JVM JIT動態編譯

一、概述
1.1 基本概念
a. 動態編譯(dynamic compilation)指的是「在運行時進行編譯」;與之相對的是事前編譯(ahead-of-time compilation,簡稱AOT),也叫靜態編譯(static compilation)。
b. JIT編譯(just-in-time compilation)狹義來說是當某段程式碼即將第一次被執行時進行編譯,因而叫「即時編譯」。JIT編譯是動態編譯的一種特例。JIT編譯一詞後來被泛化,時常與動態編譯等價;但要注意廣義與狹義的JIT編譯所指的區別。
c. 自適應動態編譯(adaptive dynamic compilation)也是一種動態編譯,但它通常執行的時機比JIT編譯遲,先讓程式「以某種式」先運行起來,收集一些資訊之後再做動態編譯。這樣的編譯可以更加優化。
1.2 JVM運行原理
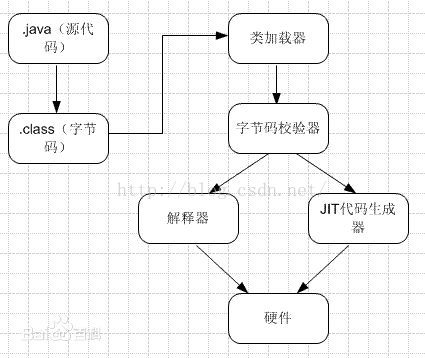
在部分商用虛擬機中(如HotSpot),Java程式最初是通過解釋器(Interpreter)進行解釋執行的,當虛擬機發現某個方法或程式碼塊的運行特別頻繁時,就會把這些程式碼認定為「熱點程式碼」。為了提高熱點程式碼的執行效率,在運行時,虛擬機將會把這些程式碼編譯成與本地平台相關的機器碼,並進行各種層次的優化,完成這個任務的編譯器稱為即時編譯器(Just In Time Compiler,下文統稱JIT編譯器)。
即時編譯器並不是虛擬機必須的部分,Java虛擬機規範並沒有規定Java虛擬機內必須要有即時編譯器存在,更沒有限定或指導即時編譯器應該如何去實現。但是,即時編譯器編譯性能的好壞、程式碼優化程度的高低卻是衡量一款商用虛擬機優秀與否的最關鍵的指標之一,它也是虛擬機中最核心且最能體現虛擬機技術水平的部分。
由於Java虛擬機規範並沒有具體的約束規則去限制即使編譯器應該如何實現,所以這部分功能完全是與虛擬機具體實現相關的內容,如無特殊說明,我們提到的編譯器、即時編譯器都是指Hotspot虛擬機內的即時編譯器,虛擬機也是特指HotSpot虛擬機。
二、為什麼HotSpot虛擬機要使用解釋器與編譯器並存的架構?
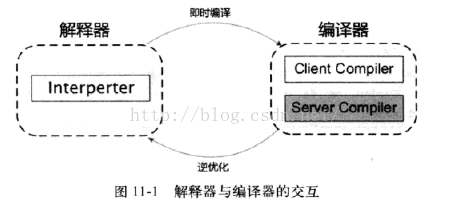
儘管並不是所有的Java虛擬機都採用解釋器與編譯器並存的架構,但許多主流的商用虛擬機(如HotSpot),都同時包含解釋器和編譯器。解釋器與編譯器兩者各有優勢:當程式需要迅速啟動和執行的時候,解釋器可以首先發揮作用,省去編譯的時間,立即執行。在程式運行後,隨著時間的推移,編譯器逐漸發揮作用,把越來越多的程式碼編譯成本地程式碼之後,可以獲取更高的執行效率。當程式運行環境中記憶體資源限制較大(如部分嵌入式系統中),可以使用解釋器執行節約記憶體,反之可以使用編譯執行來提升效率。此外,如果編譯後出現「罕見陷阱」,可以通過逆優化退回到解釋執行。
2.1 編譯的時間開銷
解釋器的執行,抽象的看是這樣的:
輸入的程式碼 -> [ 解釋器 解釋執行 ] -> 執行結果
而要JIT編譯然後再執行的話,抽象的看則是:
輸入的程式碼 -> [ 編譯器 編譯 ] -> 編譯後的程式碼 -> [ 執行 ] -> 執行結果
說JIT比解釋快,其實說的是「執行編譯後的程式碼」比「解釋器解釋執行」要快,並不是說「編譯」這個動作比「解釋」這個動作快。
JIT編譯再怎麼快,至少也比解釋執行一次略慢一些,而要得到最後的執行結果還得再經過一個「執行編譯後的程式碼」的過程。所以,對「只執行一次」的程式碼而言,解釋執行其實總是比JIT編譯執行要快。
怎麼算是「只執行一次的程式碼」呢?粗略說,下面兩個條件同時滿足時就是嚴格的「只執行一次」
- 只被調用一次,例如類的構造器(class initializer,<clinit>())
- 沒有循環
對只執行一次的程式碼做JIT編譯再執行,可以說是得不償失。對只執行少量次數的程式碼,JIT編譯帶來的執行速度的提升也未必能抵消掉最初編譯帶來的開銷。只有對頻繁執行的程式碼,JIT編譯才能保證有正面的收益。
2.2 編譯的空間開銷
對一般的Java方法而言,編譯後程式碼的大小相對於位元組碼的大小,膨脹比達到10x是很正常的。同上面說的時間開銷一樣,這裡的空間開銷也是,只有對執行頻繁的程式碼才值得編譯,如果把所有程式碼都編譯則會顯著增加程式碼所佔空間,導致「程式碼爆炸」。
這也就解釋了為什麼有些JVM會選擇不總是做JIT編譯,而是選擇用解釋器+JIT編譯器的混合執行引擎。
三、為何HotSpot虛擬機要實現兩個不同的即時編譯器?
HotSpot虛擬機中內置了兩個即時編譯器:Client Complier和Server Complier,簡稱為C1、C2編譯器,分別用在客戶端和服務端。目前主流的HotSpot虛擬機中默認是採用解釋器與其中一個編譯器直接配合的方式工作。程式使用哪個編譯器,取決於虛擬機運行的模式。HotSpot虛擬機會根據自身版本與宿主機器的硬體性能自動選擇運行模式,用戶也可以使用「-client」或「-server」參數去強制指定虛擬機運行在Client模式或Server模式。
用Client Complier獲取更高的編譯速度,用Server Complier 來獲取更好的編譯品質。為什麼提供多個即時編譯器與為什麼提供多個垃圾收集器類似,都是為了適應不同的應用場景。
Server Compiler和Client Compiler兩個編譯器的編譯過程是不一樣的。
- 對Client Compiler來說,它是一個簡單快速的編譯器,主要關注點在於局部優化,而放棄許多耗時較長的全局優化手段。
- 而Server Compiler則是專門面向伺服器端的,並為服務端的性能配置特別調整過的編譯器,是一個充分優化過的高級編譯器。
四、哪些程式程式碼會被編譯為本地程式碼?如何編譯為本地程式碼?
程式中的程式碼只有是熱點程式碼時,才會編譯為本地程式碼,那麼什麼是熱點程式碼呢?運行過程中會被即時編譯器編譯的「熱點程式碼」有兩類:
- 被多次調用的方法。
- 被多次執行的循環體。
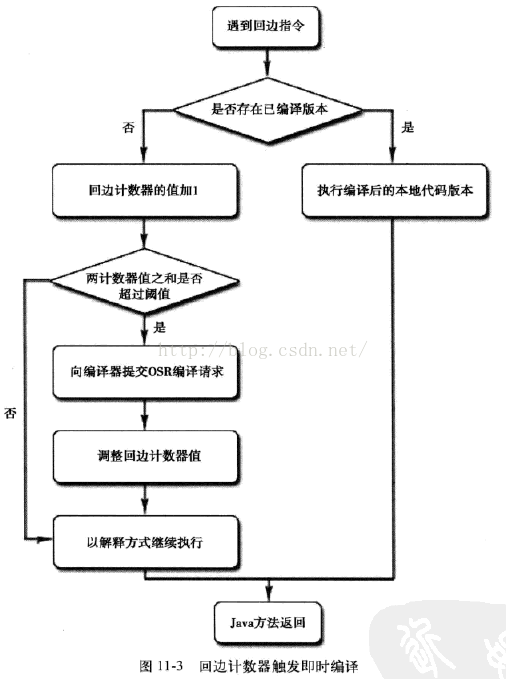
兩種情況,編譯器都是以整個方法作為編譯對象。 這種編譯方法因為編譯發生在方法執行過程之中,因此形象的稱之為棧上替換(On Stack Replacement,OSR),即方法棧幀還在棧上,方法就被替換了。
4.1 如何判斷方法或一段程式碼或是不是熱點程式碼呢?
要知道方法或一段程式碼是不是熱點程式碼,是不是需要觸發即時編譯,需要進行Hot Spot Detection(熱點探測)。
目前主要的熱點探測方式有以下兩種:
- (1) 基於取樣的熱點探測
採用這種方法的虛擬機會周期性地檢查各個執行緒的棧頂,如果發現某些方法經常出現在棧頂,那這個方法就是「熱點方法」。這種探測方法的好處是實現簡單高效,還可以很容易地獲取方法調用關係(將調用堆棧展開即可),缺點是很難精確地確認一個方法的熱度,容易因為受到執行緒阻塞或別的外界因素的影響而擾亂熱點探測。
- (2) 基於計數器的熱點探測
採用這種方法的虛擬機會為每個方法(甚至是程式碼塊)建立計數器,統計方法的執行次數,如果執行次數超過一定的閥值,就認為它是「熱點方法」。這種統計方法實現複雜一些,需要為每個方法建立並維護計數器,而且不能直接獲取到方法的調用關係,但是它的統計結果相對更加精確嚴謹。
4.2 HotSpot虛擬機中使用的是哪鍾熱點檢測方式呢?
在HotSpot虛擬機中使用的是第二種——基於計數器的熱點探測方法,因此它為每個方法準備了兩個計數器:方法調用計數器和回邊計數器。在確定虛擬機運行參數的前提下,這兩個計數器都有一個確定的閾值,當計數器超過閾值溢出了,就會觸發JIT編譯。
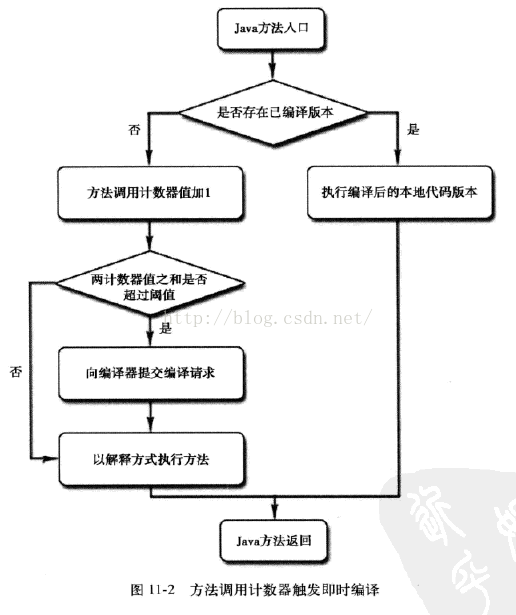
4.2.1 方法調用計數器
顧名思義,這個計數器用於統計方法被調用的次數。
當一個方法被調用時,會先檢查該方法是否存在被JIT編譯過的版本,如果存在,則優先使用編譯後的本地程式碼來執行。如果不存在已被編譯過的版本,則將此方法的調用計數器值加1,然後判斷方法調用計數器與回邊計數器值之和是否超過方法調用計數器的閾值。如果超過閾值,那麼將會向即時編譯器提交一個該方法的程式碼編譯請求。
如果不做任何設置,執行引擎並不會同步等待編譯請求完成,而是繼續進行解釋器按照解釋方式執行位元組碼,直到提交的請求被編譯器編譯完成。當編譯工作完成之後,這個方法的調用入口地址就會系統自動改寫成新的,下一次調用該方法時就會使用已編譯的版本。
4.2.2 回邊計數器
它的作用就是統計一個方法中循環體程式碼執行的次數,在位元組碼中遇到控制流向後跳轉的指令稱為「回邊」。
參考文章:
//www.zhihu.com/question/37389356/answer/73820511
//zhuanlan.zhihu.com/p/19977592
//blog.csdn.net/u010412719/article/details/47008717


