乾貨,使用布隆過濾器實現高效快取!
前言
本文主要描述,使用布隆過濾實現高效快取。文中採用數組做為快取,如果需要高並發命中,則需將文中的數組換成Redis資料庫。
布隆過濾
布隆快取的創建過程如下:
1,先定義快取bit數組(BitArray),數組的長度就是快取數據的最大數量。
2,然後將字元串通過哈希運算,求出它的HashCode。
3,然後將HashCode作為偽隨機數生成器(Random)的種子,生成一個小於最大數量的正數x。
4,然後將這x作為快取數組的索引,將數組[x]的值設置為true。
布隆過濾
程式碼實現
首先建立WinForm項目BloomTest。
然後編寫布隆過濾器,程式碼如下:
public class BloomFilter { //布隆快取數組 public BitArray BloomCache; //布隆快取數組的長度 public Int64 BloomCacheLength { get; } public Int64 HashCount { get; } /// <summary> /// /// </summary> /// <param name="bloomCacheLength">布隆快取數組的長度,默認20000</param> /// <param name="hashCount">hash運算次數,默認3</param> public BloomFilter(int bloomCacheLength = 20000, int hashCount = 3) { BloomCache = new BitArray(bloomCacheLength); BloomCacheLength = bloomCacheLength; HashCount = hashCount; } public void Add(string str) { var hashCode =str.GetHashCode(); Random random = new Random(hashCode); for (int i = 0; i < HashCount; i++) { var x = random.Next((int)(BloomCacheLength - 1)); BloomCache[x] = true; } } public bool IsExist(string str) { var hashCode = str.GetHashCode(); Random random = new Random(hashCode); for (int i = 0; i < HashCount; i++) { if (!BloomCache[random.Next((int)(BloomCacheLength - 1))]) { return false; } } return true; } //錯誤率查看 public double GetFalsePositiveProbability(double setSize) { // (1 - e^(-k * n / m)) ^ k return Math.Pow((1 - Math.Exp(-HashCount * setSize / BloomCacheLength)), HashCount); } //計算基於布隆過濾器散列的最佳數量,即hashCount的最佳值 public int OptimalNumberOfHashes(int setSize) { return (int)Math.Ceiling((BloomCacheLength / setSize) * Math.Log(2.0)); } }
然後編寫布隆過濾器的使用程式碼,如下:
public partial class Form1 : Form { BloomFilter bloom = new BloomFilter(20000, 3); int setSize = 2000; public Form1() { InitializeComponent(); //生成布隆快取數組 for (int i = 0; i < setSize; i++) { bloom.Add("kiba" + i); } } private void btnSearch_Click(object sender, EventArgs e) { Stopwatch sw = new Stopwatch(); sw.Start(); string con = tbCon.Text.Trim(); var ret = bloom.IsExist(con); sw.Stop(); lblRet.Text = $@"結果:{ret}{Environment.NewLine} 耗時:{sw.ElapsedTicks}{Environment.NewLine} 錯誤概率:{bloom.GetFalsePositiveProbability(setSize)}{Environment.NewLine} 最佳數量:{bloom.OptimalNumberOfHashes(setSize)}"; } }
測試結果
運行項目,點擊查詢數據。
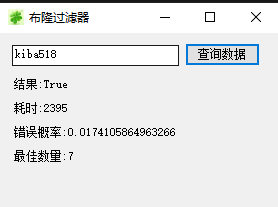
如上圖所示,我們成功命中了,如果在項目中,命中了就可以查詢真實快取了。
錯誤概率
布隆快取存在命中錯誤,即如果兩個數據的哈希運算後值相同,那麼久會存在命中失敗的問題。
錯誤概率可以通過哈希運算次數和布隆快取數組長度和插入數據數量計算出來。
最佳數量
布隆快取建議我們多做幾次哈希運算,即多存幾個快取索引,文中默認創建3個。
我們程式碼中,向布隆快取數組中插入了2000個數據,通過計算得出,最佳的哈希運算次數為7,即當插入數量為2000,布隆快取數組長度為20000時,HashCount的最優值為7。
應用場景
布隆快取有很多場景可以應用,比如重複URL檢測,黑名單驗證,垃圾郵件過濾等等。
舉個例子,爬蟲在爬取網站之前,會先通過布隆過濾計算出該Url是否已經爬取過,再確定是否發起Http請求。
關於快取穿透、快取擊穿、快取雪崩
快取穿透
快取穿透是指快取和資料庫中都沒有的數據,這時用戶不斷的發起這樣的請求,會對資料庫和快取造成比較大的壓力。
解決方案:增加更多,更有效的數據校驗,讓這些請求在進入查詢前被攔截。將快取和資料庫中都沒有的數據寫入快取,並設置一個較短的有效期,用來防止該請求多次進入到資料庫。
快取擊穿
快取擊穿是指快取中的數據正好到期,然後又突然出現大量該數據的訪問。導致大量請求直接發送到資料庫。
解決方案:對數據進行熱點標記,然後對熱點數據進行特殊有效期設置。對普通數據進行有效期延長處理,比如被請求過一次,加長固定時間的有效期。
快取雪崩
快取雪崩與快取擊穿的意思類似,區別在於,快取擊穿指的是只有一條數據直接請求資料庫,而雪崩指的是很多這樣的數據直接請求資料庫。
解決方案:快取資料庫分散式部署。
結語
布隆快取因為存在誤判,所以不能用於百分之百定位數據的場景,但如果該場景可以容錯,那布隆快取將大大提升性能。
—————————————————————————————————-
到此,到此布隆過濾就已經介紹完了。
程式碼已經傳到Github上了,歡迎大家下載。
Github地址: //github.com/kiba518/BloomFilter_Kiba
—————————————————————————————————-
註:此文章為原創,任何形式的轉載都請聯繫作者獲得授權並註明出處!
若您覺得這篇文章還不錯,請點擊下方的【推薦】,非常感謝!
//www.cnblogs.com/kiba/p/14767430.html