Java容器 | 基於源碼分析List集合體系
- 2021 年 5 月 17 日
- 筆記
- ArrayList, JAVA, Java編程 核心基礎, linkedlist, list
一、容器之List集合
List集合體系應該是日常開發中最常用的API,而且通常是作為面試壓軸問題(JVM、集合、並發),集合這塊程式碼的整體設計也是融合很多編程思想,對於程式設計師來說具有很高的參考和借鑒價值。
基本要點
- 基礎:元素增查刪、容器資訊;
- 進階:存儲結構、容量管理;
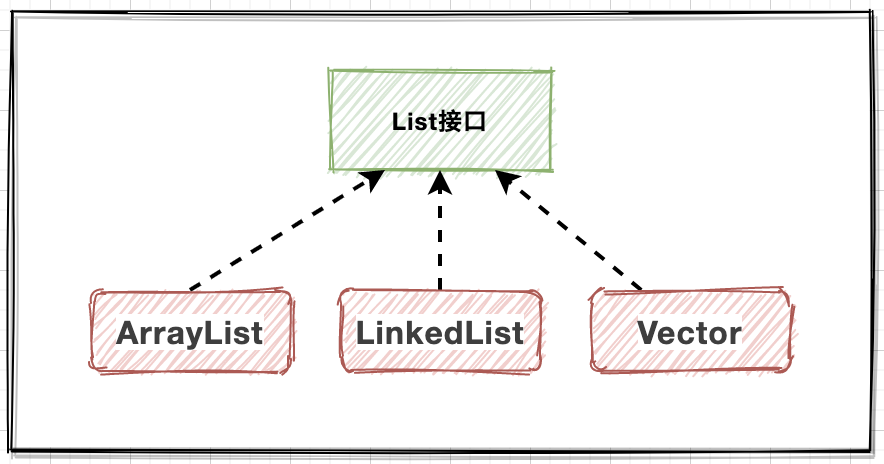
API體系
- ArrayList:維護數組實現,查詢快;
- Vector:維護數組實現,執行緒安全;
- LinkedList:維護鏈表實現,增刪快;
核心特性包括:初始化與載入,元素管理,自動擴容,數組和鏈表兩種數據結構。Vector底層基於ArrayList實現的執行緒安全操作,而ArrayList與LinkedList屬於非執行緒安全操作,自然效率相比Vector會高,這個是通過源碼閱讀可以發現的特點。
二、ArrayList詳解
1、數組特點
ArrayList就是集合體系中List介面的具體實現類,底層維護Object數組來進行裝載和管理數據:
private static final Object[] EMPTY_ELEMENTDATA = {};
提到數組結構,潛意識的就是基於元素對應的索引查詢,所以速度快,如果刪除元素,可能會導致大量元素移動,所以相對於LinkedList效率較低。
數組存儲的機制:
數組屬於是緊湊連續型存儲,通過下標索引可以隨機訪問並快速找到對應元素,因為有預先開闢記憶體空間的機制,所以相對節約存儲空間,如果數組一旦需要擴容,則重新開闢一塊更大的記憶體空間,再把數據全部複製過去,效率會非常的低下。
2、構造方法
這裡主要看兩個構造方法:
無參構造器:初始化ArrayList,聲明一個空數組。
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
有參構造器:傳入容量參數大於0,則設置數組的長度。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}
如果沒通過構造方法指定數組長度,則採用默認數組長度,在添加元素的操作中會設置數組容量。
private static final int DEFAULT_CAPACITY = 10;
3、裝載數據
通過上面的分析,可以知道數組是有容量限制的,但是ArrayList卻可以一直裝載元素,當然也是有邊界值的,只是通常不會裝載那麼多元素:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
超過這個限制會拋出記憶體溢出的錯誤。
裝載元素:會判斷容量是否足夠;
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
當容量不夠時,會進行擴容操作,這裡貼量化關鍵源碼:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
elementData = Arrays.copyOf(elementData, newCapacity);
}
機制:計算新容量(newCapacity=15),拷貝一個新數組,設置容量為newCapacity。
指定位置添加:這個方法很少使用到,同樣看兩行關鍵程式碼;
public void add(int index, E element) {
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index,elementData,index+1,size-index);
elementData[index] = element;
size++;
}
機制:判斷數組容量,然後就是很直接的一個數組拷貝操作,簡單來個圖解:
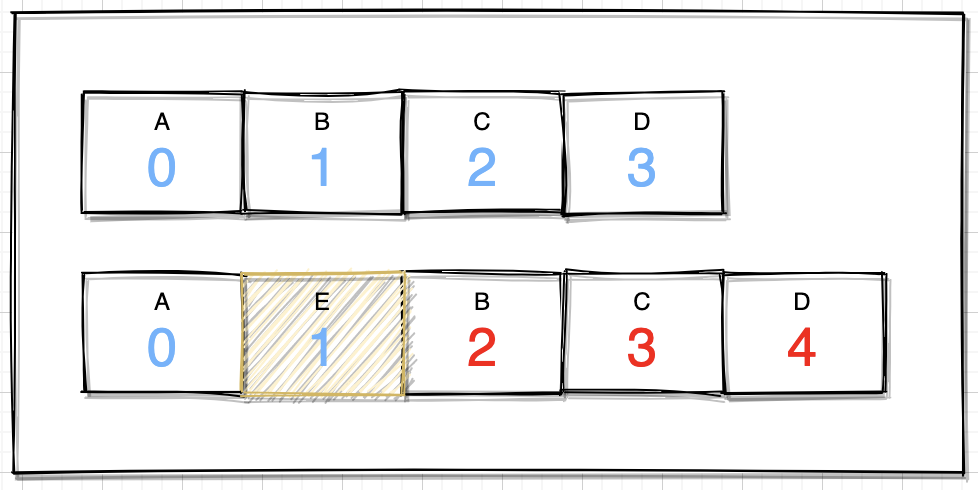
如上圖,假設在index=1位置放入元素E,按照如下過程運行:
- 獲取數組index到結束位置的長度;
- 拷貝到index+1的位置;
- 原來index位置,放入element元素;
這個過程就好比排隊,如果在首位插入一位,即後面的全部後退一位,效率自然低下,當然這裡也並不是絕對的,如果移動的數組長度夠小,或者一直在末尾添加,效率的影響自然就降低很多。
4、移除數據
上面看的數據裝載,那與之相反的邏輯再看一下,依舊看幾行關鍵源碼:
public E remove(int index) {
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0) {
System.arraycopy(elementData, index+1, elementData, index, numMoved);
}
elementData[--size] = null;
return oldValue;
}
機制:從邏輯上看,與添加元素的機制差不多,即把添加位置之後的元素拷貝到index開始的位置,這個邏輯在排隊中好比前面離開一位,後面的隊列整體都前進一位。
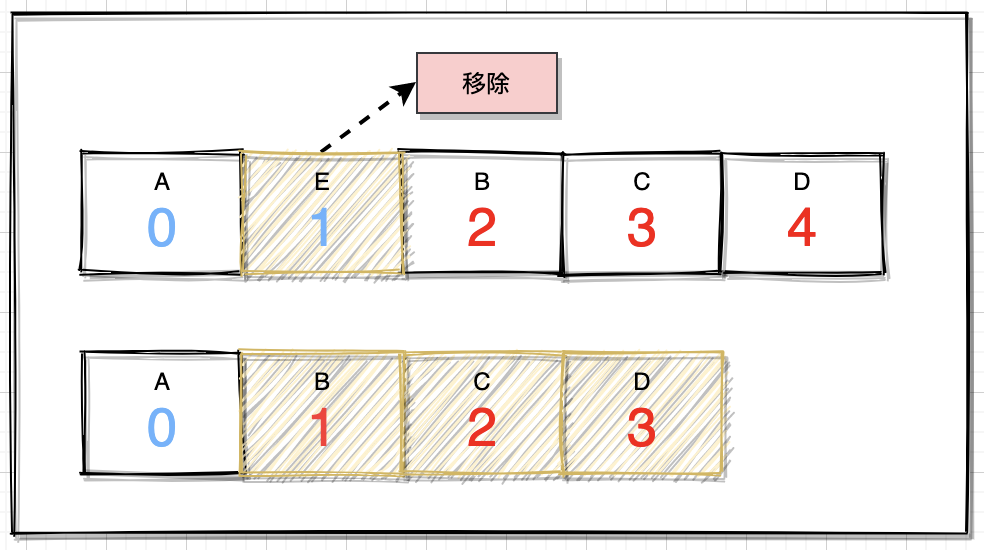
其效率問題也是一樣,如果移除集合的首位元素,後面所有元素都要移動,移除元素的位置越靠後,效率影響就相對降低。
5、容量與數量
在集合的源碼中,有兩個關鍵欄位需要明確一下:
- capacity:集合的容量,裝載能力;
- size:容器中裝載元素的個數;
通常容器大小獲取的是size,即裝載元素個數,不斷裝載元素觸發擴容機制,capacity容量才會改變。
三、LinkedList詳解
1、鏈表結構特點
鏈表結構存儲在物理單元上非連續、非順序,節點元素間的邏輯順序是通過鏈表中的指針鏈接次序實現的。鏈表由一系列節點組成,節點可以在運行時動態生成,節點包括兩個部分:一個是存儲數據元素的數據域,另一個是存儲下一個結點地址的指針域。
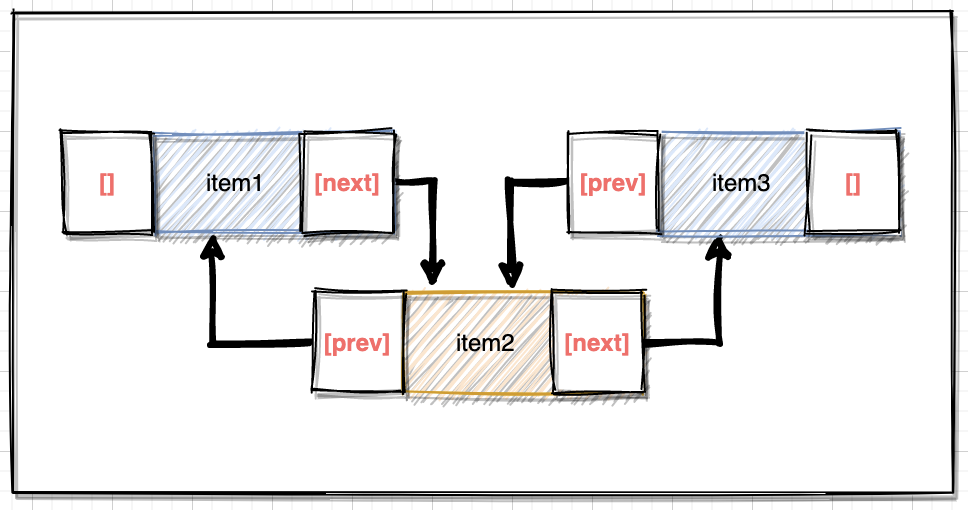
特點描述
- 物理存儲上是無序且不連續的;
- 鏈表是由多個節點以鏈式結構組成;
- 邏輯層面上看形成一個有序的鏈路結構;
- 首節點沒有指向上個節點的地址;
- 尾節點沒有指向下個節點的地址;
鏈表結構解決數組存儲需要預先知道元素個數的缺陷,可以充分利用記憶體空間,實現靈活的記憶體動態管理。
2、LinkedList結構
LinkedList底層數據存儲結構正是基於鏈表實現,首先看下節點的描述:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
在LinkedList中定義靜態類Node描述節點的結構:元素、前後指針。在LinkedList類中定義三個核心變數:
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
即大小,首位節點,關於這個三個變數的描述在源碼的注釋上已經寫的非常清楚了:
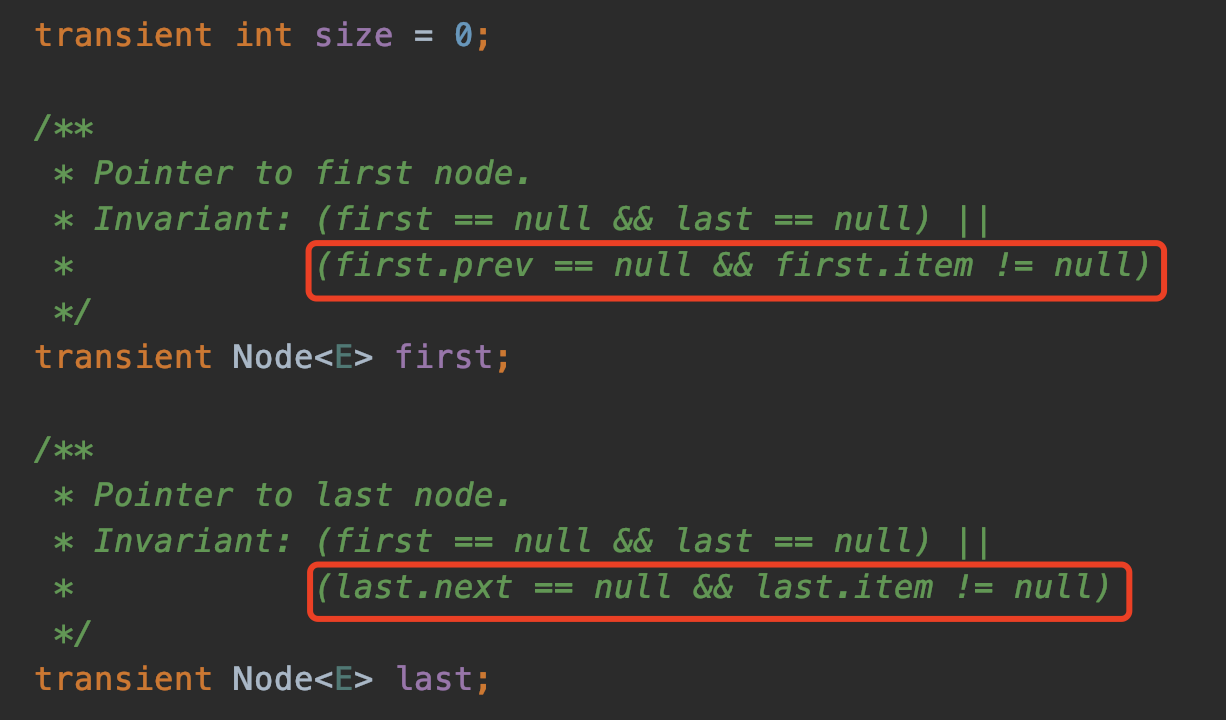
首節點上個節點為null,尾節點下個節點為null,並且item不為null。
3、元素管理
LinkedList一大特點即元素增加和刪除的效率高,根據鏈表的結構特點來看源碼。
添加元素
通過源碼可以看到,添加元素時實際調用的是該方法,把新添加的元素放在原鏈表最後一位:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
結合Node類的構造方法,實際的操作如下圖:
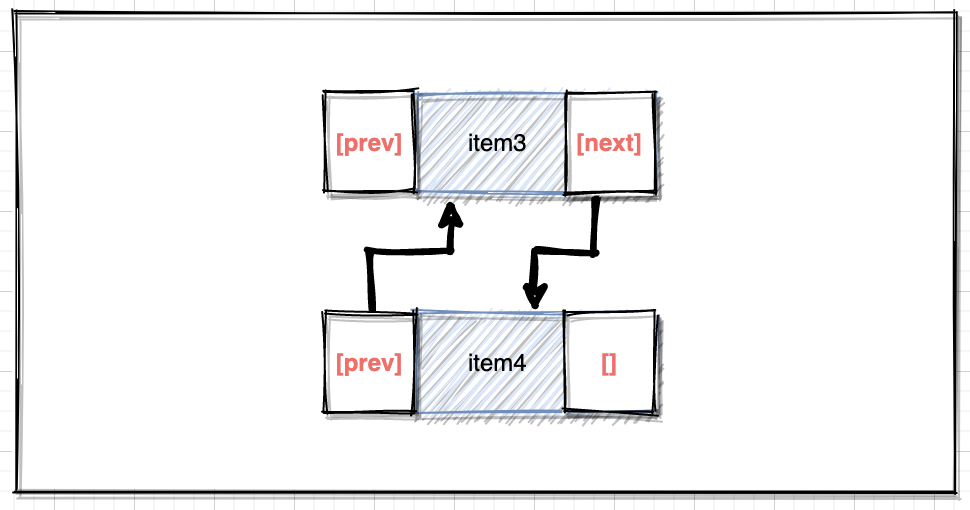
核心的邏輯即:新的尾節點和舊的尾節點構建指針關係,並處理首位節點變數。
刪除元素
刪除元素可以根據元素對象或者元素index刪除,最後核心都是執行unlink方法:
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
與添加元素核心邏輯相似,也是一個重新構建節點指針的過程:

- 兩個if判斷是否刪除的是首位節點;
- 刪除節點的上個節點的next指向刪除節點的next節點;
- 刪除節點的下個節點的prev指向刪除節點的prev節點;
通過增刪方法的源碼分析,可以看到LinkedList對元素的增刪並不會涉及大規模的元素移動,影響的節點非常少,效率自然相對ArrayList高很多。
4、查詢方法
基於鏈表結構存儲而非數組,對元素查詢的效率會有很大影響,先看源碼:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
這段源碼結合LinkedList結構看,真的是極具策略性:
- 首先是對index的合法性校驗;
- 然後判斷index在鏈表的上半段還是下半段;
- 如果在鏈表上半段:從first節點順序遍歷;
- 如果在鏈表下半段:從last節點倒序遍歷;
通過上面的源碼可以看到,查詢LinkedList中靠中間位置的元素,需要執行的遍歷的次數越多,效率也就越低,所以LinkedList相對更適合查詢首位元素。
四、源程式碼地址
GitHub·地址
//github.com/cicadasmile/java-base-parent
GitEE·地址
//gitee.com/cicadasmile/java-base-parent

閱讀標籤
【Java基礎】【設計模式】【結構與演算法】【Linux系統】【資料庫】
【分散式架構】【微服務】【大數據組件】【SpringBoot進階】【Spring&Boot基礎】


