Pytorch系列:(五)CNN
卷積
Conv2d
2D卷積函數和參數如下
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros'
)
參數說明:
in_channels: 輸入通道數,RGB圖片一般是3
out_channels: 輸出通道,也可以理解為kernel的數量
kernel_size:kernel的和寬設置
kernel 輸出尺寸計算:
\(\lfloor(n_h -k_h+p_h)/s_h+1\rfloor *\lfloor(n_w -k_w+p_w)/s_w+1\rfloor\)
stride:kernel移動的步伐
padding:在四周加入padding的數量,默認補0
dilation:
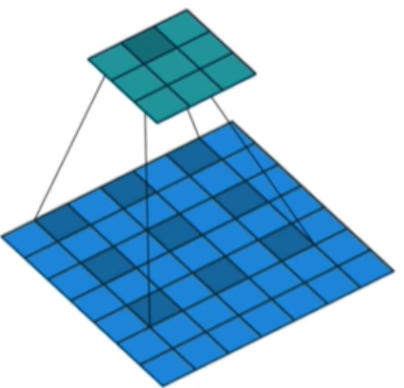
空洞就是計算的時候,對輸入層進行挖空操作,如下圖所示(圖片來源於網路)
group:
分組計算,輸出的feature map數量還是一樣,只不過,每一個輸出feature map 並不是用所有的輸入feature map 計算的,而是分組計算,這樣可以並行化並且減少計算成本
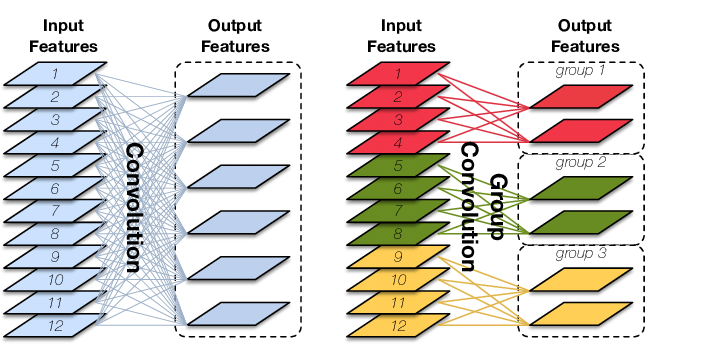
假設輸入為12個feature map , 輸出為6個通道,常規卷積Conv參數\(6*12*k^2\),但是假設goup=3,那麼參數為 3個 \(2*4*k^2\),這是因為計算的時候,輸入的feature map 和 計算的kernel 都要分成3組(如下圖所示,圖片來源網路)。

bias: 如果bias=True,添加偏置
Conv1d
一維卷積的特點是,卷積核有一個維度和特徵的維度是保持一致的,卷積核的另外一個維度是作用在sequenc length上面。
Conv1d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True
)
in_channels: – 輸入訊號的通道。即為詞向量的維度。2維RGB影像卷積中,為3, 一般用在序列模型中,例如一句話中的單詞表徵為300,那麼輸入就設置為300
out_channels: 輸出多少個channel
kernel_size:設置卷積尺寸,其中一個維度為in_channels,所以實際上卷積大小為kernel_size*in_channels
stride:卷積步長,作用在sequence len上面
padding:在序列兩邊補0
dilation:卷積核元素之間的間距,同上面conv2d
groups: 同上面conv2d
bias: 如果bias=True,添加偏置
尺寸計算方法
假設輸入尺寸為 (batch, sequence len, feature_len) 需要將維度轉換為( batch , feature_len, sequence len),卷積核的尺寸為(feature_len, kernel_size) , 輸出為( batch, kernel_size, Lout) ,其中Lout的計算方法如下:
\(L_{out} = \lfloor(feature\_len -k_h+p_h)/s_h+1\rfloor\)
轉置卷積
反卷積(轉置卷積)和正常卷積相反,具有尺寸擴張作用,也可以理解為帶參數學習的上取樣功能,主要可以用到GAN中的。
轉置卷積的操作如下圖所示:
相當於將被卷積的2*2 feature map進行padding,之後再做卷積操作。
設卷積核大小為k*k,輸入為方形矩陣
-
對輸入進行四邊補零,單邊補零的數量為k-1
-
將卷積核旋轉180°,在新的輸入上進行直接卷積 (上下翻轉,左右翻轉)
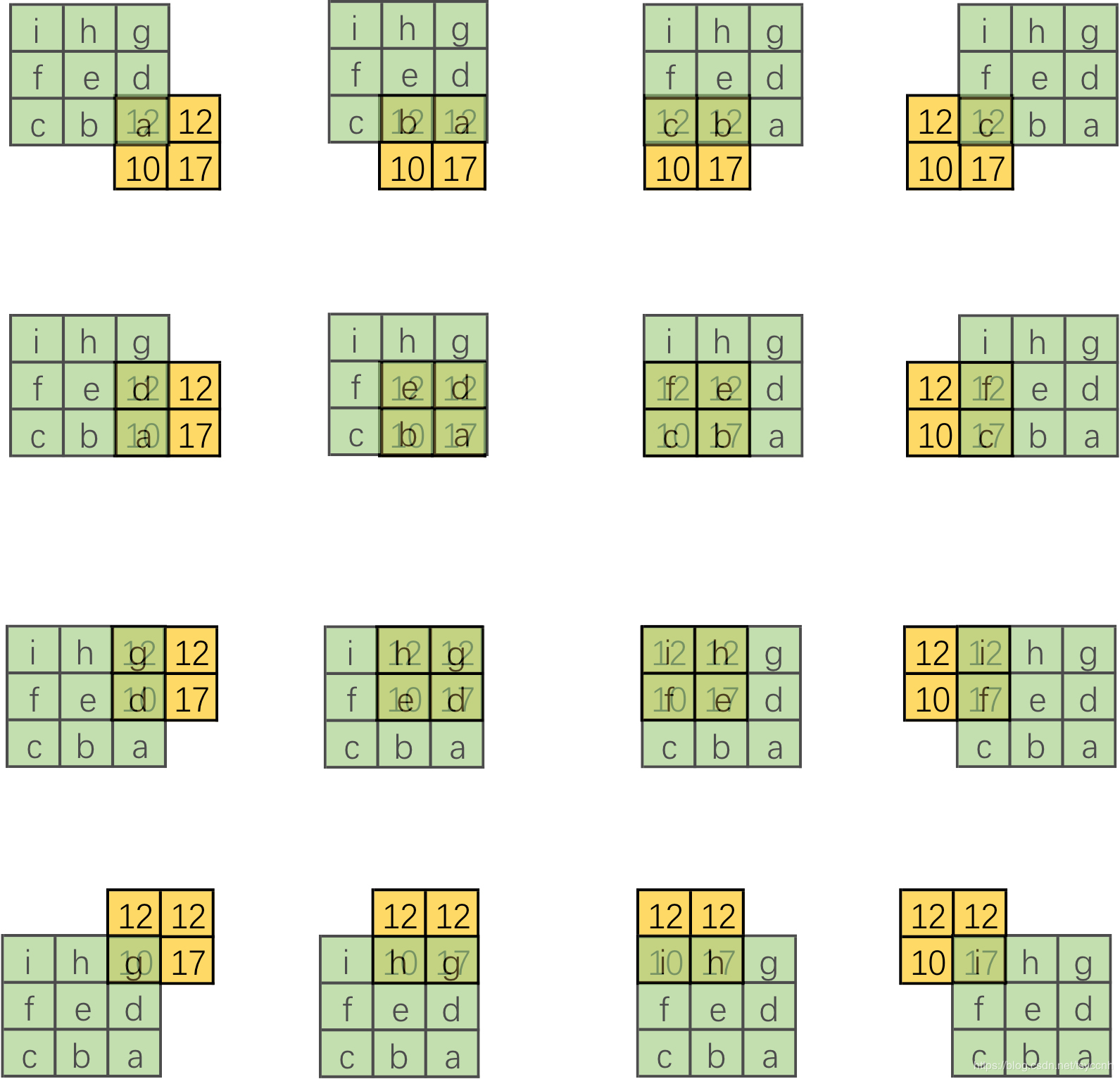

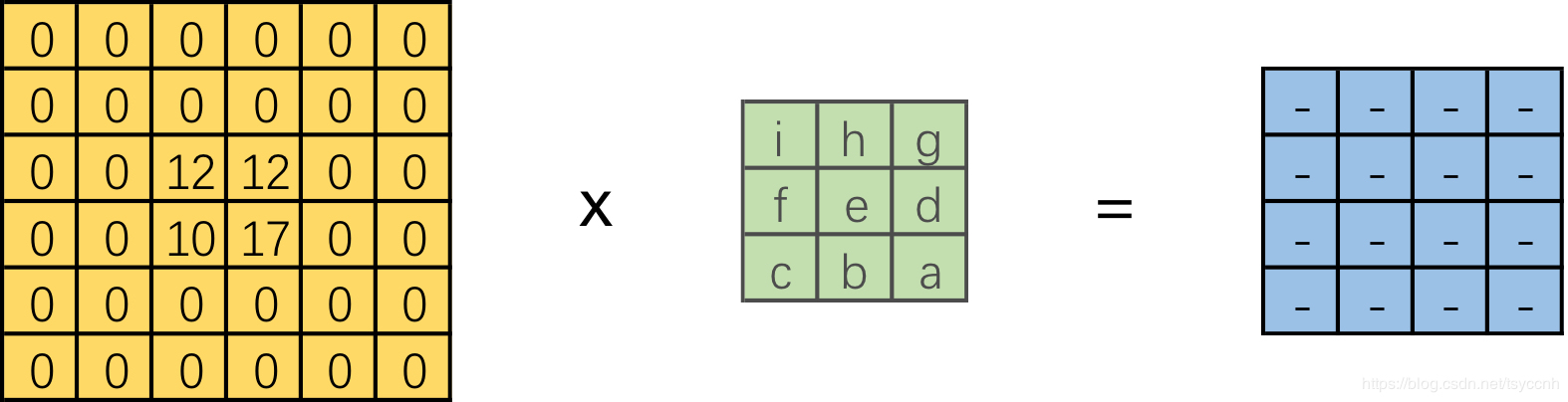
在pytorch中轉置卷積函數如下,其中參數和傳統卷積基本一致
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zeros'
)
尺寸計算方法
簡化版
\(out = (in\_{channel}-1) * stride + kernel\_size\)
完整版
\(out = (in\_{channel}-1) * stride -2*padding_size + dilation * (kernel\_size-1)+output\_padding +1\)
推薦一個細緻講解轉置卷積的帖子://blog.csdn.net/tsyccnh/article/details/87357447
池化函數
nn.MaxPool2d
nn.MaxPool2d(
kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False
)
其中,
return_indices: 可以返回池化的位置,主要用於自編碼其中池化上取樣(最大池化)
ceil_mode: 表示尺寸向上取整,主要用於kernel_size無法被長寬整除的時候。
其他參數和上述卷積參數含義一樣。
主要功能是進行特徵縮減,同時保留最大資訊,2*2的MaxPoold執行操作如下圖所示(來源於cs231n )
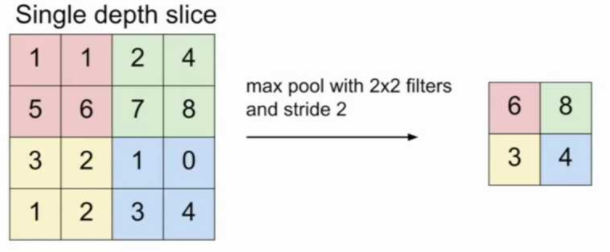
pytorch中的pooling函數,默認kernel size和stride是一樣的
pool2d = nn.MaxPool2d(3) # 這裡省略stride設置 pool2d(X)
# 也可以手動設置更詳細的:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
nn.AvgPool2d
nn.AvgPool2d(
kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None
)
其中:
count_include_pad:求平均值的時候,是否考慮將padding加入計算,divisor_override:可以設置分母,例如2*2均值就是除以4,但是我們可以設置其他值
其他參數和上述nn.MaxPool2d含義一樣
主要操作和nn.MaxPool2d一樣,不同的是,這裡做的是求平均操作。
nn.MaxUnpool2d
反池化操作,就是池化的反向操作,具體如下圖所示(圖片來源網路):
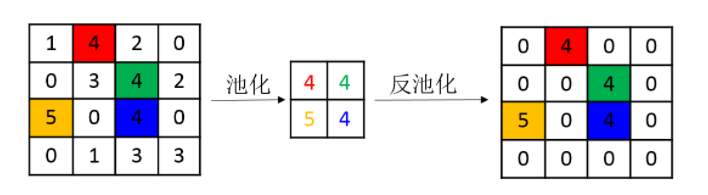
nn.MaxUnpool2d(
kernel_size,
stride=None,
padding=0
)
一個例子,首先使用MaxPool2d取樣,然後保留取樣位置,最後使用取樣位置indices來進行反池化操作。
img = torch.randn((28,28))
max_pool_l = nn.MaxPool2d((2,2),stride=(2,2),return_indices=True)
img_pool,indices = max_pool_l(img)
maxUpPool_l = nn.MaxUnpooled((2,2),stride=(2,2))
img_Up = maxUpPool_l(input_i , indices)


