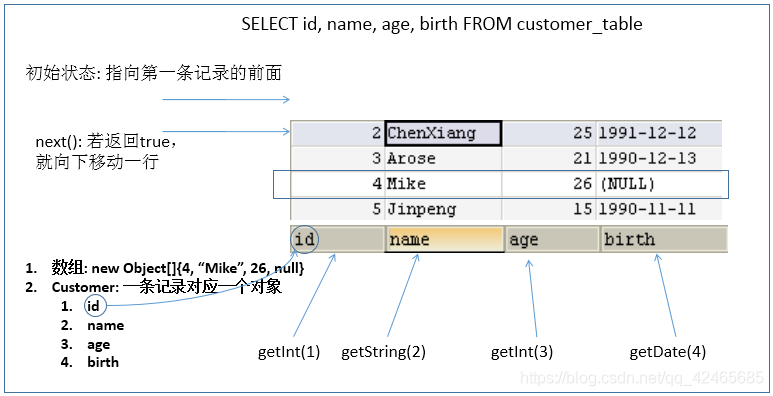
ResultSet返回的實際上就是一張數據表。有一個指針指向數據表的第一條記錄的前面。 -
ResultSet對象維護了一個指向當前數據行的游標,初始的時候,游標在第一行之前,可以通過ResultSet對象的next()方法移動到下一行。調用next()方法檢測下一行是否有效。若有效,該方法返回true,且指針下移。相當於Iterator對象的hasNext()和next()方法的結合體。 -
當指針指向一行時, 可以通過調用
getXxx(int index)或getXxx(int columnName)獲取每一列的值。- 例如:
getInt(1),getString("name") - 注意:Java與資料庫交互涉及到的相關Java API中的索引都從1開始。
- 例如:
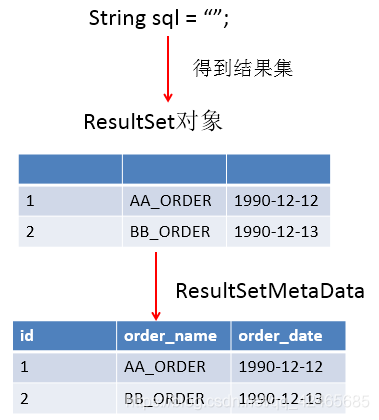
ResultSetMetaData
-
可用於獲取關於
ResultSet對象中列的類型和屬性資訊的對象 -
ResultSetMetaData metaData= resultSet.getMetaData();-
getColumnName(int column):獲取指定列的名稱。
-
getColumnLabel(int column):獲取指定列的別名。
-
getColumnCount():返回當前 ResultSet 對象中的列數。
-
getColumnTypeName(int column):檢索指定列的資料庫特定的類型名稱。
-
getColumnDisplaySize(int column):指示指定列的最大標準寬度,以字元為單位。
-
isNullable(int column):指示指定列中的值是否可以為 null。
-
isAutoIncrement(int column):指示是否自動為指定列進行編號,這樣這些列仍然是只讀的。
-
public class Order {
private Integer orderId;
private String orderName;
private Date orderDate;
}
/***** 主要起別名 *****/
String sql = "select order_id orderId,order_name orderName,order_date orderDate from `order` where order_id = ?";
//預編譯SQL
PreparedStatement statement = connection.prepareStatement(sql);
//填充佔位符
statement.setObject(1,1);
//執行
ResultSet resultSet = statement.executeQuery();
//獲取結果集的元數據
ResultSetMetaData metaData = resultSet.getMetaData();
if (resultSet.next()) {
Object orderId = metaData.getObject(1); //order_id
Object orderName = metaData.getObject(2); //order_name
Object orderDate = metaData.getObject(3); //order_date
Order order = new Order(orderId,orderName,orderDate);
System.out.println(order);
}
鏈接關閉釋放資源
- 釋放
ResultSet,Statement,Connection。 - 資料庫連接(
Connection)是非常稀有的資源,用完後必須馬上釋放,如果Connection不能及時正確的關閉將導致系統宕機。Connection的使用原則是盡量晚創建,盡量早的釋放。 - 可以在
finally中關閉,保證及時其他程式碼出現異常,資源也一定能被關閉。
完整程式碼
# jdbc.properties 配置文件
user=root
password=root
url=jdbc:mysql://localhost:3306/test?useUnicode=true&cahracterEncoding=utf8
driverClass=com.mysql.jdbc.Driver
/* JDBCUtils.java */
public class JDBCUtils {
/** 獲取資料庫鏈接@return */
public static Connection getConnection() {
Connection connection = null;
try {
//1.載入配置文件
InputStream resourceAsStream = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");
//2.讀取配置文件資訊
Properties properties = new Properties();
properties.load(resourceAsStream);
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String url = properties.getProperty("url");
String driverClass = properties.getProperty("driverClass");
//3.載入Driver
Class.forName(driverClass);
//4.獲取鏈接
connection = DriverManager.getConnection(url, user, password);
} catch (Exception e) {
e.printStackTrace();
}
return connection;
}
/** 關閉鏈接,釋放資源 */
public static void closeResource(Connection conn, Statement ps) {
try {
if (conn != null) conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if(ps != null) ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
public static void closeResource(Connection conn, Statement ps, ResultSet rs) {
try {
if (conn != null) conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if(ps != null) ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if (rs != null) rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
/* Custormer.java */
public class Custormer {
private Integer id;
private String name;
private String email;
private Date birth;
...
}
/* QueryForData.java */
public class QueryForData {
/* 查詢customers表中id為12的記錄(一條記錄) */
public void testGetInstanceList() {
String sql = "select id,name,email,birth from customers where id = ?";
List<Custormer> list = queryForList(Custormer.class, sql, 12);
list.forEach(System.out::println);
}
/* 查詢customers表中所有記錄(多條記錄) */
public void testGetInstanceList() {
String sql = "select id,name,email,birth from customers";
List<Custormer> list = queryForList(Custormer.class, sql);
list.forEach(System.out::println);
}
public <T> List<T> queryForList(Class<T> aClass, String sql, Object ...args ) {
Connection conn = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//1.獲取資料庫鏈接
conn = JDBCUtils.getConnection();
//2.預編譯SQL語句,返回PreparedStatement的實例
preparedStatement = conn.prepareStatement(sql);
//3.填充佔位符
for (int i = 0; i < args.length; i++) {
preparedStatement.setObject(i + 1,args[i]);
}
//4.執行SQL
resultSet = preparedStatement.executeQuery();
//5.獲取結果集的元數據
ResultSetMetaData metaData = resultSet.getMetaData();
//6.通過ResultSetMetaData獲取結果集中的列數
int columnCount = metaData.getColumnCount();
//7創建ArrayList<T>對象,儲存從資料庫里查詢的記錄
List<T> list = new ArrayList<T>();
//8.處理結果集:next():判斷結果集的下一條是否有數據,如果有返回true,指針下移,沒有則返回false,指針不會下移;不同於集合中的iterator中的next(),反之倒是hashNext()與next()的結合。
while (resultSet.next()) {
//9.得到aClass實例
T t = aClass.newInstance();
//10.循環遍歷每一個列
for (int i = 0; i < columnCount; i++) {
//10.1獲取欄位值value
Object value = resultSet.getObject(i + 1);
//10.2獲取當前欄位名
String columnLabel = metaData.getColumnLabel(i + 1);
//10.3使用反射,給對象的相應屬性賦值
Field field = aClass.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t,value);
}
list.add(t);
}
return list;
} catch (Exception e) {
e.printStackTrace();
} finally {
// 11.關閉資源
JDBCUtils.closeResource(conn,preparedStatement,resultSet);
}
return null;
}
}
/* UpForData.java */
public class UpForData {
//插入數據
public void addData() {
try {
String sql = "insert into customers(name,email,birth) values(?,?,?)";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
java.util.Date parseDate = simpleDateFormat.parse("2000-01-01");
int addInt = update(sql,"貝多芬","[email protected]",new Date(parseDate.getTime()));
if (addInt > 0) {
System.out.println("插入成功!");
} else {
System.out.println("插入失敗!");
}
} catch (ParseException e) {
e.printStackTrace();
}
}
//修改數據
public void amendData() {
try {
String sql = "update customers set name = ?, email= ?, birth = ? where id = ?";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
java.util.Date parseDate = simpleDateFormat.parse("2000-10-05");
int amendInt = update(sql,"托馬斯·克里斯特","[email protected]",new Date(parseDate.getTime()),21);
if (amendInt > 0) {
System.out.println("修改成功!");
} else {
System.out.println("修改失敗!");
}
} catch (ParseException e) {
e.printStackTrace();
}
}
//刪除數據
public void deleData() {
String sql = "delete from customers where id = ?";
int deleInt = update(sql,20);
if (deleInt > 0) {
System.out.println("刪除成功!");
} else {
System.out.println("刪除失敗!");
}
}
public int update(String sql,Object ... args){
Connection conn = null;
PreparedStatement preparedStatement = null;
try {
//1.獲取資料庫的連接
conn = JDBCUtils.getConnection();
//2.預編譯SQL語句,返回PreparedStatement的實例
preparedStatement = conn.prepareStatement(sql);
//3.填充佔位符
for(int i = 0;i < args.length;i++){
preparedStatement.setObject(i + 1, args[i]);
}
//4.執行sql語句
return preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
//5.關閉資源
JDBCUtils.closeResource(conn, preparedStatement);
}
return -1;
}
}
操作BLOB類型
MySQL BLOB類型
-
MySQL中,BLOB是一個二進位大型對象,是一個可以儲存大量數據的容器,它能容納不同大小的數據。 -
插入BLOB類型的數據必須使用
PreparedStatement,因為BLOB類型的數據無法使用字元串拼接寫的。 -
MySQL的四種BLOB類型(除了在存儲的最大資訊量上不同外,他們是等同的)類型 大小 TinyBlob 最大 255 Blod 最大 65K MediumBlob 最大 16M LongBlob 最大 4G -
實際使用中根據需要存入的數據大小定義不同的BLOB類型。
-
需要注意的是:如果存儲的文件過大,資料庫的性能會下降。
-
如果在指定了相關的Blob類型以後,還報錯:
xxx too large,那麼在mysql的安裝目錄下,找my.ini文件加上如下的配置參數:max_allowed_packet=16M。同時注意:修改了my.ini文件之後,需要重新啟動mysql服務。
向資料庫表中插入大數據類型
public void testInsert() {
String sql = "insert into customers(name,email,birth,photo) values(?,?,?,?)";
Connection connection = null;
PreparedStatement preparedStatement = null;
FileInputStream fileInputStream = null;
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, "托馬斯·克里斯特");
preparedStatement.setObject(2, "[email protected]");
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyy-MM-dd");
Date date = simpleDateFormat.parse("2020-10-10");
preparedStatement.setObject(3, new Date(date.getTime()));
//操類型的變數
fileInputStream = new FileInputStream(new File("wallhaven-y877ok.png"));
preparedStatement.setBlob(4,fileInputStream);
//執行
preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(connection,preparedStatement);
try {
if (fileInputStream != null) fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
修改數據表中的Blob類型欄位
public void testUpdate() {
String sql = "update customers set photo = ? where id = ?";
Connection connection = null;
PreparedStatement preparedStatement = null;
FileInputStream fileInputStream = null;
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
//操類型的變數
fileInputStream = new FileInputStream(new File("wallhaven-y877ok.png"));
preparedStatement.setBlob(4,fileInputStream);
preparedStatement.setInt(2,1);
//執行
preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(connection,preparedStatement);
try {
if (fileInputStream != null) fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
從數據表中讀取大數據類型
public void testQueryBlob() {
InputStream binaryStream = null;
FileOutputStream fileOutputStream = null;
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBCUtils.getConnection();
String sql = "select id,name,email,birth,photo from customers where id = ?";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1,22);
resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
int id = (int) resultSet.getObject("id");
String name = (String) resultSet.getObject("name");
String email = (String) resultSet.getObject("email");
java.sql.Date birth = resultSet.getDate("birth");
Custormer custormer = new Custormer(id, name, email, birth);
//將Bolb類型的欄位下載下來
Blob photo = resultSet.getBlob("photo");
binaryStream = photo.getBinaryStream();
fileOutputStream = new FileOutputStream(new File("test.jpg"));
byte[] bytes = new byte[1024];
int len;
while ((len = binaryStream.read(bytes)) != -1) {
fileOutputStream.write(bytes,0,len);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(connection,preparedStatement,resultSet);
try {
if (binaryStream != null) binaryStream.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fileOutputStream != null) fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
批量插入
批量執行SQL語句
當需要成批插入或者更新記錄時,可以採用Java的批量更新機制,這一機制允許多條語句一次性提交給資料庫批量處理。通常情況下比單獨提交處理更有效率
JDBC的批量處理語句包括下面三個方法:
- addBatch(String):添加需要批量處理的SQL語句或是參數;
- executeBatch():執行批量處理語句;
- clearBatch():清空快取的數據
舉例
-
mysql伺服器默認是關閉批處理的,我們需要通過一個參數,讓mysql開啟批處理的支援。?rewriteBatchedStatements=true寫在配置文件的url後面。jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true
-
設置不允許自動提交數據
setAutoCommit(false),資料庫默認為true(要在獲取資料庫鏈接後調用)。- addBatch():累計多條
SQL語句。 - connection.commit():立即提交數據。
public void testInsert () { Connection connection = null; PreparedStatement preparedStatement = null; try { long start = System.currentTimeMillis(); connection = JDBCUtils.getConnection(); //設置不允許自動提交數據 connection.setAutoCommit(false); String sql = "insert into goods(name) values(?)"; preparedStatement = connection.prepareStatement(sql); for (int i = 1; i <= 24986598; i++) { preparedStatement.setObject(1,"name_" + i); //1.積 sql preparedStatement.addBatch(); if (i % 1000 == 0) { //2.執行Batch preparedStatement.executeBatch(); //3.清空Batch preparedStatement.clearBatch(); } } //提交數據 connection.commit(); long end = System.currentTimeMillis(); System.out.println("花費時間為:" + (end - start)); // 226877 -> 118675 } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(connection,preparedStatement); } } - addBatch():累計多條
資料庫事務
資料庫事務介紹
- 事務:一組邏輯操作單元,使數據從一種狀態變換到另一種狀態。
- 事務處理:保證所有事務都作為一個工作單元來執行。即使出現故障,都不能改變這種執行方式。當在一個事務中執行多個操作時,要麼所有的事務都被提交(commit),數據被永久的保存;要麼資料庫管理系統將放棄所有的修改,整個事務回滾(rollback)到最初狀態。
- 為保證資料庫中數據的一致性,數據的操作應當是離散的、成組的邏輯單元;當它全部完成時,數據的一致性可以保持,而當這個單元中的一部分操作失敗,整個事務應全部視為錯誤,所有從起點以後的操作應全部回退到開始狀態。
JDBC事務處理
-
數據一旦提交,就不能回滾。
-
數據在什麼時候意味著提交?
- 當一個連接對象被創建時,該連接默認為自動提交事務:每次執行一條SQL語句,如果執行成功,則會向資料庫自動提交,不能回滾。
- 關閉資料庫連接,數據就會自動提交。如果多個操作,每個操作使用的是自己單獨的連接,則無法保證事務。即同一個事務的多個操作必須在同一連接下。
-
JDBC程式中如何讓多個 SQL 語句作為一個事務執行:
-
調用 Connection 對象的
setAutoCommit(false);以取消自動提交事務。 -
在所有的 SQL 語句都成功執行後,調用
commit();方法提交事務。 -
在出現異常時,調用
rollback();方法回滾事務。若此時 Connection 沒有被關閉,還可能被重複使用,則需要恢復其自動提交狀態
setAutoCommit(true)。尤其是在使用資料庫連接池技術時,執行close()方法前,建議恢復自動提交狀態。
-
案例【AA向BB轉賬一百】
@Test
public void testUpdate() {
Connection connection = null;
try {
connection = JDBCUtils.getConnection();
//1.取消數據的自動提交
connection.setAutoCommit(false);
String sql = "update user_table set balance = balance - 100 where user = ?";
update(connection,sql, "AA");
//1.2模擬網路異常
System.out.println(10 / 0);
String sql2 = "update user_table set balance = balance + 100 where user = ?";
update(connection,sql2,"BB");
System.out.println("轉賬成功!");
//2.正常執行提交數據
connection.commit();
} catch (Exception e) {
e.printStackTrace();
try {
//3.若有異常,則回滾操作
connection.rollback();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
} finally {
try {
//4.回復每次DML操作的自動提交功能
connection.setAutoCommit(true);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
JDBCUtils.closeResource(connection,null);
}
}
對資料庫增刪改操作的方法:
public int update(Connection conn, String sql,Object ... args) {
PreparedStatement preparedStatement = null;
try {
preparedStatement = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
preparedStatement.setObject(i + 1, args[i]);
}
return preparedStatement.executeUpdate();
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
JDBCUtils.closeResource(null,preparedStatement);
}
return -1;
}
事務的ACID屬性
- 原子性(Atomicity)
原子性是指事務是一個不可分割的工作單位,事務中的操作要麼都發生,要麼都不發生。 - 一致性(Consistency)
事務必須使資料庫從一個一致性狀態變換到另外一個一致性狀態。 - 隔離性(Isolation)
事務的隔離性是指一個事務的執行不能被其他事務干擾,即一個事務內部的操作及使用的數據對並發的其他事務是隔離的,並發執行的各個事務之間不能互相干擾。 - 持久性(Durability)
持久性是指一個事務一旦被提交,它對資料庫中數據的改變就是永久性的,接下來的其他操作和資料庫故障不應該對其有任何影響。
資料庫的並發為問題
- 對於同時運行的多個事務, 當這些事務訪問資料庫中相同的數據時, 如果沒有採取必要的隔離機制, 就會導致各種並發問題:
- 臟讀: 對於兩個事務 T1, T2。 T1 讀取了已經被 T2 更新但還沒有被提交的欄位。之後, 若 T2 回滾, T1讀取的內容就是臨時且無效的。
- 不可重複讀: 對於兩個事務T1, T2。 T1 讀取了一個欄位, 然後 T2 更新了該欄位。之後, T1再次讀取同一個欄位時, 值就不同了。
- 幻讀: 對於兩個事務T1, T2,。T1 從一個表中讀取了一個欄位, 然後 T2 在該表中插入了一些新的行。之後, 如果 T1 再次讀取同一個表, 就會多出幾行。
- 資料庫事務的隔離性: 資料庫系統必須具有隔離並發運行各個事務的能力, 使它們不會相互影響, 避免各種並發問題。
- 一個事務與其他事務隔離的程度稱為隔離級別。資料庫規定了多種事務隔離級別, 不同隔離級別對應不同的干擾程度, 隔離級別越高, 數據一致性就越好, 但並發性越弱。
四種隔離級別
-
資料庫提供的四種事務隔離級別:
隔離級別 描述 READ UNCOMMITTED
(讀未提交數據)允許事務讀取未被其它事務提交更改。臟讀、不可重複讀以及幻讀的問題都會出現。 READ COMMITED
(讀已提交數據)只允許事務讀取已經被其它事務提交的變更,可以避免臟讀。但不可重複讀和幻讀問題仍然可能出現。 REPEATABLE READ
(可重複讀)確保事務可以多次從一個欄位中讀取相同的值。在這個事務持續期間,禁止其他事務對這個欄位進行更新,可以避免臟讀和不可重複讀。但幻讀的問題仍然存在。 SERIALIZABLE
(串列化)確保事務可以從一個表中讀取相同的行。在這個事務持續期間。禁止其他事務對該表執行插入、更新、刪除操作,所有並發問題都可以避免,但性能十分低下。 -
Oracle 支援的 2 種事務隔離級別:READ COMMITED、SERIALIZABLE。Oracle 默認的事務隔離級別為: READ COMMITED 。
-
Mysql 支援 4 種事務隔離級別。Mysql 默認的事務隔離級別為: REPEATABLE READ。
在MySQL中設置隔離級別
-
每啟動一個 mysql 程式, 就會獲得一個單獨的資料庫連接. 每個資料庫連接都有一個全局變數 @@tx_isolation, 表示當前的事務隔離級別。
-
查看當前的隔離級別:
SELECT @@tx_isolation; -
設置當前 mySQL 連接的隔離級別:
set transaction isolation level read committed; -
設置資料庫系統的全局的隔離級別:
set global transaction isolation level read committed; -
補充操作:
-
創建mysql資料庫用戶:
create user tom identified by 'abc123'; -
授予許可權
#授予通過網路方式登錄的tom用戶,對所有庫所有表的全部許可權,密碼設為abc123. grant all privileges on *.* to tom@'%' identified by 'abc123'; #給tom用戶使用本地命令行方式,授予atguigudb這個庫下的所有表的插刪改查的許可權。 grant select,insert,delete,update on atguigudb.* to tom@localhost identified by 'abc123';
-
在Java中設置隔離級別
通過Connection中的void setTransactionIsolation(int level)、int getTransactionIsolation()分別設置和讀取事務隔離級別。
public void testTransactionSelect() throws Exception {
Connection connection = JDBCUtils.getConnection();
//設置事務隔離級別:避免臟讀
connection.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
//查看事務隔離級別
System.out.println(connection.getTransactionIsolation());
//關閉自動提交數據
connection.setAutoCommit(false);
String sql = "select user,password,balance from user_table where user = ?";
User user = getInstance(User.class, connection, sql, "cc");
System.out.println(user);
}
DAO及相關實現類
- DAO:Data Access Object訪問數據資訊的類和介面,包括了對數據的CRUD(Create、Retrival、Update、Delete),而不包含任何業務相關的資訊。也稱作:BaseDAO
- 作用:為了實現功能的模組化,更有利於程式碼的維護和升級。
目錄結構:

資料庫連接池
JDBC資料庫連接池的必要性
-
在使用開發基於資料庫的web程式時,傳統的模式基本是按以下步驟:
- 在主程式(如servlet、beans)中建立資料庫連接
- 進行sql操作
- 斷開資料庫連接
-
這種模式開發,存在的問題:
- 普通的JDBC資料庫連接使用 DriverManager 來獲取,每次向資料庫建立連接的時候都要將 Connection 載入到記憶體中,再驗證用戶名和密碼(得花費0.05s~1s的時間)。需要資料庫連接的時候,就向資料庫要求一個,執行完成後再斷開連接。這樣的方式將會消耗大量的資源和時間。資料庫的連接資源並沒有得到很好的重複利用。若同時有幾百人甚至幾千人在線,頻繁的進行資料庫連接操作將佔用很多的系統資源,嚴重的甚至會造成伺服器的崩潰。
- 對於每一次資料庫連接,使用完後都得斷開。否則,如果程式出現異常而未能關閉,將會導致資料庫系統中的記憶體泄漏,最終將導致重啟資料庫。(回憶:何為Java的記憶體泄漏?)
- 這種開發不能控制被創建的連接對象數,系統資源會被毫無顧及的分配出去,如連接過多,也可能導致記憶體泄漏,伺服器崩潰。
資料庫連接池技術
-
為解決傳統開發中的資料庫連接問題,可以採用資料庫連接池技術。
-
資料庫連接池的基本思想:就是為資料庫連接建立一個「緩衝池」。預先在緩衝池中放入一定數量的連接,當需要建立資料庫連接時,只需從「緩衝池」中取出一個,使用完畢之後再放回去。
-
資料庫連接池負責分配、管理和釋放資料庫連接,它允許應用程式重複使用一個現有的資料庫連接,而不是重新建立一個。
-
資料庫連接池在初始化時將創建一定數量的資料庫連接放到連接池中,這些資料庫連接的數量是由最小資料庫連接數來設定的。無論這些資料庫連接是否被使用,連接池都將一直保證至少擁有這麼多的連接數量。連接池的最大資料庫連接數量限定了這個連接池能佔有的最大連接數,當應用程式向連接池請求的連接數超過最大連接數量時,這些請求將被加入到等待隊列中。
-
資料庫連接池技術的優點
1. 資源重用
由於資料庫連接得以重用,避免了頻繁創建,釋放連接引起的大量性能開銷。在減少系統消耗的基礎上,另一方面也增加了系統運行環境的平穩性。
2. 更快的系統反應速度
資料庫連接池在初始化過程中,往往已經創建了若干資料庫連接置於連接池中備用。此時連接的初始化工作均已完成。對於業務請求處理而言,直接利用現有可用連接,避免了資料庫連接初始化和釋放過程的時間開銷,從而減少了系統的響應時間
3. 新的資源分配手段
對於多應用共享同一資料庫的系統而言,可在應用層通過資料庫連接池的配置,實現某一應用最大可用資料庫連接數的限制,避免某一應用獨佔所有的資料庫資源
4. 統一的連接管理,避免資料庫連接泄漏
在較為完善的資料庫連接池實現中,可根據預先的佔用超時設定,強制回收被佔用連接,從而避免了常規資料庫連接操作中可能出現的資源泄露
多種開源的資料庫連接池
- JDBC 的資料庫連接池使用 javax.sql.DataSource 來表示,DataSource 只是一個介面,該介面通常由伺服器(Weblogic, WebSphere, Tomcat)提供實現,也有一些開源組織提供實現:
- DBCP 是Apache提供的資料庫連接池。tomcat 伺服器自帶dbcp資料庫連接池。速度相對c3p0較快,但因自身存在BUG,Hibernate3已不再提供支援。
- C3P0 是一個開源組織提供的一個資料庫連接池,速度相對較慢,穩定性還可以。hibernate官方推薦使用
- Proxool 是sourceforge下的一個開源項目資料庫連接池,有監控連接池狀態的功能,穩定性較c3p0差一點
- BoneCP 是一個開源組織提供的資料庫連接池,速度快
- Druid 是阿里提供的資料庫連接池,據說是集DBCP 、C3P0 、Proxool 優點於一身的資料庫連接池,但是速度不確定是否有BoneCP快
- DataSource 通常被稱為數據源,它包含連接池和連接池管理兩個部分,習慣上也經常把 DataSource 稱為連接池
- DataSource用來取代DriverManager來獲取Connection,獲取速度快,同時可以大幅度提高資料庫訪問速度。
- 特別注意:
- 數據源和資料庫連接不同,數據源無需創建多個,它是產生資料庫連接的工廠,因此整個應用只需要一個數據源即可。
- 當資料庫訪問結束後,程式還是像以前一樣關閉資料庫連接:conn.close(); 但conn.close()並沒有關閉資料庫的物理連接,它僅僅把資料庫連接釋放,歸還給了資料庫連接池。
C3P0資料庫連接池
//使用C3P0資料庫連接池的配置文件方式,獲取資料庫的連接:推薦
private static DataSource cpds = new ComboPooledDataSource("helloc3p0");
public static Connection getConnection() throws SQLException{
Connection conn = cpds.getConnection();
return conn;
}
其中,src下的配置文件為:【c3p0-config.xml】
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<named-config name="helloc3p0">
<!-- 獲取連接的4個基本資訊 -->
<property name="user">root</property>
<property name="password">root</property>
<property name="jdbcUrl">jdbc:mysql://localhost/test</property>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<!-- 涉及到資料庫連接池的管理的相關屬性的設置 -->
<!-- 若資料庫中連接數不足時, 一次向資料庫伺服器申請多少個連接 -->
<property name="acquireIncrement">5</property>
<!-- 初始化資料庫連接池時連接的數量 -->
<property name="initialPoolSize">5</property>
<!-- 資料庫連接池中的最小的資料庫連接數 -->
<property name="minPoolSize">5</property>
<!-- 資料庫連接池中的最大的資料庫連接數 -->
<property name="maxPoolSize">10</property>
<!-- C3P0 資料庫連接池可以維護的 Statement 的個數 -->
<property name="maxStatements">20</property>
<!-- 每個連接同時可以使用的 Statement 對象的個數 -->
<property name="maxStatementsPerConnection">5</property>
</named-config>
</c3p0-config>
DBCP資料庫連接池
- DBCP 是 Apache 軟體基金組織下的開源連接池實現,該連接池依賴該組織下的另一個開源系統:Common-pool。如需使用該連接池實現,應在系統中增加如下兩個 jar 文件:
- Commons-dbcp.jar:連接池的實現
- Commons-pool.jar:連接池實現的依賴庫
- Tomcat 的連接池正是採用該連接池來實現的。該資料庫連接池既可以與應用伺服器整合使用,也可由應用程式獨立使用。
- 數據源和資料庫連接不同,數據源無需創建多個,它是產生資料庫連接的工廠,因此整個應用只需要一個數據源即可。
- 當資料庫訪問結束後,程式還是像以前一樣關閉資料庫連接:conn.close(); 但上面的程式碼並沒有關閉資料庫的物理連接,它僅僅把資料庫連接釋放,歸還給了資料庫連接池。
- 配置屬性說明
| 屬性 | 默認值 | 說明 |
|---|---|---|
| initialSize | 0 | 連接池啟動時創建的初始化連接數量 |
| maxActive | 8 | 連接池中可同時連接的最大的連接數 |
| maxIdle | 8 | 連接池中最大的空閑的連接數,超過的空閑連接將被釋放,如果設置為負數表示不限制 |
| minIdle | 0 | 連接池中最小的空閑的連接數,低於這個數量會被創建新的連接。該參數越接近maxIdle,性能越好,因為連接的創建和銷毀,都是需要消耗資源的;但是不能太大。 |
| maxWait | 無限制 | 最大等待時間,當沒有可用連接時,連接池等待連接釋放的最大時間,超過該時間限制會拋出異常,如果設置-1表示無限等待 |
| poolPreparedStatements | false | 開啟池的Statement是否prepared |
| maxOpenPreparedStatements | 無限制 | 開啟池的prepared 後的同時最大連接數 |
| minEvictableIdleTimeMillis | 連接池中連接,在時間段內一直空閑, 被逐出連接池的時間 | |
| removeAbandonedTimeout | 300 | 超過時間限制,回收沒有用(廢棄)的連接 |
| removeAbandoned | false | 超過removeAbandonedTimeout時間後,是否進 行沒用連接(廢棄)的回收 |
private static DataSource source;
static {
try {
Properties pros = new Properties();
InputStream inputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("dbcp.properties");
pros.load(inputStream);
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection1() throws SQLException {
Connection conn = source.getConnection();
return conn;
}
其中,src下的配置文件為:【dbcp.properties】
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test
username=root
password=root
initialSize=10
maxActive=10
#...
Druid(德魯伊)資料庫連接池
Druid是阿里巴巴開源平台上一個資料庫連接池實現,它結合了C3P0、DBCP、Proxool等DB池的優點,同時加入了日誌監控,可以很好的監控DB池連接和SQL的執行情況,可以說是針對監控而生的DB連接池,可以說是目前最好的連接池之一。
- 詳細配置參數:
| 配置 | 預設 | 說明 |
|---|---|---|
| name | 配置這個屬性的意義在於,如果存在多個數據源,監控的時候可以通過名字來區分開來。 如果沒有配置,將會生成一個名字,格式是:」DataSource-」 + System.identityHashCode(this) | |
| url | 連接資料庫的url,不同資料庫不一樣。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 連接資料庫的用戶名 | |
| password | 連接資料庫的密碼。如果你不希望密碼直接寫在配置文件中,可以使用ConfigFilter。詳細看這裡://github.com/alibaba/druid/wiki/使用ConfigFilter | |
| driverClassName | 根據url自動識別 這一項可配可不配,如果不配置druid會根據url自動識別dbType,然後選擇相應的driverClassName(建議配置下) | |
| initialSize | 0 | 初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時 |
| maxActive | 8 | 最大連接池數量 |
| maxIdle | 8 | 已經不再使用,配置了也沒效果 |
| minIdle | 最小連接池數量 | |
| maxWait | 獲取連接時最大等待時間,單位毫秒。配置了maxWait之後,預設啟用公平鎖,並發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖。 | |
| poolPreparedStatements | false | 是否快取preparedStatement,也就是PSCache。PSCache對支援游標的資料庫性能提升巨大,比如說oracle。在mysql下建議關閉。 |
| maxOpenPreparedStatements | -1 | 要啟用PSCache,必須配置大於0,當大於0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache佔用記憶體過多的問題,可以把這個數值配置大一些,比如說100 |
| validationQuery | 用來檢測連接是否有效的sql,要求是一個查詢語句。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會其作用。 | |
| testOnBorrow | true | 申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。 |
| testOnReturn | false | 歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能 |
| testWhileIdle | false | 建議配置為true,不影響性能,並且保證安全性。申請連接的時候檢測,如果空閑時間大於timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。 |
| timeBetweenEvictionRunsMillis | 有兩個含義: 1)Destroy執行緒會檢測連接的間隔時間2)testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明 | |
| numTestsPerEvictionRun | 不再使用,一個DruidDataSource只支援一個EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理連接初始化的時候執行的sql | |
| exceptionSorter | 根據dbType自動識別 當資料庫拋出一些不可恢復的異常時,拋棄連接 | |
| filters | 屬性類型是字元串,通過別名的方式配置擴展插件,常用的插件有: 監控統計用的filter:stat日誌用的filter:log4j防禦sql注入的filter:wall | |
| proxyFilters | 類型是List,如果同時配置了filters和proxyFilters,是組合關係,並非替換關係 |
private static DataSource source;
static {
try {
Properties pros = new Properties();
InputStream inputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
pros.load(inputStream);
source = DruidDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
Connection conn = source.getConnection();
return conn;
}
其中,src下的配置文件為:【druid.properties】
url=jdbc:mysql://localhost:3306/test
username=root
password=root
driverClassName=com.mysql.jdbc.Driver
initialSize=10
maxActive=20
maxWait=1000
filters=wall
Apache-DBUtils實現CRUD操作
Apache-DBUtils簡介
- commons-dbutils 是 Apache 組織提供的一個開源 JDBC工具類庫,它是對JDBC的簡單封裝,學習成本極低,並且使用dbutils能極大簡化jdbc編碼的工作量,同時也不會影響程式的性能。
- API介紹:
- org.apache.commons.dbutils.QueryRunner
- org.apache.commons.dbutils.ResultSetHandler
- 工具類:org.apache.commons.dbutils.DbUtils
- API包說明:

主要API的使用
DbUtils
DbUtils :提供如關閉連接、裝載JDBC驅動程式等常規工作的工具類,裡面的所有方法都是靜態的。主要方法如下:
public static void close(…) throws java.sql.SQLException: DbUtils類提供了三個重載的關閉方法。這些方法檢查所提供的參數是不是NULL,如果不是的話,它們就關閉Connection、Statement和ResultSet。public static void closeQuietly(…): 這一類方法不僅能在Connection、Statement和ResultSet為NULL情況下避免關閉,還能隱藏一些在程式中拋出的SQLEeception。public static void commitAndClose(Connection conn)throws SQLException: 用來提交連接的事務,然後關閉連接public static void commitAndCloseQuietly(Connection conn): 用來提交連接,然後關閉連接,並且在關閉連接時不拋出SQL異常。public static void rollback(Connection conn)throws SQLException:允許conn為null,因為方法內部做了判斷public static void rollbackAndClose(Connection conn)throws SQLExceptionrollbackAndCloseQuietly(Connection)public static boolean loadDriver(java.lang.String driverClassName):這一方裝載並註冊JDBC驅動程式,如果成功就返回true。使用該方法,你不需要捕捉這個異常ClassNotFoundException。
QueryRunner類
-
該類簡單化了SQL查詢,它與ResultSetHandler組合在一起使用可以完成大部分的資料庫操作,能夠大大減少編碼量。
-
QueryRunner類提供了兩個構造器:
- 默認的構造器
- 需要一個 javax.sql.DataSource 來作參數的構造器
-
QueryRunner類的主要方法:
- 更新
public int update(Connection conn, String sql, Object... params) throws SQLException:用來執行一個更新(插入、更新或刪除)操作。- ……
- 插入
public <T> T insert(Connection conn,String sql,ResultSetHandler<T> rsh, Object... params) throws SQLException:只支援INSERT語句,其中 rsh – The handler used to create the result object from the ResultSet of auto-generated keys. 返回值: An object generated by the handler.即自動生成的鍵值- ….
- 批處理
public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE語句public <T> T insertBatch(Connection conn,String sql,ResultSetHandler<T> rsh,Object[][] params)throws SQLException:只支援INSERT語句- …..
- 查詢
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException:執行一個查詢操作,在這個查詢中,對象數組中的每個元素值被用來作為查詢語句的置換參數。該方法會自行處理 PreparedStatement 和 ResultSet 的創建和關閉。- ……
- 更新
-
案例
@Test public void testInsert() throws Exception { QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection(); String sql = "insert into customers(name,email,birth)values(?,?,?)"; int count = runner.update(conn, sql, "托馬斯", "[email protected]", "1992-09-08"); System.out.println("添加了" + count + "條記錄"); JDBCUtils.closeResource(conn, null); }@Test public void testDelete() throws Exception { QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = "delete from customers where id < ?"; int count = runner.update(conn, sql,3); System.out.println("刪除了" + count + "條記錄"); JDBCUtils.closeResource(conn, null); }
ResultSetHandler介面及實現類
-
該介面用於處理 java.sql.ResultSet,將數據按要求轉換為另一種形式。
-
ResultSetHandler 介面提供了一個單獨的方法:Object handle (java.sql.ResultSet .rs)。
-
介面的主要實現類:
- ArrayHandler:把結果集中的第一行數據轉成對象數組。
- ArrayListHandler:把結果集中的每一行數據都轉成一個數組,再存放到List中。
- BeanHandler:將結果集中的第一行數據封裝到一個對應的JavaBean實例中。
- BeanListHandler:將結果集中的每一行數據都封裝到一個對應的JavaBean實例中,存放到List里。
- ColumnListHandler:將結果集中某一列的數據存放到List中。
- KeyedHandler(name):將結果集中的每一行數據都封裝到一個Map里,再把這些map再存到一個map里,其key為指定的key。
- MapHandler:將結果集中的第一行數據封裝到一個Map里,key是列名,value就是對應的值。
- MapListHandler:將結果集中的每一行數據都封裝到一個Map里,然後再存放到List
- ScalarHandler:查詢單個值對象
-
測試
/** 測試查詢一條記錄 * BeanHandler<T> 是 ResultSetHandler<T>的實現類 */ @Test public void testQuery1() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select id,name,email,birth from customers where id = ?"; BeanHandler<Custormer> beanHandler = new BeanHandler<Custormer>(Custormer.class); Custormer query = queryRunner.query(conn, sql, beanHandler, 25); System.out.println(query); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }/** 測試查詢多條記錄 * BeanListHandler<T> 是 ResultSetHandler<T>的實現類 */ @Test public void testQuery2() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select id,name,email,birth from customers where id < ?"; BeanListHandler<Custormer> beanHandler = new BeanListHandler<Custormer>(Custormer.class); List<Custormer> query = queryRunner.query(conn, sql, beanHandler, 23); query.forEach(System.out::println); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }/** 查詢一條記錄 * MapHandler 是 ResultSetHandler<T>的實現類 * 將查詢出來的記錄 欄位名 與 值 作為 map 中的key 和 value */ @Test public void testQuery3() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select id,name,email,birth from customers where id = ?"; MapHandler mapHandler = new MapHandler(); Map<String, Object> query = queryRunner.query(conn, sql, mapHandler, 23); for (Map.Entry<String,Object> entry : query.entrySet()) { System.out.println(entry.getKey() + "=" + entry.getValue()); } } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }/** 查詢多條記錄 * MapListHandler 是 ResultSetHandler<T>的實現類 * 將查詢出來的記錄 欄位名 與 值 作為 map 中的key 和 value,並保存到 List 中 */ @Test public void testQuery4() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select id,name,email,birth from customers where id < ?"; MapListHandler mapHandler = new MapListHandler(); List<Map<String, Object>> query = queryRunner.query(conn, sql, mapHandler, 23); Iterator<Map<String, Object>> iterator = query.iterator(); while (iterator.hasNext()) { for (Map.Entry<String,Object> entry : iterator.next().entrySet()) { System.out.print(entry.getKey() + "=" + entry.getValue() + ", "); } System.out.println(); } } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }/** 用於查詢特殊條件記錄 * ScalarHandler 是 ResultSetHandler<T>的實現類 */ @Test public void testQuery5() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select count(*) from customers"; ScalarHandler scalarHandler = new ScalarHandler(); Long count = (Long) queryRunner.query(conn, sql, scalarHandler); System.out.println("總共有" + count + "條記錄"); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }/** 自定義ResultSetHandler實現類 */ @Test public void testQuery7() { Connection conn = null; try { QueryRunner queryRunner = new QueryRunner(); conn = JDBCUtils.getConnection(); String sql = "select id,name,email,birth from customers where id = ?"; ResultSetHandler<Custormer> handler = new ResultSetHandler<Custormer>() { @Override public Custormer handle(ResultSet rs) throws SQLException { if (rs.next()) { int id = rs.getInt("id"); String name = rs.getString("name"); String email = rs.getString("email"); Date birth = rs.getDate("birth"); Custormer custormer = new Custormer(id, name, email, birth); return custormer; } return null; } }; Custormer query = queryRunner.query(conn, sql, handler, 24); System.out.println(query); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.closeResource(conn,null); } }


