Java中的執行緒池用過吧?來說說你是怎麼理解執行緒池吧?
前言
Java中的執行緒池用過吧?來說說你是怎麼使用執行緒池的?這句話在面試過程中遇到過好幾次了。我甚至這次標題都想寫成【Java八股文之執行緒池】,但是有點太俗套了。雖然,執行緒池是一個已經被說爛的知識點了,但是還是要寫這一篇用來加深自己的印象,但是想使用一個特殊的方式寫出來。
執行緒池
使用執行緒池的目的
先說一下我們為什麼要使用執行緒池?
- 執行緒是稀缺資源,不能頻繁的創建。而且創建和銷毀執行緒也是比較佔用系統開銷的。
- 為了做到解耦,執行緒的創建與執行任務分開,方便對執行緒進行維護。
- 為了復用,前面也說了創建和銷毀執行緒比較耗系統開銷,那麼創建出來執行緒放到一個池子里,可以給其他任務進行復用。
執行緒池是如何一步一步創建的
正常的我們在創建一個執行緒去執行任務的時候是這樣的:
new Thread(r).start();
但是這是最基本的方式,我們的項目中有可能很多地方都需要創建一個新的執行緒。這個使用為了減少重複程式碼,我們會把這段創建執行緒的程式碼放的一個工具類裡面,然後對外提供工具方法,使用的時候直接調用此方法即可。
/**
* 先定義介面(任務執行器)
*/
public interface Executor {
/**
* 執行任務
* @param runnable 執行緒任務
*/
void execute(Runnable runnable);
}
/**
* 實現:直接創建執行緒。
*/
class ExecutorImpl implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}
這種方式實現了創建執行緒的程式碼的復用,但是並沒有實現執行緒資源的復用,當有1000個地方需要執行緒的時候,會創建1000個執行緒。
為了實現資源也復用,增加一個阻塞隊列,當來了創建執行緒的任務的時候,先放到隊列里,然後再用一個執行緒(Worker),來處理任務。這樣就完成了執行緒資源的復用了,全程只有一個執行緒在來回的復用,一直在處理隊列中的任務。

通過上面的方式,實現了執行緒資源的復用,並且也起到提交任務和處理任務之間的解耦。但是只有一個執行緒處理任務,會有瓶頸的,所以具體需要多少執行緒來處理任務最好是根據具體的業務場景來確定,這樣我們把這個值,設置成一個參數,當創建執行緒池的時候傳入,就叫corePoolSize吧。
而且任務隊列最好也要有容量,但也應該是根據業務場景來配置容量,而且任務隊列還可以訂製一些規則,例如:按照一定的規則出隊。所以我們把任務隊列也配置成參數,在創建執行緒池的時候傳入。參數名稱就叫:workQueue吧。
當隊列中任務滿了之後,任務就會被拋棄,但是如果是重要業務任務,還不能拋棄,所以,當隊列中任務滿了之後,在執行緒池沒有資源處理任務的時候,拒絕策略,我們也根據業務場景來確定,這樣也在創建的時候傳入一種拒絕策略,參數名稱就叫:rejectedExecutionHandler。
繼續優化
雖然多了上面的三個參數後效果優化了不少,但是還可以繼續優化:
- 並不用上來就創建
corePoolSize數量的執行緒,我們可以增加了一個變數workCount,來記錄已經創建出來了工作執行緒,這樣在初始化的時候只有workCount<corePoolSize的時候,我們才創建執行緒來執行任務,當workCount>CorePoolSize的時候,再來了任務,就去進隊列。 - 在增加拒絕策略的時候,我定義一個介面:
RejectedExecutionHandler,然後使用者可以自己去實現這個介面,來完成自己的拒絕策略。 - 增加一個執行緒工廠的入參:
ThreadFactory,這樣保證每次創建執行緒的時候不用手動去創建執行緒了,而是通過ThreadFactory來獲取執行緒,並且也可以增加一些執行緒的標識。
雖然說第三版的執行緒池已經可以應對日常工作中的情況了,但是還是不夠有彈性,所謂的彈性就是指,在任務提交頻繁時應該處理能力提高,任務提交不頻繁時處理能力應該降低。
上面這版執行緒池就不夠彈性。
如果某個時間段,任務提交量劇增,這個時候,corePoolSize和隊列都滿了,再來提交任務就只能走拒絕策略了。
你或許會想到,那我可以增大corePoolSize的值,這樣就會創建出來更多的執行緒來處理任務,但是這個任務提交量劇增,只是某個時間段,過了這個時間段之後,創建出來這麼多的執行緒,可以大部分都會是空閑的狀態。這樣也是浪費資源了。
這樣就導致了一個兩難的情況,corePoolSize的值設置太大了也不好,設置太小了也不好。
這個時候,為讓執行緒池做到彈性伸縮,我們可以為他再添加一個參數:maximumPoolSize,這個參數代表的意思是最大執行緒數。
當corePoolSize和workQueue都滿了的時候,新提交的任務仍然可以創建新執行緒來進行處理,這些超過corePoolSize創建出來的執行緒,被稱為非核心執行緒。當corePoolSize與非核心執行緒數量的和等於maximumPoolSize再執行拒絕策略。
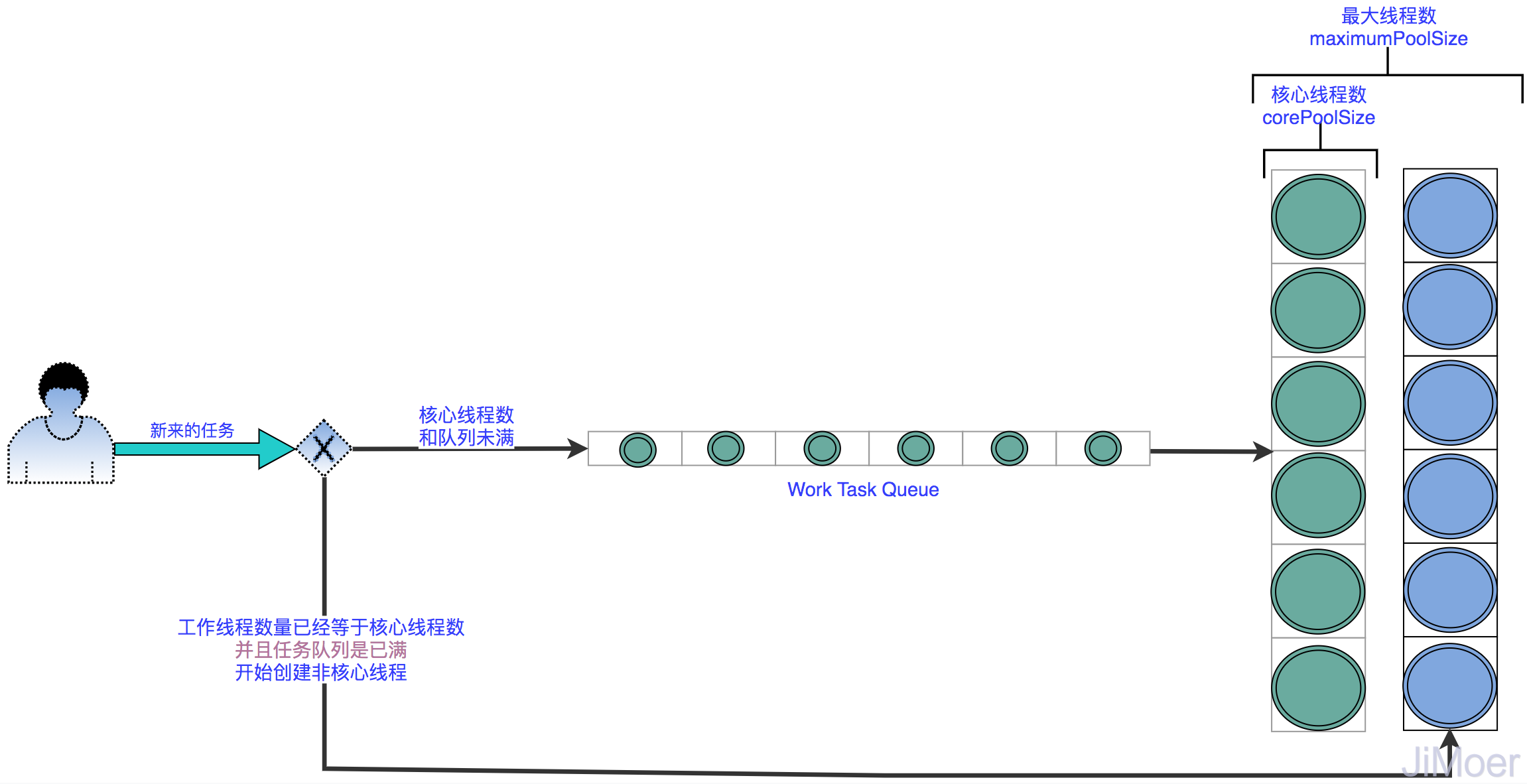
通過這樣的方式,corePoolSize,負責平時情況的執行緒使用量,maximumPoolSize負責提交任務高峰時的,臨時擴充容量。
但是目前這樣的方式只是考慮到了提交任務量高峰時期的擴充,但這個高峰期只是暫時的,過了這個高峰期,非核心執行緒一直放著也是浪費資源,所以我們再設定一個非核心執行緒的空閑活躍時間的參數:keepAliveTime,這樣當非核心執行緒數,空閑時間超過這個值就銷毀執行緒,釋放資源。
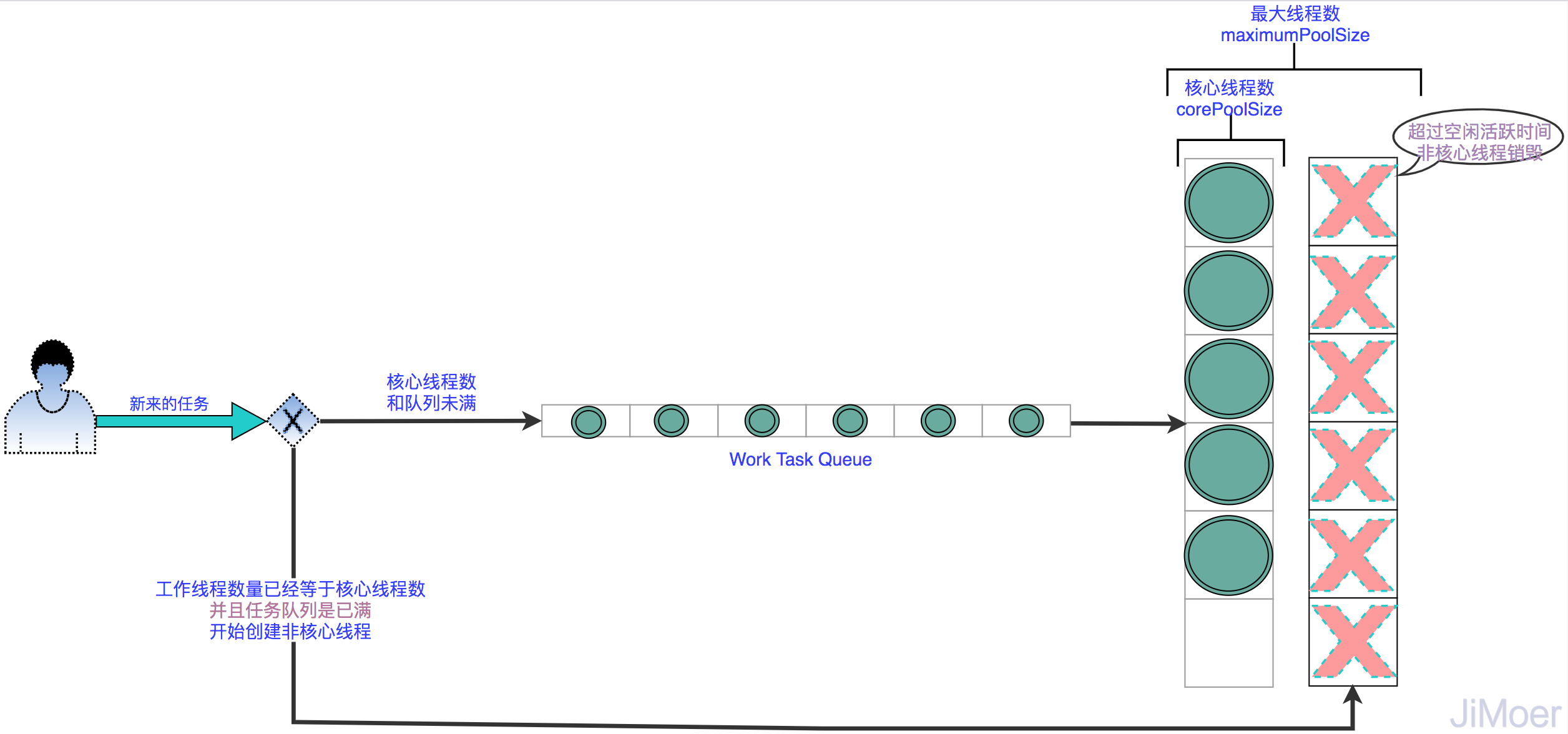
這一版的執行緒池,做到了在提交任務高峰時可臨時擴容,低谷時又可及時回收非核心執行緒,從而節省資源。真正的做到了收放自如。
通過上面幾版執行緒池的改進,最終改進成了和Java中的執行緒池原理基本相似了。這樣也能更透徹的理解創建執行緒池時要傳入的這幾個關鍵參數的意義了。
下面說幾個執行緒池常見的考察點
Java中的執行緒池的阻塞隊列都有哪幾種
ArrayBlockingQueue: 有界隊列,按照阻塞的先後順序訪問隊列,默認情況下不保證執行緒公平的訪問隊列~如果要保證公平性,會降低一定的吞吐量。底層是靠ReentrantLock來實現的,每一個方法中,都是靠ReentrantLock加鎖來完成阻塞。
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
LinkedBlockingQueue:基於鏈表的阻塞隊列,按照先進先出的順序排列,在不設置隊列長度的時候默認Integer.MAX_VALUE。所以認為當不設置隊列長度時,LinkedBlockingQueue為無解隊列。當指定了隊列長度後變為有界隊列,通常LinkedBlockingQueue的吞吐量要高於ArrayBlockingQueue;SynchronousQueue:一個不存儲元素的阻塞隊列,每個插入操作必須等到另一個執行緒調用移除操作,否則插入操作一直處於阻塞狀態。在不允許任務在隊列中等待的時候可以使用此隊列。DelayQueue:延遲獲取元素隊列,按照指定時間後獲取,為無界阻塞隊列。PriorityBlockingQueue:優先順序排序隊列,按照一定的優先順序對任務進行排序,默認是小頂堆。LinkedBlockingDeque:基於鏈表的雙端阻塞隊列。
Java提供了哪幾個默認的執行緒池,為什麼實際開發中不建議直接使用?
Executors.newCachedThreadPool();:阻塞隊列採用的SynchronousQueue,所以是不存儲等待任務的,並且最大執行緒數的值是Integer.MAX_VALUE。所以當任務提交量高峰時,相當於無限制的創建執行緒。並且空閑時間是60秒,QPS高峰期最終會將伺服器資源耗盡,所以真正實際應用中不建議使用。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Executors.newFixedThreadPool(int nThreads);:可重用固定執行緒數的執行緒池,源碼如下:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
核心執行緒數和最大執行緒數相等的執行緒池,並且阻塞任務隊列還是一個無解隊列,這樣,當處理任務的執行緒數量達到核心執行緒數時,再提交的任務都會進行到阻塞隊列里,但是阻塞隊列是無界的,這樣就提交任務高峰期有可能會造成任務一直堆積在隊列里,超出記憶體容量最終導致記憶體溢出。
Executors.newScheduledThreadPool(int corePoolSize);:一個定長執行緒池,支援定時及周期性任務執行,這個執行緒池的最大執行緒數也是Integer.MAX_VALUE,可以理解為會無限創建執行緒。存在將資源耗盡的風險,所以一般場景下不建議使用。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
Executors.newSingleThreadExecutor();
這種執行緒池,會創建一個執行緒數固定是1的執行緒池,並且任務隊列是無解的LinkedBlockingQueue,存在任務隊列無限添加造成OOM的風險。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
Executors.newWorkStealingPool();:一個具有搶佔式操作的執行緒池。
參數中傳入的是一個執行緒並發的數量,這裡和之前就有很明顯的區別,前面4種執行緒池都有核心執行緒數、最大執行緒數等等,而這就使用了一個並發執行緒數解決問題。這個執行緒池不會保證任務的順序執行,也就是 WorkStealing 的意思,搶佔式的工作,哪個執行緒搶到任務就執行。
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Java中的執行緒池提供了哪幾種拒絕策略
AbortPolicy:該策略默認是飽和策略。當不能在處理提交的任務時,直接拋出RejectedExecutionException,使用者可以自行捕獲此異常。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
CallerRunsPolicy:該策略是在執行緒池處理不了任務時,交給提交任務的主執行緒去處理任務,主執行緒在處理任務的時候,不能在提交任務了,這樣執行緒池就可以有時間去處理堆積的任務了。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
DiscardOldestPolicy:該策略是,拋棄最老的任務,然後再嘗試提交任務,若阻塞隊列使用PriorityBlockingQueue優先順序隊列,將會導致優先順序最高的任務被拋棄,所以在阻塞隊列為PriorityBlockingQueue時,不建議使用此策略。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
DiscardPolicy:這是一個比較任性的策略,當執行緒池處理不了任務時,直接拋棄,再來了新任務也直接拋棄。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
RejectHandler:
直接拋拒絕異常。
public void rejectedExecution(Runnable r, java.util.concurrent.ThreadPoolExecutor executor) {
throw new RejectedExecutionException();
}
Java中執行緒池核心執行緒數與最大執行緒數該如何配置
可以根據提交的任務不同,將執行緒池分開。
- 處理CPU密集型任務,執行緒數量應該較少,可為
N(CPU核數)+1或N(CPU核數) * 2,因為此時執行緒一定調度到某個CPU執行,若任務本身是CPU綁定的任務,那麼過多的執行緒只會增加執行緒切換的開銷,而不能提升吞吐量,但可能需要較長隊列做緩衝。 - I/O密集型任務,執行較慢、數量不大的IO任務,要考慮更多執行緒數,而無需太大隊列。相比計算型任務,需多一些執行緒,要結合具體的 I/O 阻塞時長考慮。
但是實際情況下,有些任務是既耗CPU資源,又佔用I/O資源的。所以這個時候可以採用類似美團技術提出方案,實時的監控執行緒池狀態資訊,然後對執行緒池的數據進行調整。
在監控執行緒池的時候可以使用如下幾個執行緒池屬性:
getTaskCount():執行緒池需要執行的任務數量。completedTaskCount:執行緒池在運行過程中已完成的任務數量,小於或等於taskCount。largestPoolSize:執行緒池裡曾經創建過的最大執行緒數量。通過這個數據可以知道執行緒池是否曾經滿過,如該數值等於執行緒池的最大執行緒數量,則表示執行緒池曾經滿過。getPoolSize():執行緒池的執行緒數量,如果執行緒池不銷毀的話,執行緒池裡的執行緒不會自動銷毀,所以這個大小隻增不減。getActiveCount():獲取活動的執行緒數。
參考:
你管這破玩意叫執行緒池?
[Java並發編程藝術]


