上課老師提問我什麼是二叉查找樹,我把這些動圖拿了出來,動圖圖解及程式碼實現。
- 2021 年 5 月 17 日
- 筆記
- 數據結構和演算法:簡單方法
本文為系列專題【數據結構和演算法:簡單方法】的第 12 篇文章。
- 數據結構 | 順序表
- 數據結構 | 鏈表
- 數據結構 | 棧
- 數據結構 | 隊列
- 數據結構 | 雙鏈表和循環鏈表
- 數據結構 | 二叉樹的概念和原理
- 數據結構 | 二叉樹的創建及遍歷實現
- 數據結構 | 線索二叉樹
- 數據結構 | 二叉堆
- 演算法 | 順序查找和二分查找
1. 是什麼?
二叉查找樹(Binary Search Tree)必須滿足以下特點:
- 若左子樹不為空,則左子樹的所有結點值皆小於根結點值
- 若右子樹不為空,則右子樹的所有結點值皆大於根結點值
- 左右子樹也是二叉排序樹
如下圖,是一顆二叉查找樹:
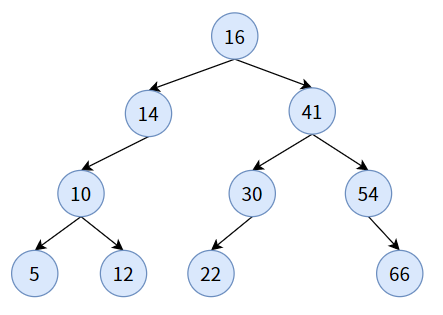
如果你對二叉查找樹進行中序遍歷,可以得到:5, 10, 12, 14, 16, 22, 30, 41, 54, 66。剛好是一個從小到大的有序序列,從這一點看,二叉查找樹是可以進行排序的,所以這種樹又叫二叉排序樹(Binary Sort Tree)。
2. 查找
我們以上圖為例,說明查找成功和失敗兩種過程。
先貼出程式碼:
int bst_search(BSTNode *root, int key, BSTNode **p, BSTNode *q)
{
if (root == NULL) { // 空樹,查找失敗
*p = q;
return 0;
}
if (key == root->data) { // 目標值相等根結點的值,查找成功
*p = root;
return 1;
} else if (key < root->data) { // 目標值小於根結點的值,遞歸進入左子樹
return bst_search(root->left_child, key, p, root);
} else { // 目標值大於根結點的值,遞歸進入右子樹
return bst_search(root->right_child, key, p, root);
}
}
該方法中的三個指針的作用如下:
-
指針
root始終指向根結點, 標識了與目標值比較的結點; -
二級指針
p指向最終查找的結果。如果查找成功,則指向「指向『找到的結點』的指針」;如果查找失敗,則指向「指向『上次最後一個訪問的結點』的指針」。 -
指針
q初始為空,以後始終指向上一個根結點。
下面是查找成功的過程動圖:

下面是查找失敗的過程動圖:

請注意,以上過程成立的前提是:二叉樹是一顆二叉排序樹,必須滿足二叉排序樹的三個特點。
所以,二叉排序樹的「排序」二字是為查找而服務的,上面兩個動圖足以說明,排序方便了查找,因為每次比較都在縮小範圍。
二叉排序樹和二分查找本質上做的事是一樣的,比如以下幾方面:
- 都是有序的。二分查找是全部有序,二叉排序數是局部有序。
- 都是將一組數劃分成若干區域。二分查找通過三個標誌位,二叉排序樹通過樹結構。
- 都是通過比較目標值和「區域分界點」的大小,從而確定目標值在哪個區域中。在二分查找中與中間標誌位比較,在二叉查找樹中與根結點比較。
我們在二分查找中說過:當涉及到頻繁地插入和刪除操作時,二分查找就不合適了。原因之一是二分查找要求元素是有序的(從小到大或從大到小),插入、刪除破壞順序後,需要額外精力維護有序狀態。原因之二是二分查找使用順序表實現,順序表的插入和刪除操作需要移動大量元素,也會影響效率。
但是二叉排序樹是一個樹,樹結構通常使用鏈式結構來實現。鏈式結構對插入和刪除操作很友好,也有利於我們維護二叉樹的有序狀態。
3. 創建和插入
現在給你一組沒有順序的數,比如 {16, 41, 14, 30, 10, 12, 54, 5, 22, 66},如何創建出一顆二叉查找樹(BST)?這裡為了方便起見,我們約定二叉查找樹中沒有重複值。
所謂創建,即向一個空樹中不斷插入結點,從而構成一個非空的二叉查找樹。所以關鍵在於如何向一個二叉查找樹中插入結點。
所謂插入,即不斷比較待插入結點和樹中結點的值,使其插到合適的位置,怎麼找到「合適的位置」呢?方法前面已經給出,即 bst_search。
如果我們在二叉查找樹中查找待插入值,一定會查找失敗,即 bst_search 一定返回 0,所以bst_search 方法中的 p 指針最終指向的是最後一個訪問的根結點,這個根結點的左孩子或右孩子即是「合適的位置」。
下面是創建(插入)的過程動圖,和查找失敗的過程動圖非常相似:

插入一個結點的程式碼如下,可以看出,和 bst_search 的程式碼很相似:
int insert_bst_node(BSTNode **p_root, int key)
{
BSTNode *p;
if (bst_search(*p_root, key, &p, NULL) == 0) { // 沒有查找到 key
BSTNode *new = create_bst_node(key); // 創建新結點
if (p == NULL) { // 空樹,新節點直接作為根結點
*p_root = new;
return 1;
}
if (key < p->data) { // 插入值小於 p 的值,插入到左子樹
p->left_child = new;
return 1;
}
if (key > p->data) { // 插入值大於 p 的值,插入到右子樹
p->right_child = new;
return 1;
}
}
return 0; // 插入失敗
}
那麼,創建操作用一個 for 循環就搞定了:
void create_bst(BSTNode **root, int *array, int length)
{
// 循環向空二叉查找樹中插入若干結點
for (int i = 0; i < length; i++) {
insert_bst_node(root, array[i]);
}
}
4. 刪除
至此,我們已經介紹過好幾種數據結構了,每種都涉及到增加(插入)和刪除操作。就像加法和減法一樣,插入和刪除操作可以看作是一對「反操作」。這意味著,它們在原理、程式碼上有相似之處,能夠做到觸類旁通。但這不是絕對了,必須具體問題結合具體環境進行具體分析。比如刪除二叉查找樹中的某個結點,可能會破壞二叉查找樹的結構,破壞其順序,所以我們就需要分情況討論。
【情況一】
待刪除的結點沒有孩子,即刪除葉子結點。這是最簡單的情況,因為刪除葉子不會破壞剩下的結構,也不會破壞剩下的結點的順序。
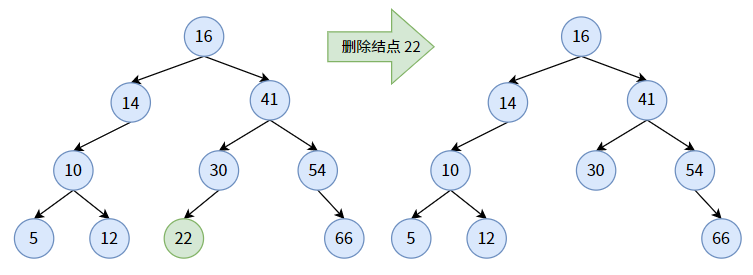
【情況二】
待刪除的結點只有左子樹或者右子樹。這種情況也好做,將其左子樹或右子樹移動到刪除結點處即可。由於二叉查找樹使用了鏈式結構,所以刪除操作的代價很小,只需要改變指針的指向。
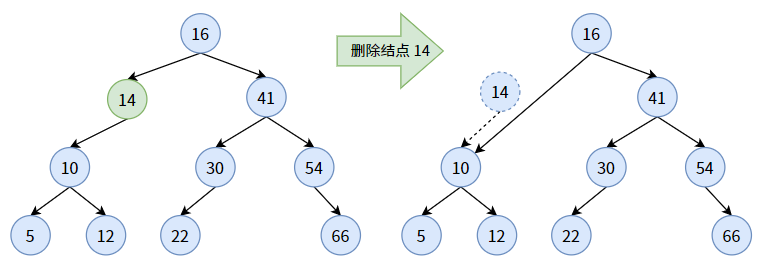
【情況三】
待刪除的結點既有左子樹又有右子樹。這種情況比較複雜,因為刪除結點後,剩下了該結點的左子樹和右子樹「在風中飄蕩」,一方面我們要維持樹結構,另一方面我們要維持二叉查找樹的結點大小順序,所以刪除結點會涉及到整個樹結構的調整,即將「剩下的」左子樹和右子樹重新插到樹結構中去。下面是過程:

從上圖過程就可以看出,這有點太過打動干戈了。我們先是改變 結點 16 的右孩子指針,然後刪除 結點 41,並將其右子樹「摘出來」,然後把剩下的右子樹中的所有結點重新插入到二叉查找樹中。這樣確實挺累人的。
不妨換一種思路:
我們將 32 賦值給結點 41,然後刪除結點 32,同樣能夠達到刪除結點 41 的效果。這種方式大大簡化了操作,不需要移動甚至改變樹的結構,代價較小。我稱這種方式為——狸貓換太子。
那麼為什麼偏偏是把結點 32 賦值給待刪除結點 41 呢?前面說過,二叉查找樹的中序遍歷是一個有序序列,這也是為什麼叫它二叉排序樹的原因。結點 32 剛好是結點 41 在中序遍歷序列下的直接前驅結點,所以,將 32 賦值給結點 41 後,並不會影響二叉查找樹的「左子樹值小於根結點,右子樹值大於根結點」的定義。
所以,如何找到待刪除結點在中序序列下的直接前驅是關鍵。
在中序遍歷序列下,根結點的直接前驅是其左子樹中最右最下的那個結點,如上例中結點 41 的直接前驅是結點 32.
到此,如何寫程式碼就很清晰了。
一、先遞歸地找到待刪除結點:
/**
* @description: 刪除目標值結點
* @param {BSTNode**} 二級指針,指向 指向樹根結點的指針 的指針
* @param {int} key 目標值
* @return {int} 刪除成功返回1;否則返回0
*/
int delete_bst_node(BSTNode **p_root, int key)
{
if (*p_root == NULL) {
return 0;
}
if (key == (*p_root)->data) { // 找到要刪除的目標值 key
rebuild_bst_after_delete(p_root);
} else if (key < (*p_root)->data) { // 目標值小於根結點,遞歸進入左子樹
return delete_bst_node(&(*p_root)->left_child, key);
} else { // 目標值大於右子樹,遞歸進入右子樹
return delete_bst_node(&(*p_root)->right_child, key);
}
}
可以看出,這段程式碼和刪除操作的程式碼沒有太大區別,本質仍是查找。
二、找到待刪除結點後,將結點刪除,然後調整以維持二叉查找樹的結構:
/**
* @description: 刪除某個結點後重新調整二叉查找樹
* @param {BSTNode**} p_node 指向待刪除結點的二級指針
* @return {int} 成功返回1;失敗返回0
*/
int rebuild_bst_after_delete(BSTNode **p_node)
{
BSTNode *prev, *tmp;
tmp = *p_node;
if ((*p_node)->left_child == NULL) { // 左子樹為空,重接右子樹
*p_node = (*p_node)->right_child;
free(tmp);
return 1;
}
if ((*p_node)->right_child == NULL) { // 右子樹為空,重接左子樹
*p_node = (*p_node)->left_child;
free(tmp);
return 1;
}
// 左右子樹均不為空
if ((*p_node)->left_child != NULL && (*p_node)->right_child != NULL) {
prev = (*p_node)->left_child;
while (prev->right_child != NULL) { // 找到待刪除結點的直接前驅
tmp = prev;
prev = prev->right_child;
}
(*p_node)->data = prev->data; // 賦值
if (tmp != *p_node) { // 待刪除結點有子孫結點
tmp->right_child = prev->left_child;
} else { // 待刪除結點只有兩個孩子結點,沒有子孫結點
tmp->left_child = prev->left_child;
}
free(prev);
return 1;
}
return 0;
}
以上就是二叉查找樹的基本原理及實現
如有錯誤,還請指正。
如果覺得寫的不錯,可以點個贊和關注。後續會有更多數據結構和演算法相關文章。
微信掃描下方二維碼,一起學習更多電腦基礎知識。



