語音降噪論文「A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier」的研讀
最近認真的研讀了這篇關於降噪的論文。它是一種利用混合模型降噪的方法,即既利用了生成模型(MoG高斯模型),也利用了判別模型(神經網路NN模型)。本文根據自己的理解對原理做了梳理。
論文是基於「Speech Enhancement Using a Mixture-Maximum Model」提出的MixMAX模型的。假設雜訊是加性雜訊,乾淨語音為x(t),雜訊為y(t),則在時域帶噪語音z(t)可以表示為z(t) = x(t) + y(t)。對z(t)做短時傅里葉變換(STFT)得到Z(k),再取對數譜(log-spectral)可得到Zk(k表示對數譜的第k維,即對數譜的第k個頻段(frequency bin)。若做STFT的樣本有L個,則對數譜的維數是 L/2 + 1)。相應的可得到Xk和Yk。MixMAX模型是指加噪後語音的每個頻段上的值Zk是對應的Xk和Yk中的大值,即 = MAX(Xk, Yk)。
語音x由音素組成,設定一個音素可用一個高斯表示。假設音素有m個,則乾淨語音的密度函數f(x)可以表示成下式:

fi(x)表示第i個音素的密度函數。由於x是用多維的對數譜表示的,且各維向量之間相互獨立,所以fi(x)可以表示成各維向量的密度函數fi,k(xk)的乘積。各維的密度函數表示如下式:
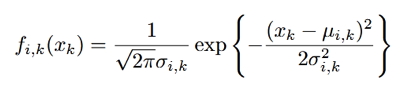
μi,k表示這一維上的均值,δi,k表示這一維上的方差。ci表示這個音素所佔的權重,權重的加權和要為1。
雜訊y只用一個高斯表示。同語音一樣,y也是用多維的對數譜表示的,y的密度函數可以表示如下:
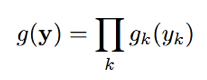
同樣gk(yk)表示如下:
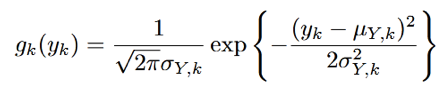
對於y每一維上的密度函數,其概率分布函數Gk(y)為:
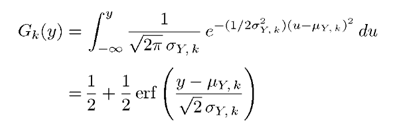
其中erf()為誤差函數,表示如下:

同理可求得乾淨語音中每個音素的每一維上的概率分布函數,如下式:
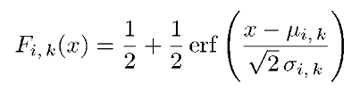
對於帶噪語音Z來說,當語音音素給定時(即i給定時)其對數譜的第k維分量Zk的分布函數Hi,k(z)可以通過下式求得:

上式就是求I = i時的條件概率。由於X和Y相互獨立,就變成了X和Y的第k維向量上的分布函數的乘積。對Zk的分布函數Hi,k(z)求導,就得到了的密度函數hi,k(z),表示如下:
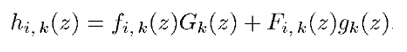
所以z的密度函數h(z)通過下式求得:
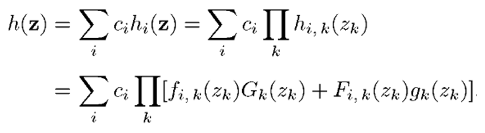
帶噪語音Z已知,我們的目標是要根據帶噪語音估計出乾淨語音X,即求出Z已知條件下的X的條件期望。基於MMSE估計,X的條件期望/估計表示如下:
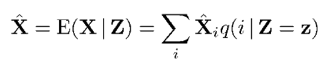
上式中X的條件期望又轉換成了每個音素條件期望的加權和。條件概率q(i | Z = z)可根據全概率公式得到,如下:
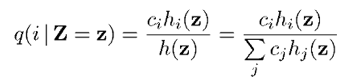
對於每個音素的條件期望,表示如下: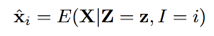 。對於每個音素的對數譜的每一維的條件期望,表示如下:
。對於每個音素的對數譜的每一維的條件期望,表示如下:
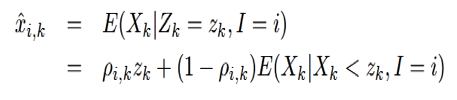
其中:

定義  ,可以推得x的對數譜的每一維上的估計如下式:
,可以推得x的對數譜的每一維上的估計如下式:

可以把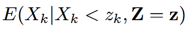 用基於譜減的
用基於譜減的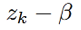 替代,其中β表示消噪程度。ρk可以看成是乾淨語音的概率。所以
替代,其中β表示消噪程度。ρk可以看成是乾淨語音的概率。所以
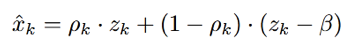
抵消掉正負項,可得:
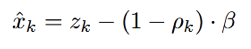
上式就是求消噪後的語音的對數譜的每維向量的數學表達式。zk可根據帶噪語音求得,β要tuning,知道ρk後xk的估計就可得到了。對得到的每維向量做反變換,可得到消噪後的時域的值。
上文已給出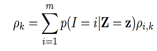 ,其中p(I = i | Z = z)表示在Z已知下是每個音素可能的概率,或者說一幀帶噪語音是每個音素的可能的概率,用pi表示。pi可以通過全概率公式求出,即
,其中p(I = i | Z = z)表示在Z已知下是每個音素可能的概率,或者說一幀帶噪語音是每個音素的可能的概率,用pi表示。pi可以通過全概率公式求出,即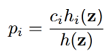 。但對每種語言來說,總的音素的個數是已知的(比如英語中有39個音素),這樣求每幀是某個音素的概率是一個典型的分類問題。神經網路(NN)處理分類問題是優於傳統方法的,所以可以用NN來訓練一個模型,處理時用這個模型來計算每幀屬於各個音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基於MOG模型的方法求出),就可得到ρk了(
。但對每種語言來說,總的音素的個數是已知的(比如英語中有39個音素),這樣求每幀是某個音素的概率是一個典型的分類問題。神經網路(NN)處理分類問題是優於傳統方法的,所以可以用NN來訓練一個模型,處理時用這個模型來計算每幀屬於各個音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基於MOG模型的方法求出),就可得到ρk了(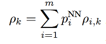 )。有了ρk,xk的估計就可求出了。可以看出NN模型的作用是替換計算pi的傳統方法,使計算pi更準確。
)。有了ρk,xk的估計就可求出了。可以看出NN模型的作用是替換計算pi的傳統方法,使計算pi更準確。
乾淨語音的高斯模型並不是用常規的EM演算法訓練得到的,而是基於一個已做好音素標註的語料庫得到的,論文作者用的是TIMIT庫。每幀跟一個音素一一對應,把屬於一個音素的所有幀歸為一類,算對數譜的各個向量的值,最後求均值和方差,得到這個向量的密度函數表達式,均值和方差的計算如下式:
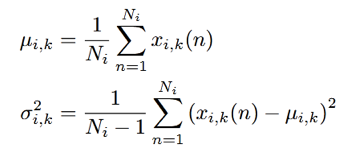
其中Ni表示屬於某一音素的幀的個數。一個音素的所有向量的密度表達式相乘,就得到了這個音素的密度函數表達式。再通過屬於這個音素的幀數占所有幀數的比例得到權重
(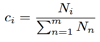 ), 這樣乾淨語音的高斯模型就建立好了。
), 這樣乾淨語音的高斯模型就建立好了。
對於非穩態雜訊來說,雜訊參數(μY,k和δY,k)最好能自適應。雜訊參數的初始值可以通過每句話的前250毫秒求得(基於前250毫秒都是雜訊的假設),求法同上面的乾淨語音的高斯模型,數學表達式如下:

雜訊參數的更新基於以下算式:

其中α為平滑係數,0 < α < 1,也需要tuning。雜訊參數(μY,k和δY,k)更新了,Gk(y)和gk(yk)就更新了,hi,k(z)也就更新了,從而ρi,k也更新了。
綜上, 基於生成-判別混合模型的降噪演算法如下:
1) 訓練階段
輸入:
根據已標註好音素的語料庫,得到對數譜向量z1,…zn(用於算MOG),MFCC向量v1,…,vn(用於NN訓練)和每幀相對應的音素標籤i1,…,in。
MoG 模型訓練:
根據對數譜向量z1,…,zn算乾淨語音的MOG
NN模型訓練:
根據(v1,i1),…(vn,…,in)訓練一個基於音素的多分類模型
2) 推理階段
輸入:
帶噪語音的對數譜向量以及MFCC向量
輸出:
消噪後的語音
計算步驟:



