高性能MySQL-索引
創建索引-高效索引
1.1 索引初體驗
1.1.1 介紹
索引是一種特殊的文件(InnoDB數據表上的索引是表空間的一個組成部分),它們包含著對數據表裡所有記錄的引用指針。
索引的作用是做數據的快速檢索,而快速檢索的實現的本質是數據結構。通過不同數據結構的選擇,實現各種數據快速檢索。在資料庫中,高效的查找演算法是非常重要的,因為資料庫中存儲了大量數據,一個高效的索引能節省巨大的時間。
1.1.2 索引類型
//www.cs.usfca.edu/~galles/visualization/Algorithms.html
推薦使用上面的網站來可視化查看各種數據結構
B-Tree索引
儘管名稱為B-Tree索引,但事實上,其不同引擎對其內部實現結構還是會不一樣,Inno DB使用的是B+Tree這種結構來存儲索引
注意: InnoDB 的數據文件本身就是索引文件 即
表數據文件本身就是按 B+Tree 組織的一個索引結構,這棵樹的葉點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此 InnoDB 表數據文件本身就是主索引。
對於MyISAM引擎,其採用了非聚集索引的方式來實現
即數據和索引落在不同的兩個文件上。MyISAM 在建表時以主鍵作為 KEY 來建立主索引 B+樹,非葉子結點只存儲下一節點的指針,樹的葉子節點存的是對應數據的物理地址。我們拿到這個物理地址後,就可以到 MyISAM 數據文件中直接定位到具體的數據記錄了。
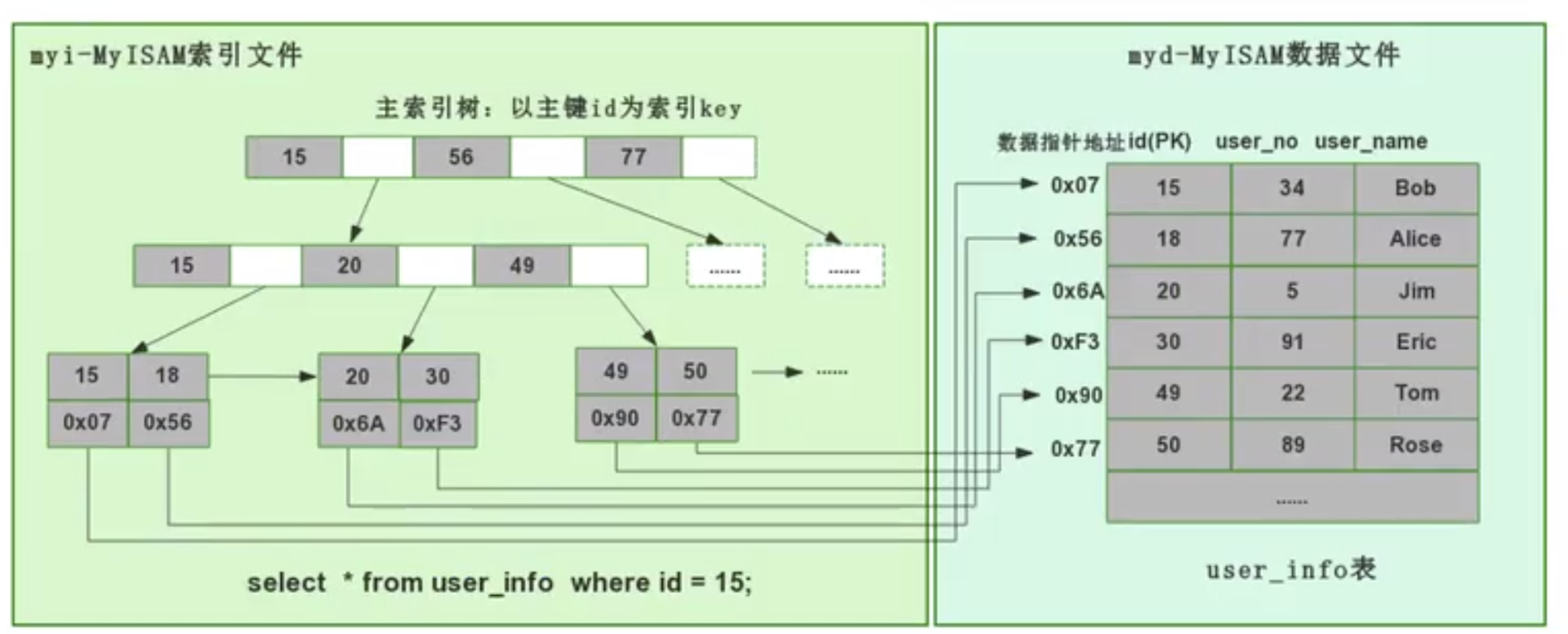
對於InnoDB引擎,其使用聚集索引的方式來建表
即數據和索引都存儲在同一個文件 ,對於InnoDB使用的B+Tree結構,其非葉子節點是不存儲數據的,只存儲索引,所有的數據都存儲在葉子節點頁,並且葉子節點存儲的是主鍵ID對應的數據,這也是為什麼Mysql在建表時要求必須指定主鍵的原因。由於數據真正的排序方式只能有一種,所以在每張表中只能存在著一個以主鍵為索引的聚集索引。 因此上面我們才說了InnoDB的數據文件就是索引文件

注意:InnoDB只在主鍵索引樹的葉子節點存儲了具體數據,但是其他索引樹卻不存具體數據,而要先找到主鍵,再在主鍵索引樹找到對應的數據。 別問,問就是節省空間,拿時間換空間。這也證明了選擇合適的主鍵的重要性。
B+Tree索引查詢類型:
-
全值匹配
和索引中的所有列進行匹配,例如key(A,B,C),匹配(A,B,C)
-
匹配最左前綴
例如key(A,B,C),可以匹配(A) (A,B) (A,B,C)
-
匹配列前綴
例如數據changtong,加上索引後可以匹配(c*),這也就是為什麼我們對某一添加了索引的列使用模糊查詢時like a% 就會使用索引,如果是%a就只能夠完全檢索了
-
匹配範圍值
B-tree索引是順序存儲數據的,因此能夠使用索引進行範圍匹配
-
精確匹配某一列並範圍匹配另外一列
例如key(A,B)可以匹配(A,B*)
-
只訪問索引的查詢
這裡主要是覆蓋索引,只訪問索引,不訪問數據行
Hash索引
顧名思義,使用哈希表實現,這也就意味著其只有對精確匹配才有效,這個實現有點像HashMap,根據數據的Hash值確定位置,這裡索引只存哈希值和行指針,不存數據,由於Hash演算法的特點,也無法排序
InnoDB一般不使用Hash索引,但是其有一項功能叫「自適應哈希索引」,當它發現某些數據訪問非常頻繁,可能會基於B-Tree的基礎上再創建一個Hash索引,該過程自發且不可控,可以選擇關閉。
綜上所述,對於使用InnoDB引擎的我們來說,Hash索引了解一下就好了,不過這也給我們提供了一個思路,例如我們存儲網路鏈接這樣的無序長字元串,是不是可以使用上Hash演算法?我們可以新建一列url_hash,存放該鏈接對應的Hash值,然後我們對該Hash值建立索引,就能得到更好的查詢體驗了,在查詢時使用以下查詢語句即可
select id from url where url="//changtong1819.top"
and url_hash = CR32("//changtong1819.top")
當然,缺點是我們可能需要使用觸發器等工具維護我們的Hash值
空間索引
MyISAM支援該索引
全文索引
全文索引是一種特殊類型的索引,它查找的是文本中的關鍵詞,而不是簡單的where
1.2 索引的優點
索引可以讓伺服器快速地定位到表的指定位置。但是這並不是索引的唯一作用,到目前為止可以看到,根據創建索引的數據結構不同,索引也有一些其他的附加作用。
最常見的B-Tree索引,由於其按照順序存儲數據,所以 MySQL可以用來做ORDER BY和GROUPBY操作。因為數據是有序的,所以B-Tree也就會將相關的列值都存儲在一起。
最後,因為索引中存儲了實際的列值,所以某些查詢只使用索引就能夠完成全部查詢。據此特性,總結下來索引有如下三個優點:
- 索引大大減少了伺服器需要掃描的數據量。
- 索引可以幫助伺服器避免排序和臨時表。
- 索引可以將隨機IO變為順序IO。
注意:索引並非總是好的解決方案
只有當索引幫助存儲引擎快速查找到記錄帶來的好處大於其帶來的額外工作時,索引才是有效的。對於非常小的表,大部分情況下簡單的全表掃描更高效。對於中到大型的表,索引就非常有效。但對於特大型的表,建立和使用索引的代價將隨之增長。這種情況下,則需要一種技術可以直接區分出查詢需要的一組數據,而不是一條記錄一條記錄地匹配。例如可以使用分區技術。
1.3 高性能索引
1.3.1 獨立的列
如果查詢的列不是獨立的,則不會使用索引。獨立的列意味著索引列不能是表達式、函數的一部分
例如:
select id from user where id + 1 = 10
儘管上面的寫法看著很智障,但貌似我以前好像寫過這樣的查詢語句,靠!總而言之,能在業務層簡化就盡量簡化,直接寫id = 9就會使用索引了。
1.3.2 前綴索引和索引選擇性
當我們需要索引長字元串怎麼辦?這會讓索引變得大且慢,前面提到了仿Hash索引是一個思路,也有其它類似方法,總而言之就是簡化索引欄位長度
我們如果存儲了一列全是類似”changtong1819hahahahahahahahhhehehehehhehehexixixiixixii “這樣的長數據列的話,我們可以增加一列,這一列只保存上面數據列中的前10個字元,對該列添加索引,在查詢時匹配這兩列能夠極大的提高查詢速度。
那麼問題來了,具體截取多少個字元呢?什麼是索引選擇性?
對於我們上面的例子來說,截取太長,匹配效果好,但是既然這個索引還是長,那我要它幹嘛?截取太短的話,就會導致我們該索引的相同值太多了,我們知道B-Tree好就好在其實順序存儲的,當相同值越多,就導致索引效果會越差,即選擇性差。因此,我們要權衡兩種效果來選擇合適的長度,這肯定是和實際資料庫的存放數據相關了。
1.3.3 多列索引
我們知道,每創建一個索引欄位就會產生一個B-Tree來存儲對應的索引,那麼我們分別對兩個欄位創建了索引會有什麼效果?我們該如何查詢呢?
MySQL引入了索引合併策略,在一定程度上可以幫助我們通過多個單列索引來定位到指定的數據,當然,儘管有該策略,我們應該也能想到其效率也不會有多高。這是MySQL對我們的查詢操作進行的優化,但是我們要盡量創建合適的索引。
1.3.4 索引列順序
我們遇到的最容易引起困惑的問題就是索引列的順序。正確的順序有利於使用該索引的查詢,並且同時需要考慮如何更好地滿足排序和分組的需要。當然,這一切都是在於我們使用了B-Tree這種順序存儲結構的情況下
通常情況下我們將選擇性最高的列放在索引的最前列,這有利於我們的where語句。但考慮到其他情況的話,這樣做就可能不是最好的選擇了。我們使用where語句時,要充分考慮到聯合索引的執行與否。
1.3.5 聚簇索引
聚簇索引並不是一種索引類型,而是一種數據存儲方式,前面提到過了,InnoDB的聚簇索引即是在一個結構中保存了索引與數據行。
如果沒有定義主鍵,InnoDB會選擇一個唯一的非空索引代替。如果沒有這樣的索引,InnoDB會隱式定義一個主鍵來作為聚簇索引。InnoDB 只聚集在同一個頁面中的記錄。包含相鄰鍵值的頁面可能會相距甚遠。
注意:InnoDB只會對主鍵索引才回使用聚簇索引這一存儲方式,同時InnoDB表數據的保存形式其實就是對主鍵的聚簇索引。即對於InnoDB,聚簇索引就是表。
我們平時手動創建的索引稱為二級索引,而通過二級索引查找行,存儲引擎需要找到二級索引的葉子節點獲得對應的主鍵值(二級索引沒有行數據),然後根據這個值去聚簇索引中查找到對應的行。對於InnoDB,自適應哈希索引能夠減少這樣的重複工作。
在InnoDB表中按主鍵順序插入行
如果正在使用InnoDB表並且沒有什麼數據需要聚集,那麼可以定義一個代理鍵(surrogate key)作為主鍵,這種主鍵的數據應該和應用無關,最簡單的方法是使用AUTO_INCREMENT自增列。這樣可以保證數據行是按順序寫入,對於根據主鍵做關聯操作的性能也會更好。
最好避免隨機的(不連續且值的分布範圍非常大)聚簇索引,特別是對於IО密集型的應用。例如,從性能的角度考慮,使用UUID來作為聚簇索引則會很糟糕:它使得聚簇索引的插入變得完全隨機,這是最壞的情況,使得數據沒有任何聚集特性。
使用InnoDB時應該儘可能地按主鍵順序插入數據,並且儘可能地使用單調增加的聚簇鍵的值來插入新行。
1.3.6 覆蓋索引
如果索引的葉子節點中已經包含要查詢的數據,那麼就不需要再回表查詢
如果一個索引包含(或者說覆蓋)所有需要查詢的欄位的值,我們就稱之為「覆蓋索引」。
MySQL不能在索引中執行LIKE操作。這是底層存儲引擎API的限制,MySQL 5.5和更早的版本中只允許在索引中做簡單比較操作(例如等於、不等於以及大於)。
MySQL 能在索引中做最左前綴匹配的LIKE比較,因為該操作可以轉換為簡單的比較操作,但是如果是通配符開頭的LIKE查詢,存儲引擎就無法做比較匹配。這種情況下,MySQL伺服器只能提取數據行的值而不是索引值來做比較。
1.3.7 使用索引掃描
MySQL有兩種方式可以生成有序的結果:通過排序操作;或者按索引順序掃描。
掃描索引本身是很快的,因為只需要從一條索引記錄移動到緊接著的下一條記錄。但如果索引不能覆蓋查詢所需的全部列,那就不得不每掃描一條索引記錄就都回表查詢一次對應的行。這基本上都是隨機I/o,因此按索引順序讀取數據的速度通常要比順序地全表掃描慢,尤其是在IO密集型的工作負載時。
MySQL可以使用同一個索引既滿足排序,又用於查找行。因此,如果可能,設計索引時應該儘可能地同時滿足這兩種任務,這樣是最好的。
注意:只有當索引的列順序和ORDER BY子句的順序完全一致,並且所有列的排序方向(倒序或正序)都一樣時,MySQL才能夠使用索引來對結果做排序。如果查詢需要關聯多張表,則只有當ORDER BY子句引用的欄位全部為第一個表時,才能使用索引做排序。ORDER BY子句和查找型查詢的限制是一樣的:需要滿足索引的最左前綴的要求。
1.3.8 壓縮索引
MyISAM使用前綴壓縮來減少索引的大小,從而讓更多的索引可以放入記憶體中,這在某些情況下能極大地提高性能。默認只壓縮字元串,但通過參數設置也可以對整數做壓縮。
1.3.9 冗餘和重複索引
MySQL允許在相同列上創建多個索引,無論是有意的還是無意的。MySQL需要單獨維護重複的索引,並且優化器在優化查詢的時候也需要逐個地進行考慮,這會影響性能。
重複索引是指在相同的列上按照相同的順序創建的相同類型的索引。應該避免這樣創建重複索引,發現以後也應該立即移除。
通常情況下,我們不會寫出兩個KEY(A)這樣的索引。但是像主鍵、外鍵MySQL會自動創建索引,我們再去添加索引就會導致重複了。至於冗餘索引,我們創建了KEY(A,B)之後在創建KEY(A)就很明顯冗餘了。
1.3.10 未使用的索引
有些索引可能從未被使用,可以用工具查看,然後刪除
1.3.11 索引和鎖
索引可以讓查詢鎖定更少的行。如果你的查詢從不訪問那些不需要的行,那麼就會鎖定更少的行,從兩個方面來看這對性能都有好處。首先,雖然InnoDB的行鎖效率很高,記憶體使用也很少,但是鎖定行的時候仍然會帶來額外開銷﹔其次,鎖定超過需要的行會增加鎖爭用並減少並發性。
MySQL 5.1之後,InnoDB可以在服務端過濾掉行之後就釋放鎖,此前版本需要事務提交後才釋放鎖
如果不能使用索引查找和鎖定行的話,MySQL會做全表掃描並鎖住所有的行,而不管是不是需要。
InnoDB在二級索引上使用共享(讀)鎖,但訪問主鍵索引需要排他(寫)鎖。
1.4 合理使用索引
1.4.1 支援多種過濾條件
創建索引時我們需要考慮哪些列擁有很多不同的取值,哪些列在WHERE子句中出現得最頻繁。在有更多不同值的列上創建索引的選擇性會更好。一般來說這樣做都是對的,因為可以讓MySQL更有效地過濾掉不需要的行。
像性別這樣的選擇性就兩個的欄位,單獨添加個索引毫無必要,索引的最主要目的就是快速查找、定位數據。而性別這樣的數據在表中的定位性比較差,即便加上索引,優化器也是會認為此索引使用的成本過高,而不會使用索引。
但並不是性別就一定不能成為索引欄位,如果該表經常出現性別和其他欄位往往同時出現在where後面,那麼你可以將性別和其他欄位作為聯合索引。即能夠幫助我們多過濾一些數據行還是好的。
1.4.2 避免多範圍條件
前面我們提到了,InnoDB使用B+Tree作為索引存儲結構,而這是一種順序存儲結構,因此InnoDB是支援索引的範圍匹配的,但是這並不意味著我們可以隨意在where後面添加多個範圍匹配。
不過我嘗試了幾種多範圍條件的查詢,發現都使用了索引
1.4.3 優化排序
對於那些選擇性非常低的列,可以增加一些特殊的索引來做排序。例如,可以創建(sex,x)索引用於對x欄位和性別欄位的查詢。


