多任務學習之深度學習部分
- 2021 年 4 月 6 日
- AI
醉了,看了兩篇寫的亂起八糟的綜述,在大佬的文章中找到一篇靠譜的,架構清晰的了。。。佛了,浪費這麼多時間,算了。。當作擴充一下知識吧。。

終於看到一個比較清晰的結構圖了。。。
下面是一些零散的知識點:
0、多任務學習的靈感以及和其它XX學習的關係
多任務學習比單任務學習能夠更加準確地反映了人類的學習過程,因為跨領域集成知識是人類很自然而然的學習方式。當新生嬰兒學會走路或使用手時,它會積累一般的運動技巧,這些技巧依賴於平衡的抽象概念和直觀的物理原理。一旦掌握了這些運動技能和抽象概念,就可以在生活中將它們重複使用和擴充,以完成日後更複雜的任務,例如騎自行車或走鋼絲。每當人們嘗試學習新事物時,我們都會將大量的先驗知識結合進來。難怪神經網路需要如此眾多的訓練樣本和計算時間:每一項任務都是從頭開始學習的。想像一下在不先學習走路的情況下嘗試學習走鋼絲!人類以很少的樣本快速學習的能力取決於這種學習概念的過程,這些概念可在多種環境中推廣並利用這些概念進行快速學習。我們認致力於模仿人類的這種學習過程的系統主要集中在
多任務學習以及元學習(multi task learning and meta learning)的相關領域(Hospedales等,2020),
遷移學習(transfer learning)(Zhuang等,2019)和
終身學習(life long learning).
然而,學習多個任務的確實帶來了相對於只學習單個任務學習所沒有的困難, 特別是在不同的任務有衝突的情況下。 在這種情況下,提高模型在一項任務上的性能會損害具有不同目標的其它的任務的性能,這種現象稱為負遷移。 最小化負遷移是MTL方法的主要目標。 許多體系結構設計有特定的功能以減少負向遷移,例如特定於任務的特徵空間和注意力機制,但是任務之間的資訊劃分是一條很好的路線:我們希望允許任務之間的資訊流產生正向轉移,並且 不鼓勵分享會造成負面轉移。 MTL研究中正在積極研究如何精確設計這種系統的問題。
1、multi task learning=joint learning,=learning to learn=learning with auxiliary tasks
同一個東西的不同說法;
2、看loss損失函數,有多個項就是多任務學習,特別的,L1或L2正則化也可以看作一種簡單的多任務學習,這個任務的目標是盡量讓參數小並且不同參數保持在大致相同的量綱里,小參數穩定;
3、為啥用多任務:
(1)方便,不用一個任務一個model,一個model做所有任務
(2)提升泛化能力,
多任務的loss是多個loss的求和,這個求和可以是加權的也可以是其它的方式(這涉及到多目標優化,多目標優化不僅局限於多任務學習中的多個loss的權衡,多任務學習中多個loss的設計往往依賴於多目標優化中的一些理論和方法,二者關係是這樣的),這樣看來和加入正則項的形式很類似:

你看這個loss,是不是很像一個雙任務學習的問題的形式。
所以,多任務在多個任務之間相關的時候,可以提高模型的泛化能力,這個提高泛化能力的說法有很多,不過我覺得從L1和L2正則化的角度考慮更好理解,簡單來說就是引入了一些先驗知識,並且這個先驗知識對於model訓練來說效果很不錯,比如l1正則化強制讓model認為他的參數應該滿足拉普拉斯分布(至於讓參數滿足拉普拉斯分布是不是真的對下游任務能產生積極的效果,暫時沒看到什麼嚴謹地推導結果),多任務也是通過在loss中增加其它的loss從而引入先驗知識,至於怎麼引入好的輔助任務,靠人的經驗(比如後bert時代,預訓練任務的各種組合,nsp+mlm,sop+mlm,這個我們完全可以自己靈活的定義,甚至可以mlm+sop+下游的文本分類、文本匹配任務等等);
5、關於為啥MTL能夠提升泛化能力的問題
(1)、隱式/顯式數據增強
對於A任務,某些數據樣本可能是雜訊,則A任務訓練的時候這些雜訊樣本起不到什麼作用,
這裡用雜訊來指代這類樣本感覺有點偏頗,我覺得更好的說法是對任務loss的優化貢獻度不高的樣本更恰當一些。
比如lightgbm中的goss tree或者是focal loss,前者刪除當前任務中的小梯度樣本,更快更好更迅速的收斂,但是這些小梯度樣本可能在B任務中就不是小梯度的,這種處理方式隱式得減少了訓練樣本的數量,
後者,focol loss會對貢獻度不高的樣本降權,當權重特別小的時候,對應的樣本其實也等同於被刪除了,但是對另外一個任務這種樣本可能就比較重要了。
除此之外,我覺得也會有顯式的數據增強,例如nsp和mlm任務,雖然使用的是同一個語料,但是這兩個任務實際上需要分別對原始數據進行兩次改造,一次改造是對原始數據進行mask處理來對應mlm任務需要的input的數據形式,一次改造是直接以句子為單位改造成正負樣本對,所以其實類似於對input進行改造從而得到更多類型的input。這個我在實現nsp+mlm任務的時候發現有這個問題,一個樣本最終要拆成兩種樣本形式進入model去train。
(2)、幫模型注意更重要的特徵
如果一個任務非常困難或數據有限,同時數據高維太高,那麼一個模型可能很難區分相關的特徵和不相關的特徵。MTL可以幫助模型將注意力集中在那些實際上很重要的特徵上,因為其他任務將為這些特徵的相關性或不相關性提供額外的證據(這建立在多個任務對應的最好的特徵大致相同的前提下)。
(3)、Eavesdropping
這個詞翻譯過來叫竊聽。。感覺怪怪的。某些特徵在A任務上難以學習,可能A對標的loss無法有效地利用這種特徵,但在另一個任務B上就很好學習,任務B可以更好地把這些特徵represent出來,舉個不嚴謹地例子,比如組隊打比賽,我對nlp熟悉,另一個隊友對graph熟悉,那麼他把GNN的model做好了提供一個輸出的api,我直接用這個GNn的網路結構拼上nlp的一些網路結構一起輸出來更好地完成任務
(4)、更大的假設空間
比如說對任務A來說,nn的適合的參數解可能就在某個固定的高維空間中的一塊超立方體里,對於任務B來說,可能在另外一個立方體里,MTL迫使model在更大的不同的超立方體里尋找最合適的參數解,這樣未來的新任務可能可以更好的讓model去學習,前提是這個新任務的合適的參數解也在這麼多超立方體構成的空間里。
(5)、正則化
前面說過了,不贅述。
深度學習中的兩種基本的multi task learning的實現
MTL的現有方法通常分為兩類:硬參數共享與軟參數共享。硬參數共享是在多個任務之間共享模型權重的實踐,以便訓練每個權重以共同最小化多個損失函數。在軟參數共享下,不同任務具有權重不同的特定於任務的單獨模型,但是將不同任務的模型參數之間的距離添加到聯合目標函數中。儘管沒有顯式的參數共享,但是激勵特定任務模型具有相似的參數。
這是早期的一個簡單清晰的分類方法,
如下

hard parameter share,這種最好實現,我們在輸出的時候加多個任務層就行,torch寫起來非常的方便快捷easy。

soft parameter sharing
這種實現起來也不複雜,不過會麻煩一點,首先根據n個不同任務獨立構建n個結構相同的網路,然後對網路的參數進行限制,希望這些參數接近,這個時候,讓參數接近的問題就變成了一個計算distance的問題,我們可以計算不同子網路的相同層之間的歐幾里得距離,把這個距離作為損失函數放到loss里,比如cosineloss就是一種很經典的通過nn實現metric learning的例子,除此之外還有trace的方法,沒了解過,先放著。
但是在過去的幾年中,多任務方法的性質變得極為多樣化,我們認為僅這兩個類別還不夠廣泛,無法準確地描述整個領域。相反,我們擴大了此二分法的成員範圍,以涵蓋更多領域。我們將硬參數共享方法的類別概括為多任務體系結構,而軟參數共享則擴展為多任務優化。結合使用時,體系結構設計和優化技術可提供近乎完整的描述目前的多任務學習領域的體系結構。但是,領域內仍然存在一個重要的方向:任務關係學習。任務關係標記(或TRL)方法專註於學習任務之間關係的顯式表示形式,例如任務嵌入或transfer learning affinities,而這些類型的方法不太適合架構設計或優化。
最終,從廣義上講,這三個方向-多任務網路結構設計,多目標優化和多任務間的關係學習-構成了現代深度多任務學習的現有方法。考慮到多目標優化本身比較獨立,這裡主要介紹多任務網路結構設計和多任務間的關係學習,多目標優化部分獨立再整一篇。
多任務網路結構設計
MTL(多任務學習)的文獻中有很大一部分致力於多任務神經網路體系結構的設計。創建共享體系結構時,有許多不同的因素需要考慮,例如哪些參數共享哪些不共享,共享層和不共享層的輸出如何融合等等。當考慮針對特定問題領域的體系結構時,會出現更多變化,例如如何將卷積濾波器劃分為一組視覺任務的共享組和特定於任務的組。 MTL的許多提議體系結構在任務之間共享資訊的程度方面起到了平衡的作用:
共享過多會導致負效應,並且與每個任務的單個模型相比,聯合多任務模型的性能可能更差,而共享太少就不允許模型之間有效利用任務之間的資訊。 MTL的最佳性能體系結構是平衡良好共享的體系結構。
我們將MTL體系結構分為四類:
1 特定任務域的體系結構,對於單域架構,我們考慮電腦視覺,自然語言處理和強化學習領域。
2 多模態體系結構 多模態體系結構以多種模式處理輸入任務,例如使用電腦視覺結合自然語言處理進行視覺問答。應該注意的是,我們僅考慮處理多個任務的多模態體系結構(除此之外還有多模態單任務的體系結構(多模態也是一個很大的研究領域。。醉了算了還是先把當下的掌握好),比如下文的多源異構網路的圖就是一個典型的例子)。多模態的多任務學習結構應該是最好辨認的。
3 學習型體系結構,多任務架構搜索之類。
4 條件型體系結構,在條件體系架構中,用於給定數據段的架構取決於數據本身
下面按照不同領域進行了詳細的多任務學習的進展的介紹,第一個章節介紹了CV領域的多任務學習的發展,暫時跳過,以後 有機會研究cv再說,直接看nlp的發展部分比較熟悉一些看的有體會。
自然語言處理自然很適合MTL,因為存在大量相關問題,人們可以詢問給定的一段文本以及與任務無關的表示形式,而現代NLP技術中經常使用這種形式。近年來,用於NLP的神經體系結構已經歷了階段性發展,傳統的前饋體系已發展成為遞歸模型,而遞歸模型則通過基於注意力的體系結構來實現。這些網路基本layer的發展同時也反映了這些用於MTL的NLP體系結構的應用的發展。
xx注意,許多NLP技術可以視為多任務,因為它們構建了與任務無關的通用表示形式(例如單詞嵌入),並且在這種解釋下,對多任務NLP的討論將包括大量眾所周知的一般NLP技術。在這裡,出於實用性考慮,我們將討論限制在大多數情況下,包括同時顯式學習多個任務的技術,以同時執行這些任務為最終目標。
首先是
特定任務域的體系結構特定任務域的體系結構特定任務域的體系結構特定任務域的體系結構特定任務域的體系結構特定任務域的體系結構特定任務域的體系結構
1、共享embedding層

這些架構中的許多架構在結構上與早期的電腦視覺共享架構相似:共享的全局特徵提取器,然後是特定於任務的輸出分支。 但是,在這種情況下,共享層是embedding層。
這種架構方式的網路結構的其餘部分是特定於任務的,包括卷積,max over time,完全連接層以及softmax輸出。這項開創性的工作(Collobert等,2011)是受MTL的一般原則推動的:跨任務共享的表示形式可以更好地進行泛化,這種方式屬於典型的 特定任務域的體系結構。
2、共享seq2seq
用於NLP的現代遞歸神經網路的引入,產生了多任務NLP的新模型家族,並引入了新穎的遞歸架構(Luong等人,2015; Liu等人,2016a,b; Dong等人,2015 )。序列到序列學習(seq2seq)(Sutskever et al。,2014)被改編為(Luong et al。,2015)中的多任務學習。在這項工作中,作者探索了用於多任務seq2seq模型的參數共享方案的三種變體,他們將它們命名為一對多,多對一和多對多。在一對多的情況下,編碼器在所有任務中都是共享的,而解碼器則是特定於任務的。這對於處理需要不同格式輸出的任務集很有用,例如將一段文本翻譯成多種目標語言。在多對一中,編碼器是特定於任務的,而解碼器是共享的。這是對常規參數共享方案的顛倒,在常規方案中,較早的層被共享並饋送到特定於任務的分支中。當任務集需要以相同格式輸出時(例如,影像字幕和將機器翻譯成相同的目標語言),可以使用多對一變體。最後,作者探索了多對多變體,其中有多個共享的或特定於任務的編碼器和解碼器。他們使用這種變體,例如,使用英語和德語編碼器和解碼器共同訓練英語到德語和德語到英語翻譯系統。英文編碼器也輸入到英文解碼器中,以執行自動編碼器重構任務,德語編碼器也是如此。在(Dong et al。,2015)中提出了與機器翻譯的序列架構相似的序列,重點是訓練多任務網路將一種源語言翻譯成多種目標語言。上述的seq2seq中的encoder和decoder的共享也是屬於 特定任務域的體系結構。
(Liu et al。,2016a)還探索了遞歸多任務架構的幾種變體,重點是允許任務之間資訊流動的不同機制。作者探索了三種參數共享方案:統一層,耦合層和共享層體系結構,如圖7所示。這種看起來屬於學習型體系結構(學習型體系結構在體系結構學習的各個步驟之間是固定的,因此對來自同一任務的每個輸入執行相同的計算)。
第一種方法,統一層的參數共享:

在統一層共享體系結構中,每個任務都有其自己的嵌入層,並且所有任務共享一個LSTM層。
這種不是embedding共享,而是LSTM進行共享,和上面提到的seq2seq中的encoder或decoder共享的機制類似。
第二種方法,耦合層模型的共享:
對於耦合層模型,每個任務都有自己的單獨LSTM層,但是每個任務都可以從其他任務的LSTM層讀取資訊。更具體地說,修改給定任務在時間步t的LSTM的存儲內容,以包括每個任務在時間步t 的LSTM層的隱藏狀態的加權總和,同時保留LSTM的所有其他組件。

第三種方法:共享層的共享
最後,共享層體系結構為每個任務分配一個單獨的LSTM層,以及一個饋送給特定於任務的LSTM的共享雙向LSTM層。

簡單來看,embedding層不共享,中間的複雜模型層進行不同程度的共享。
資訊級聯
到目前為止,在我們討論的所有NLP體系結構中,與每個任務相對應的子體系結構都是對稱的。特別是,每個任務的輸出分支出現在每個任務的最大網路深度處。一些工作(Søgaard和Goldberg,2016年; Hashimoto等人,2016年; Sanh等人,2019年)建議在較早的層上直接對接任務層,以便這些低級任務學習到的feature可以被較高級別的任務使用。通過這樣做,我們形成了一個明確的任務層次結構,並為一個任務中的資訊提供了直接的方法,以幫助另一任務的解決方案,我們將此迭代迭代和特徵組合的模板稱為級聯資訊,如圖所示。

(Søgaard和Goldberg,2016年)通過選擇POS標記作為底層任務來給語法分塊任務和CCG超級標記任務層輸送有價值的represent,從而形成了這種層次結構。他們的網路體系結構由一系列雙向RNN層組成,對於每個任務i,都有一個相關的層「 i」,任務i的任務特定分類器從該層中派生。在這種情況下,用於POS標記的關聯層比語法分塊和CCG超級標記的關聯層在網路中出現得更早,因此,學習到的POS feature可以用於語法分塊和CCG超級標記的任務。在(Søgaard和Goldberg,2016)發表後不久(Hashimoto et al。,2016)通過構建具有5個任務的類似監督架構,在幾種語言任務上實現了SOTA的結果合:POS標記,分塊,依賴項解析,語義相關性和文本含義。作者還用雙向LSTM單元替換了雙向RNN單元(Søgaard和Goldberg,2016年)。圖8顯示了它們的體系結構。
除了增加任務數量之外,此方法還引入了一個正則項,以避免訓練任務之間的干擾。每次取樣任務的數據集進行訓練時,更新前參數與當前模型參數之間的平方歐幾里得距離就會添加到損失函數中。這鼓勵網路參數不要偏離參數配置,該參數配置是通過訓練上一個時期的不同任務來學習的。
在這兩部著作發表之後(Sanh等人,2019),我們針對不同的任務集引入了類似啟發的模型,從而實現了命名實體識別,實體提及檢測和關係提取的SOTA結果。按照從低到高的順序,這項工作中的任務層次是NER,EMD和coreference resolution/relation extraction(均排在最高級別)。
對抗特徵分離
在對抗性方法的一種新穎應用中,(Liu等人,2017)引入了一種用於多任務學習的對抗性學習框架,以將學習到的特徵提煉成特定於任務和與任務無關的子空間。它們的體系結構由一個共享的LSTM層和每個任務對應的一個特定於任務的LSTM層組成。一旦來自任務的輸入語句通過共享的LSTM層和特定於任務的LSTM層,則將兩個輸出連接起來,並用作執行推理的最終特徵。但是,由共享LSTM層產生的representation也將被饋送到任務鑒別器中。任務層是一個簡單的線性變換層,後跟一個softmax層,該層經過訓練可以預測原始輸入語句來自哪個任務。然後,對共享LSTM層進行訓練,以共同最小化任務損失和鑒別符損失,從而使共享LSTM產生的功能不包含任何特定於任務的資訊。此外,鼓勵使用共享特徵和特定於任務的特徵對結果特徵使用正交性懲罰(類似於(Ruder等人,2019))對單獨的資訊進行編碼。更具體地說,正交性損失定義為特定任務特徵和共享特徵的乘積的平方Frobenius範數。為了鼓勵特定於任務的和共享的特徵相互正交,此損失被添加到總體訓練目標中。這兩個輔助損失迫使共享網路中的特定於任務的資訊和與不可知任務的資訊分離。(沒有圖,看不出來)
BERT for MTL
文中就提到了MTDNN,
//zhuanlan.zhihu.com/p/48612853
關於MTDNN的介紹可見這篇。
多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構多模態體系結構
Multi-Modal Architectures
前面我們討論了專門設計用於在一個特定任務域中處理數據的多任務體系結構。在這裡,我們描述了使用來自多個域的數據(通常是視覺和語言數據的某種組合)來處理多個任務的體系結構。多模態學習是多任務學習的有趣擴展:跨域共享表示可減少過擬合併提高數據效率。在多任務單模態情況下,represent是跨任務共享的,但是,在多任務多模態的情況下,represent是跨任務和跨模態共享的,從而提供了另一個抽象層,通過該抽象層,必須對學習的represent進行概括。這表明,多任務多模式學習可能會增加多任務學習已經展現出的收益。
(Nguyen和Okatani,2019年)通過使用密集的共同注意層(Nguyen和Okatani,2018年)介紹了用於共享視覺和語言任務的體系結構(Nguyen和Okatani,2018年),其中將任務組織為層次結構,並在早期的層中監督低級任務網路(意思是低級任務網路直接上任務層完成任務)。開發了密集的共同注意層,用於視覺問題解答,特別是用於視覺和語言資訊的集成。任務監督的這種設置類似於上文中討論的級聯資訊體系結構。但是,此方法不是手動設計任務的層次結構,而是執行在每個任務的層上搜索以了解任務層次。 (Akhtar et al。,2019)的體系結構使用雙向GRU層以及成對注意機製為每對模式提供學習,從而處理視覺,音頻和文本輸入以對人類說話者的影片中的情感和情感進行分類包含所有輸入模式的共享表示。
兩者(Nguyen和Okatani,2019年; Akhtar等人,2019年)都專註於一組任務,這些任務都共享相同的固定模式集。相反,(Kaiser等人,2017)和(Pramanik等人,2019)專註於構建「通用多模態多任務模型」,其中單個模型可以處理具有不同輸入域的多個任務。引入(Kaiser等,2017)的系統由輸入編碼器,I / O混合器和自回歸解碼器組成,這三個模組分別由卷積,關注層和稀疏混合的混合組成,作者還證明了任務之間的高度共享可以顯著提高訓練數據有限的任務的性能。而不是匯總來自各種深度學習模式的機制,(Pramanik et al。,2019)引入了一種架構稱為OmniNet,它具有時空快取機制,可以學習數據在空間和時間維度上的依存關係,如圖12所示。每個輸入模態都有一個對應的「外圍」網路,這些網路的輸出網路被匯總並饋入中央神經處理器,其輸出被饋送到特定於任務的輸出頭。 CNP具有帶有空間快取和時間快取的編碼器-解碼器體系結構。 OmniNet在POS標記,影像標題,視覺問題解答和影片活動識別方面達到了SOTA競爭性能。

最近,(Lu等人,2020年)引入了一種多任務模型,該模型可以同時處理12個不同的數據集,恰當地命名為12合1。。。。他們的模型在這些任務中的12個中有11個在性能上優於相應的單任務模型,並且使用多任務訓練作為預訓練步驟可以在其中7個任務上實現SOTA性能。該架構基於ViLBERT模型(Lu等人,2020),並使用諸如動態任務調度,課程學習和超參數啟發式等多種方法進行了訓練。
(多模態目前感覺發展勢頭很猛啊。。可以,是個很不錯很有意思的方向)
Learned Architectures(自動多任務框架學習)Learned Architectures(自動多任務框架學習)Learned Architectures(自動多任務框架學習)Learned Architectures(自動多任務框架學習)Learned Architectures(自動多任務框架學習)Learned Architectures(自動多任務框架學習)
正如我們在前面的部分中已經看到的那樣,共享體系結構的設計已經有了很多發展,以強調多任務學習的優點,同時減輕缺點。用於多任務學習的體系結構設計的另一種方法是學習體系結構以及所得模型的權重。以下許多用於學習共享體系結構的方法允許模型學習如何在任務之間共享參數。使用可變的參數共享方案,模型可以以類似的任務比不相關的任務具有更高的共享度的方式移動任務之間的重疊。這是減輕任務之間負效應的一種潛在方法:如果兩個任務呈現負向轉移,則模型可以學習將這些任務的參數分開。更進一步,可能情況是兩個任務在網路的某些部分呈現出正向轉移,而在其他部分呈現出負向轉移。在這種情況下,手動設計參數共享方案以適應網路不同部分的各種任務相似性變得不可行,尤其是隨著任務數量和網路規模的增長。經驗豐富的參數共享提供了一種方法,可以促進任務之間的自適應共享,其精確度對於手工設計的共享體系結構來說是不現實的。
我們將自動多任務框架學習的體系結構的方法大致分為四類:
體系結構搜索,
分支共享,
模組共享,
細粒度共享。
這些分類之間的界限不是具體的,而且常常模糊不清,但是我們認為這是一種有用的方法,可以廣泛地代表最近開發的方法中的模式。
體系結構搜索,
Wong和Gesmundo,2017年; Liang等人,2018年; Gao等人,2020年中的每一個都介紹了一種用於多任務架構搜索的方法,但是方法卻完全不同。 (Wong and Gesmundo,2017)引入了多任務神經模型搜索(MNMS)控制器。此方法不涉及在所有任務之間共享的單個網路。取而代之的是,在所有任務上同時訓練MNMS控制器,以為每個任務生成一個單獨的體系結構。該方法是(Zoph和Le,2016)的擴展,其中RNN控制器迭代地選擇架構設計,並通過強化學習進行訓練,以最大程度地提高最終網路的預期性能。在多任務變體中,RNN還使用任務嵌入(與MNMS控制器一起學習),以根據任務的性質來決定體系結構設計的選擇。
另一方面,(Liang等人,2018)介紹了多任務神經體系結構搜索演算法的幾種變體,該演算法使用進化策略來學習神經網路模組,這些神經網路模組可以針對各種任務進行不同的重新排序。該方法是(Meyerson和Miikkulainen,2017)中引入的軟層排序的擴展(在2.3.2節中進行了討論)。就像(Meyerson and Miikkulainen,2017)中一樣,(Liang et al。,2018)的方法涉及一起學習神經網路模組及其對各種任務的排序。在體系結構搜索擴展中,將學習模組的體系結構以及針對單個任務的路由。該演算法最複雜的變種稱為模組和任務路由的協同進化(CMTR),其中CoDeepNEAT演算法(Miikkulainen等人,2019)用於在外部循環中演化共享組模組的體系結構,這些模組的任務特定路由在一個內部循環中演化。
最近,(Gao等人,2020年)提出了MTL-NAS作為MTL中基於梯度的體系結構搜索的一種方法。搜索空間中的所有體系結構均由一組固定體系結構的單任務主幹網路組成,每個任務骨幹網一個,並且搜索過程在這些單任務網路的不同層之間的特徵融合操作上進行操作。特徵融合操作由NDDR(來自NDDR-CNN(Gao等人,2019),參見2.1.2節)進行參數化,本質上是作用於來自不同任務的特徵圖串聯的1 1卷積。此方法還為融合操作的權重引入了最小熵目標,從而使搜索過程在體系結構搜索階段收斂到離散體系結構,從而減少了對離散化體系結構組合的需求,就像在其他NAS工作中一樣(Liu et al。,2018)並縮小了學習的軟架構和最終離散化版本之間的性能差距。在NYU-v2(Silberman et al。,2012)和Taskonomy(Zamir et al。,2018)數據集上,最終學習的體系結構表現出優於常見的多任務基準。
分支共享方法是在任務之間共享參數的粗粒度方法。一旦兩個任務的計算圖不同,它們就永遠不會重新結合(見圖13)。
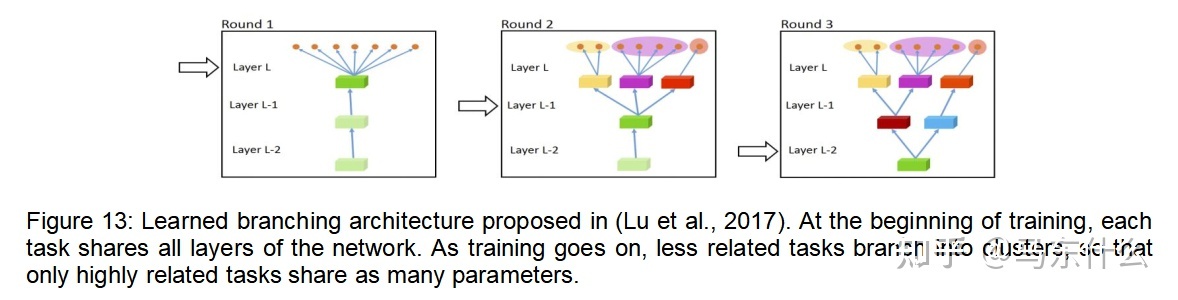
(Lu et al。,2017)是多任務深度學習中分支共享方法的最早方法之一。這個想法是從一個網路開始的,該網路在所有任務之間共享,直到特定於任務的輸出頭為止,然後從最靠近輸出頭的那一層開始,逐層迭代地分離任務之間的參數,並移動到較早的層。此過程的示意圖如圖13所示。當共享層拆分為多個特定於任務的層時,將基於成對任務親緣關係的估計來對任務進行聚類。這些任務親和力是根據以下原理計算的:如果對於每個任務對應的模型,相同的輸入數據同樣容易/困難,則兩個任務很可能相關。
最近,(Vandenhende et al。,2019)提出了一種類似的方法,但具有不同的任務分組標準。代替並發樣本難度,此演算法使用表示相似度分析(RSA)(Kriegeskorte,2008)作為任務相似度的度量。 RSA建立在以下原則上:相似的任務將依賴於輸入的相似特徵,因此將學習相似的特徵表示。這些方法之間的另一個重要區別是(Vandenhende et al。,2019)全局計算分支結構,而不是逐層貪婪地計算分支結構。但是,對所有分支結構的搜索在計算上是昂貴的,因此作者採用beam search策略來根據網路不同部分中任務之間的表示相似性來計算分支結構。本文包括兩種方法的直接比較,並且基於RSA的變體被證明是更好的。在某些方法中還使用RSA來學習明確的任務關係,這在第4節中進行了討論。
模組共享代表了一種更細粒度的方法,其中在任務之間共享一組神經網路模組,其中每個任務的體系結構是由一些或所有模組的任務特定組合構成的,如圖16所示。

我們知道的最早在多任務學習中進行模組化參數共享的工作是PathNet(Fernando等人,2017)。

儘管不同的任務在較大的模型中具有不同的計算路徑,但PathNet模型是一個用於多個任務的大型神經網路。如圖14所示。每個任務的途徑都是通過錦標賽選擇遺傳演算法學習的,其中許多不同的候選途徑競爭並朝著更大網路的最佳子網路發展。儘管這種想法通常是籠統的,並且可以應用於各種環境,例如多任務學習和元學習,但是作者將這種模型部署為具有兩個強化學習任務的連續學習。在第一項任務的訓練中獲得的權重在第二項任務的訓練期間被固定,在此期間,通過網路的新途徑得以發展以完成手頭的任務。
軟層排序(Soft Layer Ordering)(Meyerson和Miikkulainen,2017年)和模組化元學習(Alet等人,2018年)是模組化MTL的兩個並行工作,相似但有重要區別。這些方法中的每一種都學習一組共享的神經網路模組,這些神經網路模組以不同的方式組合用於不同的任務,希望如果在不同任務網路中的各種情況下使用網路「構建塊」,它們將學習普遍適用的知識。軟層排序通過計算網路每個層上每個模組的輸出的凸組合來對任務網路進行參數化,如圖15所示。

通過此參數化,每個學習到的模組都可以對網路中的每個深度級別做出貢獻。模組化元學習在模組上學習計算圖,這意味著計算的每個步驟都是少量模塊的離散組成,而不是所有模組的軟組合。這些方法導致了不同的優化策略,即可以使用梯度的來優化「soft layer order」體系結構中的計算圖。網路模組具有共同的意義,因為模組的組成是可區分的操作。相比之下,「模組化元學習」中的計算圖是離散結構,因此不能使用基於梯度的優化方法來學習每個任務的模組上的圖。相反,作者採用模擬退火(一種黑盒優化方法)來學習計算圖。雖然此兩級優化會產生計算成本,但計算圖的離散性質提供了在生成的模型中產生歸納偏差的能力,而層間的軟共享則不會表現出這種偏差。這些方法代表了許多其他方法已採用的廣泛通用模板的兩種實現:學習單個網路部分,並學習如何將它們組合在一起。
最細粒度的參數共享
最後,最細粒度的參數共享方法就是我們所謂的細粒度共享,其中共享決策發生在參數級別而不是層級別,如圖17所示。

細粒度參數共享方案是最近引入的MTL體系結構類型,與在層或多層級別共享相比,它們允許任務之間的資訊流更靈活。 Piggyback(Mallya et al。,2018)是一種通過學習掩蓋原始網路的各個權重來使預訓練網路適應相關任務的方法。這允許存儲新訓練的模型,而在保留原始網路功能的同時,每個原始模型參數的存儲成本僅為一個額外的位。儘管網路輸出相對於這些網路掩碼不可區分,但是通過使用掩碼值的連續鬆弛作為二進位掩碼值的雜訊估計,通過梯度下降與網路權重一起優化了這些網路掩碼。在二進位化神經網路的先前工作中,證明了這種優化掩碼值的方法是合理的(Courbariaux等人,2015)。
(Newell等人,2019)和(Bragman等人,2019)分別提出了兩個新的思路,它們各自為多任務CNN提出了一種參數共享方案,其中共享發生在卷積核級別。對於多任務網路的每個卷積層,(Newell等人,2019)的方法學習一個二進位值的NC數組M,其中N是任務數,C是給定層中的特徵通道數網路。 M的第(i; c)個元素表示第i個任務的模型是否應在考慮的層中包括第c個特徵圖。與其使用Gumbel-Softmax(Jang et al。,2016)分布優化此二進位值數組,作者並沒有直接學習這些值。相反,該方法學習大小為N N的實值矩陣P,其值在[0; 1],其中P的第(i; j)個元素表示特徵通道的比例,該特徵通道由任務i和任務j的模型共享。以這種方式,直接學習任務之間的關係,並且在計算每個新的P值之後,對滿足P = C1 MT M的數組M進行取樣。使用M進行此參數化後,就不會直接學習網路體系結構,而是對其進行取樣,以使學習到的任務相似度矩陣以指示任務參數之間的重疊量。該任務相似度矩陣P是通過演化策略學習的。 (Bragman et al。,2019)提出了隨機濾波器組(SFG),其中通過變分推理學習將卷積濾波器分配給特定任務或共享任務。更具體地說,通過學習卷積過濾器可能分配給特定任務或共享角色的後驗分布來訓練SFG。據我們所知,SFG是多任務體系結構學習的唯一概率方法。
Sun等人(2019a)引入了一種演算法,該演算法可通過提取單個完全共享模型的稀疏子網路來學習細粒度參數共享方案。作者從一個隨機初始化的,超參數化的網路中採用迭代幅度修剪(IMP)(Frankle and Carbin,2018),從較大的網路中為每個單獨的任務提取一個稀疏的子網路。 IMP通過訓練少量的時間段來修剪網路,然後刪除幅度最小的權重,直到達到所需的稀疏度。給定合理的稀疏度,為每個任務提取的子網將重疊,並且在任務之間表現出細粒度的參數共享。圖17中顯示了一個圖表。
重要的是要注意,兩個任務的提取子網之間的重疊程度不一定與這兩個任務的相關性相關,這表明需要一種細粒度的參數共享方案,該方案必須合併任務相關資訊以構建任務之間的適當共享機制。
2.5 Conditional Architectures
條件或自適應計算(Bengio et al。,2013)是一種方法,其中根據網路的輸入來選擇要執行的部分神經網路體系結構。 在多任務學習之外的許多領域都使用了條件計算,例如降低模型計算成本和分層強化學習(Kulkarni等人,2016)。 在多任務情況下,條件架構在輸入之間以及任務之間是動態的,
儘管這些動態實例化的體系結構的組件是共享的,但鼓勵這些組件在各種輸入和任務之間進行通用化。
神經模組網路(Andreas et al。,2016)是條件計算的早期工作,專門為視覺問題回答而設計。該方法利用自然語言中問題的組成結構來訓練和部署專門針對問題各個部分的模組。給定問題的結構由非神經語義解析器(特別是斯坦福解析器)確定(Klein和Manning,2003年)。解析器的輸出用於確定問題的組成部分以及它們之間的關係,相應的神經模組用於為給定問題動態實例化模型。此過程如圖18所示。

儘管這項工作為將來的條件計算方法鋪平了道路,但從某種意義上講,它是無法理解的,其構成是無法學習的。因此,每個模組和模組組合的作用是固定的,無法提高。
路由網路(Rosenbaum等人,2017)和組合遞歸學習器(CRL)(Chang等人,2018)是條件計算的最新相關工作,其中除模組權重外,還學習了模組他們自己的組成。路由網路由路由器和一組神經網路模組組成。給定一條輸入數據後,路由器會從網路模組集合中迭代選擇一個模組,以將其應用於固定的迭代次數。此過程如圖19所示。

路由器還可以選擇「通過」操作而不是模組,而只是繼續進行下一個路由迭代,可以直接通過反向傳播來學習模組權重,並且可以通過以下方法學習路由器權重:強化學習以最大程度地提高動態實例化網路在其輸入上的性能。(Chang等人,2018)的《 Compositional Recursive Learner》類似,但有一些關鍵區別。給定一個輸入數據,CRL也會迭代選擇一個網路模組中固定的一組模組(通過這些模組來路由輸入),對於CRL,有意將任何特定於任務的資訊(例如任務ID)從網路模組中隱藏起來,以確保模組學習與任務無關的資訊CRL還通過在課程上進行強化學習來進行培訓,以鼓勵重用在較簡單的問題上學習的模組。
(Ahn et al。,2019)引入了一種非常相似的架構,其中從較大的骨幹網中選擇配置和規模各異的層來路由輸入。再次對路由器(在此變體中稱為選擇器網路)進行強化學習訓練。
(Kirsch et al。,2018)的架構同樣受到路由網路和CRL的啟發,但採用的是本地路由而不是全局視圖。在「路由網路」和「 CRL」中,任何網路模組都可以放在任何深度的實例化網路中。相反,(Kirsch et al。,2018)提出了一種條件架構,其中僅在網路層內做出路由決策。該體系結構由一系列模組化層組成,每個層都有m個網路模組。當將一層應用於輸入時,輸入將通過控制器,該控制器從屬於該層的m個模組的集合中選擇k個模組。然後單獨輸入圖層輸入
通過選擇的k個模組中的每個模組,將結果相加或連接起來以形成該層的輸出。這些模組化層中的控制器不是通過強化學習而是通過變式方法來訓練的,其中模組的選擇被視為潛在變數。作者認為,與過去在條件計算上的工作相比,他們的模型在體系結構上的差異減少了模組崩潰的發生,而模組崩潰是眾所周知的條件模型的弱點。發生模組崩潰時,路由器僅從可用集中選擇少量模組,而其餘模組大部分仍未使用,因此生成的模型沒有模組化。
最近,軟模組化(Yang等,2020)是另一種條件方法,可以看作是路由網路的軟鬆弛。軟模組化使用由L層組成的路由器網路和策略網路,每個L層具有m個模組。代替路由網路那樣在每個計算步驟上做出離散決策並選擇一個模組,每個模組的輸入是前一層模組輸出的線性組合。具體而言,路由器網路將觀察值和相應的任務索引作為輸入,並輸出第一層之後每一層的線性組合權重的mm矩陣,以便權重的第i行和第j列中的元素層`的矩陣表示從層`到模組j的輸入中來自層`1的模組i的權重。路由網路的軟放鬆消除了對路由器與策略分開進行訓練的需要,而整個網路可以端到端地進行訓練。該體系結構還與軟層排序有關(Meyerson和Miikkulainen,2017年)(請參見2.3.2節),儘管使用軟模組化不會直接學習線性組合權重,而是由一個單獨的網路(路由器)動態計算得出的網路)。當與Soft Actor-Critic(Haarnoja等人,2018)結合使用時,根據Meta-World基準測試,Soft Modularization代理在MT50上的成功率達到60%(Yu等人,2019)。
可以在(Rosenbaum et al。,2019)和(Ramachandran and Le,2019)中找到基於路由的方法的優缺點的詳盡討論。
接下來是關於多目標優化的部分,這部分和我目前做的事情比較相關,所以打算單獨開篇詳細地研究一下,多任務深度學習部分了解個大概就好了
Task Relationship Learning
現在,我們已經討論了MTL體系結構和優化方法,從而完成了由硬參數共享和軟參數共享指定的流行二分法的更廣泛的類比。但是,這兩種方法的鮮為人知的第三個方向是:任務關係學習。任務關係學習(或TRL)是一種單獨的方法,既不適合架構設計也不適合優化,而是專門針對MTL的多任務的關係學習。 TRL的目標是學習任務或任務之間關係的顯式表示形式,例如通過相似性將任務分為幾類,並利用學習到的任務關係來改善對手頭任務的學習。
在本節中,我們討論TRL中的三個研究方向。第一個是對任務進行分組,其中的目標是將一組任務劃分為多個組,以便在組中同時進行任務訓練是有益的。第二種是學習轉移關係,其中包括嘗試分析和理解將知識從一項任務轉移到另一項任務對學習有益的方法。最後,我們討論了任務嵌入方法,該方法學習了任務本身的嵌入空間。
分組任務
作為對負遷移的一種解決方案,許多MTL方法旨在自適應地在相關任務之間共享資訊,並從可能會損害彼此學習的任務中分離資訊。此處使用任務分組作為替代解決方案:如果兩個任務表現出負遷移,則只需將其學習從一開始就分開即可。但是,這樣做需要花費大量的時間才能在訓練網路中針對各種任務集共同進行反覆試驗,並且目前很少有方法能夠準確地確定任務組的聯合學習動態,而無需進行這種蠻力的反覆試驗。 。
Alons and Plank,2016)和(Bingel andSøgaard,2017)這兩篇論文都是經驗研究,分析了MTL中各種任務組對自然語言處理的有效性,重點是選擇一個或兩個輔助任務(例如POS標記,語法分塊和單詞計數)以幫助在主語言上學習通過在任務的許多組合上訓練多任務網路來完成任務(例如,命名實體識別和語義框架檢測)。在這些研究中,為每個單獨的主要任務訓練了一個單任務網路,並將其性能與結合一個或兩個輔助任務在主要任務上訓練的多任務網路的性能進行了比較。
(Alonso and Plank,2016)訓練了1440個任務組合,每個任務組合都有一個主任務和一個或兩個輔助任務,發現使用標籤具有高熵和低峰度的輔助任務,主要任務的性能提升最大。這與(Bingel andSøgaard,2017)的發現是一致的,在該發現中訓練了90對任務(一個主要任務,一個輔助任務)。使用這些訓練運行的結果作為數據,此工作將訓練邏輯對數回歸模型,以基於數據集和兩個任務的學習曲線的特徵來預測輔助任務是對主要任務的性能有幫助還是有損。他們還發現,輔助標籤分布的熵與主要任務的改善高度相關,儘管與主要任務改善最相關的特徵是自行訓練時主要任務學習曲線的梯度。具體來說,如果任務的學習曲線(在單任務設置中進行訓練時)在訓練的前20%到30%期間開始趨於平穩,則在訓練中包含輔助任務可能會改善主要任務的性能。作者推測這可能是因為其學習曲線具有早期平穩期的主要任務很可能卡在了非最佳局部最小值中,而包含輔助任務則有助於優化過程逃脫該最小值。他們的發現令人驚訝的是,當包括輔助任務時,未發現主任務數據集和輔助任務數據集大小的差異指示了主任務性能的提高。儘管這些研究不能像對待MTL一樣對待所有任務,但他們發現暗示任務之間積極轉移的條件足夠普遍,以至於它們在多任務設置中很有用。
在(Doersch and Zisserman,2017)中進行了電腦視覺任務聯合訓練的實證研究,重點是自監督的任務,即相對位置回歸,著色,運動分割和示例匹配。這項研究不是很深入,因為它不是本文的唯一重點,但是作者得出了一個有趣的結論,即與單任務基準相比,多任務訓練始終可以提高性能。考慮到MTL通常無法完成單任務訓練,因此這一事實非常令人驚訝。持續的改進可能是由於任務之間的關係或其自我監督的標籤的性質,但這些答案中的任何一個都不確定。
與這些用於分析多任務任務關係的實證研究相鄰的是一種有原則的方法,該方法可以在訓練過程中在線學習這些關係,而無需進行反覆試驗的任務分組,稱為選擇性共享(Strezoski等人,2019b)。選擇性共享使用共享的主幹體系結構來處理多個任務,並根據整個訓練過程中梯度向量的相似性將任務分為幾組。聚類的原因是特定於任務的分支都使用相同的參數初始化,因此任務梯度之間的相似性表示任務的相似性。在整個訓練過程中更新任務群集時,網路的任務分支將合併,以便將群集在一起的任務共享參數,並且此過程將繼續進行,直到群集停止更改為止。與確定大型任務組的大型實證研究相比,降低計算成本具有明顯的好處,該方法還利用學習到的任務特徵來了解任務之間的關係,這是TRL的一種功能強大且價格便宜的方法,在(Kriegeskorte (2008年; Song等人,2019年)(請參見第4.2節以進行進一步討論)。但是,應該指出的是,他們的模型基於一個假設,該假設在訓練過程中會越來越分解。當跨任務的參數仍然相對相似時,梯度向量可以在訓練開始時指示任務的相似性。但是,隨著訓練的繼續和模型參數的進一步分離,任務梯度之間的相似性變得越來越無法代表任務之間的相似性,並且該訊號將演變為雜訊,具有足夠非凸的損耗態勢。儘管如此,該方法仍憑經驗顯示對通過適當配置計算任務關係有效。
最近,(Standley等,2019)對Taskonomy數據集進行的任務分組進行了深入的實證研究(Zamir等,2018),以及將一組任務劃分為多個簇的方法,每個簇之間表現出正向轉移他們各自的任務。這樣的任務劃分如圖24所示。

使用具有不同數量的訓練數據和網路規模的四個不同的訓練設置來訓練五個任務組中的每對任務,作者發現了一些有趣的趨勢。首先,關於多任務訓練是否在單任務基準線上得到改善的結果好壞參半,許多多任務網路的性能都比單任務相對好。接下來,從單任務到多任務訓練的性能增益隨訓練設置的不同而有很大差異,這意味著MTL的有效性不再像我們曾經想過的那樣依賴於任務本身之間的關係。出乎意料的是,該研究還發現多任務相似度與任務之間的轉移相似度之間沒有相關性,這再次表明,聯合任務學習動力學背後的因素(多任務和轉移學習中)實際上更多。正在考慮的任務。為了找到一組具有理想學習動態的任務組,本工作使用了多任務網路在收斂時的性能近似值和使用這些近似值選擇一組多任務集的分支定界演算法。任務網路共同執行所有任務。使用這種對任務進行分組的方法,所得的多任務網路始終優於單個任務基準線,這是對聯合研究每對任務的經驗研究的多任務設置的巨大改進。據我們所知,這是決定在多任務學習中一起訓練哪些任務的唯一計算框架,該框架允許對兩個以上的任務進行聯合訓練。
遷移關係
如上所述,MTL中任務之間的學習轉移關係與為了聯合學習而將任務分組的問題有關,儘管它們並不總是相關聯,。但是,與同時學習任務不同,轉移學習(遷移學習)已經在更廣泛的深度學習研究工作中發揮了重要作用。大多數自然語言處理和電腦視覺模型不是從頭開始,而是轉移經過預先訓練的模型以用於新任務。即便如此,對可以顯式學習任務之間的轉移關係的方法的研究還只是最近。如今,隨著遷移學習的廣泛應用,這些方法有可能對更大的研究領域產生重大影響。
嘗試學習任務之間的轉移相似度的第一項(當然也是最著名的)工作是Taskonomy(Zamir等人,2018)。除了Taskonomy數據集(其中包含標記為26個任務的400萬張影像)之外,本文還介紹了一種基於任務之間的轉移關係自動構建視覺任務分類法的計算方法。為此,在每個任務上訓練一個單任務網路,然後通過對每對任務回答以下問題來計算傳輸關係:通過在特徵提取器之上訓練一個解碼器,我們如何能夠很好地執行任務i接受過任務j的訓練?
這有點簡化,因為實際的訓練設置涉及從多個源任務轉移到單個目標任務,但是主要思想是相同的。一旦計算了轉移相似度,構造任務分類法的問題就是以滿足源任務數量預算的方式為每個目標任務選擇理想的一個或多個源任務。這樣做的動機是限制可以訪問全部受監督數據(這些是源任務)的任務的數量,並學習其餘任務則通過從源任務轉移而來,僅需少量訓練數據就可以在轉移的特徵提取器之上訓練解碼器。選擇理想的源任務集以及將每個目標任務使用哪些源任務(給定任務傳遞相似度)的問題被編碼為布爾整數編程問題。解決方案可以表示為有向圖,其中節點是任務,並且從任務i到任務j的邊的存在意味著任務i包含在任務j的源任務集合中。圖中顯示了用於不同監管預算和轉移順序的某些最終分類法(每個目標任務的最大源任務數)
25. Taskonomy是第一個大規模的實證研究,用於分析任務轉移關係並根據其轉移關係計算任務的顯式層次結構,從而能夠計算最佳轉移策略,從而在有限的監督下學習一組相關任務。但是,他們這樣做的方法非常昂貴,因為它涉及對源/目標任務的大量組合進行培訓。構造任務分類法的整個過程花費了47,886個GPU小時。
(Dwivedi and Roig,2019)引入了一種類似的啟發但效率更高的方法來學習任務轉移關係,該方法使用表示相似度分析(RSA)(Kriegeskorte,2008)計算任務之間的相似度。 RSA是計算神經科學中用於定量比較神經活動度量的一種常用工具,近年來,它已被用於深度學習社區分析神經網路的激活(Vandenhende et al。,2019)。 (Dwivedi和Roig,2019)中RSA傳輸模型背後的基本假設是,如果兩個任務表現出正向傳輸,則在每個任務上訓練的單任務網路將傾向於學習相似的表示形式,因此RSA將是準確的衡量當前任務的轉移親和力。由於RSA僅涉及比較不同網路的表示,因此無需在每對任務之間實際執行任何傳輸學習,從而使RSA傳輸模型比Taskonomy快了幾個數量級。此外,作者發現,從RSA計算出的任務相似度幾乎與用於訓練任務的模型的大小無關,因此可以使用非常小的模型來完成任務關係的計算,從而降低計算成本,甚至更多。
學習任務轉移關係的現有方法都是最近才出現的,在這一領域還有很多工作要做。 需要注意的一件有趣的事是,RSA和歸因圖傳遞模型(Kriegeskorte,2008; Song等,2019)在計算非平凡資訊時實現效率的方式。 簡而言之,這些模型使用網路來訓練網路。 兩種方法都利用單任務網路學習的資訊(中間表示或相關性評分),以告知下游訓練。 另一方面,Taskonomy訓練了額外的網路來完成這兩種方法的工作,而無需進行任何額外的訓練。 它表明,深層網路學習到的豐富資訊不僅對網路的前向傳遞有用。 通常,即使在MTL之外,也可以並且應該利用此資訊來進一步為模型訓練提供資訊:使用網路來訓練網路。
任務嵌入
儘管任務嵌入主要用於元學習(meta learning,還沒仔細研究過),但任務嵌入是學習任務關係的一種非常通用的形式,並且與本節到目前為止我們討論的方法密切相關。即使在模型之間建立了牢固的聯繫,在MTL中仍然嚴重缺乏利用任務嵌入的方法。不過,這不足為奇。任務嵌入在已經從同一個分布中學習了許多任務後給出了新任務的情況下找到了最有用的方法,並且必須針對已學習的任務對新任務進行本地化。如果要學習的模型的任務集是固定的(與MTL一樣),為什麼要為每個任務分配矢量表示呢?儘管如此,我們仍然認為與TRL的連接很重要,因此我們簡要介紹了元學習文獻中的幾種任務嵌入方法。
(James et al。,2018)使用度量學習來構建任務嵌入,以模仿學習各種機器人操縱任務。該模型名為TecNet,由嵌入網路和控制網路組成。嵌入網路根據給定任務的許多示例來生成任務的矢量表示,而控制網路將觀察值和任務表示作為輸入來產生動作。 (Achille et al。,2019)不是從專家演示中計算嵌入的任務,而是從預訓練網路的Fisher資訊矩陣構造它們。最後,(Lan et al。,2019)訓練了一種用於元強化學習的共享策略,該策略以任務嵌入為條件。這些任務嵌入是任務編碼器的輸出,任務編碼器經過訓練可以根據每個任務的經驗輸出嵌入。
MTL in non-neural models
這個上一篇已經大概介紹完了,這裡不贅述了。
簡單總結:
寫到這邊,我發現如果擴展來看,將hard share和soft share擴展為網路局部單元的share方式,現有的網路結構可以做一個歸類
首先是單源input的情況
(1)單個input源+單個loss(任務)+沒有share的概念,很常見了;
圖片來源:
//zhuanlan.zhihu.com/p/65472471
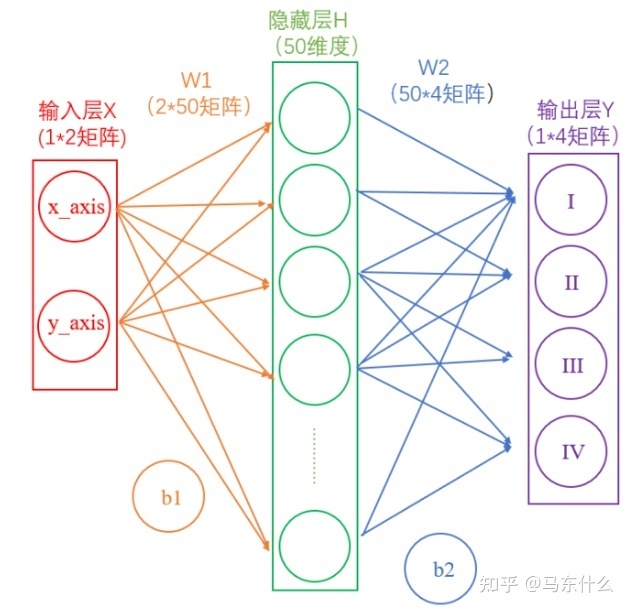
(2)單個input源,多個loss+no share,

典型的,multi-head機制的閹割版

把concat的部分化成不同任務的任務層即可。
上述都是不考慮share的網路結構,也是比較常見的網路結構,下面是引入share的概念之後的網路結構,個人認為hard share,soft share可以作為一種網路構建的機制靈活的應用於網路中的部分模組不一定要按照原文的架構來看。
(3)單個input源,多個loss+hard share/softshare/noshare,
如果hard share可以擴展來看,作為一種局部結構的話,這樣其實還有更多的情況,比如input部分可以接n個子網路結構,這些子網路結構不進行任何形式的share,然後n個自網路的結果concat之後再進入shared layers。比如multi head attention的模型結構(看這個網路結構就好。。。)
concat之後就linear這層算是共享的

同樣啊,我們也可以就對上圖中,某兩層進行softshare,最後一層不share或者concat做成no share或者concat之後再加兩三層做hard share也可以。。。頭痛
然後是多源input的情況:
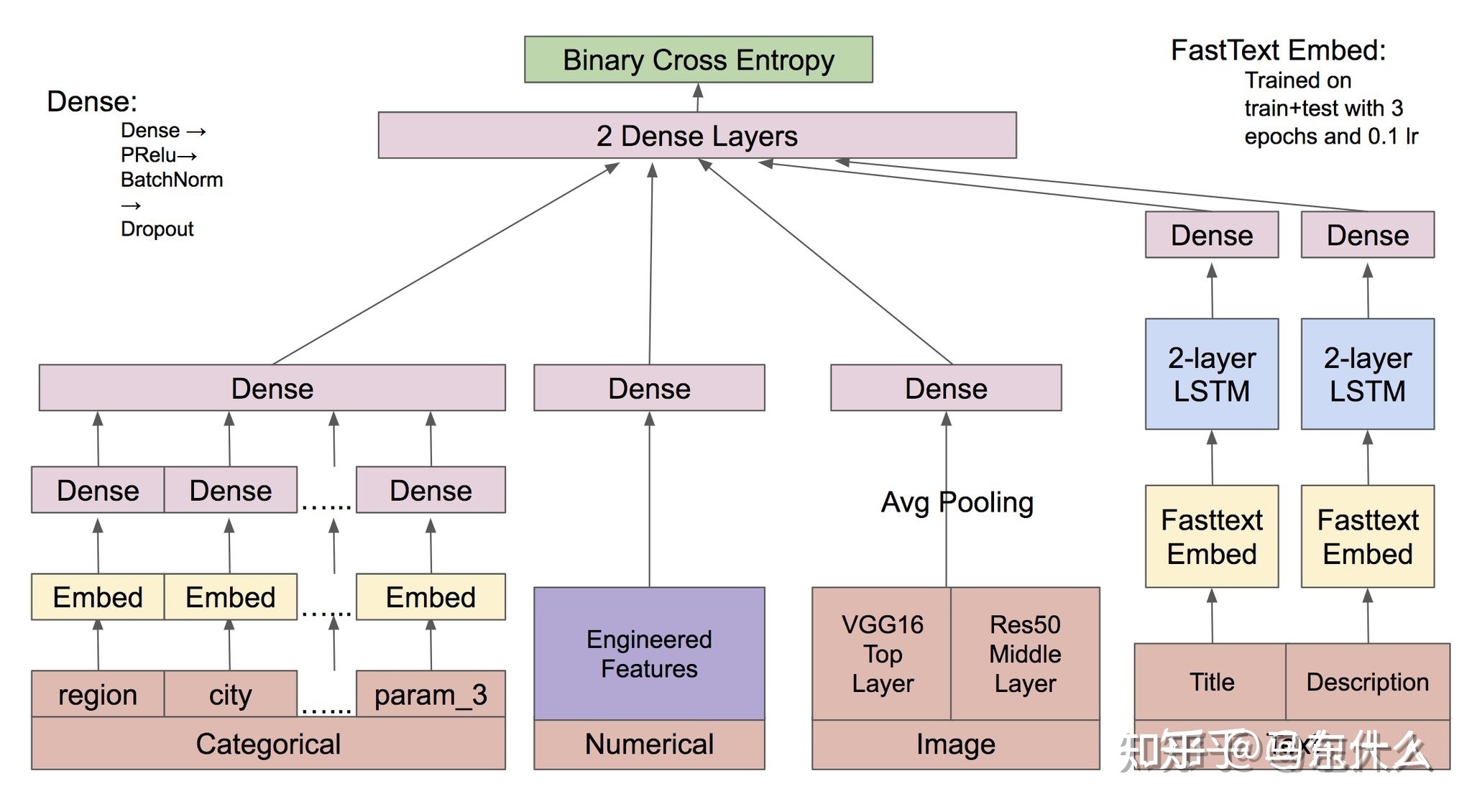
多個input源的思路和單源類似,一個經典圖:
下面是
一個多input源+單個loss+hard share(2 dense layers其實勉強算是做了一層的hard share,如果直接concat不接任何共享層則為no share的形式)
binary cross entropy部分換成多個任務層,則變成了 多input源+多loss+hard share
如果下圖的三個dense之間做soft share

則變成 多input源+多個loss+hard/soft/no share 。。。腦子疼
//zhuanlan.zhihu.com/p/38707354
後續待研究的一些比較著名並且有開源的多任務網路架構:

MOE和MMOE
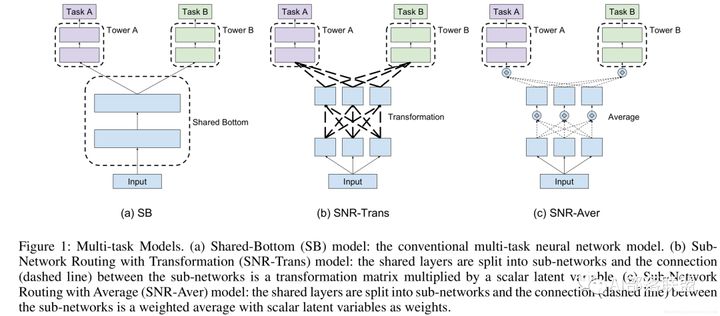
SNR

PCG PLE
十字綉網路

