華為雲PB級資料庫GaussDB(for Redis)揭秘第八期:用高斯 Redis 進行計數
摘要:高斯Redis,計數的最佳選擇!
一、背景
當我們打開手機刷微博時,就要開始和各種各樣的計數器打交道了。我們註冊一個帳號後,微博就會給我們記錄一組數據:關注數、粉絲數、動態數…;我們刷帖時,關注每天的熱搜情況,微博需要為每個熱搜記錄一組搜索量。在這一串數據後面,是一個個計數器在工作。
計數器可以分為常規計數器和基數計數器,對於常規計數器,只需要對計數器進行簡單的增減即可;對於基數計數器,需要對元素進行去重,比如統計搜索量時,需要保證每個用戶的多次搜索只統計一次。對於這兩種需求,Redis 都有對應的數據類型進行統計。然而開源 Redis 是一個弱一致性的資料庫,在特定的場景下,弱一致的計數不能滿足業務需求,為此,我們需要一個強一致的資料庫進行計數。
GaussDB(for Redis)(下文簡稱高斯Redis),是華為自研的強一致、持久化 NoSQL 資料庫,兼容 Redis5.0 協議。本文將介紹常規計數器與基數計數器的應用場景及使用高斯 Redis 實現計數。
二、常規計數器
2.1如何使用 Redis 進行常規計數
Redis 實現常規計數器有兩種數據類型適合:String 和 Hash。
2.1.1使用string 計數
當我們需要維護的計數器數目較少,比如統計網站的註冊用戶數時,適合使用 String 類型的計數器。Redis 提供的 Incr 和 Decr 命令分別對 String 類型的 key 值進行增一與減一操作:
127.0.0.1:6379> SET counter 100 OK 127.0.0.1:6379> INCR counter (integer) 101 127.0.0.1:6379> DECR counter (integer) 100
除Incr與Decr命令外,Redis String 類型還提供 Incrby 與 Decrby 命令,語法格式為:
- incrby: INCRBY key count
將 key 增加 count,count 可正可負,返回 key 的結果:
127.0.0.1:6379> INCRBY counter 10 (integer) 10 127.0.0.1:6379> INCRBY counter -20 (integer) -10
- decrby: DECRBY key count
將 key 減少 count,count 可正可負,返回 key 的結果:
127.0.0.1:6379> DECRBY counter 10 (integer) -10 127.0.0.1:6379> DECRBY counter -20 (integer) 10
2.1.2使用Hash計數
需要維護多個密切關聯的計數器時,可以使用Hash結構進行計數。比如,當我們註冊一個微博帳號時,微博會給每個用戶記錄一些用戶數據,比如粉絲數、關注數等,這些數據都綁定到對應用戶上,因此可以將這組計數器記錄在同一個Hash key中,使用 hincrby 命令,語法格式為:
- hincrby: HINCRBY key filed count
將 Hash key 的 filed 增加 count,count 可正可負,返回對應 field 的結果:
127.0.0.1:6379> HGET userid field (nil) 127.0.0.1:6379> HINCRBY userid field 1 (integer) 1 127.0.0.1:6379> HINCRBY userid field -1 (integer) 0 127.0.0.1:6379> HGET userid field "0"
2.2常規計數器使用場景
常規計數器的使用場景很廣泛,對於社交產品,用戶的粉絲數、關注數,帖子的點贊數、收藏數…;對於影片網站,需要統計影片的播放次數(PV統計,Page View);對於電商秒殺,需要統計商品數量並進行流量控制。在並發量高的情況下,Redis 的性能優勢明顯,非常適合以上場景。
以電商秒殺業務為例,為了處理高並發讀寫,通常在MySQL上層部署Redis作為快取。為了抗住大流量,使用計數器作限流。比如,當我們想控制每秒1萬次請求時,可以初始化一個counter=10000,隨後每次請求過來,都對counter減一,當counter 歸零後,阻塞後續的請求。每隔一段時間,重置counter=10000,以此保證大流量不會衝擊底層的MySQL。
三、基數統計:HyperLogLog 的原理及使用
基數計數(cardinality counting)是指在一個數據集合中,統計不重複元素的個數,是實際應用中一種常見的場景。比如統計一段時間內訪問某個網站的用戶數,網路遊戲的日活用戶數量等。
在數據量較小情況下,我們可以把所有數據保存下來進行去重統計。Redis 中,可以使用 Set 與 Zset 將數據保存下來,然後統計集合中的元素數量。而當數據量較大時,該方法會消耗較大的存儲空間,需要考慮其它的演算法。
考慮一種情況,當我們登錄微博時,微博會記錄我們的登錄情況,並統計每天有多少活躍用戶。很顯然,我們不需要也不應該記錄活躍用戶的ID,並且,少量誤差對活躍用戶數量的統計使用影響不大,這種場景下,我們可以使用 HyperLogLog 進行計數。HyperLogLog 是一種使用極少記憶體實現巨量統計的計數演算法,非常適合大數據場景的基數估計,在 Redis 中被實現為一種數據類型。
3.1HyperLogLog 原理介紹
3.1.1從伯努利試驗到基數計數
HyperLogLog 是一種基數估計演算法,其思想來自於伯努利過程。
簡單來說,伯努利過程就是一個拋硬幣的過程。拋一次硬幣,結果為正面或者反面的概率都是1/2。記正面為1,反面為0,如果拋硬幣多次,直到出現第一次正面時停止,記為一次投擲試驗,並且得到一個投擲結果的序列,比如「001」,我們可以知道,這個序列出現的概率是 。
反過來,如果我們持續進行投擲試驗,當出現第一次「001」序列時,我們可以簡單估算出,我們投擲試驗次數為8(事實上,這是一個極大似然估計)。

HyperLogLog 的原理就是將每個元素視為一次投擲試驗,通過記錄試驗的最大投擲次數對元素的數量進行估計。當我們向集合中每插入一個元素,視為做了一次投擲試驗,相同的元素對應一個投擲結果的序列。為了將每一個元素轉化成一個「01」序列,我們可以使用一個哈希函數進行轉換:
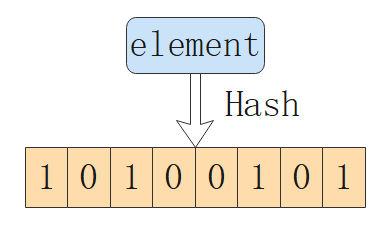
這裡,我們有了一個簡單的估計演算法。我們只需要記錄哈希結果中第一個「1」出現的位置的最大值即可,但很明顯,當數據量較小時,這樣一個估計值誤差會很大,而且單個元素的對估計值的影響不平滑。
3.1.2分桶平均減小誤差
為了減小單一估計量的影響,HyperLogLog 使用分桶多次試驗的方法減小誤差。方法是將哈希後的bitmap中前若干位當成桶的編號,剩餘位當成試驗結果。
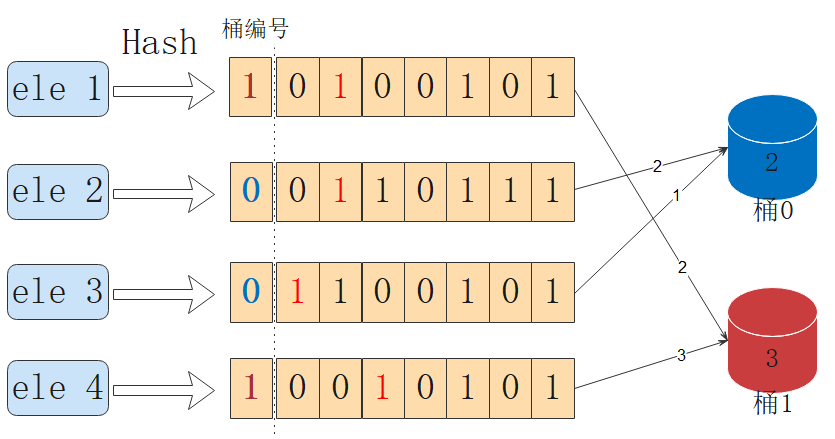
對於每個桶中的結果,計算其調和平均值獲取基數估計值(相比算術平均,調和平均數能夠有效改善基數較小情況下極值影響過大的問題):
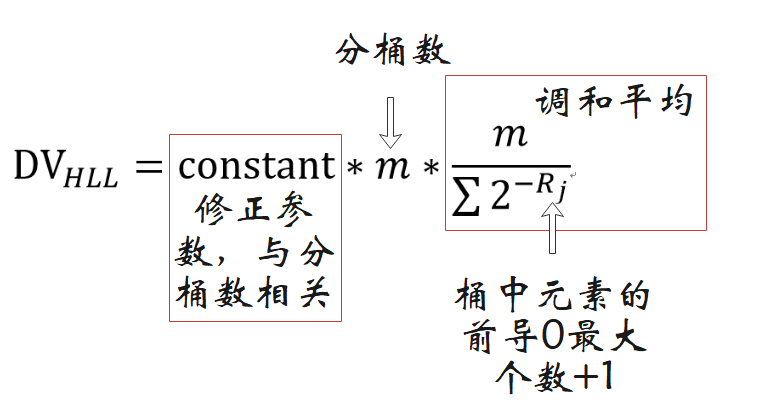
3.2Redis 中的 HyperLogLog
Redis 將HyperLogLog 實現成一種數據類型,對於每個元素,Redis將其Hash成64位的二進位串,用低14位用來表示bucket的下標(所以桶的個數為1<<14=16384),剩餘的位用來模擬伯努利分布,每個桶需要6個bit;最多能夠對 個元素進行統計,記憶體佔用約12 k;其標準誤差為 0.81%。
Redis 支援的 HyperLogLog 命令只有3個,pfadd,pfcoun,pfmerge, 其語法如下:
- pfadd:將所有元素參數添加到 HyperLogLog 數據結構中
語法:PFADD key element1 [element2…]
如果至少有一個元素被添加返回1,否則返回0
如果沒有指定 element,則創建 hyperloglog key
127.0.0.1:6379> pfadd key1 ele1 ele2 (integer) 1 127.0.0.1:6379> pfadd key1 (integer) 0 127.0.0.1:6379> pfadd key2 (integer) 0
- pfcount:返回給定的HyperLogLog的基數估計值
語法:PFCOUNT key1 [key2 … ]
返回對應 HyperLogLog 的基數值,多個key時,返回多個key的合併後的基數值。
127.0.0.1:6379> pfcount key1 (integer) 0 127.0.0.1:6379> pfadd key1 ele1 ele2 (integer) 1 127.0.0.1:6379> pfadd key2 ele1 ele3 (integer) 1 127.0.0.1:6379> pfcount key1 (integer) 2 127.0.0.1:6379> pfcount key1 key2 (integer) 3
- pfmerge:將多個 HyperLogLog 合併為一個
語法:PFMERGE destkey sourcekey1 [sourcekey2 …]
將 sourcekey 與 destkey 合併,當 destkey 不存在時,會創建 destkey
返回OK
127.0.0.1:6379> pfadd key1 ele1 ele2 (integer) 1 127.0.0.1:6379> pfadd key2 ele1 ele3 (integer) 1 127.0.0.1:6379> pfcount key3 (integer) 0 127.0.0.1:6379> pfmerge key3 key1 key2 OK 127.0.0.1:6379> pfcount key3 (integer) 3
3.3HyperLogLog 的適用場景
HyperLogLog 作為一種計算大數據量的基數統計演算法,在統計註冊用戶數,每日訪問IP數,實時統計在線用戶數等場景可以大顯神威。
- 統計網站的UV(unique visitor)
對於一個網頁,我們想要知道這個網頁的受關注程度,可以統計一下有多少用戶(IP)點擊了這個網頁。為此,我們給每個時間段設置一條記錄,比如,127.0.0.1這個IP在2021年1月1日1點的時候訪問了網頁:
pfadd key_prefix_2021010101 "127.0.0.1"
當需要統計這一天0-1點這一個小時一共有多少IP訪問了這個網頁時:
pfcount key_prefix_2021010101
需要統計上午8到12點的網頁訪問情況:
pfcount key_prefix_2021010109 …… key_prefix_2021010112
一天結束了,需要統計並保存這一天訪問情況:
pfmerge key_prefix_2021010101 ...... key_prefix_2021010124
對於一個熱門的網頁,這樣一個計數的方式顯然能夠極大的節約存儲空間。
- 用戶畫像
用戶畫像是根據用戶在互聯網上留下的各種數據,給用戶貼上一系列的標籤,比如用戶的性別,年齡,愛好等。在進行數據分析時,可以使用 HyperLogLog 進行數據的保存與分析。
1. 對於每個標籤,創建hyperloglog key值保存數據,如:man, woman, basketball…等,對於每個需要記錄的值,都需要創建一個key進行記錄。
2. 每多一個用戶時,向所有記錄的key里使用pfadd 添加元素。
3. 進行數據分析時,使用 pfcount 將需要分析的數據進行統計。
四、高斯Redis在計數上的優勢
4.1開源 Redis 的問題
生產環境中,為避免單點故障,增強資料庫可用性,Redis 通常將數據複製多個副本,保存在不同的伺服器上;在大量並發請求過來時,為了儘可能利用主從節點的伺服器資源,可以採用主寫從讀的方式。由於 Redis 的主從同步是非同步的,當主節點寫入數據後,從節點不保證立刻更新數據,如果此時讀取數據,讀到的就是過期的舊數據,產生數據不一致問題。
當主節點故障宕機後,數據不一致的問題會更嚴重。主節點故障後,哨兵節點會將從節點提升為主,原主節點上堆積的數據 buffer 就徹底丟失了。在電商秒殺業務中,如果發生主節點複製buffer堆積,導致從節點與主節點的 counter 偏大很多,一旦此時主節點宕機,發生主備倒換後,容易導致流量壓力超出閾值,大量數據可能會將 MySQL 壓垮,導致系統不可用。
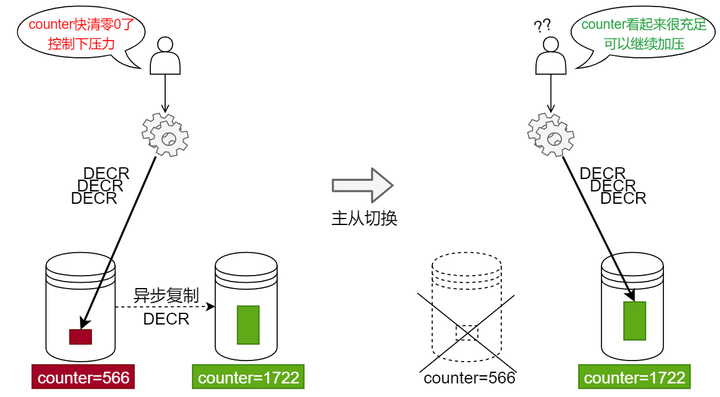
4.2高斯 Redis 如何解決
高斯 Redis 藉助高斯品牌的「存算分離」架構,將全量數據下沉到強一致存儲層(DFV Pool),徹底摒棄了開源 Redis 的非同步複製機制;計算層將海量數據進行分片,在故障場景下,自動進行接管,實現了服務的高可用。
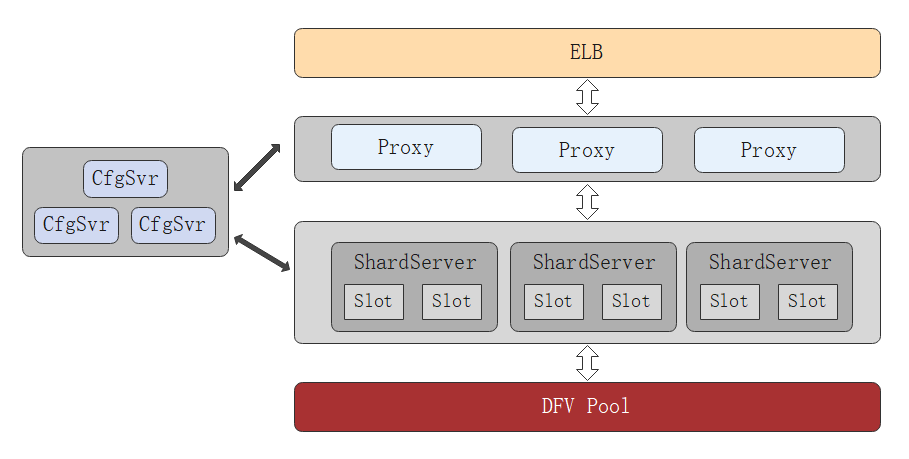
存儲層 DFV Pool 是華為內部自研的公司級Data Lake,是分散式、強一致、高性能的先進架構。底層實現3副本強一致的存儲,保證了在任何時間點的數據強一致,故障情況下數據不丟失,對於秒殺等業務滿足計數的絕對精確。此外,藉助存算分離架構,高斯Redis 還擁有低成本、大容量、秒擴容等優勢:
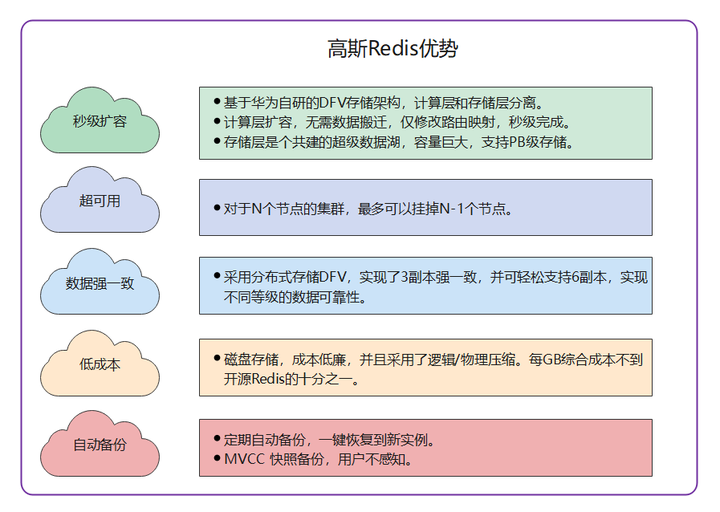
五、結語
高斯 Redis 在社區版 Redis 的基礎上,結合華為自研強一致存儲DFV Pool,具有強一致、秒擴容、超可用、低成本等優勢,保證了計數的準確性、可靠性。
本文作者:華為雲高斯Redis團隊。
杭州西安深圳簡歷投遞:[email protected]
更多技術文章,關注高斯Redis官方部落格://bbs.huaweicloud.com/community/usersnew/id_1614151726110813
六、參考資料
1.《Redis應用場景-計數器》
//blog.csdn.net/nklinsirui/article/details/106432298
2.《HyperLogLog 演算法的原理講解以及 Redis 是如何應用它的》
//juejin.cn/post/6844903785744056333
3.《五種常用基數估計演算法效果實驗及實踐建議》
//blog.codinglabs.org/articles/cardinality-estimate-exper.html
4.《【雲駐共創】從相識到相惜:Redis與計算存儲分離四部曲》
//bbs.huaweicloud.com/blogs/253041
5.《華為雲PB級資料庫GaussDB(for Redis)揭秘第七期:高斯Redis與強一致》
//bbs.huaweicloud.com/blogs/256888
本文分享自華為雲社區《華為雲PB級資料庫GaussDB(for Redis)揭秘第八期:用高斯 Redis 進行計數》,原文作者:心機胖。

