百億級圖數據在快手安全情報的應用與挑戰
本文首發於 Nebula Graph 公眾號 NebulaGraphCommunity,Follow 看大廠圖資料庫技術實踐。
【作者介紹】
- 戚名鈺:快手安全-移動安全組,主要負責快手安全情報平台的建設
- 倪雯:快手數據平台-分散式存儲組,主要負責快手圖資料庫的建設
- 姚靖怡:快手數據平台-分散式存儲組,主要負責快手圖資料庫的建設
【公司簡介】
快手是一家全球領先的內容社區和社交平台,旨在通過短影片的方式幫助人們發現所需、發揮所長,持續提升每個人獨特的幸福感。
一. 為什麼需要圖資料庫
傳統的關係型資料庫,在處理複雜數據關係運算上表現很差,隨著數據量和深度的增加,關係型資料庫無法在有效的時間內計算出結果。
所以,為了更好的體現數據間的連接,企業需要一種將關係資訊存儲為實體、靈活拓展數據模型的資料庫技術,這項技術就是圖資料庫(Graph Database)。
相比於傳統關係型資料庫,圖資料庫具有以下兩個優點:
第一點,圖資料庫能很好地體現數據之間的關聯關係
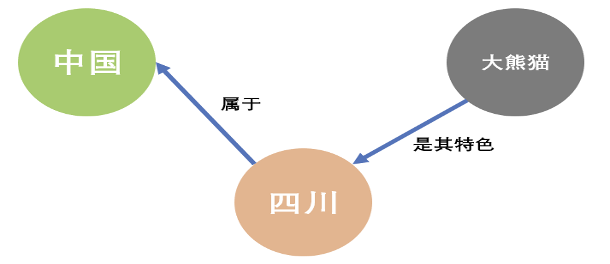
從上面的圖模型可以看出,圖資料庫的目標就是基於圖模型以一種直觀的方式來展示這些關係,其基於事物關係的模型表達,使圖資料庫天然具有可解釋性。
第二點,圖資料庫能很好地處理數據之間的關聯關係:
- 高性能:傳統關係型資料庫在處理關聯關係數據時主要靠 JOIN 操作,而隨著數據量的增多和關聯深度的增加,受制於多表連接與外鍵約束,傳統關係型資料庫會導致較大的額外開銷,產生嚴重的性能問題。而圖資料庫從底層適配了圖模型的數據結構,使得它的數據查詢與分析速度更快。
- 靈活:圖資料庫有非常靈活的數據模型,使用者可以根據業務變化隨時調整圖數據結構模型,可以任意添加或刪除頂點、邊,擴充或者縮小圖模型等,這種頻繁的數據schema更改在圖資料庫上能到很好的支援。
- 敏捷:圖資料庫的圖模型非常直觀,支援測試驅動開發模式,每次構建時可進行功能測試和性能測試,符合當今最流行的敏捷開發需求,對於提高生產和交付效率也有一定幫助。
基於以上兩個優點,圖資料庫在金融反欺詐、公安刑偵、社交網路、知識圖譜、數據血緣、IT 資產及運維、威脅情報等領域有巨大需求。
而快手安全情報則是通過整合移動端、PC Web 端、雲端、聯盟及小程式等全鏈條的安全數據,最終形成統一的基礎安全能力賦能公司業務。
由於安全情報本身具有數據實體多樣性、關聯關係複雜性、數據標籤豐富性等特點,因此採用圖資料庫來做是最為合適的。
二. 為什麼選擇 Nebula Graph
通過收集需求及前期調研,快手安全情報在圖資料庫上最終選擇了Nebula Graph作為生產環境的圖資料庫。
2.1 需求收集
對於圖資料庫的選型來說,其主要需求是在數據寫入與數據查詢兩個方面:
- 數據寫入方式:離線 + 在線
- 需要支援天級的離線數據批量導入,每天新增寫入數據量在百億級別,要求當天產生的關聯關係數據,小時級能寫完
- 需要支援數據的實時寫入,Flink 從 Kafka 中消費數據,並在做完邏輯處理之後,直接對接圖資料庫,進行數據的實時寫入,需要支援的 QPS 在 10W 量級
- 數據查詢方式:毫秒級的在線實時查詢,需要支援的 QPS 在 5W 量級
- 點及邊的屬性過濾及查詢
- 多度關聯關係的查詢
- 部分基本圖數據分析能力
- 圖最短路徑演算法等
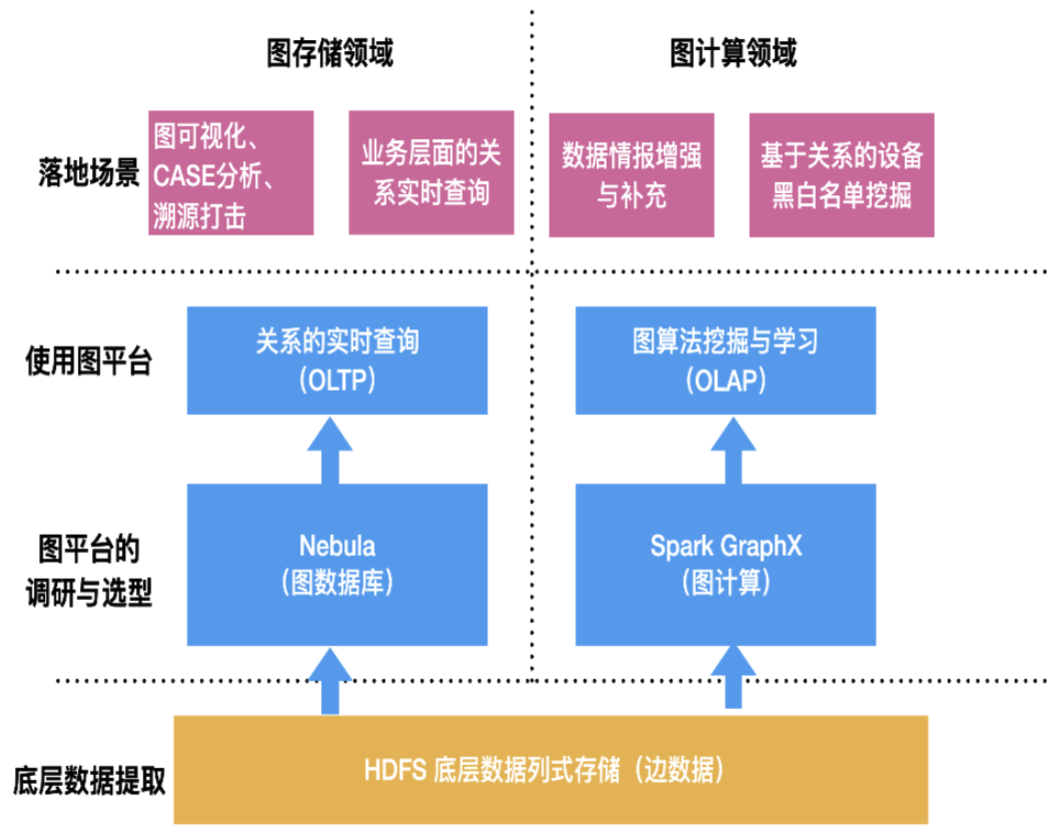
綜上所述,此次選型的適用於大數據架構的圖資料庫主要需要提供 3 種基本能力:實時和離線數據寫入、在線圖數據基本查詢、基於圖資料庫的簡單 OLAP 分析,其對應定位是:在線、高並發、低時延 OLTP 類圖查詢服務及簡單 OLAP 類圖查詢能力。
2.2 選型
基於以上的確定性需求,在進行圖資料庫的選型上,我們主要考慮了以下幾點:
- 圖資料庫所能支援的數據量必須要足夠大,因為企業級的圖數據經常會達到百億甚至千億級別
- 集群可線性拓展,因為需要能夠在生產環境不停服的情況下在線擴展機器
- 查詢性能要達到毫秒級,因為需要滿足在線服務的性能要求,且隨著圖數據量的增多,查詢性能不受影響
- 能夠較方便的與 HDFS、Spark 等大數據平台打通,後期能夠在此基礎上搭建圖計算平台
2.3 Nebula Graph的特點
- 高性能:提供毫秒級讀寫
- 可擴展:可水平擴容,支援超大規模圖存儲
- 引擎架構:存儲與計算分離
- 圖數據模型:點(vertex)、邊(edge),並且支援點或邊的屬性(properties)建模
- 查詢語言:nGQL,類 SQL 的查詢語言,易學易用,滿足複雜業務需求
- 提供了較為豐富和完善的數據導入導出工具
- Nebula Graph 作為開源圖資料庫產品,在開源社區具有良好的活躍度
- 相較於 JanusGraph 和 HugeGraph,Nebula Graph查詢性能有極大的提升
正是基於Nebula Graph的以上特點以及對我們使用場景和需求的恰好滿足,因此最終選擇Nebula Graph作為我們生產環境的圖資料庫來使用。
三. 安全情報的圖數據建模
如下圖所示,從情報的角度來看,安全的分層對抗與防守,從下到上,其對抗難度是逐漸增加的:
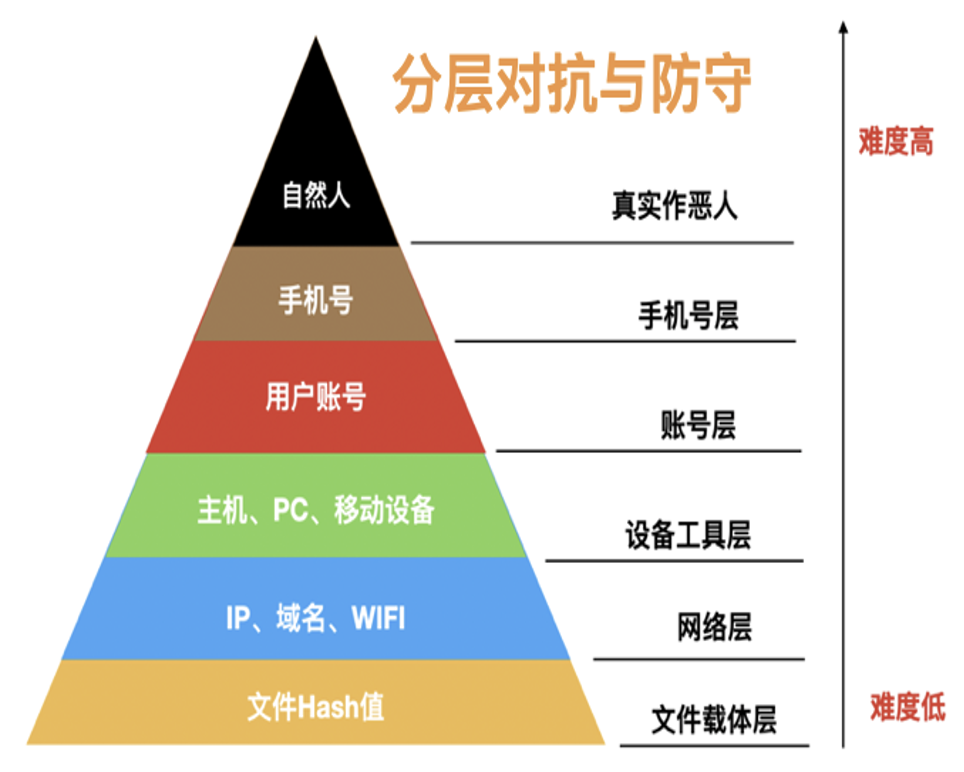
每一個平面上,之前攻擊方與防守方都是單獨的對抗,現在利用圖資料庫之後,可以將每一個層次的實體ID通過關聯關係串聯起來,形成一張立體層次的網,通過這張立體層次的網能夠使企業快速掌握攻擊者的攻擊方式、作弊工具、團伙特徵等較全貌的資訊。
因此基於安全數據的圖結構數據建模,可以將原來的平面識別層次變成立體網狀識別層次,能幫助企業更清晰準確的識別攻擊與風險。
3.1 基本圖結構
安全情報的圖建模主要目的是希望判斷任何一個維度風險的時候,不單單局限於該維度本身的狀態與屬性去看它的風險,而是將維度從個體擴展為網路層面,通過圖結構的數據關係,通過上下層次(異構圖)及同級層次(同構圖)立體去觀察該維度的風險。
以設備風險舉例:對一個設備而言,整體分為網路層、設備層、帳號層和用戶層這四個層面,每個層面都由其代表性的實體 ID 來表達。通過圖資料庫,可以做到對一個設備進行立體的三維層次的風險認知,這對於風險的識別會非常有幫助。
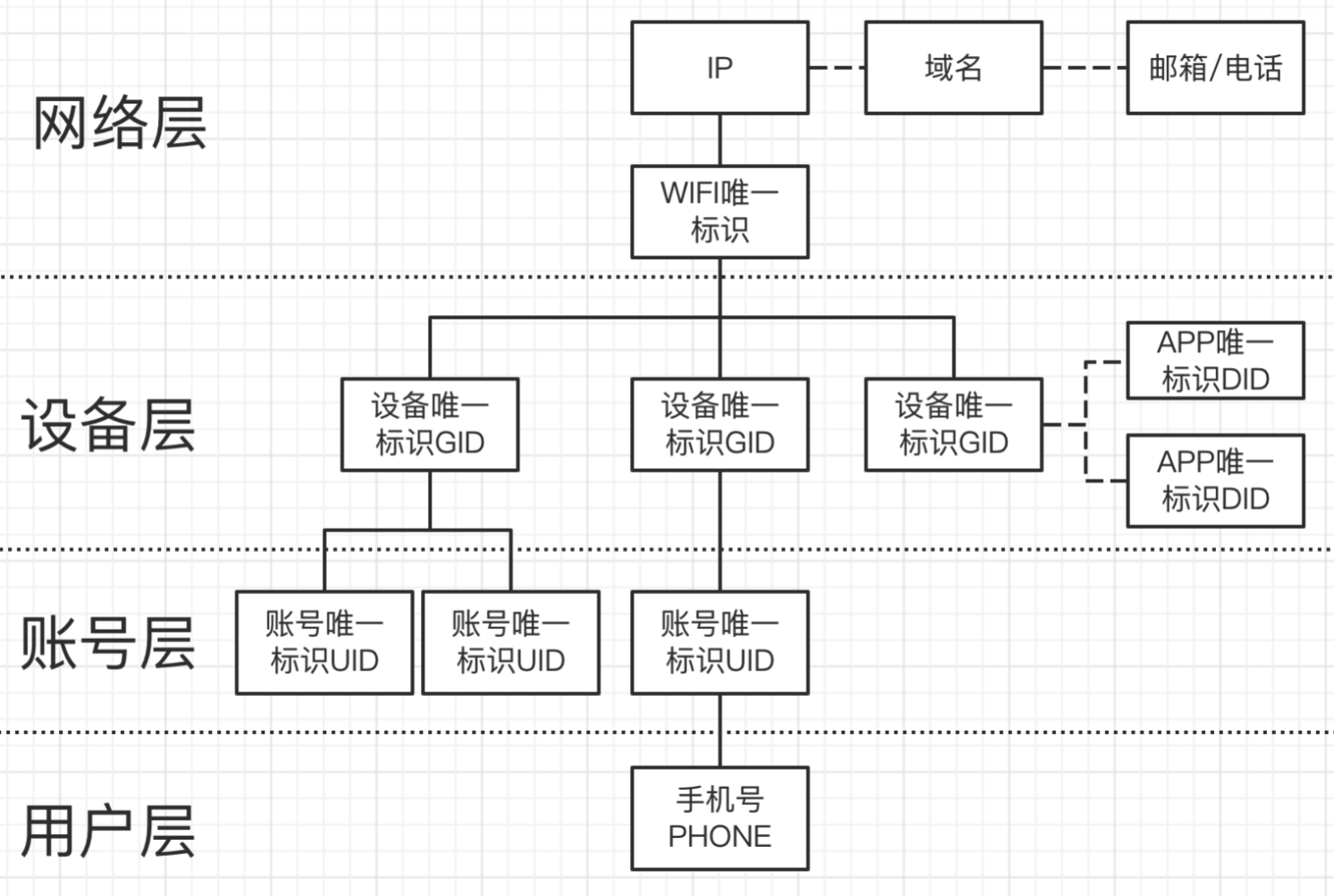
如上圖所示,這是安全情報的基本圖結構建模,以上構成了一個基於安全情報的知識圖譜。
3.2 動態圖結構
在基本圖結構之上,還需要考慮的是,每一種關聯關係的存在都是有時效性的,A 時間段內關聯關係存在,B 時間段內該關聯關係則未必存在,因此我們希望安全情報能在圖資料庫上真實反映客觀現實的這種不同時間段內的關聯關係。
這意味著需要隨著查詢時間區間的不同,而呈現出不同的圖結構模型的數據,我們稱之為動態圖結構。
在動態圖結構的設計上,涉及到的一個問題是:在被查詢的區間上,什麼樣的邊關係應該被返回?
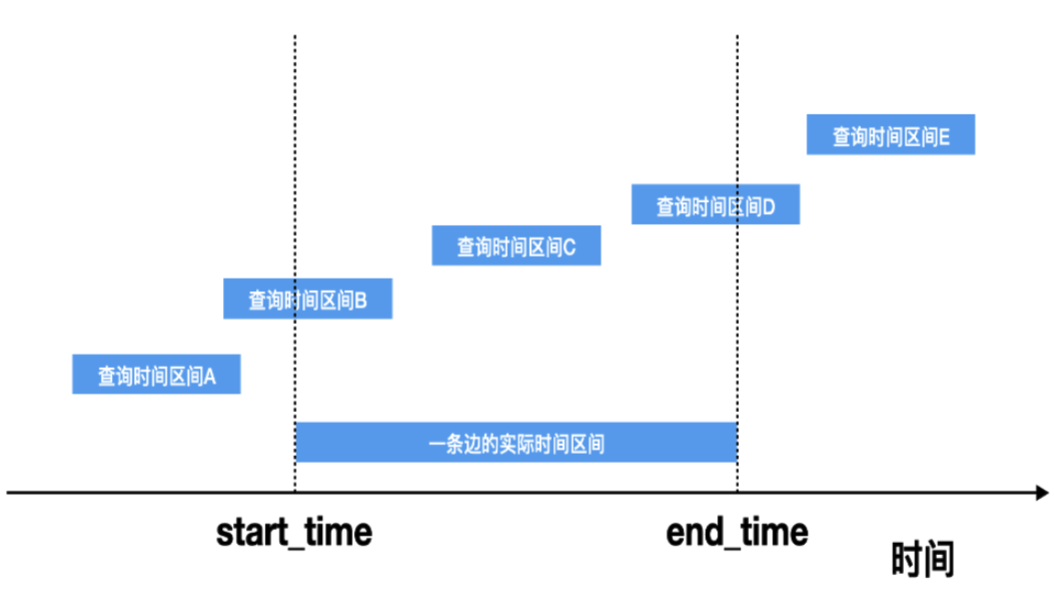
如上圖所示,當查詢時間區間為 B、C、D 時,這條邊應該要被返回,當查詢時間區間為A、E時,這條邊不應該被返回。
3.3 權重圖結構
在面對黑灰產或者真人作惡時,往往會出現這種情況:就是一個設備上面會對應非常多的帳號,有些帳號是不法壞人自己的常用帳號,而有些帳號則是他們買來做特定不法直播的帳號。為配合公安或法務的打擊,我們需要從這批帳號裡面精準區分出哪些帳號是真實壞人自己的常用帳號,而哪些帳號只是他們買來用於作惡的帳號。
因此這裡面會涉及到帳號與設備關聯關係邊的權重問題:如果是該設備常用的帳號,那麼表明這個帳號與這個設備的關係是較強的關係,則這條邊的權重就會高;如果僅僅是作惡/開直播的時候才會使用的帳號,那麼帳號與設備的關係則會比較弱,相應權重就會低一些。
因此我們在邊的屬性上,除了有時間維度外,還增加了權重維度。
綜上所述,最終在安全情報上所建立的圖模型是:帶權重的動態時區圖結構。
四. 基於圖資料庫的安全情報服務架構與優化
整體安全情報服務架構圖如下所示:
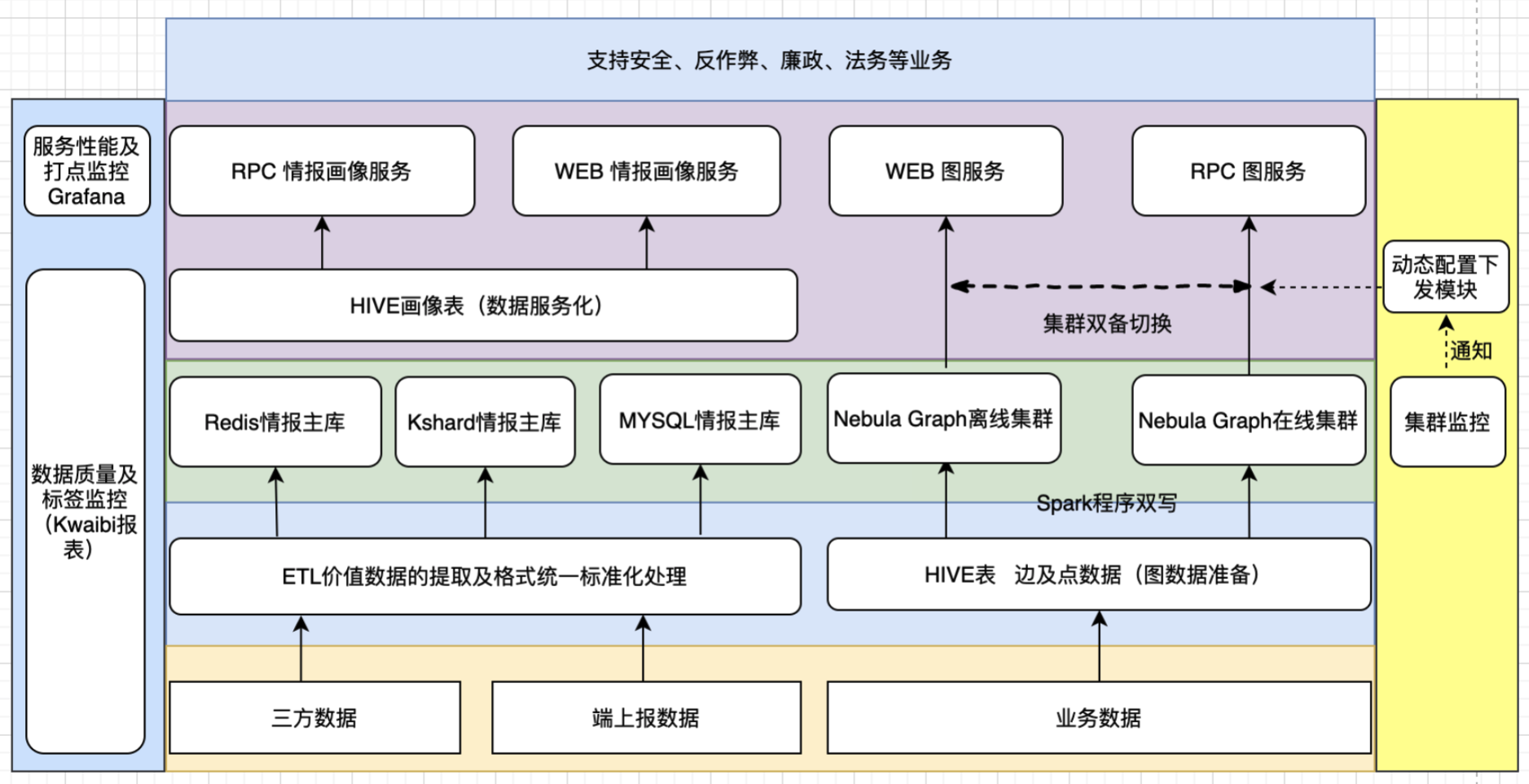
安全情報服務整體架構圖
其中,基於圖資料庫的情報綜合查詢平台,軟體架構如下圖所示:
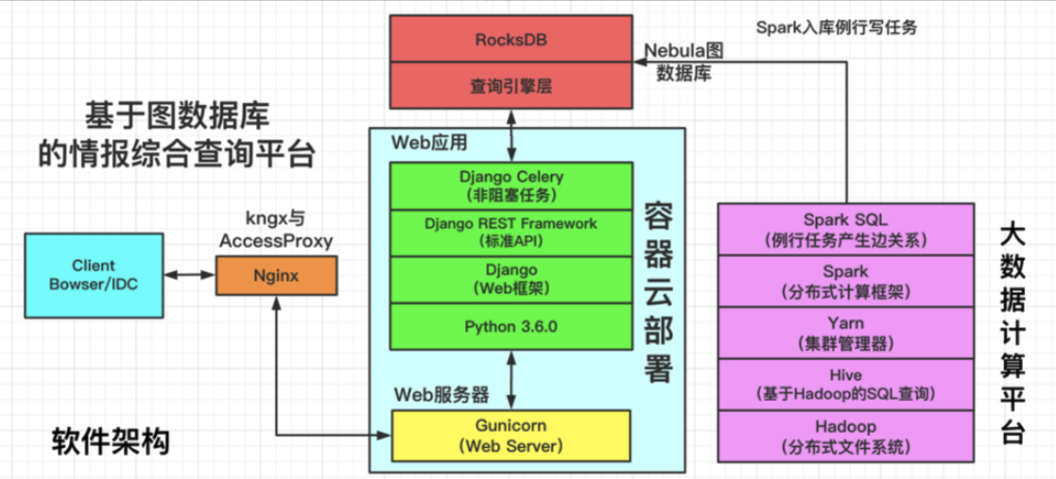
情報綜合查詢平台軟體架構圖
註:AccessProxy 支援辦公網到 IDC 的訪問,kngx 支援 IDC 內的直接調用
4.1 離線數據寫入優化
針對所構建的關聯關係數據,每天更新的量在數十億級別,如何保證這數十億級別的數據能在小時級內寫入、感知數據異常且不丟失數據,這也是一項非常有挑戰性的工作。
對這部分的優化主要是:失敗重試、臟數據發現及導入失敗報警策略。
數據導入過程中會由於臟數據、服務端抖動、資料庫進程掛掉、寫入太快等各種因素導致寫 batch 數據失敗,我們通過用同步 client API、多層級的重試機制及失敗退出策略,解決了由於服務端抖動重啟等情況造成的寫失敗或寫 batch 不完全成功等問題。
4.2 雙集群 HA 保證與切換機制
在圖資料庫部分,快手部署了在線與離線兩套圖資料庫集群,兩個集群的數據採用同步雙寫,在線集群承擔在線 RPC 類的服務,離線集群承擔 CASE 分析及 WEB 查詢的服務,這兩個集群互不影響。
同時集群的狀態監控與動態配置下發模組是打通的,當某一個集群出現慢查詢或發生故障時,通過動態配置下發模組來進行自動切換,做到上層業務無感知。
4.3 集群穩定性建設
數據架構團隊對開源版本的 Nebula Graph 進行了整體的調研、維護與改進。
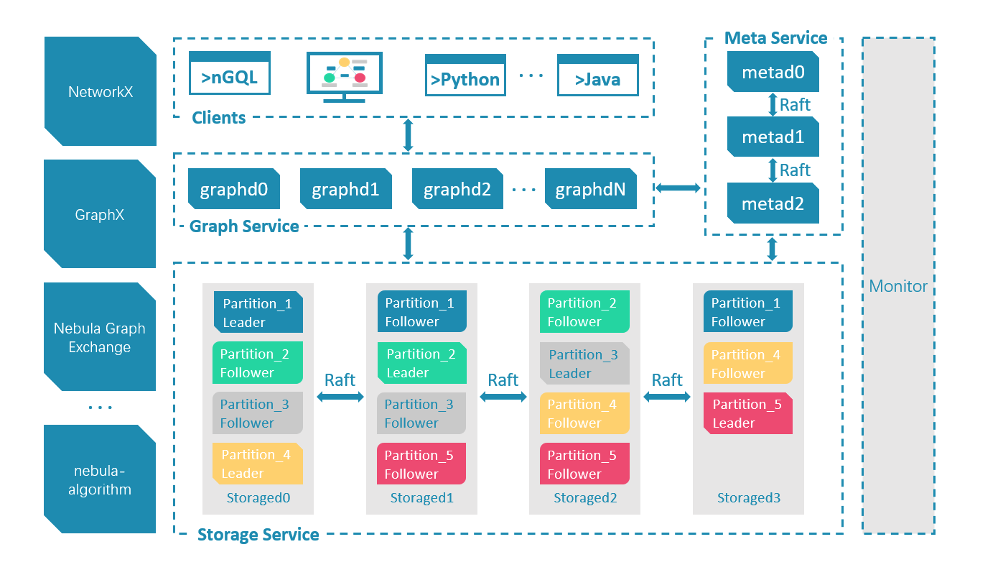
Nebula 的集群採用計算存儲分離的模式,從整體架構看,分為 Meta,Graph,Storage 三個角色,分別負責元數據管理,計算和存儲:
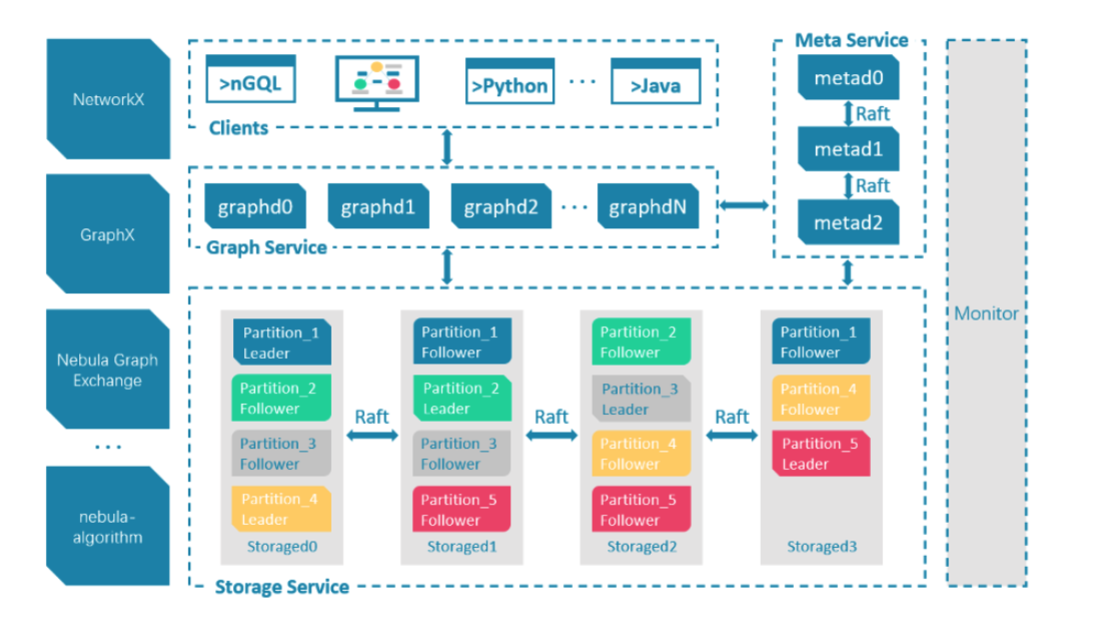
Nebula 整體架構圖
Nebula 的存儲層作為圖資料庫引擎的底座,支援多種存儲類型,我們使用 Nebula 時選擇了經典模式,即用經典的 C++ 實現的 RocksdDB 作為底層 KV 存儲,並利用 Raft 演算法解決一致性的問題,使整個集群支援水平動態擴容。
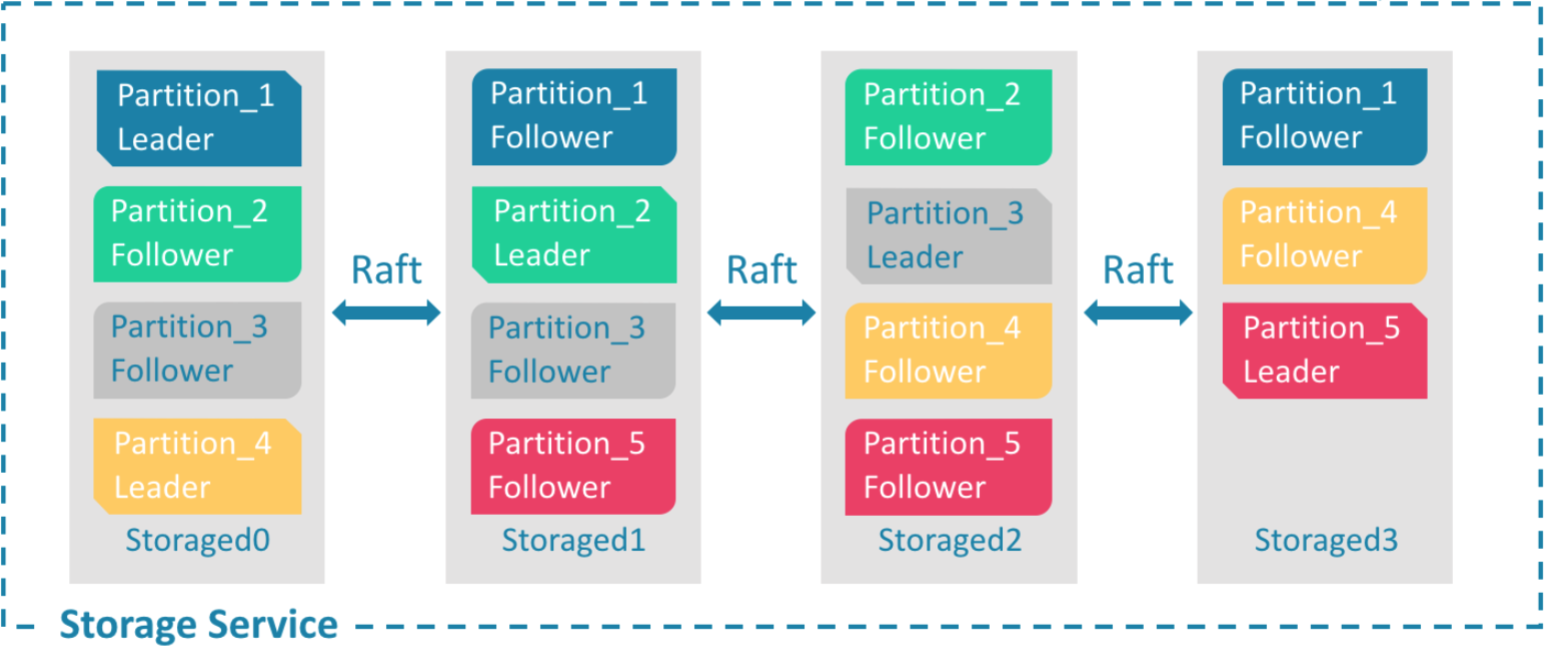
存儲層架構圖
我們對存儲層進行了充分的測試、程式碼改進與參數優化。其中包括:優化 Raft 心跳邏輯、改進 leader選舉和 log offset 的邏輯以及對 Raft 參數進行調優等,來提升單集群的故障恢復時間;再結合客戶端重試機制的優化,使得 Nebula 引擎在用戶體驗上從最初的故障直接掉線改善為故障毫秒級恢復。
在監控報警體系上,我們構建了對集群多個層面的監控,其整體監控架構如下圖所示:
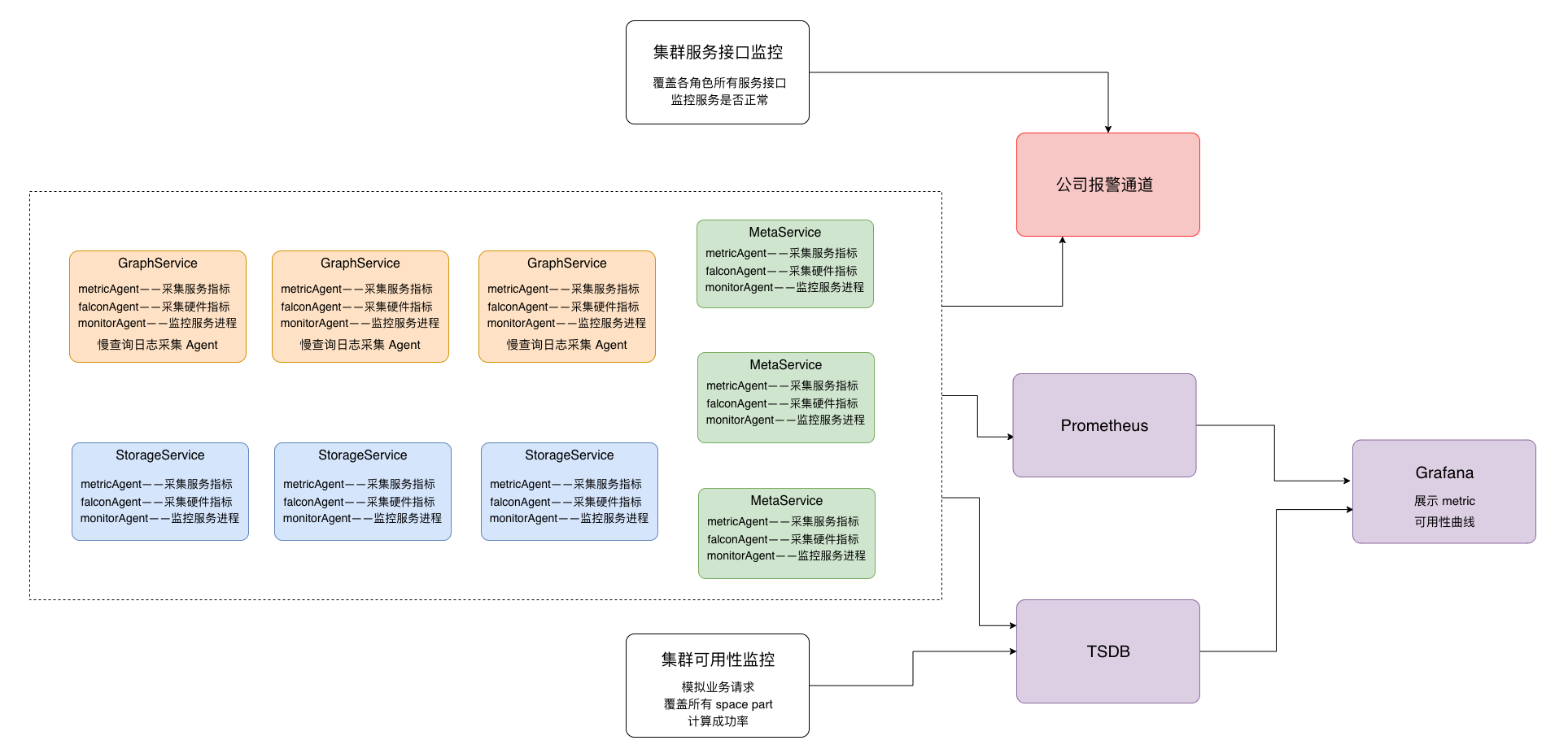
集群監控架構圖
包括如下幾個方面:
- 機器硬體層面 cpu busy、磁碟 util、記憶體、網路等
- 集群每個角色 meta、storage、graph 服務介面監控、partition leader上線狀態及分布的監控
- 從用戶角度對集群整體可用性的評估監控
- 集群各角色 meta、storage、rocksdb、graph 的 metric 採集監控
- 慢查詢監控
4.4 對超級節點查詢的優化
由於現實圖網路結構中點的出度往往符合冪律分布特徵,圖遍歷遇到超級點(出度百萬/千萬)將導致資料庫層面明顯的慢查詢,如何保證在線服務查詢耗時的平穩性,避免極端耗時的發生是我們需要解決的問題。
圖遍歷超級點問題在工程上的解決思路是:在業務可接受的前提下縮小查詢規模。具體方法有:
- 查詢中做符合條件的 limit 截斷
- 查詢按一定比例進行邊取樣
下面分別描述具體的優化策略:
4.4.1 limit 截斷優化
【前提條件】
業務層面可接受每一跳做 limit 截斷,例如如下兩個查詢:
# 最終做limit截斷
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP.create_time as create_time, GID_IP.update_time as update_time, $^.IP.ip as ip, $$.GID.gid | limit 100
# 在中間查詢結果已經做了截斷,然後再進行下一步
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP._dst as dst | limit 100 | go from $-.dst ..... | limit 100
【優化前】
對第二個查詢語句,在優化前,storage會遍歷點的所有出度,graph 層在最終返回 client 前才做 limit n 的截斷,這種無法避免大量耗時的操作。
另外 Nebula 雖然支援 storage 配置集群(進程)級別參數max_edge_returned_per_vertex(每個 vertex 掃描最大出度),但無法滿足查詢語句級別靈活指定 limit 並且對於多跳多點出度查詢也無法做到語句級別精確限制。
【優化思路】
一跳 go 遍歷查詢分兩步:
- step1:掃描 srcVertex 所有出度 destVertex(同時獲取邊的屬性)
- step2:獲取所有 destVertex 的屬性 value
那麼 go 多跳遍歷中每跳的執行分兩種情況:
- case 1:只執行 step1 掃邊出度
- case 2:執行 step1 + step2
而 step2 是耗時大頭(查每個 destVertex 屬性即一次 rocksdb iterator,不命中 cache 情況下耗時 500us),對於出度大的點將「limit 截斷」提前到 step2 之前是關鍵,另外 limit 能下推到 step1 storage 掃邊出度階段對於超級點也有較大的收益。
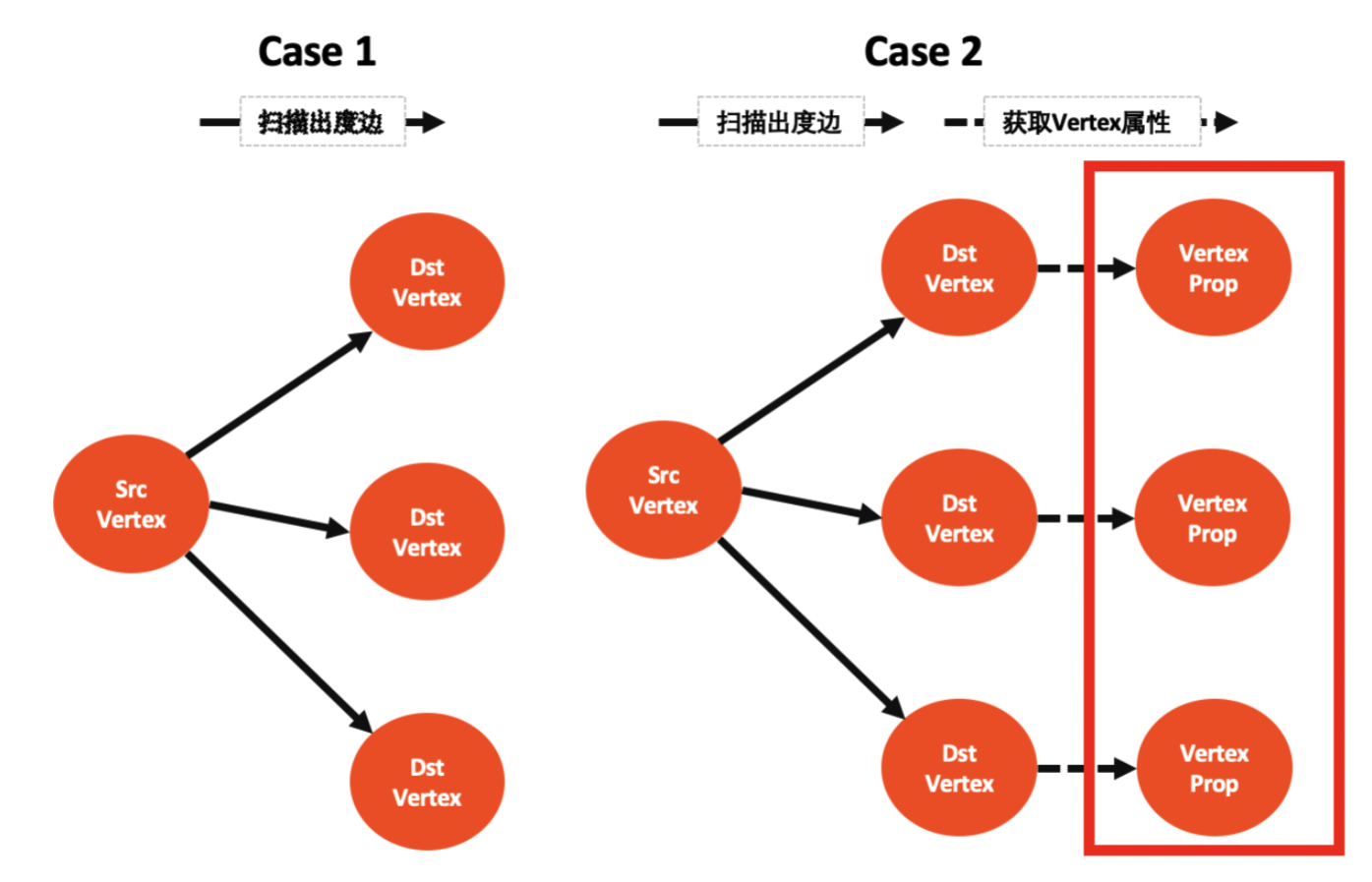
這裡我們總結下什麼條件下能執行「limit 截斷優化」及其收益:
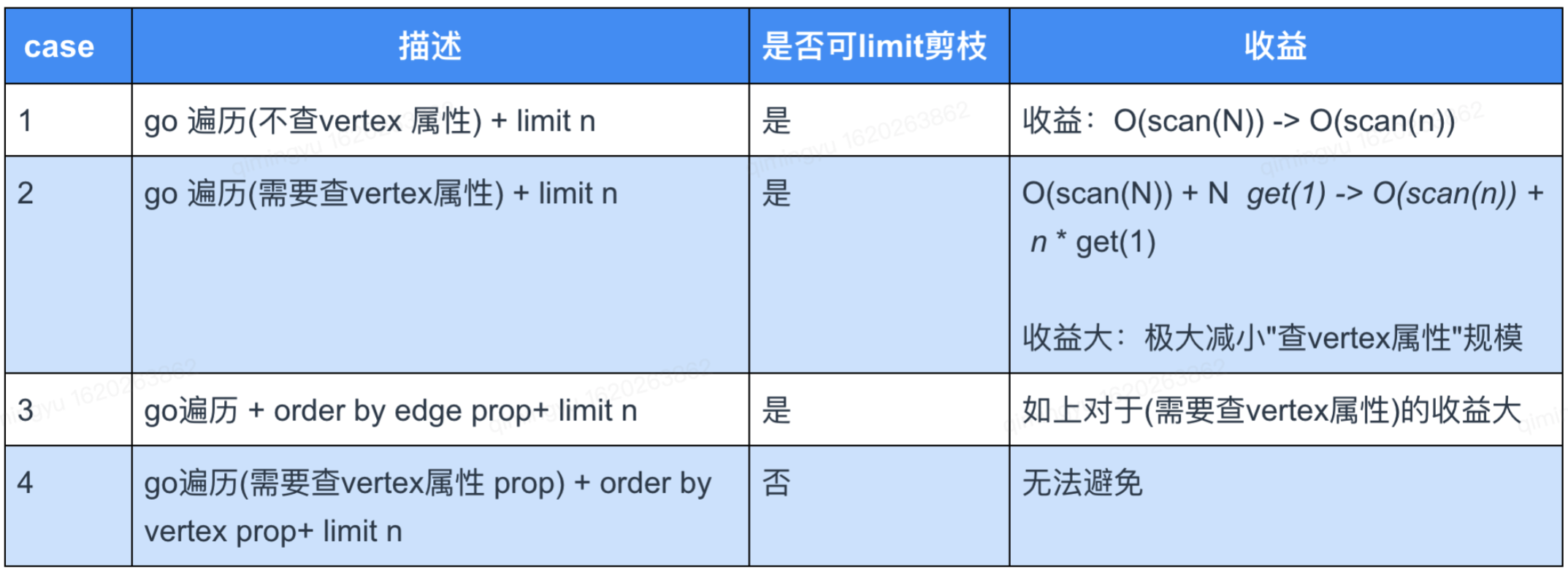
表注釋: N 表示 vertex 出度,n 表示 limit n,scan 表示掃邊出度消耗,get 表示獲取 vertex 屬性的消耗
【測試效果】
對於以上 case1 和 case2 可執行「limit 截斷優化」且收益明顯,其中安全業務查詢屬於 case2,以下是在 3 台機器集群,單機單盤 900 GB 數據存儲量上針對 case2 limit 100 做的測試結果(不命中 rocksdb cache 的條件):
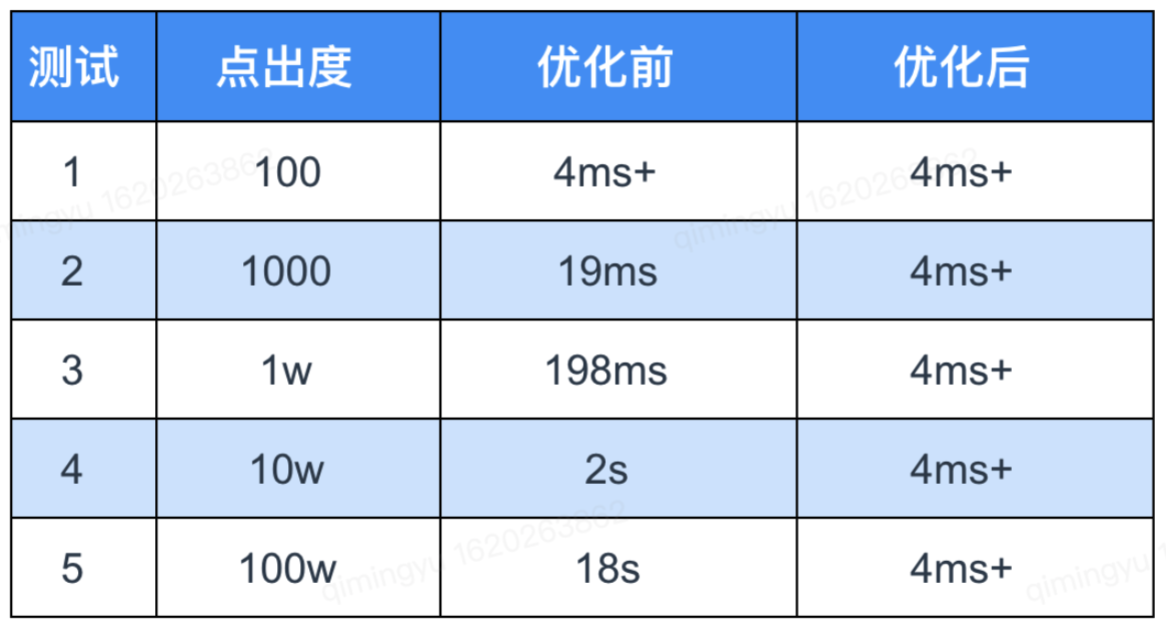
以上測試結果表明,經過我們的優化後,在圖超級點查詢耗時上,取得了非常優異的表現。
4.4.2 邊取樣優化
針對不能簡單做「limit 截斷優化」的場景,我們可以採取「邊取樣優化」的方式來解決。在 Nebula 社區原生支援的「storage 進程級別可配置每個 vertex 最大返回出度邊和開啟邊取樣功能」基礎上,我們優化後,可以進一步支援如下功能:
- storage 開啟取樣功能後,可支援配置掃
max_iter_edge_for_sample數量的邊而非掃所有邊(默認) - graph 支援
go每跳出度取樣功能 - storage 和 graph 的「取樣是否開啟
enable_reservoir_sampling」和「每個 vertex 最大返回出度max_edge_returned_per_vertex」都支援 session 級別參數可配
通過以上功能的支援,業務可以更靈活地調整查詢取樣比例,控制遍歷查詢規模,以達到在線服務的平滑性。
4.5 查詢客戶端的改造與優化
開源的 Nebula Graph 有自己的一套客戶端,而如何將這套客戶端與快手的工程相結合,這裡我們也做了一些相應的改造與優化。主要解決了下面兩個問題:
- 連接池化:Nebula Graph 官方客戶端提供的底層介面,每次查詢都需要建立連接初始化、執行查詢、關閉連接這些步驟,在高頻查詢場景中頻繁創建、關閉連接極大地影響著系統的性能與穩定性。在實踐中,通過連接池化技術對官方客戶端進行二次封裝,並對連接生命周期的各個階段進行監控,實現了連接的復用和共享,提升了業務穩定性。
- 自動故障切換:通過對連接建立、初始化、查詢、銷毀各個階段的異常監控和定期探活,實現了資料庫集群中的故障節點的實時發現和自動剔除,如果整個集群不可用,則能秒級遷移至備用集群,降低了集群故障對在線業務可用性造成的潛在影響。
4.6 查詢結果的可視化及下載
針對固定關係的查詢(寫死 nGQL),前端根據返回結果,進行訂製化的圖形介面展示,如下圖所示:
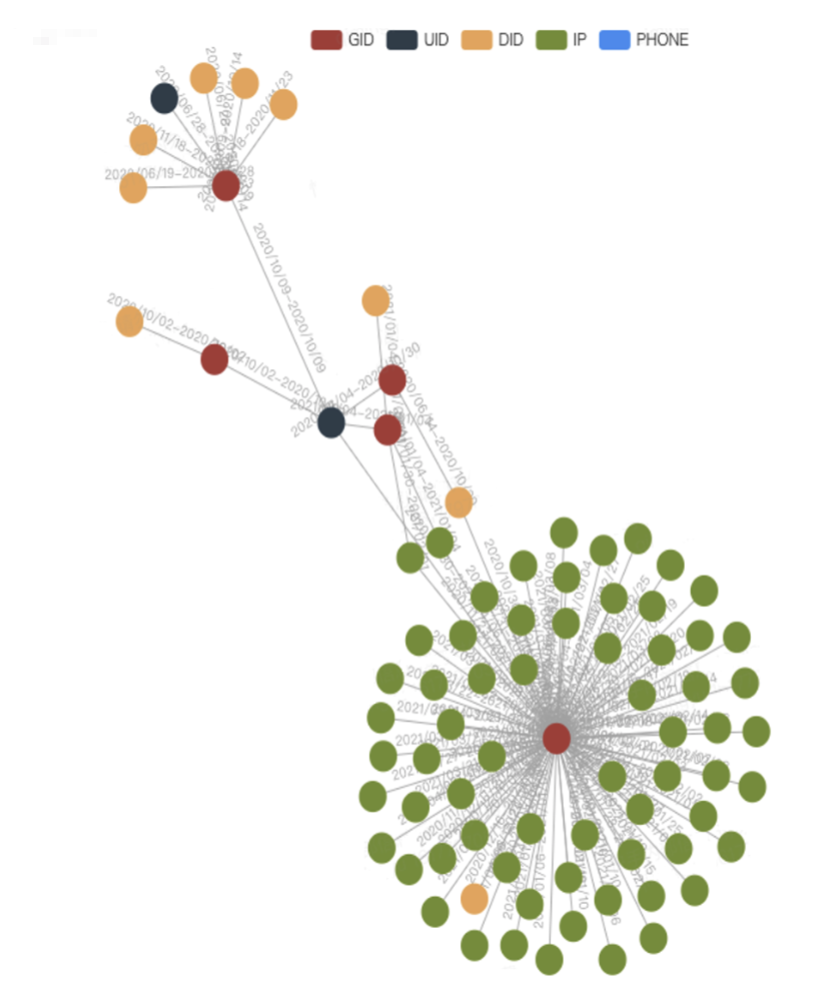
這裡前端採用ECharts的關係圖,在前端的圖結構數據載入及展示這裡也做了一些優化。
問題一:關係圖需要能展示每個節點的詳情資訊,而 ECharts 提供的圖裡只能做簡單的 value 值的展示。
解決方案:在原程式碼上進行改造,每個節點添加點擊事件,彈出模態框展示更多的詳情資訊。
問題二:關係圖在點擊事件觸發後,圖會有較長時間的轉動,無法辨認點擊了哪個節點。
解決方案:獲取初次渲染圖形時每個節點的窗口位置,在點擊事件觸發後,給每個節點位置固定下來。
問題三:當圖的節點眾多時候,關係圖展示的比較擁擠。
解決方案:開啟滑鼠縮放和評議漫遊功能。
針對靈活關係的查詢(靈活 nGQL),根據部署的Nebula Graph Studio進行可視化的呈現,如下圖所示:
五. 圖資料庫在安全情報上的實踐
基於以上圖資料庫的結構與優化,我們提供了 Web 查詢和 RPC 查詢兩種接入方式,主要支援了快手的如下業務:
- 支援快手安全的溯源、線下打擊與黑灰產分析
- 支援業務安全的風控與反作弊
例如,群控設備與正常設備在圖數據上的表現存在明顯區別:
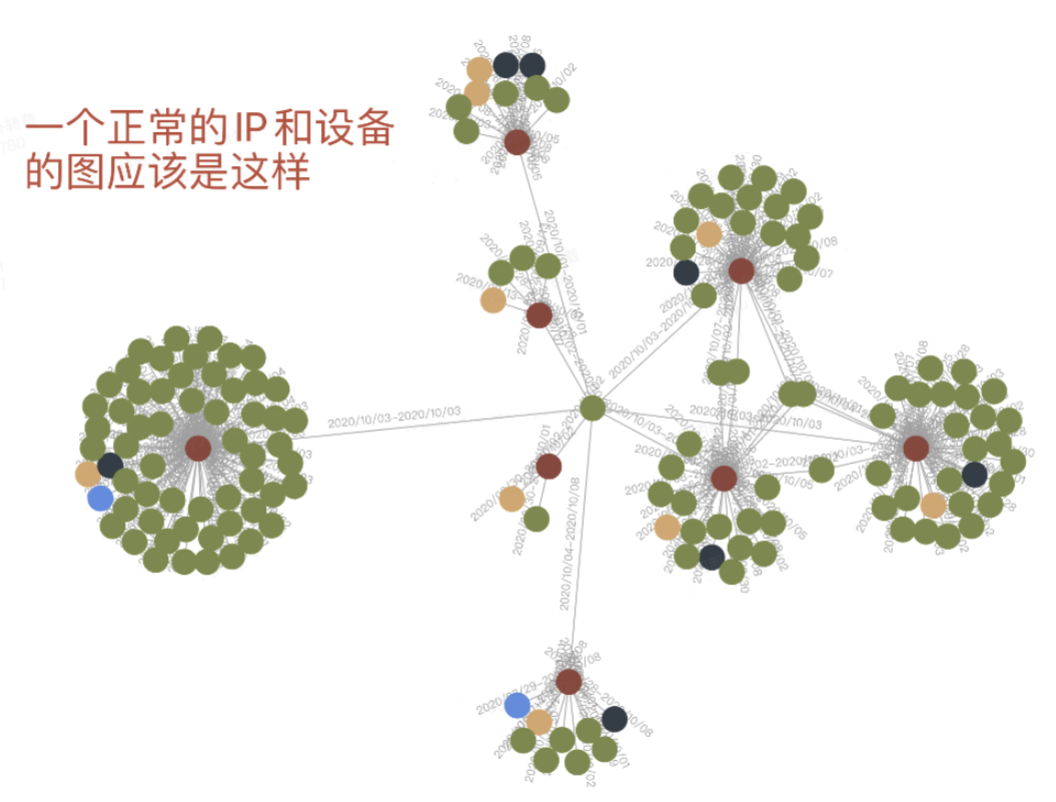
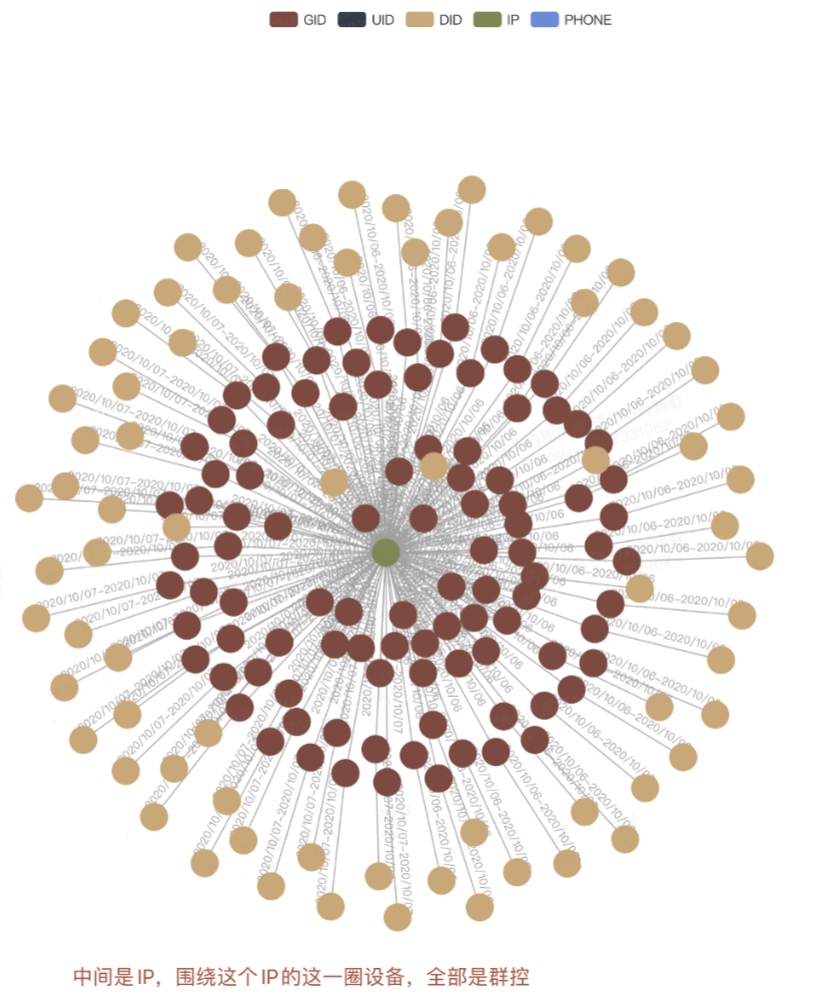
對於群控設備的識別:
六. 總結與展望
- 穩定性建設:集群 HA 能力實現跨 AZ 集群的實時同步、訪問自動切換,以保障99.99 的 SLA
- 性能提升:考慮改造 RPC、AEP 新硬體的存儲方案、優化查詢執行計劃
- 圖計算平台與圖查詢打通:建設圖計算/圖學習/圖查詢的一體化平台
- 實時判定:實時關係的寫入及實時風險的綜合判定
七. 致謝
感謝開源社區Nebula Graph對快手的支援。
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebulae 名片,Nebula 小助手會拉你進群~~


