AAAI2020 | 一種任意形狀文本的檢測方法
- 2019 年 12 月 11 日
- 筆記
本文授權轉載自:CSIG文檔影像分析與識別專委會 作者:王豪,盧普

本文簡要介紹AAAI 2020論文「All You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting」的主要工作。該論文提出了用邊界點來表示任意形狀文本的方法,解決了自然場景影像中任意形狀文本的端到端識別問題。如圖1所示:現有方法用外接四邊形框來表示文本邊界(圖1,(a)),通過RoI-Align來提取四邊形內的特徵(圖1,(b)),這樣會提取出大量的背景雜訊,影響識別網路。利用邊界點來表示任意形狀文本有以下優勢:
- 邊界點能夠描述精準的文本形狀,消除背景雜訊所帶來的影響(圖1,(c));
- 通過邊界點,可以將任意形狀的文本矯正為水平文本,有利於識別網路(圖1,(d));
- 由於邊界點的表示方法,識別分支通過反向傳播來進一步優化邊界點的檢測。

Fig.1. Illustrations of two kinds of methods for text region representation.
一、研究背景
文本檢測和識別常作為兩個獨立的子任務進行研究,但事實上,兩者是相互關聯並且能相互促進的。近期的一些工作開始關注到文本端到端識別問題,並取的了顯著的進展。面對不規則的文本,這些方法多採用分割的方式對文字區域進行描述。分割的方法常需要複雜的後處理,並且獲取的文本框和識別分支之間並不可導,識別分支的文本語義資訊無法通過反向傳播來對文本框進行優化。同時一些方法使用字元分割的方法進行識別,這使得識別器失去序列建模能力,並且需要額外的字元標註,增加了識別的訓練難度以及標註成本。
二、原理簡述

Fig.2. Overall architecture.
雖然邊界點的預測理論上可以直接從水平候選框中預測(如圖3(d)所示),但是自然場景中的文本呈現各種不同的形狀、角度以及仿射變換等,這使得直接從水平候選框中預測邊界點變得十分困難,不具有穩定性。因此,我們在文本實例的最小外接四邊形上預測邊界點,這樣可以將不同角度、形狀的文本旋轉為水平形狀,在對齊後的文本實例上預測邊界點對於網路更為高效,容易。
具體方法細節如圖2所示,本文的方法的包含三個部分:多方向矩形包圍框檢測器(the Oriented Rectangular Box Detector),邊界點檢測器(the Boundary Point Detection Network),以及識別網路(the Recognition Network)。對於多方向矩形包圍框檢測器,該文首先使用RPN網路進行候選區提取。為了產生多方向的矩形框,在提取出的候選區對目標矩形框的中心偏移量、寬度、高度和傾斜角度進行回歸。獲取了矩形包圍框後,利用矩形框進行特徵提取,並在提取的的候選區中進行文字邊界點的回歸。得到預測的邊界點後,對文本區域的特徵進行矯正,並將矯正的特徵輸入到後續的識別器中。
對於邊界點檢測網路,如圖3(c)所示,該方法根據默認錨點(設定的參考點)進行回歸,這些錨點被均勻的放置在最小矩形包圍框的兩個長邊上,同時從文本實例的每個長邊上等距取樣K個點作為文字的目標邊界點。本文採用預測相對偏移量的方式來獲取邊界點的坐標,即預測一個的向量(個邊界點)。對於邊界點

可從預測的偏移量獲取,

,其中

代表定義的描點。
對於識別網路,識別器使用矯正的特徵預測出字元序列。首先,編碼器將矯正的特徵編碼為特徵序列

。 然後基於注意力的解碼器將F轉化為字元序列

, 其中T是序列長度。當為第t時,解碼器通過隱藏層狀態

和上一步的結果
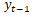
預測當前步的結果。
本文的方法採用完全端到端的訓練方式,網路的損失函數包含四個部分,

, 其中

為RPN的損失,

為多方向矩形框回歸的損失值,

為邊界點回歸的損失值,

為識別網路的損失。

Fig. 3. Illustrations of regression procedure.
三、主要實驗結果及可視化效果
TABLE1. Results on Total-Text.「P」, 「R」 and 「F」 mean Precision, Recall and F-measure indetection task respectively. 「E2E」 means end-to-end, 「None」 means recognition without any lexicon, 「Full」 lexicon contains all words in test set.

TABLE 2. Results on ICDAR2015 and ICDAR2013 (DetEval). 「S」, 「W」 and 「G」 mean recognition with strong, weak and generic lexicon respectively. 「*」 denotes that training dataset of MLT2017 is used for training.


Fig.3. Examples of text spotting results of our method on Total-Text, ICDAR2015, and ICDAR2013.
從Table 1來看,文中的方法在曲形數據集上取得了優異的性能,大幅領先先前方法。總結來看,性能的提升主要來源於三點:
1) 相對於基於分割的方法MaskTextSpotter, 本文的識別器採用基於注意力的解碼器,能夠捕獲字元之間的語義關係,而MaskTextSpotter獨立地預測每個字元;
2) 相對於其他方法,本文使用邊界點對文本區域的特徵進行矯正,識別器擁有更好的特徵;
3) 得益於更好的識別結果,由於檢測和識別共享特徵,檢測的結果受特徵影響得到進一步提升。
對於Table 2,文中的方法在ICDAR15多方向數據集上取得較好的結果,得益於序列識別器,在只使用通用字典的情況下高於先前的結果。在ICDAR13水平數據集上,本文的方法未使用字元標註,也取得較好的結果。
Fig. 3展示了一些可視化的結果圖。該方法能處理任意形狀的文本,並且能很好地處理垂直文本,能夠正確獲取豎直文本的閱讀順序。
四、總結及討論
本文提出了一個以邊界點表示任意形狀文本的端到端網路,實驗證明了此種方法在端到端識別任務上的有效性和優越性。檢測任務和識別任務均能從邊界點這種表示形式中受益:1)由於邊界點的表示是可導的,因此識別分支的導數回傳會進一步優化檢測結果;2)使用邊界點對不規則文本的特徵進行矯正能移除背景干擾,可以提升識別性能。
五、相關資源
- 論文下載:https://arxiv.org/abs/1911.09550 ; https://arxiv.org/pdf/1911.09550
原文作者:Hao Wang, Pu Lu, Hui Zhang, Minkun Yang, Xiang Bai, Yongchao Xu, Mengchao He, Yongpan Wang, Wenyu Liu


