【Azure 事件中心】EPH (EventProcessorHost) 消費端觀察到多次Shutdown,LeaseLost的error資訊,這是什麼情況呢?
- 2021 年 4 月 7 日
- 筆記
- 【Azure 事件中心】, EventProcessorHost, LeaseLost, Shutdown, 事件中心 Azure Event Hub
問題詳情
使用EPH獲取Event Hub數據時,多次出現連接shutdown和LeaseLost的error ,截取某一次的error log如:
|
Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ’29’, Reason: ‘LeaseLost‘. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ’26’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ‘1’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ’22’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ‘8’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ‘9’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ‘7’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ’31’, Reason: ‘LeaseLost’. Time:2021-03-10 08:43:48.4650|NE:VSDN|Machine:RD0003FF01A8BE|Lv:INFO|ActivityId:|Msg:CdmEventProcessor Shutting Down. Partition ’17’, Reason: ‘LeaseLost’ ….
|
如何解釋EPH的Shutting Down呢?為什麼出現LeaseLost(租約丟失)情況呢?
問題解釋
在Azure SDK Microsoft.Azure.EventHubs.Processor 的解釋中列舉出LeaseLost是The lease was lost or transitioned to a new processor instance,表示當前租約丟失,或者轉移到一個新的Processor實例上。
這是因為Event Hub可以設置多個分區,同時也可以通過多個消費端來消費分區中的數據,但是多少個客戶端是最好的呢?根據【Azure 事件中心的 .NET 編程指南】中對EPH(Event Processor Host)的介紹,客戶端主機將嘗試使用「貪婪」演算法獲取事件中心內每個分區上的租約,如果當前只有一個消費端連接Event Hub,則當前消費端會把所有分區的租約都獲取過去。當有2個或者多個消費端時,它們會自動在多個消費端中進行負載均衡,最終達到動態平衡
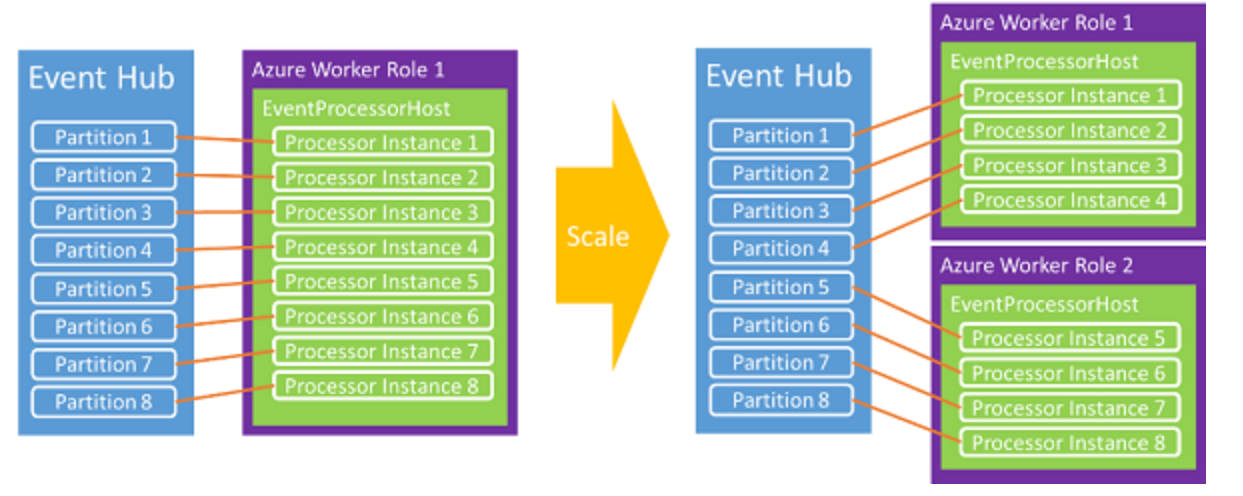
- 只有一個消費端時(Azure Worker Role 1),8個分區都與它建立租約。
- 當有第二個消費端時(Azure Worker Role 2), EPH就自動動態平衡分區數,最終表現為各自處理4個分區數據。
- 而原來與Worker Role 1相連的5,6,7,8分區就會出現shutdown,原因時leaselost的日誌記錄。
所以,我們觀察到的Shutdown LeaseLost日誌消息就是因為EPH在自動進行多個實例間分區數的動態平衡而產生的。這是完全正常的現象。
EPH出現LeaseLost的詳細分解
TLDR: This behavior is absolutely normal.
Why can’t Lease Management be smooth & exception-free: To give more control on the situation to developer.
The really long story – all-the-way from Basics
EventProcessorhost(herebyEPH– is very similar to what__consumer_offset topicdoes forKafka Consumers– partition ownership & checkpoint store) is written byMicrosoft Azure EventHubsteam themselves – to translate all of theEventHubs partition receiver Guinto a simpleonReceive(Events)callback.… …
譯文內容為:
TLDR: This behavior is absolutely normal. 這是正常的行為
為什麼不能讓Event Hub分區租約的管理不出現異常呢?這是為了更好地讓開發者來控制租約到期(Lease Lost)的情況。
這需要從EventProcessorHost(簡稱 EPH)從創建之時說起, EPH是由Microsoft Azure EventHubs團隊開發,用來把所有的EventHubs partition receiver事件轉換為一個簡單的回調事件 onReceive。這樣的目的是為了解決在讀取高吞吐量分區數據流的情況下的2個主要的,眾所周知的問題
1)容錯接收管道 (Fault tolerant receive pipe-line) – 如果運行PartitionReceiver的Host 宕機後恢復正常,則它需要從其宕機的地方繼續進行處理。 為了記住上一次成功處理的EventData,EPH使用提供給EPH構造函數的Blob來存儲檢查點(Checkpoints -調用context.CheckpointAsync()時)。 所以,當Host進程終止時(例如:突然重新啟動或遇到硬體故障,再也無法恢復),任何EPH實例都可以執行此任務並從該Checkpoint恢復。
2)在EPH實例之間動態分配分區 (Balance/distribute partitions across EPH instances) 假設有10個分區和2個EPH實例處理來自這10個分區的事件 – 需要一種在實例之間劃分分區的方法(PartitionManager組件)。 使用Azure存儲-Blob LeaseManagement功能來實現這一點。 從2.2.10版本開始 — 簡化為EPH假定所有分區均被載入。
基於以上的情況,我們來看一看EPH發生了什麼,首先, 在上面的10個事件中心分區和2個EPH實例的示例中,處理其中的事件順序如下:
一:假設第一個EPH實例(EPH1)最初是單獨啟動的,它為所有10個分區創建了接收器,並且開始處理事件。在啟動過程中 — EPH1將通過獲取代表這10個事件中心分區的租約(存儲Blob上)來宣布擁有所有這10個分區(EPH在存儲帳戶中內部創建-從StorageConnectionString中獲取Blob)。但是該租約旨在指定時間內有效,有效期過後,EPH1會失去對分區的所有權
二:通過更新Blob上的租約,EPH1會連續續訂這10個分區的租約。 續訂頻率以及其他有用的調整可以使用PartitionManagerOptions修改
三:啟動第二個EPH實例(EPH2), 並且使用與EPH1相同的StorageConnectionString。開始時,EPH2有0個分區要處理,為了要在EPH實例之間實現分區的動態平衡,EPH2將下載租約列表(包含分區ID與擁有者的映射關係)。並會平均的截取5個分區的租約。在整個過程中,EPH2會根據所獲取的分區資訊得到最新的檢查點(checkpoint),創建PartitionReceiver並繼續接收消息
四:最後,EPH1將失去對這5個分區的所有權,並將根據其分區的實時狀態而遇到不同的錯誤。
- 如果EPH1正在調用PartitionReceiver.Receive時,而且EPH2在同一分區創建PartitionReceive, EPH1就會遇見ReceiverDisconnectedException。並且調用EventProcessor.Close方法,Close Reason為LeaseLost
- 如果EPH1處於
checkpointing或renewing租約的狀態,而EPH2竊取了租約,則產生EventProcessorOptions.ExceptionReceived異常,eventHandler帶有leaselostException的訊號(409 conflict error)-最終也會調用IEventProcess.Close (LeaseLost)
為什麼不能讓Event Hub分區租約的管理不出現異常呢?(Why can’t Lease Management be smooth & exception-free)
為了使消費端簡單和無錯誤,EPH可以吞下與租約相關的異常,而不通過用戶程式碼的方式通知。 但是,我們意識到,拋出LeaseLostException可能使客戶能夠在IEventProcessor.ProcessEvents()回調中找到問題的根源 — 可能是頻繁進行分區移動造成
- 當消費端實例(EPH)發生輕微的網路抖動, 使得EPH無法續訂租約而重啟。如果這個實例的網路一直處於抖動情況,EPH將來來回回獲取Partitions資訊,同時不斷的嘗試從其他EPH中竊取租約。這將導致消費端無法處理正常的Event Hub事件。當發生這樣的情況時,可以在日誌中可見ReceiverDisconnectedException異常,這一點可以非常好的幫助開發者定位問題。
- 或是在ProcessEvents的邏輯程式碼中出現無法處理的異常,並導致整個進程被破壞,分區也會在多個EPH實例之間來回移動。
- 也有可能是在EPH中使用的儲存賬戶上有執行write/delete操作,與EPH實例執行的操作衝突等。
- 也有可能是Azure的數據中心發生大範圍的宕機事件(不希望這樣的情況發生),分區也會在多個EPH實例之間來回移動。
在大多數情況下,對於Event Hub SDK而言,要檢測以上這些異常是非常棘手的。 所以SDK團隊將控制權委託給開發者,開發者通過拋出的異常來定位問題。
參考資料
CloseReason Enum://docs.microsoft.com/en-us/dotnet/api/microsoft.azure.eventhubs.processor.closereason?view=azure-dotnet#fields
What is causing Azure Event Hubs ReceiverDisconnectedException/LeaseLostException? //stackoverflow.com/questions/41496754/what-is-causing-azure-event-hubs-receiverdisconnectedexception-leaselostexceptio
Event Hub事件使用者://docs.azure.cn/zh-cn/event-hubs/event-hubs-programming-guide#event-consumers


