Kafka 消息存儲機制
Kafka 消息以 Partition 作為存儲單元,那麼在 Partition 內消息是以什麼樣的格式存儲的呢,如何處理 Partition 中的消息,又有哪些安全策略來保證消息不會丟失呢,這一篇我們一起看看這些問題。
Partition 文件存儲方式
每個 Topic 的消息被一個或者多個 Partition 進行管理,Partition 是一個有序的,不變的消息隊列,消息總是被追加到尾部。一個 Partition 不能被切分成多個散落在多個 broker 上或者多個磁碟上。
它作為消息管理名義上最大的管家內里其實是由很多的 Segment 文件組成。如果一個 Partition 是一個單個非常長的文件的話,那麼這個查找操作會非常慢並且容易出錯。為解決這個問題,Partition 又被劃分成多個 Segment 來組織數據。Segment 並不是終極存儲,在它的下面還有兩個組成部分:
- 索引文件:以 .index 後綴結尾,存儲當前數據文件的索引;
- 數據文件:以 .log 後綴結尾,存儲當前索引文件名對應的數據文件。
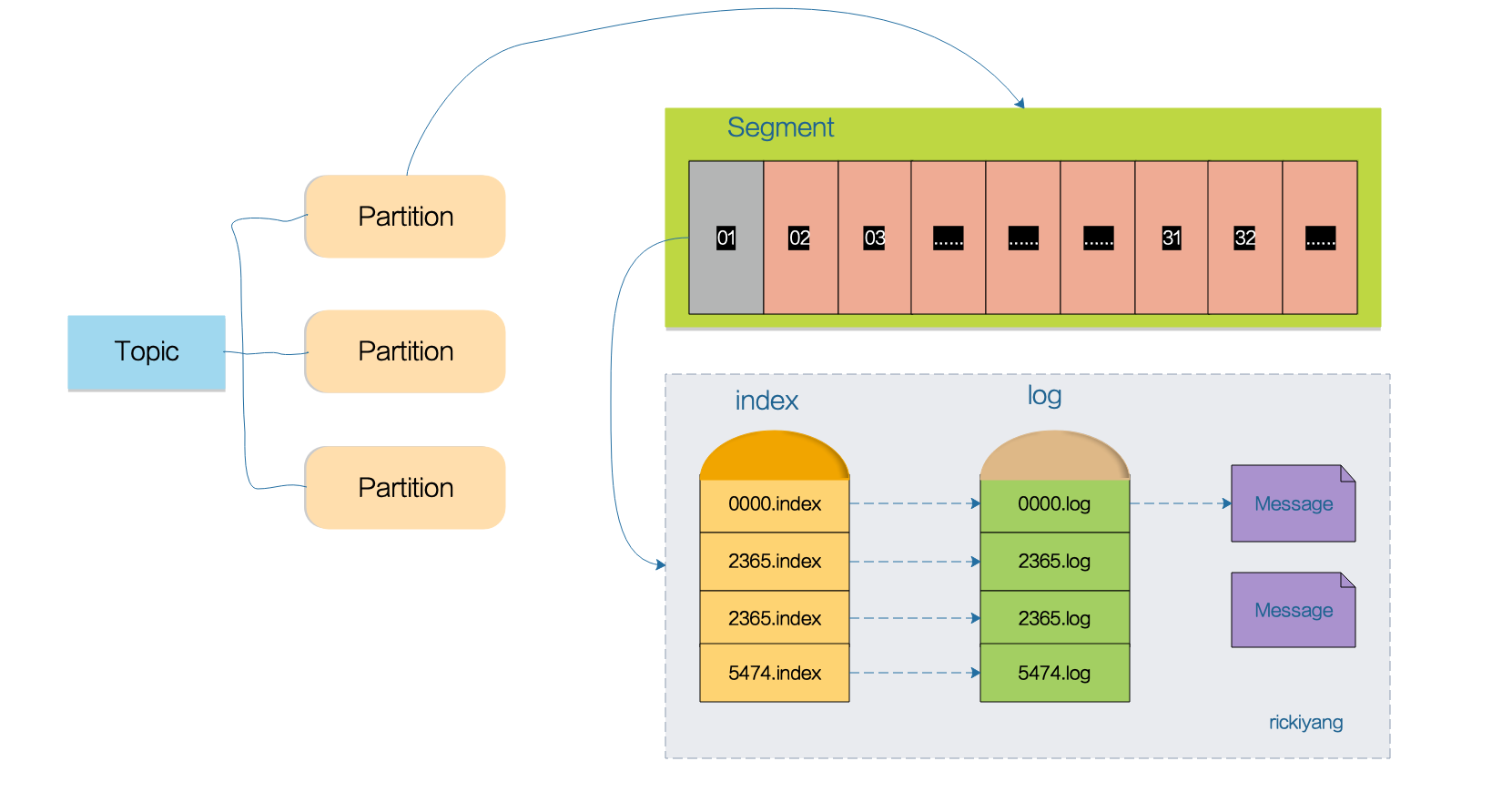
Segment 文件的命名規則是: 某個 Partition 全局的第一個 Segment 從 0 開始,後續每個 Segment 文件名以當前 Partition 的最大 offset(消息偏移量)為基準,文件名長度為 64 位 long 類型,19 位數字字元長度,不足部分用 0 填充。
如何通過 offset 找到 某一條消息呢?
- 首先會根據 offset 值去查找 Segment 中的 index 文件,因為 index 文件是以上個文件的最大 offset 偏移命名的所以可以通過二分法快速定位到索引文件。
- 找到索引文件後,索引文件中保存的是 offset 和對應的消息行在 log 日誌中的存儲行號,因為 Kafka 採用稀疏矩陣的方式來存儲索引資訊,並不是每一條索引都存儲,所以這裡只是查到文件中符合當前 offset 範圍的索引。
- 拿到 當前查到的範圍索引對應的行號之後再去對應的 log 文件中從 當前 Position 位置開始查找 offset 對應的消息,直到找到該 offset 為止。
每一條消息的組成內容有如下欄位:
offset: 4964(邏輯偏移量)
position: 75088(物理偏移量)
CreateTime: 1545203239308(創建時間)
isvalid: true(是否有效)
keysize: -1(鍵大小)
valuesize: 9(值大小)
magic: 2
compresscodec: NONE(壓縮編碼)
producerId: -1
producerEpoch: -1(epoch號)
sequence: -1(序號)
isTransactional: false(是否事務)
headerKeys: []
payload: message_0(消息的具體內容)
為什麼要設計 Partition 和 Segment 的存儲機制
Partition 是對外名義上的數據存儲,用戶理解數據都是順序存儲到 Partition 中。那麼實際在 Partition 內又多了一套不對用戶可見的 Segment 機制是為什麼呢?原因有兩個:
- 一個就是上面提到的如果使用單個 Partition 來管理數據,順序往 Partition 中累加寫勢必會造成單個 Partition 文件過大,查找和維護數據就變得非常困難。
- 另一個原因是 Kafka 消息記錄不是一直堆堆堆,默認是有日誌清除策略的。要麼是日誌超過設定的保存時間觸發清理邏輯,要麼就是 Topic 日誌文件超過閾值觸發清除邏輯,如果是一個大文件刪除是要鎖文件的這時候寫操作就不能進行。因此設置分段存儲對於清除策略來說也會變得更加簡單,只需刪除較早的日誌塊即可。
Partition 高可用機制
提起高可用我們大概猜到要做副本機制,多弄幾個備份肯定好。Kafka 也不例外提供了副本的概念(Replica),通過副本機制來實現冗餘備份。每個 Partition 可以設置多個副本,在副本集合中會存在一個 leader 的概念,所有的讀寫請求都是由 leader 來進行處理。剩餘副本都做為 follower,follower 會從 leader 同步消息日誌 。
常用的節點選舉演算法有 Raft 、Paxos、 Bully 等,根據業務的特點 Kafka 並沒有完全套用這些演算法,首先有如下概念:
- AR:分區中的所有副本統稱為 AR (Assigned Replicas)。
- ISR:in-sync replics,ISR 中存在的副本都是與 Leader 同步的副本,即 AR 中的副本不一定全部都在 ISR 中。ISR 中肯定包含當前 leader 副本。
- OSR:Outof-sync Replicas,既然 ISR 不包含未與 leader 副本同步的副本,那麼這些同步有延遲的副本放在哪裡呢?Kafka 提供了 OSR 的概念,同步有問題的副本以及新加入到 follower 的副本都會放在 OSR 中。AR = ISR + OSR。
- Hight Watermark:副本水位值,表示分區中最新一條已提交(Committed)的消息的 Offset。
- LEO:Log End Offset,Leader 中最新消息的 Offset。
- Committed Message:已提交消息,已經被所有 ISR 同步的消息。
- Lagging Message:沒有到達所有 ISR 同步的消息。
每個 Partition 都有唯一一個預寫日誌(write-ahead log),Producer 寫入的消息會先存入這裡。每一條消息都有唯一一個偏移量 offset,如果這條消息帶有 key, 就會根據 key hash 值進行路由到對應的 Partition,如果沒有指定 key 則根據隨機演算法路由到一個 Partition。
Partition leader 選舉
一個 Topic 的某個 Partition 如果有多副本機制存在,正常情況下只能有一個 副本是對外提供讀寫服務的,其餘副本從它這裡同步數據。那麼這個對外提供服務的 leader 是如何選舉出來的呢?這個問題要分為兩種情況,一種是 Kafka 首次啟動的選舉,另一種是啟動後遇到故障或者增刪副本之後的選舉。
首次啟動的選舉
當 broker 啟動後所有的 broker 都會去 zk 註冊,這時候第一個在 zk 註冊成功的 broker 會成為 leader,其餘的都是 follower,這個 broker leader 後續去執行 Partition leader 的選舉。
-
首先會從 zk 中讀取 Topic 每個分區的 ISR;
-
然後調用配置的分區選擇演算法來選擇分區 leader,這些演算法有不同的使用場景,broker 啟動,znode 發生變化,新產生節點,發生 rebalance 的時候等等。通過演算法選定一個分區作為 leader就確定了首次啟動選舉。
後續變化選舉
比如分區發生重分配的時候也會執行 leader 的選舉操作。這種情況會從重分配的 AR 列表中找到第一個存活的副本,且這個副本在目前的 ISR 列表中。
如果某個節點被優雅地關閉(也就是執行 ControlledShutdown )時,位於這個節點上的 leader 副本都會下線,所以與此對應的分區需要執行 leader 的選舉。這裡的具體操作為:從 AR 列表中找到第一個存活的副本,且這個副本在目前的 ISR 列表中,與此同時還要確保這個副本不處於正在被關閉的節點上。
Partition 副本同步機制
一旦 Partition 的 leader 確定後續的寫消息都會向這個副本請求操作,其餘副本都會同步它的數據。上面我們提到過幾個概念:AR 、ISR、 OSR,在副本同步的過程中會應用到這幾個隊列。
首先 ISR 隊列肯定包含當前的 leader 副本,也可能只有 leader 副本。什麼情況下其餘副本能夠進入到 ISR 隊列呢?
Kafka 提供了一個參數設置:rerplica.lag.time.max.ms=10000,這個參數表示 leader 副本能夠落後 flower 副本的最長時間間隔,當前默認值是 10 秒。就是說如果 leader 發現 flower 超過 10 秒沒有向它發起 fetch 請求,那麼 leader 就認為這個 flower 出了問題。如果 fetch 正常 leader 就認為該 Follower 副本與 Leader 是同步的,即使此時 Follower 副本中保存的消息明顯少於 Leader 副本中的消息。
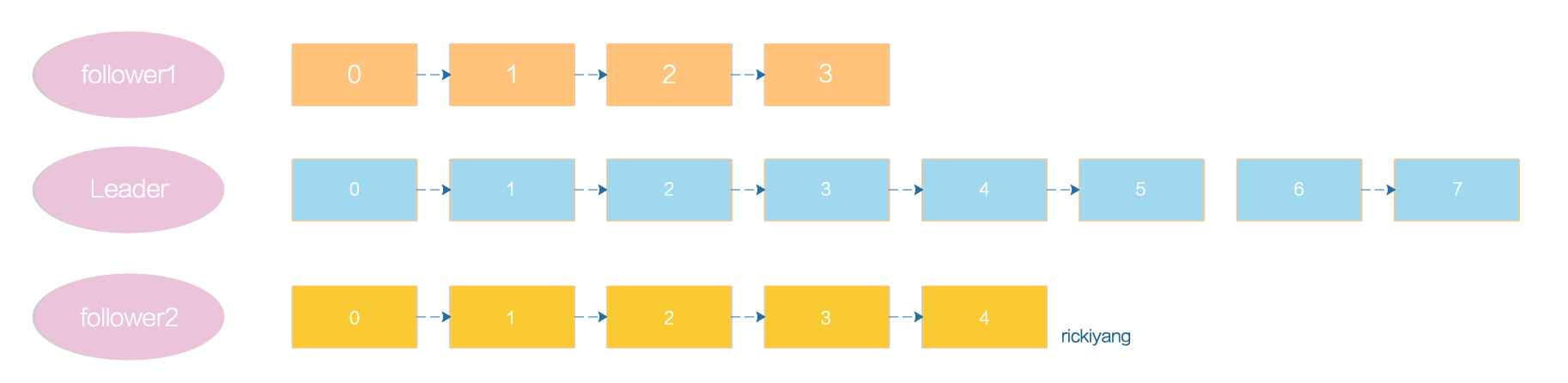
例如上圖中的兩個 follower 明顯慢於 leader,但是如果落後的時間在10 秒內,那麼這三個副本都會在 ISR 中存在,否則,落後的副本會被剔除並加入到 OSR。
當然如果後面 follower 逐漸追上了 leader 的進度,那麼該 follower 還是會被加入到 ISR,所以 ISR 並不是一個固定不變的集合,它是會動態調整的。
leader 和 follower 之間的數據同步過程大概如下:
初始狀態下 leader 和 follower 的 HW 和 LEO 都是 0,follower 會不斷地向 leader 發送請求 fetch 數據。但是因為沒有數據,這個請求會被 leader 強制拖住,直到到達我們配置的 replica.fetch.wait.max.ms 時間之後才會被釋放。同時如果在這段時間內有數據產生則直接返回數據。
Producer 提交 commit 確認機制
Producer 向某個 Topic 推過來一條消息,當前 Topic 的 leader Partition 進行相應,那麼如果其餘 follower 沒有同步成功消息會怎麼樣呢?這個問題 Kafka 交給用戶來決定。
producer 提供了如下配置:
request.required.asks=0
- 0:全非同步,無需 leader 確認成功立刻返回,發送即成功。
- 1:leader 接收到消息之後才發送 ack,無需 ISR 列表其他 follower 確認。
- -1:leader 和 ISR 列表中其他 follower 都確認接收之後才返回 ack,基本不會丟失消息(除非你的 ISR 裡面只有 leader 一個副本)。
可以看到以上確認機制配置逐級嚴格,生產環境綜合考慮一般選擇配置 = 1,如果你的業務對數據完整性要求比較高且可以接收數據處理速度稍慢那麼選擇 = 2。
offset 保存
某個消費組消費 partition 需要保存 offset 記錄當前消費位置,0.10 之前的版本是把 offset 保存到 zk 中,但是 zk 的寫性能不是很好,Kafka 採用的方案是 consumer 每分鐘上報一次,這樣就造成了重複消費的可能。
0.10 版本之後 Kafka 就 offset 的保存從 zk 剝離,保存到一個名為 consumer_offsets 的 Topic 中。消息的 key 由 [groupid、topic、partition] 組成,value 是偏移量 offset。Topic 配置的清理策略是compact。總是保留最新的 key,其餘刪掉。一般情況下,每個 key 的 offset 都是快取在記憶體中,查詢的時候不用遍歷 Partition,如果沒有快取第一次就會遍歷 Partition 建立快取然後查詢返回。



