【工程應用一】 多目標多角度的快速模板匹配演算法(基於NCC,效果無限接近Halcon中……..)
- 2021 年 4 月 6 日
- 筆記
- ,多目標, ,多角度, [03] 影像演算法優化, [04] 影像識別相關, NCC, Template Matching, 模板匹配
願意寫程式碼的人一般都不太願意去寫文章,因為程式碼方面的藝術和文字中的美學往往很難兼得,兩者都兼得的人通常都已經被西方極樂世界所收羅,我也是只喜歡寫程式碼,讓那些字母組成美妙的歌曲,然後自我沉浸在其中自得其樂。而今天,在清明之際,在踏青時節,我還是忍不住停下來歇歇腳,稍微共享一下最近一直研究的一個非常基礎的演算法和應用 – 多目標多角度的模板匹配。
模板匹配,這是一個幾十年來一直為業界所重點研究和處理的演算法,存在於各種不同的機器視覺庫中,如果哪一個沒有提供這個功能,那麼他將無法獲取大家的認可,也就失去了最基本的活力。可以說模板匹配基於機器視覺就相當於數組在程式語言中一樣,基礎但是不可或缺。
在2004年時,我的畢業設計中一個很重要的部分也是模板匹配,當時用模板匹配找到每個量杯中黃色的油的位置,現在看來用那個演算法也是醉了,不過能順利畢業還考得就是他。
在我的早期部落格中,有一篇文章已經談到了這個演算法,詳見:標準的基於歐式距離的模板匹配演算法優源碼化和實現(附源程式碼), 但是這個是個非常慢的過程,而且是單目標無旋轉的實現,在實際應用中,這個基本沒有啥實際的價值。
在工業應用場合,有著非常廣泛使用場景的是多目標多角度的模板匹配(基本無縮放或輕微縮放),這方面實現的比較好的有halcon、海康、康耐視等,中國也有一些小單位有做研究,而且效果不錯。在網路上其實也有比較多的文章談到了多目標模板匹配,基本上都是基於Opencv實現,良心的說也談到了一些核心技術,但是還是皮毛,基本都是一帶而過,而且實現的效率也基本是沒有什麼實用價值的,可能是怕說多了別人學會了吧。
雖然在我的實現中,也參考了不少網路上的文章,但是大部分的細節還是靠的自己的思考和朋友的一些指導,為了尊重他人,我也不打算特別深入講解我的實現,但是還是把一些具有一定深度的問題提出來,也算是回報網路吧。
1、概述
這裡先提工業界最為常用,也是最為基本的模板匹配方式,基於NCC的灰度模板匹配。
NCC,全稱為Normalized Cross correlation,即歸一化互相關係數, 在模板匹配中使用的非常非常廣泛,也是眾多模板匹配方法中非常耀眼的存在, 這個匹配的理論核心基礎公式如下:
 (1)
(1)
該方法也存在於Opencv的matchTemplate中,較之其他的CV提供的匹配方法,該演算法對於光照、噪音等等的影響,穩定性更佳,也是halcon等商用軟體內嵌的基於像素的模板匹配標準方法。
他的理論匹配度範圍是[-1,1],為-1時表示2副影像的極性完全相反(原圖和反色後的圖),為1則表示兩幅圖完全一樣。一般我們在計算NCC的時候都是取的絕對值,因此,通常NCC的取值為[0,1],值越大,表示兩幅影像越相似。
實際編程實現時,千萬不要直接用這個公式,如果你使用,那你離砸電腦已經不遠了,請一定要相信我。
實際中,我們都用下面的式子來實現編碼(不要問我裡面的符號的意思,兩個圖來自不同的資料,裡面的字母也不一樣,但是要研究的這個的人都應該能看懂):
 (2)
(2)
這個式子看上去更為複雜,但是實質上和公式(2)和公式(1)就是同一個東西。公式(2)我們可以把他拆解為7個部分。我們一1道來。
①、這個留到最後在說。
②、T代表的是模板,那麼②對於固定的模板來說就是一個定值,在匹配前可以直接計算好,無需擔憂耗時問題。
③、I 表示的搜索影像中的和模板一樣大的一個子塊,很明顯這個累加有多重方法可以快速的實現,比如比較原始的積分圖技術,或者我的BoxBlur里的那種更為快速的實現,這一項也是和參數無關的。
④、第四項處理方式同 ②項,無需多言。
⑤、第五項完全同第二項,同時四和五項作為一個整體也可以提前計算好,不參與匹配過程的計算。
⑥、第六項處理方式同第三項,也無需多言。
⑦、第七項完全同第三項,直接使用。
前面的分析表明,第二至第七項要買可以作為常量提前計算好,要麼就可以通過某種技術實現O(1)的快速計算,那麼現在我們再回過頭來在看第①項,他是模板影像和搜索影像同面積區域像素的一個卷積,這個是無法用某種優化技巧去實現和模板大小無關的快速實現的,註定了他就是NCC計算式中最為耗時的部分。
有人說卷積可以有FFT實現優化,沒錯,非常同意您的觀點,但是,朋友,FFT雖然其第一個F代表了Fast,但是呢他在傅里葉的世界是快的,在我們模板匹配的空間內他受到了一種無形的壓迫,在工業界還是無法接受的。
因此,我們注意到在本例中,這個卷積其實都是位元組類型的計算,對於一個N*M大小的模板圖,這個卷積需要N*M次乘法以及N*M-1次加法,由於是整數計算,本身運算速度還算比較快的,而且如果在PC上我曾經提及過有一種使用SIMD指令的提速方法,大概能有10倍的運力提高,核心是使用_mm_madd_epi16(對應PMADDWD這個指令)。
其原理如下:
_m128i _mm_madd_epi16(__m128i a, __m128i b)
Multiplies the 8 signed 16-bit integers from a by the 8 signed 16-bit integers from b Adds the signed 32-bit integer results pairwise and packs the 4 signed 32-bit integer results.

該指令可以一次性執行8個16位數據的乘法及4次加法,而我們只要提前把8為位元組數據轉換為16為數據就可以了, 通常這可以由_mm_unpacklo_epi8或者_mm_ cvtepu8_epi16實現。
2、進一步提升
有了上一步的分析,也許你就準備開始動工了,千里之行始於足下嘛,但是作為過來人,我奉勸你除非是為了看效果,否則,你還是等一等吧,下面的更精彩。
如果我們按照公式(2)就開始霸王硬上弓,大部分情況下你需要耐心的盯著你的螢幕滑鼠在那裡轉圈轉圈轉個10來秒吧,然後就可以見證奇蹟了,也許作為初學者,你會心動,而那些需要靠這個吃飯的,可能就是心痛了………
為了得到更快的搜索速度,一個最容易想到的策略就是影像金字塔,影像金字塔每增加一層,影像的點數和模板的點數救減少4倍(理論數據,實際由於非2的寬度和高度,不一定正好是4倍),那麼不考慮Cache等其他的因素,理論上每增加一層金字塔救可以提速16倍,因此,如果我們構建了一個4層的金字塔,那麼在第4層金字塔上的一次完整匹配,其計算的次數和原始的數據相比,就能減少4096倍。
我們先以無旋轉單目標為例進行簡單的說明,當我們在金字塔最高層進行一次完整的匹配後,我們可以找一個全局的極值點,這就是在頂層匹配時的最佳匹配位置,此時,我們可以將頂層匹配的結果映射到金字塔的下一層中,簡單的說就是將找到的匹配點坐標的X/Y值乘以2,那麼為了保證在下一層中的精度,此時的搜索區域需要適當的增大,比如選擇匹配點周圍5*5或者7*7的一個區域,然後在這感興趣的區域中再進行一個局部的匹配計算,此時只需要計算25或者49次小匹配的計算,當計算完畢後,再次提取出這個小區域的極值,作為本層的最終種子點,重複這個過程,直到金字塔的最底層(即原始搜索影像)為止。
稍微分析下,假定上述我們的搜索的局部範圍為5*5大小,金字塔取為4層,那麼整體的計算量是原始直接計算的多少呢,這樣評價:
 式中M和N分別表示影像的寬度和高度。
式中M和N分別表示影像的寬度和高度。
一般來說M和N都是至少以百為單位的,因此上述計算式的結果相當小,速度可以得到極大的提升。
這裡針僅對一個問題進行展開,即金字塔構建時採用何種下取樣演算法,討論如下:
①、最近鄰,這個結果太粗糙,不利於演算法穩定性,可以直接Pass掉。
②、雙線性插值,這個兼顧速度和效果,是個可以考慮的選項。
③、三次立方插值,這個東西在影像放大時是個不錯的選項,而金字塔得建立是縮小過程。
④、蘭索斯插值,這個類似於三次立方插值。
⑤、採用嚴格的高斯金字塔取樣矩陣,一個5*5的矩陣,如下所示:

對於縮小,其實③④⑤都不是很好,③內部是一個4*4的取樣,④是一個8*8的取樣,我舉一個簡單的例子。





原圖(注意紅色框部分的效果) 最近鄰 雙線性 三次立方 蘭索斯
大家可用大一點的螢幕去觀察,可以看到紅色方框內在原圖部分為非常光滑的,而四個插值中,最近鄰有所模糊,三次立方和蘭索斯在風車葉片邊緣出現了鋸齒,只有雙線性完美的保存了葉片的邊緣光滑性。
那麼經過我的實測,一種更好的方式是直接使用2*2均值下取樣,也就是使用2*2區域內的所有像素的平均值,2*2均值濾波器有一個非常好的特性,他沒有頻率響應問題,而較大的濾波器均存在該問題。同時,使用該濾波器還有一個優異的特性,即他可以以非常高效的方式實現。
當影像的寬度和高度都為2的整數倍時,如果選用雙線性插值建立下一層金字塔,此時的雙線性就退化為了2*2均值濾波器。
這裡留一個問題大家共同探討吧:
問題1: 使用2*2均值濾波器時,對於非偶數的寬度和高度,比如W0 = 101,下一層金字塔的寬度W1到底是取50,還是取51呢,如果取51,那麼第51個像素如何獲取結果(2*2取樣會越界)呢?
3、多目標
現實中通常需要在一副原圖中尋找多個匹配的目標,此時,我們的難度就有所上升了,金字塔我們依舊還可以使用,但是如何區分多目標呢。
在單目標時,我們對最高層金字塔進行了全圖匹配後,只需要取最大的匹配值作為候選點,這也是理所當然的,當問題來到多目標時,一個自然的想法就是對匹配值進行排序,然後取前N個最大值作為候選點。但是,這種直接的想法確實非常的不科學的,因為通常在某個最大值附近,由於鄰域的相似性,還存在很多和最大值非常接近的得分點,而他們實際上都是對應同一個目標。
在百度搜索多目標模板匹配,大部分情況你會找到如下的一段程式碼:
Point getNextMinLoc(Mat &result, Point minLoc, int maxValue, int templatW, int templatH)
{
int startX = minLoc.x - templatW / 3;
int startY = minLoc.y - templatH / 3;
int endX = minLoc.x + templatW / 3;
int endY = minLoc.y + templatH / 3;
if (startX < 0 || startY < 0)
{
startX = 0;
startY = 0;
}
if (endX > result.cols - 1 || endY > result.rows - 1)
{
endX = result.cols - 1;
endY = result.rows - 1;
}
int y, x;
for (y = startY; y < endY; y++)
{
for (x = startX; x < endX; x++)
{
float *data = result.ptr<float>(y);
data[x] = maxValue;
}
}
double new_minValue, new_maxValue;
Point new_minLoc, new_maxLoc;
minMaxLoc(result, &new_minValue, &new_maxValue, &new_minLoc, &new_maxLoc);
return new_minLoc;
}
這是一段比較好的參考程式碼,但是僅僅是比較好,還不能解決很多問題,但是我們可以從中學習到一些東西。
程式碼中輸入參數中有一個參數是前一次的最小值的坐標,然後在這個坐標附近一定的矩形範圍內(上述程式碼是模板影像的1/3尺寸),將得分值修改為某個很大的值,接著再進行全範圍的最大和最小值定位,此時,肯定就定位到了離輸入最小值有一定距離的另外一個最小值,而輸入最小值附近的那些次小值就不會干擾結果。
注意上面程式碼是最小值,因為他用的檢測指標是CV_TM_SQDIFF_NORMED,而非NCC,對於NCC,則需要歸為最大值。
這裡的templatW / 3和templatW / 3有點重疊範圍的意思了,但是還完全不夠。
在最頂層金字塔中找到了多個目標的粗糙位置後,就可以和前所述的一樣的方式一步一步的向下一層金字塔進行細化,直到處理到頂層金字塔為止。
4、多目標+多角度
當問題來到這裡時,整個的難度就是階躍式的提高了一個檔次。
如果目標存在旋轉,為了能找到發生旋轉的物體,我們可以創建多個方向的旋轉對象,也就是說,將搜索空間離散化,此時,有兩個可選的方式:一個是旋轉搜索影像,然後用模板在旋轉後的影像中搜索,二是旋轉模板,用旋轉後的模板在搜索影像中定位。我們說,第一種方式基本不可取,原因有三。
(1)、搜索影像一般來說都是較大的圖,對其進行旋轉耗時比較可觀。、
(2)、實際情況需要多個角度的旋轉,對原圖旋轉記憶體方面也會有過多的消耗
(3)、工業應用時,一般模板比較固定,而搜索影像總是時刻變化的。
當選擇第二種方法時,對於較小的模板影像,是可以在執行搜索前把相關旋轉資訊提前準備好,在搜索時刻直接使用,而無需做無謂的耗時。
此時,在金字塔的最頂層,需要做的計算工作也有所增加,我們需要對每個角度的模板都做一個全圖的匹配,得到匹配的結果,然後對每個可能點,選擇匹配度最大的那個角度作為頂層的候選點。
類似的,在向下一層金字塔映射時,不僅僅需要映射匹配點的X和Y坐標,還需要映射角度資訊,同理,為了保證角度方面的精度,也需要適當的擴大角度的搜索區間。
5、更多的問題
實際上,為了實現多目標和多角度的匹配,還存在很多很多的細節問題,需要取研究,這些方面的細節有些已經有了部分結論,但是大部分在網路上鮮有探討和方向,這裡列出一些問題和大家共同探討一番。
問題2:金字塔多少層比較合適?
前面提到了金字塔層數越多,所需的計算量就越少,但是同時帶來一個問題,就是計算的精度會越來越差,這是因為,隨著金字塔層數的增加,因為二次取樣影像會不斷的得到平滑,在影像解析度變得太低時一些基本的特徵已經完全丟失,各種本來不想關的資訊已經完全融合在一起了。因此,一個合適的金字塔層數就尤為重要。一些成熟的商業軟體一般可提供用戶自行輸入金字塔層數,或者自動確定。對於大部分用戶而言,他們不懂得更多的技術細節,自動設置顯得尤為重要。
我們以工業界最為出色Halcon軟體為例,經過多次測試,他的金字塔層數的自動設置是非常智慧化的,基本上自動可以保證速度最優同時效果穩定,通常,我們認為金字塔的層數只和模板影像的尺寸有關,但是,一些仔細的測試表明,兩幅同樣大小的模板圖,halcon也有可能但不一定返回不同的值,估計這其中還用到了影像的一些相似性或者結構方面的一些資訊作出的綜合判斷,不過,一個最基本的規律,還是可以分享下,那就是如果金字塔某層的短邊像素小於或者等於8了,你們這肯定是此模板金字塔層數的極限了。
問題3:角度離散化的間距如何設置最為合理?
類似於金字塔,角度離散化的間距越大,需要計算的旋轉方面的資訊就越少,速度則可以更快,但是同樣,精度就越差。
一般來說,如果模板越大,離散化的間距則需要越小,這是因為較大的模板能夠區別更小角度的變化。通常,對於大小100像素的模板,離散的角度步幅可設置為1度。同樣,如何自動的設置參數也應該是一個成熟軟體的標誌,一個可行的建議是離散的步長需要保證旋轉時兩個相鄰模板之間的長或寬的最小差異值不小於1個像素。
問題4:模板的旋轉如何處理?
通常可以用雙線性插值或者三次立方插值,來獲取旋轉後的數據,不建議用最近鄰演算法,但是不同的旋轉演算法,最後得到的匹配結果會有所不同,同時這也就說呢,其實帶角度的模板匹配,理論上很難獲取精確解,因為你畢竟不知道原始的旋轉演算法是何種,比如我從一個未旋轉影像中扣一個矩形出來作為模板, 然後把影像旋轉各10度,用halcon對模板進行匹配,得到的結果哪怕選擇亞像素也不會是精確的10度。
問題5:旋轉後無效數據的部分怎麼辦?
在對模板進行旋轉時,除非是幾個特殊的角度,比如0、90、270、360度,不會產生額外的資訊,其他的角度,都會有一些未知的區域存在,如下圖所示:



原 圖 旋轉一定的角度 (雙線性插值) 邊緣處局部放大
中間為旋轉後的模板,紅色部分為新出現的未知區域,如果說我們這個圖作為一個整體,去和原影像進行匹配,也就是說讓紅色部分參與了匹配,這很明顯會得到一個得分較低的錯誤結果。
一種也許可行的方式是,我們把這些紅色的區域剔除在匹配有效的數據之外,這時,又會面臨另外一個新的問題,在影像的邊緣部分如何處理。在上面邊緣處局部的方法圖中,我們可以看到,由於插值的特性,邊緣處未能在原始影像中採集到足夠的取樣點,因此,選擇了紅色背景色作為融合的基色,此時的結果像素就不完全是屬於原始影像了,怎麼辦?個人的一個建議是既然這部分像素也被污染了,那就不應該參與後續的匹配。
此時,在編程方面就需要繼續克服下一個困難了,前面概述方面講的一些優化方式又不能直接使用了, 真是他媽的痛苦,所以,借用某一本書里的經典勸退名言吧:聰明的機器視覺用戶都依賴標準軟體包來提供這些功能而不會試著自己實現這些演算法。
問題6:各層金字塔的角度離散值如何分配?
通常,在金子塔的最底層(和原圖一樣大小那一層),可按照前述的自動角度幅值來一步一步的旋轉影像,然後隨著金字塔的層數增加,根據模板在每層金字塔中都會縮小2倍的這個事實,在相應金字塔上模板的角度步幅也可以增加2倍,因此,如果在金字塔最底層上使用的角度步幅喂1度,那麼在第四層上可以使用8度作為角度步幅。
這樣做帶來的好處有很多,因為,通常,我們需要在最頂層做多角度的全圖的匹配,這個計算的相對來說比較大,如果角度步幅在該層得以以指數級別減少,則計算量也會有量級的降低。
問題7:各層金字塔的最低得分值如何確定?
前面一直沒提這個得分的問題,在單目標中一般是不存在這個問題的,當有多個目標時,因為可能不是完整的匹配,因此一般需要客戶確定一個最小的得分值,當然這個得分是指的在最底層時的值。當有了金字塔後,因為下取樣的一些因素,為了有更高的容錯率,一般是建議每增加一層金字塔,最小的得分值需要適當的降低。比如,用戶設置的最小得分為0.8,後續各層的得分可以為:
0.8 0.8*0.9 0.8*0.9*0.9 0.8*0.9*0.9 * 0.9
當然,其他的調整方式也未嘗不可以,但是,總體的區域需保證最小得分越來越低。
問題8:MaxOverlap是什麼鬼,內部是如何操作的?
在Halcon中,還有非常重要的參數-MaxOverlap,一個介於0和1之間的參數,前面也一直沒有談到過。其實,在真正的應用中,存在著一些目標之間有一定程度重疊的情況,這個時候,如果按照前面的那些處理方式,一般就只能獲取到重疊對象的某一個,而丟掉了其他的資訊。當有了MaxOverlap參數時,我們就可以根據這些對象的重疊重複,來決定是否剔除掉某一個不需要的目標。
但是,這也是一個比較難以琢磨的對象,Halcon幫助文檔中的說法是取的對消的最小外接矩形中的重疊比例。說實在的,編程時,這個規則應該還不夠。比如,如果有4個對象,他們都有所重疊,請問這個時候,這個MaxOverlap是指的所有的重疊量合併在一起呢,還是最大的重疊,抑或是按照得分順序第一個和之重疊的呢。目前,我也是對這個比較搖擺。
同時,另外一個比較難以確定問題是,這個重疊是在金字塔的最頂層就進行判斷還是如何呢,如果在金字塔的最頂層不進行判斷,那麼金字塔頂層中得分大於MinScore的則有很多個點,如果把這些點都直接向上一層進行映射,那個計算量也是相當客觀的。
問題9:亞像素坐標和角度是一起執行的嗎,還是分開的?
沒有亞像素的模板匹配是沒有靈魂的,特別是帶有角度的匹配。因為,正如前面所述,我們對角度採用了離散化。那麼這個時候計算的最終角度結果必然是離散化後的序列里的某個值,這樣的精度有的時候是不夠的。
通過亞像素技術,尋找局部區域里的最大值,課獲得更高的位置精度和角度精度,則可以有效的獲得精準的定位。
但是目前還是不清楚坐標+角度組成的4維的空間的亞像素計算公式是如何的。
問題10:速度優化?
以上談的一些優化基本上是結構上的優化,或者說原理上的優化,在編碼上還可以考慮時候用SIMD指令進行處理,尤其是全圖匹配的計算過程。
6、公關成果
大概前前後後再一起有折騰了大概一年的時間吧,初步還是有了一定的成果,無論是在速度上,還是在準確度中,還是能解決一定的工程問題了。
共享一些測試圖,和大家一起比較。



模板圖 待搜索圖 搜索結果



模板圖 待搜索圖 搜索結果
基於NCC的速度方面和很多參數有關,比如角度的搜索範圍,金字塔層數,模板的大小(一般模板大,速度反而快些,特別小的模板則非常耗時,知道原因嗎?),重疊的大小等等都有關。一些簡單的測試數據如下:
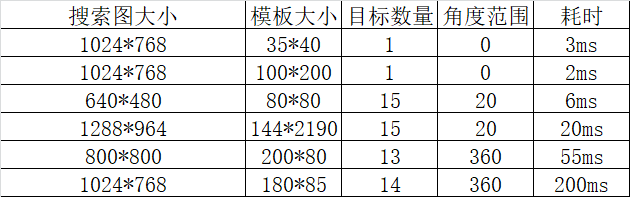
雖然歷經千辛萬苦,在磨礪了很久之後,也對這個初有小成,基本實現了這樣的一些過程,但是和halcon相比,無論是從穩定性還是效率方面都還是有一定的差距的,所以標題中的無限接近 就是一句誑語而已。
本演算法目前已經集成到國產視覺軟體Malcon中,詳情請看 中國的Malcon跟德國的Halcon的相比的優缺點 。
Malcon官方部落格://www.cnblogs.com/Malcon
或者點擊: //blog.csdn.net/lindrs/article/details/114113280?spm=1001.2014.3001.5502
Malcon中還集成了很多其他常用的200多個運算元,相信您一種能從其中找到你所需要的。
如果你希望有一個簡單的可視化測試介面,可以從如下鏈接中獲取,但是請注意這個Demo本身是有一些BUG的(不影響測試使用),請不要將其直接應用到工業環境中,以免造成不必要的損失。

可視化測試Demo: //files.cnblogs.com/files/Imageshop/TemplateMatching.rar
7、更多疑惑
弄得越多,發現不了解的也越多,特別是在研究比對Halcon的過程中,還發現了一些暫時沒有弄清楚的事情,比如:
①、在不勾選亞像素時,Halcon返回的坐標值很多情況下也是帶小數點(特別是非0度時的結果),這個作何解釋。
②、當模板的理論角度是0度時,即使按照AngleStart和AngleStep的值依次計算,取樣的角度值不會準確的取為0,而且也未勾選亞像素,他也能正確的返回0值,難道他對0度做了特別的處理嗎?
這些還需要慢慢的取探索。
如果您覺得本博文對您有所幫助,也可慷慨解囊。



