消息中間件的應用場景
提高系統性能首先考慮的是資料庫的優化,但是資料庫因為歷史原因,橫向擴展是一件非常複雜的工程,所有我們一般會盡量把流量都擋在資料庫之前。
不管是無限的橫向擴展伺服器,還是縱向阻隔到達資料庫的流量,都是這個思路。阻隔直達資料庫的流量,快取組件和消息組件是兩大殺器。這裡就重點說說MQ的應用場景。
MQ簡介
MQ:Message queue,消息隊列,就是指保存消息的一個容器。具體的定義這裡就不類似於資料庫、快取等,用來保存數據的。當然,與資料庫、快取等產品比較,也有自己一些特點,具體的特點後文會做詳細的介紹。
現在常用的MQ組件有activeMQ、rabbitMQ、rocketMQ、zeroMQ,當然近年來火熱的kafka,從某些場景來說,也是MQ,當然kafka的功能更加強大,雖然不同的MQ都有自己的特點和優勢,但是,不管是哪種MQ,都有MQ本身自帶的一些特點,下面,咱們就先聊聊MQ的特點。
MQ特點
(1)先進先出
不能先進先出,都不能說是隊列了。消息隊列的順序在入隊的時候就基本已經確定了,一般是不需人工干預的。而且,最重要的是,數據是只有一條數據在使用中。 這也是MQ在諸多場景被使用的原因。
(2)發布訂閱
發布訂閱是一種很高效的處理方式,如果不發生阻塞,基本可以當做是同步操作。這種處理方式能非常有效的提升伺服器利用率,這樣的應用場景非常廣泛。
(3)持久化
持久化確保MQ的使用不只是一個部分場景的輔助工具,而是讓MQ能像資料庫一樣存儲核心的數據。
(4)分散式
在現在大流量、大數據的使用場景下,只支援單體應用的伺服器軟體基本是無法使用的,支援分散式的部署,才能被廣泛使用。而且,MQ的定位就是一個高性能的中間件。
應用場景
消息隊列中間件是分散式系統中重要的組件,主要解決應用解耦,非同步消息,流量削鋒等問題,實現高性能,高可用,可伸縮和最終一致性架構。目前使用較多的消息隊列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
消息中間件監控
Activemq 監控
Rabbitmq 監控
Kafka 監控
非同步處理
場景說明:用戶註冊後,需要發註冊郵件和註冊簡訊。傳統的做法有兩種 1.串列的方式;2.並行方式
a、串列方式:將註冊資訊寫入資料庫成功後,發送註冊郵件,再發送註冊簡訊。以上三個任務全部完成後,返回給客戶端。

b、並行方式:將註冊資訊寫入資料庫成功後,發送註冊郵件的同時,發送註冊簡訊。以上三個任務完成後,返回給客戶端。與串列的差別是,並行的方式可以提高處理的時間
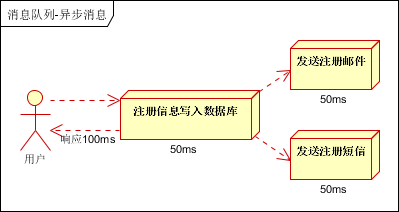
假設三個業務節點每個使用50毫秒鐘,不考慮網路等其他開銷,則串列方式的時間是150毫秒,並行的時間可能是100毫秒。
因為CPU在單位時間內處理的請求數是一定的,假設CPU1秒內吞吐量是100次。則串列方式1秒內CPU可處理的請求量是7次(1000/150)。並行方式處理的請求量是10次(1000/100)
小結:如以上案例描述,傳統的方式系統的性能(並發量,吞吐量,響應時間)會有瓶頸。如何解決這個問題呢?
引入消息隊列,將不是必須的業務邏輯,非同步處理。改造後的架構如下:
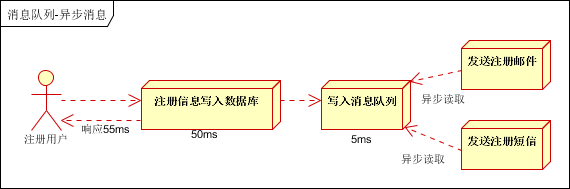
按照以上約定,用戶的響應時間相當於是註冊資訊寫入資料庫的時間,也就是50毫秒。註冊郵件,發送簡訊寫入消息隊列後,直接返回,因此寫入消息隊列的速度很快,基本可以忽略,因此用戶的響應時間可能是50毫秒。因此架構改變後,系統的吞吐量提高到每秒20 QPS。比串列提高了3倍,比並行提高了兩倍。
應用解耦
場景說明:用戶下單後,訂單系統需要通知庫存系統。傳統的做法是,訂單系統調用庫存系統的介面。如下圖:
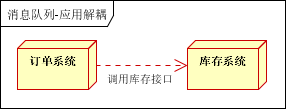
傳統模式的缺點:假如庫存系統無法訪問,則訂單減庫存將失敗,從而導致訂單失敗,訂單系統與庫存系統耦合
如何解決以上問題呢?引入應用消息隊列後的方案,如下圖:
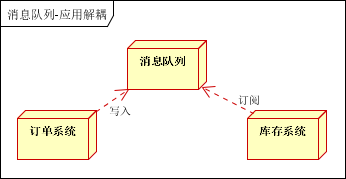
訂單系統:用戶下單後,訂單系統完成持久化處理,將消息寫入消息隊列,返回用戶訂單下單成功
庫存系統:訂閱下單的消息,採用拉/推的方式,獲取下單資訊,庫存系統根據下單資訊,進行庫存操作
假如:在下單時庫存系統不能正常使用。也不影響正常下單,因為下單後,訂單系統寫入消息隊列就不再關心其他的後續操作了。實現訂單系統與庫存系統的應用解耦
流量削峰
流量削鋒也是消息隊列中的常用場景,一般在秒殺或團搶活動中使用廣泛。
應用場景:秒殺活動,一般會因為流量過大,導致流量暴增,應用掛掉。為解決這個問題,一般需要在應用前端加入消息隊列。
a、可以控制活動的人數
b、可以緩解短時間內高流量壓垮應用
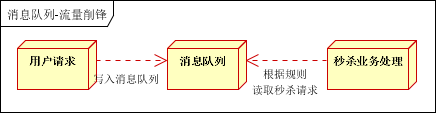
用戶的請求,伺服器接收後,首先寫入消息隊列。假如消息隊列長度超過最大數量,則直接拋棄用戶請求或跳轉到錯誤頁面。
秒殺業務根據消息隊列中的請求資訊,再做後續處理。
消息通訊
消息通訊是指,消息隊列一般都內置了高效的通訊機制,因此也可以用在純的消息通訊。比如實現點對點消息隊列,或者聊天室等。
點對點通訊:
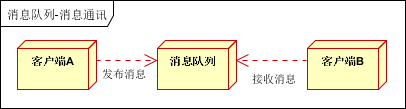
客戶端A和客戶端B使用同一隊列,進行消息通訊。
聊天室通訊:
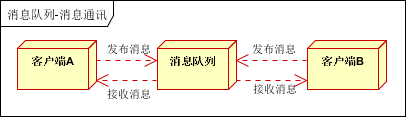
客戶端A,客戶端B,客戶端N訂閱同一主題,進行消息發布和接收。實現類似聊天室效果。
以上實際是消息隊列的兩種消息模式,點對點或發布訂閱模式。模型為示意圖,供參考。
具體例子可以參考官網://www.rabbitmq.com/web-stomp.html
海量數據同步(日誌)
日誌處理是指將消息隊列用在日誌處理中,比如Kafka的應用,解決大量日誌傳輸的問題。架構簡化如下
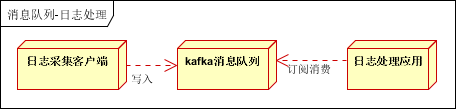
日誌採集客戶端,負責日誌數據採集,定時寫受寫入Kafka隊列
Kafka消息隊列,負責日誌數據的接收,存儲和轉發
日誌處理應用:訂閱並消費kafka隊列中的日誌數據
eg:日誌收集系統

分為Zookeeper註冊中心,日誌收集客戶端,Kafka集群和Storm集群(OtherApp)四部分組成。
Zookeeper註冊中心,提出負載均衡和地址查找服務
日誌收集客戶端,用於採集應用系統的日誌,並將數據推送到kafka隊列
Kafka集群:接收,路由,存儲,轉發等消息處理
Storm集群:與OtherApp處於同一級別,採用拉的方式消費隊列中的數據
網易使用案例:
網易NDC-DTS系統在使用,應該是最典型的應用場景,主要就是binlog的同步,數據表的主從複製。簡單一點就是:MySQL進程寫binlog文件 -> 同步應用去實時監控binlog文件讀取發送到Kafka -> 目標端處理binlog 。原理上與阿里開源的canal, 點評的puma大同小異。
任務調度
參考延時隊列
分散式事物
分散式事務有強一致,弱一致,和最終一致性這三種:
強一致:
當更新操作完成之後,任何多個後續進程或者執行緒的訪問都會返回最新的更新過的值。這種是對用戶最友好的,就是用戶上一次寫什麼,下一次就保證能讀到什麼。根據 CAP 理論,這種實現需要犧牲可用性。
弱一致:
系統並不保證續進程或者執行緒的訪問都會返回最新的更新過的值。系統在數據寫入成功之後,不承諾立即可以讀到最新寫入的值,也不會具體的承諾多久之後可以讀到。
最終一致:
弱一致性的特定形式。系統保證在沒有後續更新的前提下,系統最終返回上一次更新操作的值。在沒有故障發生的前提下,不一致窗口的時間主要受通訊延遲,系統負載和複製副本的個數影響。DNS 是一個典型的最終一致性系統。
在分散式系統中,同時滿足「CAP定律」中的「一致性」、「可用性」和「分區容錯性」三者是幾乎不可能的。在互聯網領域的絕大多數的場景,都需要犧牲強一致性來換取系統的高可用性,系統往往只需要保證「最終一致性」,只要這個最終時間是在用戶可以接受的範圍內即可,這時候我們只需要用短暫的數據不一致就可以達到我們想要效果。
實例描述
比如有訂單,庫存兩個數據,一個下單過程簡化為,加一個訂單,減一個庫存。 而訂單和庫存是獨立的服務,那怎麼保證數據一致性。
這時候我們需要思考一下,怎麼保證兩個遠程調用「同時成功」,數據一致?
請大家先注意一點遠程調用最鬱悶的地方就是,結果有3種,成功、失敗和超時。 超時的話,成功失敗都有可能。
一般的解決方案,大多數的做法是藉助mq來做最終一致。
如何實現最終一致
我們是怎麼利用Mq來達到最終一致的呢?
首先,拿我們上面提到的訂單業務舉例:
在我們進行加訂單的過程中同時插入logA(這個過程是可以做本地事務的)
然後可以非同步讀取logA,發mqA
B端接收mqA,同時減少庫存,B這裡需要做冪等(避免因為重複消息造成的業務錯亂)
那麼我們通過上面的分析可能聯想到這樣的問題?
本地先執行事務,執行成功了就發個消息過去,消費端拿到消息執行自己的事務
比如a,b,c,a非同步調用b,c如果b失敗了,或者b成功,或者b超時,那麼怎麼用mq讓他們最終一致呢?b失敗就失敗了,b成功之後給c發一個消息,b和c對a來講都是非同步的,且他們都是同時進行的話,而且需要a,b,c同時成功的情況,那麼這種情況用mq怎麼做?
其實做法還是參照於本地事務的概念的。
第一種情況:假設a,b,c三者都正常執行,那整個業務正常結束
第二種情況:假設b超時,那麼需要a給b重發消息(記得b服務要做冪等),如果出現重發失敗的話,需要看情況,是終端服務,還是繼續重發,甚至人為干預(所有的規則制定都需要根據業務規則來定)
第三種情況:假設a,b,c三者之中的一個失敗了,失敗的服務利用MQ給其他的服務發送消息,其他的服務接收消息,查詢本地事務記錄日誌,如果本地也失敗,刪除收到的消息(表示消息消費成功),如果本地成功的話,則需要調用補償介面進行補償(需要每個服務都提供業務補償介面)。
注意事項:
mq這裡有個坑,通常只適用於只允許第一個操作失敗的場景,也就是第一個成功之後必須保證後面的操作在業務上沒障礙,不然後面失敗了前面不好回滾,只允許系統異常的失敗,不允許業務上的失敗,通常業務上失敗一次後面基本上也不太可能成功了,要是因為網路或宕機引起的失敗可以通過重試解決,如果業務異常,那就只能發消息給a和c讓他們做補償了吧?通常是通過第三方進行補償,ABC提供補償介面,設計範式里通常不允許消費下游業務失敗。
怎麼理解呢,舉個例子:
比如A給B轉賬,A先自己扣錢,然後發了個消息,B這邊如果在這之前銷戶了,那重試多少次也沒用,只能人工干預。
網易在分散式事務採用的解決方式
網易部分業務是用MQ實現了最終一致性,目前教育產品,例如:網易雲課堂。
也有一部分業務用了TCC事務,但是TCC事務用的比較少,因為會侵染業務,開發成本比較高,如果體量不大的話直接用JPA或MQ支援事務就好。
網易的產品中使用分散式事務基於技術
TCC,FMT(Framework-managed transactions),事務消息都有。
開源產品myth://gitee.com/shuaiqiyu/myth
常用消息隊列(ActiveMQ、RabbitMQ、RocketMQ、Kafka)比較
|
特性MQ |
ActiveMQ |
RabbitMQ |
RocketMQ |
Kafka |
|
生產者消費者模式 |
支援 |
支援 |
支援 |
支援 |
|
發布訂閱模式 |
支援 |
支援 |
支援 |
支援 |
|
請求回應模式 |
支援 |
支援 |
不支援 |
不支援 |
|
Api完備性 |
高 |
高 |
高 |
高 |
|
多語言支援 |
支援 |
支援 |
java |
支援 |
|
單機吞吐量 |
萬級 |
萬級 |
萬級 |
十萬級 |
|
消息延遲 |
無 |
微秒級 |
毫秒級 |
毫秒級 |
|
可用性 |
高(主從) |
高(主從) |
非常高(分散式) |
非常高(分散式) |
|
消息丟失 |
低 |
低 |
理論上不會丟失 |
理論上不會丟失 |
|
文檔的完備性 |
高 |
高 |
教高 |
高 |
|
提供快速入門 |
有 |
有 |
有 |
有 |
|
社區活躍度 |
高 |
高 |
中 |
高 |
|
商業支援 |
無 |
無 |
商業雲 |
商業雲 |
ActiveMQ
歷史悠久的開源項目,已經在很多產品中得到應用,實現了JMS1.1規範,可以和spring-jms輕鬆融合,實現了多種協議,不夠輕巧(源程式碼比RocketMQ多),支援持久化到資料庫,對隊列數較多的情況支援不好。總體來說:
- RabbitMQ
它比Kafka成熟,支援AMQP事務處理,在可靠性上,RabbitMQ超過Kafka,在性能方面超過ActiveMQ。 - RocketMQ
RocketMQ是阿里開源的消息中間件,目前在Apache孵化,使用純Java開發,具有高吞吐量、高可用性、適合大規模分散式系統應用的特點。RocketMQ思路起源於Kafka,但並不是簡單的複製,它對消息的可靠傳輸及事務性做了優化,目前在阿里集團被廣泛應用於交易、充值、流計算、消息推送、日誌流式處理、binglog分發等場景,支撐了阿里多次雙十一活動。 因為是阿里內部從實踐到產品的產物,因此裡面很多介面、API並不是很普遍適用。其可靠性毋庸置疑,而且與Kafka一脈相承(甚至更優),性能強勁,支援海量堆積。 - Kafka設計的初衷就是處理日誌的,不支援AMQP事務處理,可以看做是一個日誌系統,針對性很強,所以它並沒有具備一個成熟MQ應該具備的特性。Kafka的性能(吞吐量、tps)比RabbitMQ要強,如果用來做大數據量的快速處理是比RabbitMQ有優勢的。


