多任務學習(MTL)在轉化率預估上的應用
今天主要和大家聊聊多任務學習在轉化率預估上的應用。
多任務學習(Multi-task learning,MTL)是機器學習中的一個重要領域,其目標是利用多個學習任務中所包含的有用資訊來幫助每個任務學習得到更為準確的學習器,通過使用包含在相關任務的監督訊號中的領域知識來改善泛化性能。深度學習流行之後,MTL在深度網路也有很多嘗試和方法。
(0).背景介紹
名詞定義:
CTR: 指曝光廣告中,被點擊的廣告比例
CVR: 指被點擊的廣告中,最終形成轉化的廣告比例
CTCVR: 指曝光廣告中,被點擊且最終形成轉化的廣告比例
正如上一篇《oCPC中轉化率模型與校準》中所講,如果完全是按照CPC出價計費,那隻需要建模CTR模型,而在oCPC場景下,需要對CTCVR進行建模,我們目前的業務恰好屬於後者。前期分析表明,直接對CTCVR建模,會導致召回用戶的CTR競爭力較低,影響最終曝光。所以建模需要同時考慮CTR和CTCVR兩個指標。基於以上背景,我們在業務中引入多任務學習的建模方式。
(1).多任務學習介紹
多任務學習是指: 給定m個學習任務,其中所有或一部分任務是相關但並不完全一樣的,多任務學習的目標是通過使用這m個任務中包含的知識來幫助提升各個任務的性能。聯合學習(joint learning)、自主學習(learning to learn)和帶有輔助任務的學習(learning with auxiliary task)等都可以指 MTL。一般來說,優化多個損失函數就等同於進行多任務學習(與單任務學習相反)。即使只優化一個損失函數(如在典型情況下),也有可能藉助輔助任務來改善原任務模型。在深度學習中,多任務學習通常通過隱藏層的Hard或Soft參數共享兩種方式來完成。
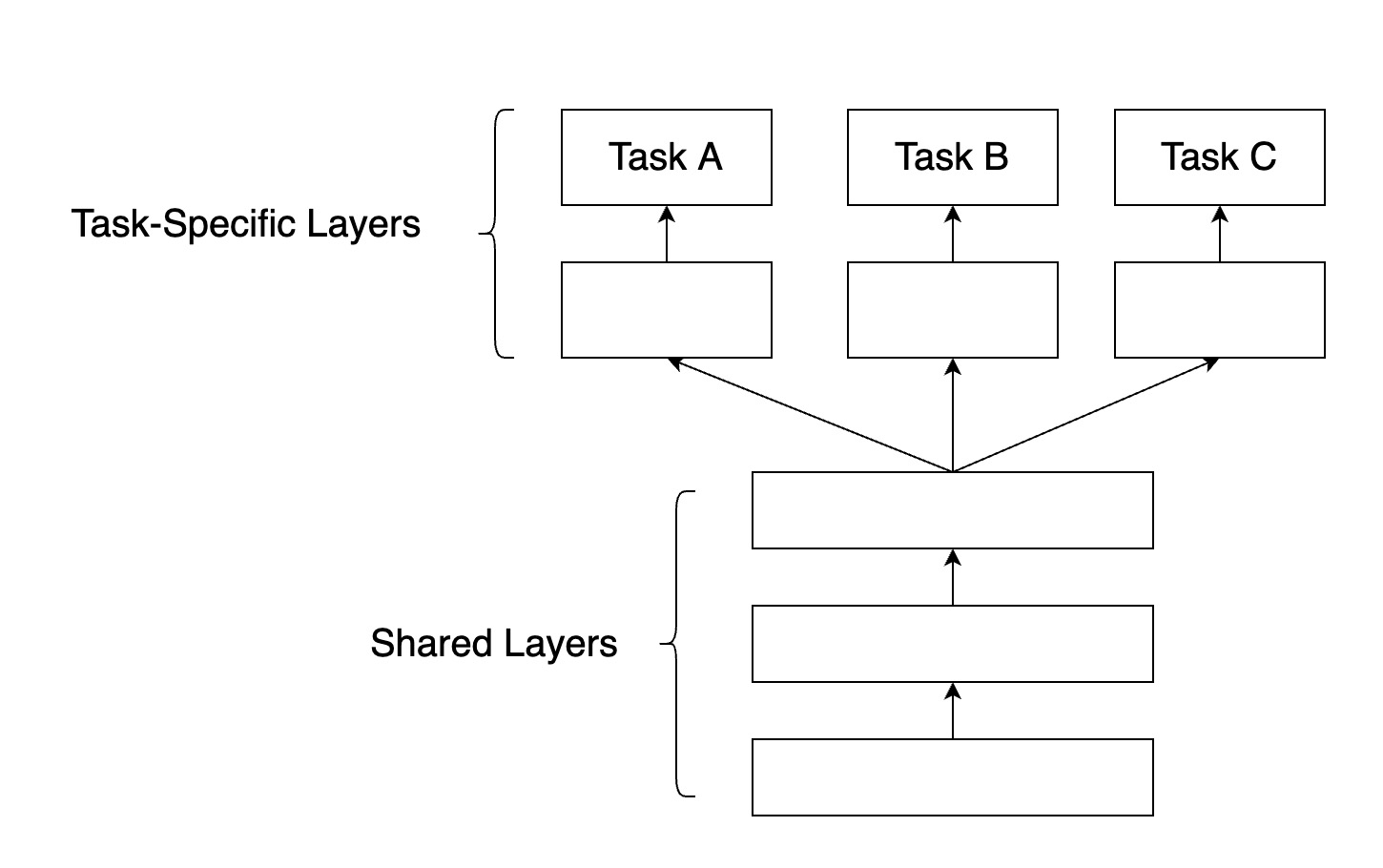
a. Hard參數共享
共享Hard參數是神經網路 MTL最常用的方法,在實際應用中,通常通過在所有任務之間共享隱藏層,同時保留幾個特定任務的輸出層來實現。硬共享機制降低了過擬合的風險。事實上,有文獻證明了這些共享參數過擬合風險的階數是N,其中N為任務的數量,比任務相關參數的過擬合風險要小。直觀來講,這一點是非常有意義的。越多任務同時學習,我們的模型就能捕捉到越多任務的同一個表示,從而使得在我們原始任務上的過擬合風險越小。如下圖所示:
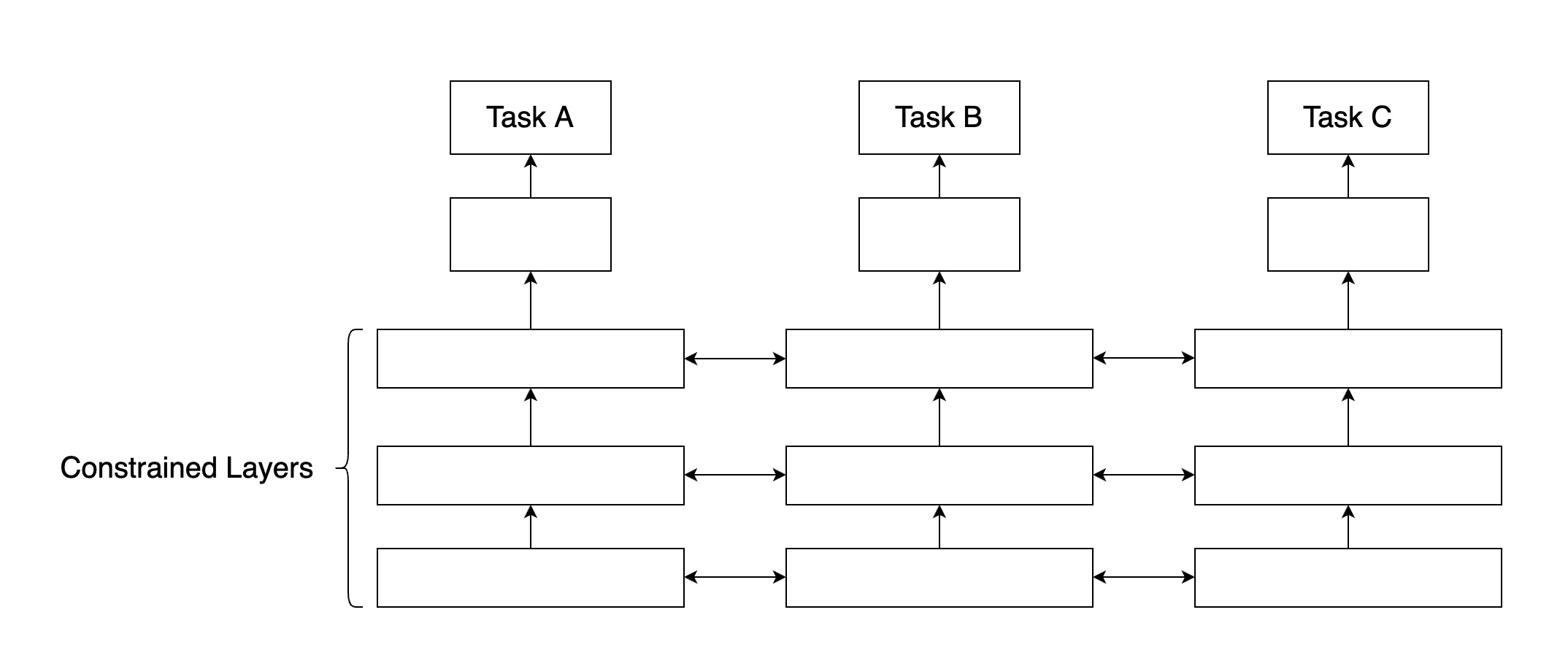
b. Soft參數共享
在共享Soft參數時,每個任務都有自己的參數和模型。模型參數之間的距離是正則化的,以便鼓勵參數相似化,業內常用L2距離進行正則化,或者使用跡範數(trace norm)。

(2). ESMM模型
ESMM:完整空間多任務模型(Entire Space Multi-Task Model),是阿里2018年提出的模型思想,是一個hard參數共享的MTL模型。主要為了解決傳統CVR建模過程中樣本選擇偏差(sample selection bias, SSB)和數據稀疏(data sparsity,DS)問題。
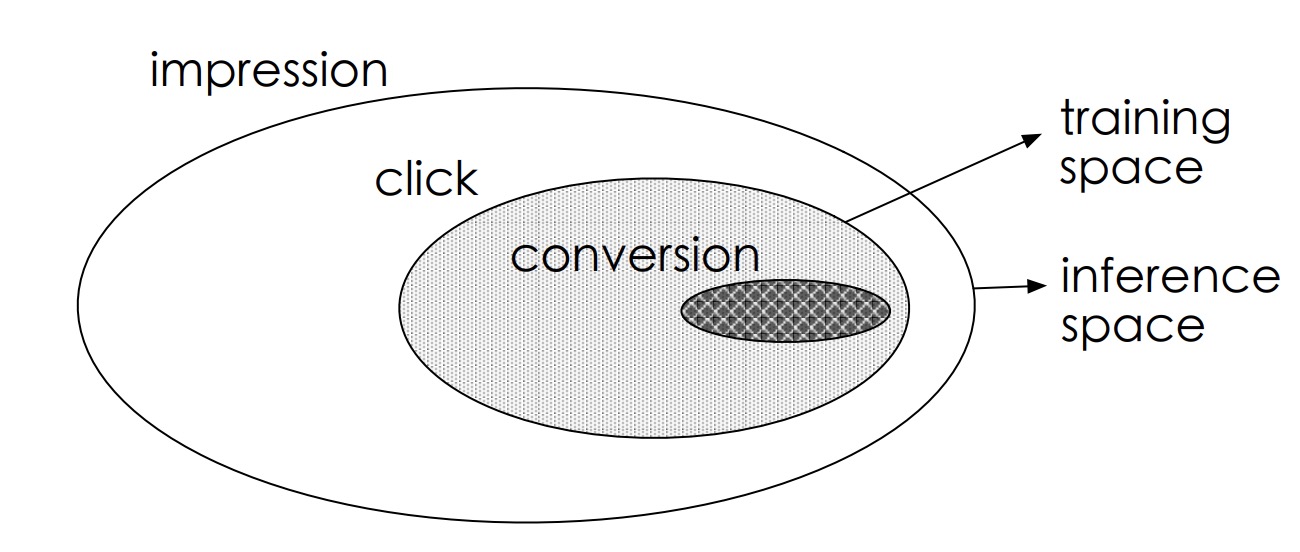
樣本選擇偏差:用戶在廣告上的行為屬於順序行為模式impression -> click -> conversion,傳統CVR建模訓練時是在click的用戶集合中選擇正負樣本,模型最終是對整個impression的用戶空間進行CVR預估,由於click用戶集合和impression用戶集合存在差異(如下圖),引起樣本選擇偏差。
數據稀疏:推薦系統中有click行為的用戶佔比是很低的,相比曝光用戶少1~3個數量級,在實際業務中,有click行為的用戶佔比不到4%,就會導致CVR模型訓練數據稀疏,高度稀疏的訓練數據使得模型的學習變的相當困難。由於用戶行為遵循impression -> click -> conversion的順序行為模式,預估結果遵循以下關係:

ESMM演算法引入兩個輔助任務學習任務,分別擬合pCTR和pCTCVR,都是從整個樣本空間選擇樣本,來同時消除上面提到的兩個問題。其架構圖如下:

從架構圖可以看到,ESMM模型由兩個子網路組成,左邊的子網路用來擬合pCVR,右邊的子網路用來擬合pCTR,最終兩個網路結果相乘得到pCTCVR。pCVR只是作為模型訓練的中間結果,最終根據模型輸出的pCTCVR和pCTR結果計算最終的pCVR,計算公式如下:
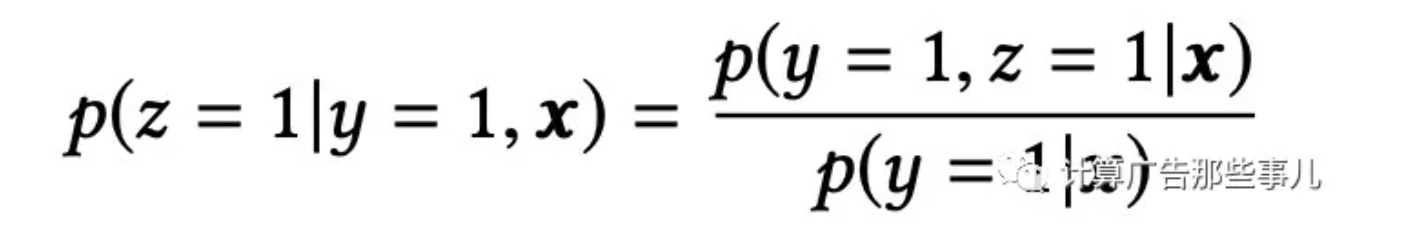
模型很好的解決了樣本偏差問題,訓練過程使用的所有樣本,均是從整個曝光的樣本空間進行選擇,其中有點擊的為CTR正樣本,否則為負樣本;有點擊且轉化的為CTCVR的正樣本,否則為負樣本。同時模型兩個子網路共享embedding層,由於CTR任務的訓練樣本量要大大超過CTCVR任務的訓練樣本量,ESMM模型中特徵表示共享的機制能夠使得CVR子任務也能夠從只有展現沒有點擊的樣本中學習,從而能夠極大地緩解訓練數據稀疏性問題。
(3). ESMM模型的優化
在ESMM模型的基礎上,我們做了以下兩點優化:
a. 優化網路embedding層,使其可以處理用戶不定長行為特徵
用戶歷史行為屬於不定長行為,比如曾經點擊過的ID列表,一般我們對這種行為引入網路中的時候,會將不定長進行截斷成統一長度(比如:平均長度)的定長行為,方便網路使用。很多用戶行為沒有達到平均長度,則會在後面統一補0,這會導致用戶embedding結果裡面包含很多並未去過的節點0的資訊。這裡我們提出一種聚合-分發的特徵處理方式,使得網路的特徵embedding層可以處理不定長的特徵。
由於單個特徵節點的embedding結果是和用戶無關的,比如:用戶A點擊k,用戶B也點擊了k,最終embedding得到的k結果是唯一的,對A和B兩個用戶訪問的k都是一樣的。基於該前提,我們採用聚合-分發的處理思想。將min-batch的所有用戶的不定長行為聚合拼接成一維的長矩陣,並記錄下各個用戶行為的索引,在embedding完成之後,根據索引將各個用戶的實際行為進行還原,並降維成固定長度,輸入到dense層使用。
b. 由於訓練正負樣本差異比較大,模型引入Focal Loss,使訓練過程更加關注數量較少的正樣本
原始ESMM模型中,直接使用pCTCVR和pCTR兩個模型的交叉熵之和作為總的loss函數,loss計算公式如下:
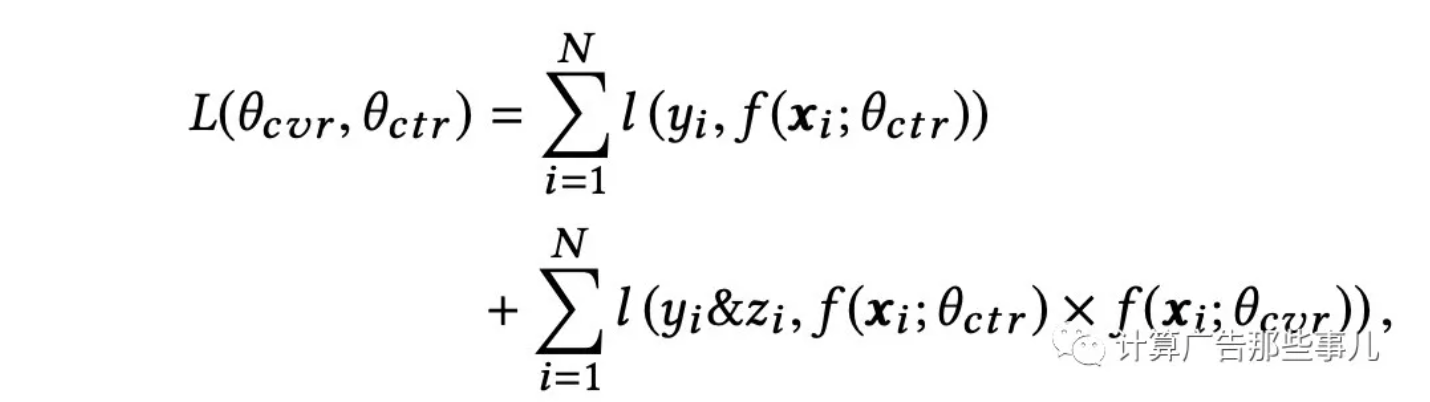
由於正負樣本比例嚴重失衡,樣本中會存在大量的easy samples,且都是屬於負樣本,這些easy negative examples會對loss起主要貢獻作用,會主導梯度的更新方向,導致模型無法學到較好的區分能力。
我們在模型中引入Focal Loss,Focal Loss是對交叉熵的優化,引入平衡權重alpha,一般與樣本權重成負相關,該類樣本佔比越少,在loss函數中的權重就越大,用來平衡正負樣本比例不均的問題。引入難易因子gamma,是給loss函數中困難的、錯分的樣本權重更大,模型更偏向於學習困難錯分的樣本。Focal Loss函數定義如下:
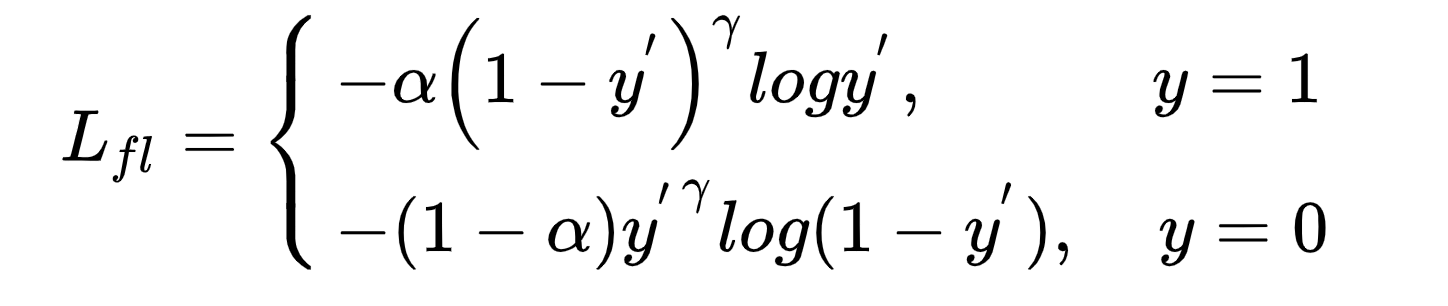
模型實際使用中,根據每個batch裡面正負樣本分布來計算α,優化focal loss之後,模型CTCVR-AUC基本持平,和優化前保持一致;CTCVR的分數在CTR上的AUC表現絕對值提升1.5%。focal loss在模型訓練主任務的過程中學習到了更多CTR相關的能力,提升了模型在CTR表現。
結合ESMM結構和loss函數可以看出,原模型兩個子網路dense層數據分別是pCTR和PCVR,所以在loss函數使用CTR*CVR來評估CTCVR的loss。由於我們模型是直接採用pCTCVR作為主任務,在評估的時候直接使用CTCVR的輸出評估。最終的loss函數如下:
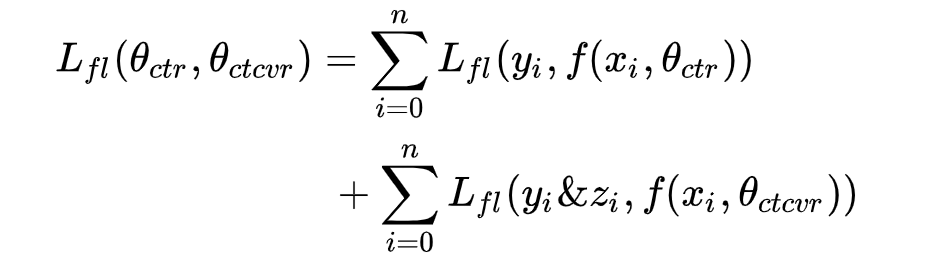
(4). 小結
本文主要介紹了多任務學習的基本概念以及我們在實際業務上對ESMM模型做的一些改進,後會有期,拜了個拜!
歡迎大家關注計算廣告那些事兒哈,除了原創文章之外,也會不定期和大家分享業內大牛的文章哈!



