HBASE-使用問題-split region
問題描述:
HBASE表的管理以REGION分區為核心,通常面臨如下幾個問題:
1) 數據如何存儲到指定的region分區,即rowkey設計,region splitkey設計
2)設計的splitkey是否可以解決熱點問題
3)設計的splitkey是否可以解決均勻分布,避免自動分裂的問題
4)region的創建和刪除問題
對於1)問題 比如:對於按照時間存儲的數據,region splitkey 可以是2019,2020 ; 201901,201902;20190101 等等類似方式,可以把指定時間段的數據存儲到響應splitkey的region中,達到按照時間存儲的效果。
對於2)問題,同一天的數據,可以通過對rowkey或者數據中的一個或多個欄位取hash方式,解決熱點問題;如果數據存在重複入庫,則需要保證用於hash的欄位值在兩次入庫時不能變更,否則會存在兩個rowkey數據 即splitkey中包含hash值部分,同樣要求rowkey包含hash值
對於3)問題,需要考慮數據量和region分區的關係,比如一天有150G的數據量,hbase 單個region建議10~20G大小,設計時則需要考慮一天需要劃分多少的region,才能避免region在數據入庫時發生頻繁split,會影響hbase服務(split會涉及數據移動,數據通過網路傳輸和落盤,影響網路和磁碟IO)
對於4)問題,未來的region是否應該提前創建,如何創建?集群存儲是否足夠,歷史的region是否下線或者刪除?
此篇文章是在提前創建region分區時遇到的問題
一般的設計方法是,在hbase 尾部region切分新的多個region,用於新的數據存儲,通常使用定時任務,提前創建
切分方式是通過調用HBASE split region方法,region尾部splitkey為 20210600 ~「」 需要切分的splitkey為20210601,20210602,20210603,20210700
採用的方法是: 先20210601切分,得到如下兩個region: 20210600 ~20210601, 20210601~「」 然後等待 20210601~「」 此region上線,再使用20210602切分
以此類推
但是在實際項目中發現,只切分了一個region就任務結束了,程式本身在等待新切分region上線時,可以等待1s~60秒中,發現此問題後,可以配置等待時長,
但是實際效果不好,仍會存在上述問題
1) 觀察Hbase regionServer端日誌,發現如下日誌,debug日誌顯示待切分region對應的存儲文件正在被引用使用,導致region split請求切分失敗

2)分析Hbase 源碼:

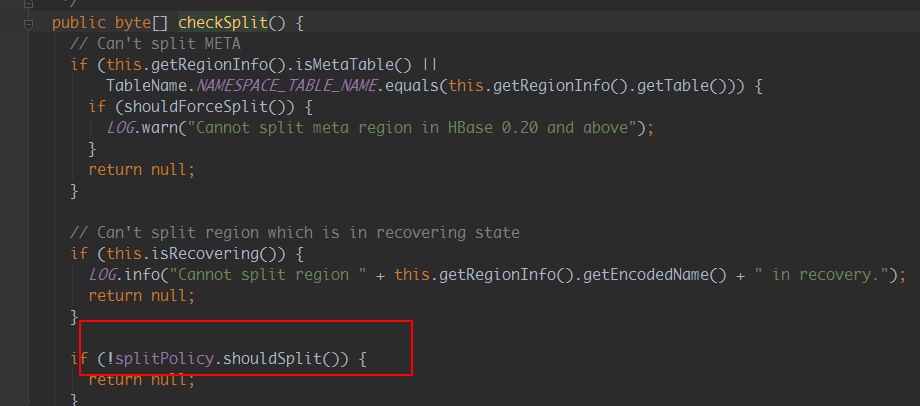
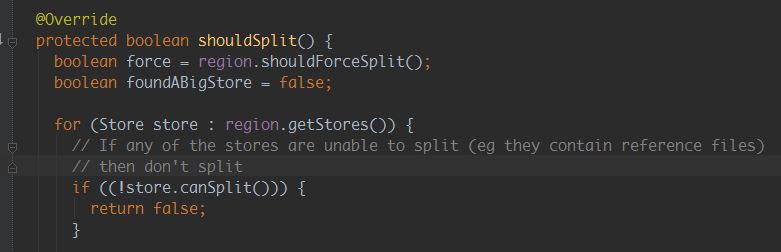
原因分析:hbase split請求調用的為非同步請求,通過源碼並結合hbase regionserver日誌可以看出,hbase接收到split請求後,
如果發現需要被切分的region有引用文件時,就返回失敗;因為時非同步請求,所以程式等待新切分region上線不可行
即Hbase接收到請求後,由於存儲文件被引用使用,導致請求失敗,region未切分,索引新切分region不會上線,從而失敗
修改後方法邏輯為:切分region,等待一段時間上線,不上線則再次切分region,以此多次,仍不成功,則等待下次定時任務觸發切分
額外說明:
實際項目中被切分region如果裡面有大量數據,切分速度會很快,但是對切分後的region再次切分時,文件引用有較長時間不會消失,無法再次切分
因此實際項目中考慮切分沒有數據的尾部region為佳,此外重試切分的時間間隔建議可配置,以免region未及時切分,導致所有數據存入到尾部一個region中

