Elasticsearch資料庫優化實戰:讓你的ES飛起來
摘要:ES已經成為了全能型的數據產品,在很多領域越來越受歡迎,本文旨在從資料庫領域分析ES的使用。
本文分享自華為雲社區《Elasticsearch資料庫加速實踐》,原文作者:css_blog 。
一、方案說明
Elasticsearch主要功能是什麼,不同的場景有不同的定位,在日誌場景我們可以用ELK生態搭建日誌分析系統,在搜索領域ES是當前最熱門的搜索引擎。在大數據領域,ES可以對標Hbase提供海量日誌的數據倉庫;在資料庫領域ES可以作為查詢分析型的分析型資料庫使用。ES已經成為了全能型的數據產品,在很多領域越來越受歡迎,本文旨在從資料庫領域分析ES的使用。
ES不是關係型資料庫,數據更新採用樂觀鎖,通過版本號控制,不支援事務處理,這也是ES區別於傳統資料庫(Mysql)的地方;但是ES支援精確查詢加速,多條件任意組合查詢,多種聚合查詢,查詢速度很快,可以替代資料庫複雜條件查詢的場景需求,甚至可以代替資料庫做二級索引。
在資料庫加速場景通常的做法是客戶產生的商品訂單數據會寫入Mysql類關係型資料庫,資料庫寫入保證事務性,但是隨著商品訂單的數據越來越多,同時客戶查詢的條件多變,無法所有欄位都建立索引,資料庫的查詢能力遠遠不能滿足查詢訴求。我們考慮用ES全量同步資料庫數據,在ES中做多條件聚合查詢,查詢的結果可以在Mysql中做關聯搜索,在查詢商品訂單詳情展示, Mysql數據和ES數據可以不要求實時一致,可以通canal消費Mysql binlog日誌資訊, 同步到ES,實現一次寫入,保證數據一致性。以下資料庫都以Mysql為例進行說明。
二、索引原理分析
ES為什麼查詢能力遠遠超過Mysql關係型資料庫,主要是他們的實現原理和底層存儲的數據結構差異決定的,以下比較兩種產品的實現原理。
Elasticsearch會對所有輸入的文本進行處理,建立索引放入記憶體中,從而提高搜索效率。在這一點上ES要優於MySQL的B+樹的結構,MySQL需要將索引放入磁碟,每次讀取需要先從磁碟讀取索引然後尋找對應的數據節點,但是ES能夠直接在記憶體中就找到目標文檔對應的大致位置,最大化提高效率。並且在進行組合查詢的時候MySQL的劣勢更加明顯,它不支援複雜的組合查詢比如聚合操作,即使要組合查詢也要事先建好索引,但是ES就可以完成這種複雜的操作,默認每個欄位都是有索引的,在查詢的時候可以各種互相組合。
(1)資料庫索引B+樹
資料庫中索引都是以樹來組織的,常用的有B tree,B-tree,B+tree,以下介紹B+tree的組織結構。
首先我們先想像下為什麼需要建立索引,假設我們有一張表book,存儲了我們保持的書籍資訊,名稱,作者,發布時間等,我們有10000條記錄,如果我們需要找一本為《database》的書,那我們的SQL為:
select name,author form book where name = 『database』;
我們需要掃描整個表,全量比較才可以,如果我們對name建立索引,書名已經按照順序排序,查詢時只需要找到對應位置就可以快速獲取結果。
索引的本質是通過不斷地縮小想要獲取數據的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查找方式來鎖定數據。
資料庫採用B+tree建立索引:
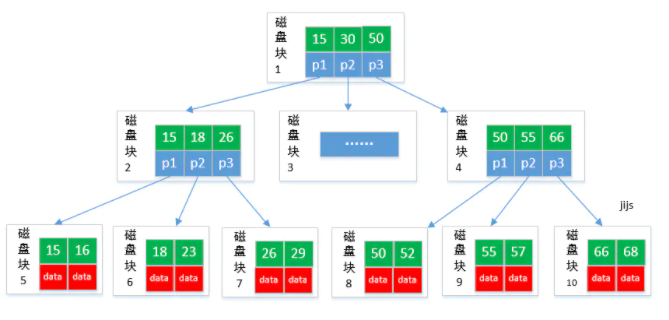
B+tree 數據只存儲在葉子節點中。這樣在B樹的基礎上每個節點存儲的關鍵字數更多,樹的層級更少所以查詢數據更快,所有指關鍵字指針都存在葉子節點,所以每次查找的次數都相同所以查詢速度更穩定。
(2)Elasticsearch索引原理
ES建立索引採用倒排索引的方式存儲。
對輸入的所有數據都建立索引,並且把所有和文檔對應起來,在我們查找數據的時候我們直接查找詞典(Term),在找到Term對應的文檔ID,進而找到數據。這和Mysql使用B+tree樹建立索引的方式類似,但是如果詞典Term很大,對Term的搜索就會很慢,ES進一步建議了詞典索引(FST),提升詞典的搜索能力。
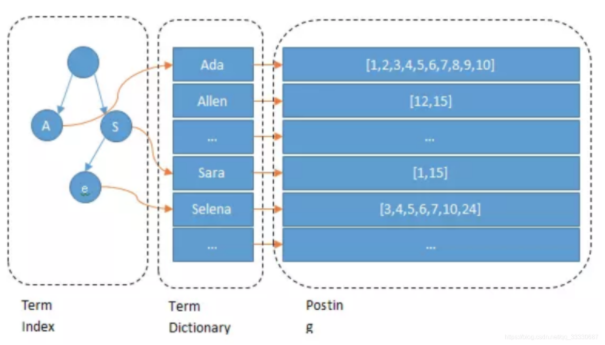
Term Index 以樹的形式保存在記憶體中,運用了FST+壓縮公共前綴方法極大的節省了記憶體,通過Term Index查詢到Term Dictionary所在的block再去磁碟上找term減少了IO次數。
Term Dictionary 排序後通過二分法將檢索的時間複雜度從原來N降低為logN。
三、查詢對比分析
以下對於資料庫搜索常用的場景對比ES和資料庫:
- 全文檢索
ES支援全文檢索,可以對數據分詞,每個詞通過FSP建立詞典索引,而Mysql關係資料庫則不支援,想像下如果搜索的不是整個欄位而是欄位中的幾個關鍵詞,使用Mysql搜索必須全表掃描。
- 精確搜索
如果Mysql對該欄位建立過索引,使用ES搜索和Mysql搜索性能差異不大,可能Mysql更快點,但是ES是分散式系統,可以支援PB級別的數據搜索,對大表搜索ES優勢更明顯。
- 多條件查詢
我們知道Mysql需要對欄位建立索引才能加速搜索過程,而ES默認是全索引的,對於多條件查詢,觸發Mysql建立聯合索引,否則多個欄位搜索,Mysql 先選擇一個欄位搜索,結果在使用第二個欄位過濾得到最終結果。
ES則採用多個欄位結果集交並操作,使用bitmap或者skiplist加快搜索速度,相比Mysql優勢明顯。
- 聚合搜索
Mysql聚合搜索如果沒有建立索引需要全表掃描排序,如果建立索引在B+tree上進行範圍查詢。
ES為了加快聚合搜索速度,通過Doc value來解決聚合搜索問題。DocValue就是列式存儲。
存儲結果如下:

Docvalue數據按照文檔ID排序,DocValue將隨機讀取變成了順序讀取,
在es中,因為分片的存在,數據被拆分成多份,放在不同機器上。但是給用戶體驗卻好像只有一個庫一樣。對於聚合查詢,其處理是分兩階段完成的:
- Shard 本地的 Lucene Index 並行計算出局部的聚合結果。
- 收到所有的 Shard 的局部聚合結果,聚合出最終的聚合結果。
這種兩階段聚合的架構使得每個 shard 不用把原數據返回,而只用返回數據量小得多的聚合結果。這樣極大的減少了網路頻寬的消耗。
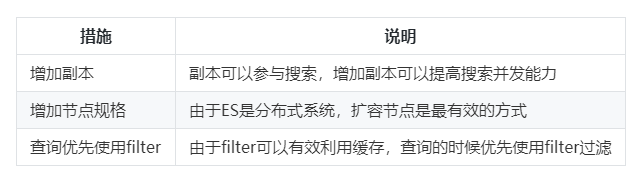
- 多副本加速
我們知道ES有shard和replica的概念,副本一方面可以保證數據的可靠性,另一方面多副本可以加快搜索速度提高搜索並發能力。
四、資料庫到Elasticsearch同步方案
結合用戶實際的使用方式和數據量的大小,Mysql數據到ES可以有多種不同的方式選擇。
- Canal=>Elasticsearch
使用Canal直接消費Mysql binlog日誌寫入ES,這種方式如果Mysql寫入量大,會面臨Canal寫入阻塞問題。
- Canal =>Kafka=>Elasticsearch
Canal數據寫入到Kafka,使用另外的app消費Kafka數據同步到ES
五、問題匯總
1.索引shard問題
在Mysql數據同步到ES中面臨索引的建立的問題,在數據寫入ES之前我們需要提前規劃數據的shards和replicas的個數,replicas 可以動態修改,但是shards數創建完成後不能修改。
隨著Mysql數據量的增加,如果shard太少,就會導致每個shard的數據量太大的問題。
如果一個索引600G,只有3 個shard,每個shard就200G,會極大的損耗查詢能力,也不利於數據遷移。
我們可以按照月來滾動創建索引,通過索引別名把所有索引關聯起來使用。
test_data-202101 test_data-202102
2.查詢加速問題
在使用ES對資料庫進行加速的場景,我們希望的是ES查詢能力儘可能快。在ES查詢不滿足要求的時候我們需要對查詢進行調優。
常用的方法有: