EfficientNet & EfficientDet 論文解讀
- 2021 年 4 月 3 日
- 筆記
- CV, Deep Learning, Object Detection
概述
總體而言,這兩篇論文都在追求一件事,那就是它們名字中都有的 efficient。只是兩篇文章的側重點不一樣,EfficientNet 主要時研究如何平衡模型的深度 (depth)、寬度 (width) 以及解析度 (resolution) 以獲得更好的性能,並使用了一個複合係數 (compound coefficient) 來統一調整模型的規模。EfficientDet 的亮點在於提出了 BiFPN (雙向特徵金字塔網路?),其實就是目標檢測中的 neck 部分用於特徵圖的融合,然後在這個基礎之上進行了跟 EfficientNet 的拼接並且加了分類和回歸的 head,同樣用複合縮放 (compound scale) 的方式進行調整。因此,先總結一下 EfficientNet 的工作。
EfficientNet
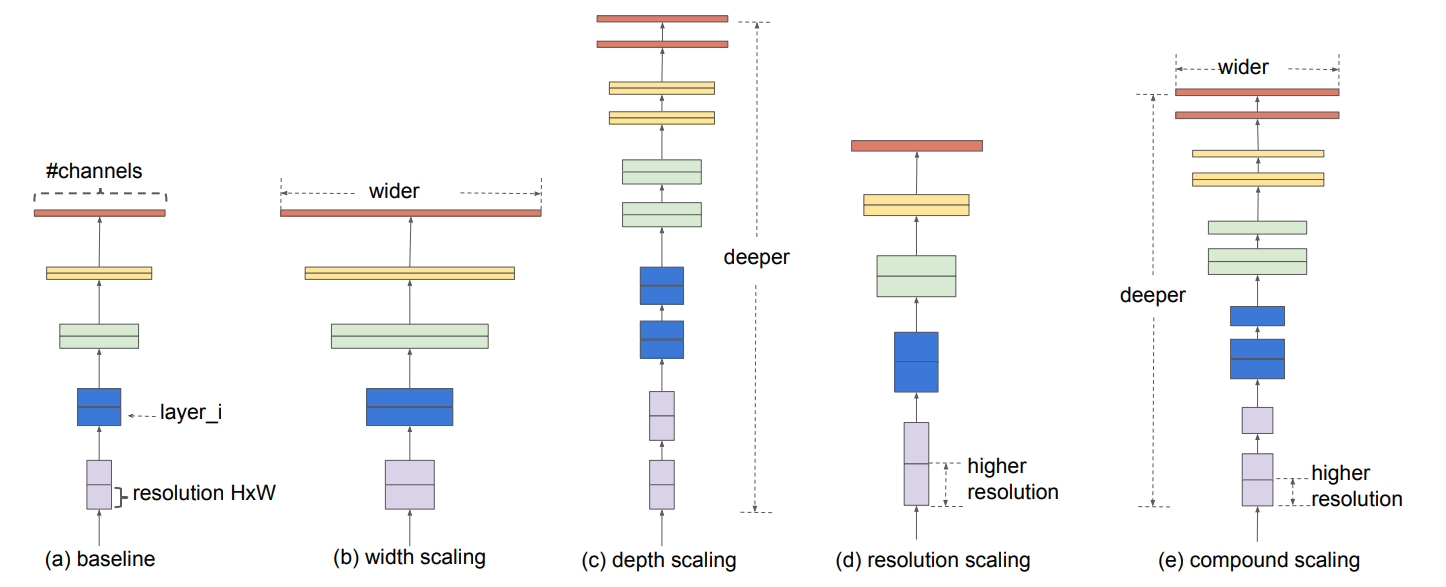
EfficientNet 的研究離不開上面那張圖。但我們首先來介紹一下 EfficientNet 的思想:它會用統一的係數來調整深度、高度、解析度。比如,這個係數為 \(N\),那麼如果我們想用 \(2^N\) 倍的計算資源來跑模型,就可以簡單地將網路的寬度、深度以及圖片尺寸分別擴大 \(\alpha^N,\beta^N,\gamma^N\) 倍(其中 \(\alpha,\beta,\gamma\) 是通過最初始的即沒有進行縮放的模型來進行網格搜索出來的參數)。
問題的推導
第 \(i\) 層卷積層可以被定義為 \(Y_i = \mathcal{F}_i (X_i)\),其中 \(\mathcal{F}_i\) 就是這個層進行的一系列操作,\(Y_i\) 是輸出,\(X_i\) 是輸入。那麼卷積網路就可以使用下式來表達:
\]
其實表達的就是一個卷積層的輸出作為另外一個卷積層的輸入,然而卷積網路的層經常會被分成多個階段,每個階段共享同樣的結構。例如,ResNet 有 5 個階段,在每個階段所有的層都有同樣的卷積形式(除了第一層需要下取樣以外)
\]
\(\mathcal{F}_j^{L_i}\) 表示 \(\mathcal{F}_i\) 在階段 \(i\) 中重複了 \(L_i\) 次。大多數的卷積網路主要關注如何設計最好的層結構 \(\mathcal{F}_i\),而模型的縮放主要從網路的長度(深度)、寬度(通道)和解析度著手,不會去改變 baseline 中預定義的 \(\mathcal{F}_i\)。雖然固定了 \(\mathcal{F}_i\) 的結構,但深度、寬度和解析度依然有著很大的探索空間。EfficientNet 通過一個複合係數來調整所有層來到達縮減設計的空間的目的。
縮放維度
接著 EfficientNet 分別對不同的卷積網路不同的維度進行探索。
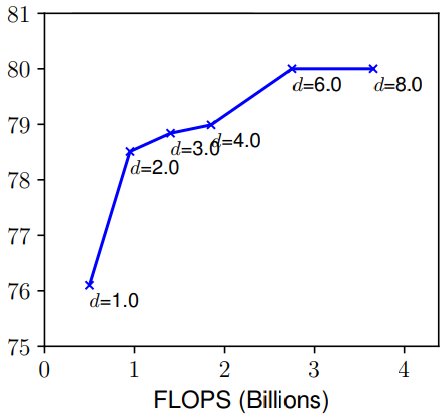
- Depth(d): 一個網路的深度簡而言之就是這個網路的層數。自從有了殘差連接、BN 等手段來減輕較深網路的訓練問題,比較深的網路就大量的出現比如:ResNet101、ResNeXt101 等,但是 ResNet1000 雖然比 ResNet101 多了許多層,準確度只有較少的提升。如上圖所示,如果一味的增加深度,那麼在非常深的情況,精度提升就不那麼明顯了。
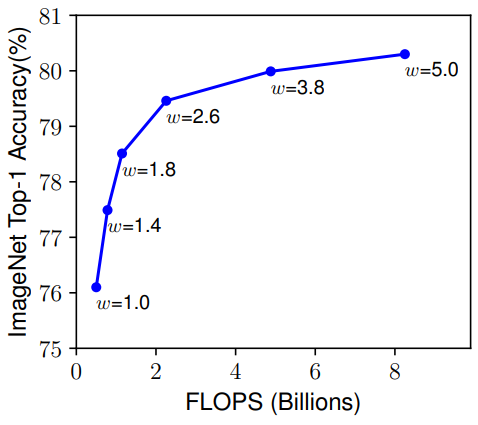
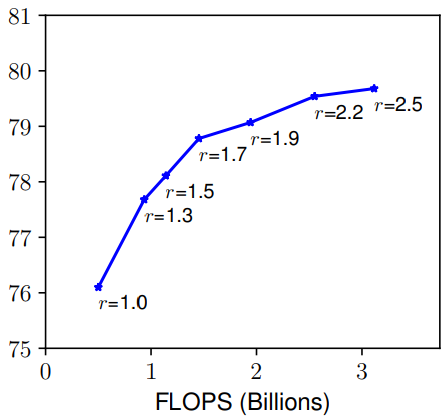
- Width(w) & Resolution(r):一個網路的寬度是指其通道數,而解析度就是輸入圖片的尺寸(簡單理解),由上圖也可以發現和深度有著同樣的問題。總而言之,縮放網路寬度、深度和解析度的任一尺度都可以改善精確度,但這種方法在模型更大的時候就沒有效果了。
複合縮放 (Compound Scaling)
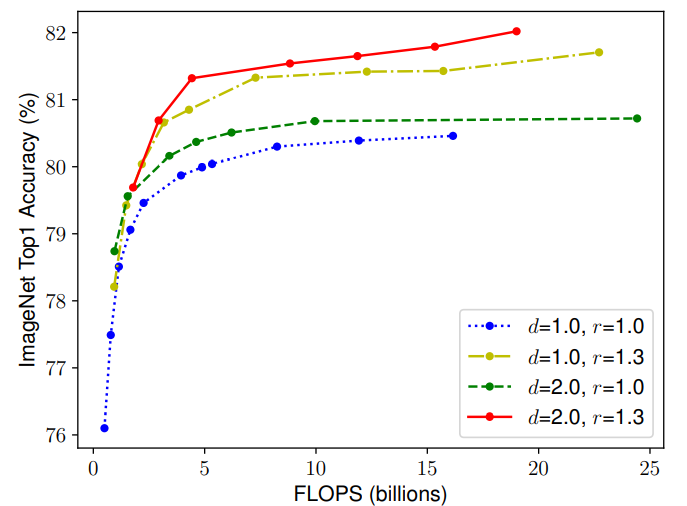
那麼就很自然的思考到一個問題:在縮放一個維度的時候,是不是對另外一個維度也是有所影響的呢?比如,增加寬度有助於獲取較大圖片中相似的特徵,所以解析度更大的時候是不是應該考慮增加網路的寬度?如上圖所示,當 r 越大的時候,將 d 也調大可以獲得更好的性能。因此平衡網路的深度、寬度以及解析度是至關重要的。
文章提出了一種複合縮放的方法,即用一個複合係數 \(\phi\) 來統一縮放網路的寬度、深度和解析度:
d &= \alpha^{\phi} \\
w &= \beta^{\phi} \\
r &= \gamma^{\phi} \\
\mathrm{s.t.} & \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2
\end{aligned}
\]
如之前所言,\(\alpha, \beta, \gamma\) 是通過網格搜索得到的。由於卷積操作的 FLOPs 和 \(d,w^2,r^2\) 是成正比的,因此使網路深度翻倍會使 FLOPs 翻倍,如果寬度和解析度是原來的兩倍,FLOPS 則會變為原來的 4 倍。由此可以計算,當三者整體為初始的 \(\phi\) 倍的時候,FLOPs 為初始的 \((\alpha \cdot \beta^2 \cdot \gamma^2)^{\phi} = 2^{\phi}\) 倍。
EfficientNet 結構
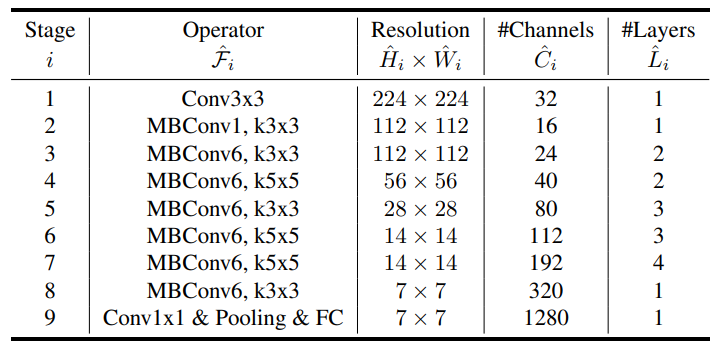
在設計 baseline 網路的時候,將 \(ACC(M) \times [FLOPS(m)/T]^w\)(即綜合模型的準確度和浮點運算次數進行考慮)作為優化目標提出了 EfficientNet-B0,其主要由 MBConv (San-dler et al., 2018; Tan et al., 2019)組成,同時加入了 squeeze-and-excitation optimization 操作。通過網格搜索 \(\alpha=1.2 \beta=1.1 \gamma=1.15\) 是 EfficientNet-B0 最優參數,然後通過 \(\phi\) 進行調整得到 B1 到 B7 版本。
EfficientDet
在了解了 EfficientNet 後再來學習 EfficientDet 只需要明白 weighted bi-directional feature pyramid network (BiFPN) 的結構與它是如何配合 EfficientNet 形成 EfficientDet 的就行了。EfficientDet 基於之前的工作主要是針對一些特定的情況進行設計,提出是否可能設計一種可以縮放的同時具有高精度和高准去率的檢測結構呢?這裡面主要需要解決兩個問題:
-
efficient multi-scale feature fusion:FPN、PANet 等之前的工作將輸入形成的多個特徵圖無差別的進行融合,然而不同的特徵圖對於每一層融合後的結果的貢獻肯定是不一樣。也就是之前沒有對進行融合的特徵圖設置權重。
-
model scaling: 這個問題其實 EfficentNet 已經解釋了。
EfficientDet 解決上述問題分別使用 BiFPN 和 EfficientNet 進行解決。
問題的推導
多尺度特徵融合指的是對不同解析度的特徵進行綜合,這也是目標檢測的 neck 部分。考慮一組多尺度特徵 \(\vec{P}^{in} = (P^{in}_{l_1},P^{in}_{l_2},\dots)\),其中 \(P^{in}_{l_i}\) 代表了 \(l_i\) 層的特徵,事實上 neck 部分的工作就是找到一個轉換的函數 \(f\) 輸入一組特徵圖後得到另外一組特徵圖即 \(\vec{P}^{out} = f(\vec{P}^{in})\)。
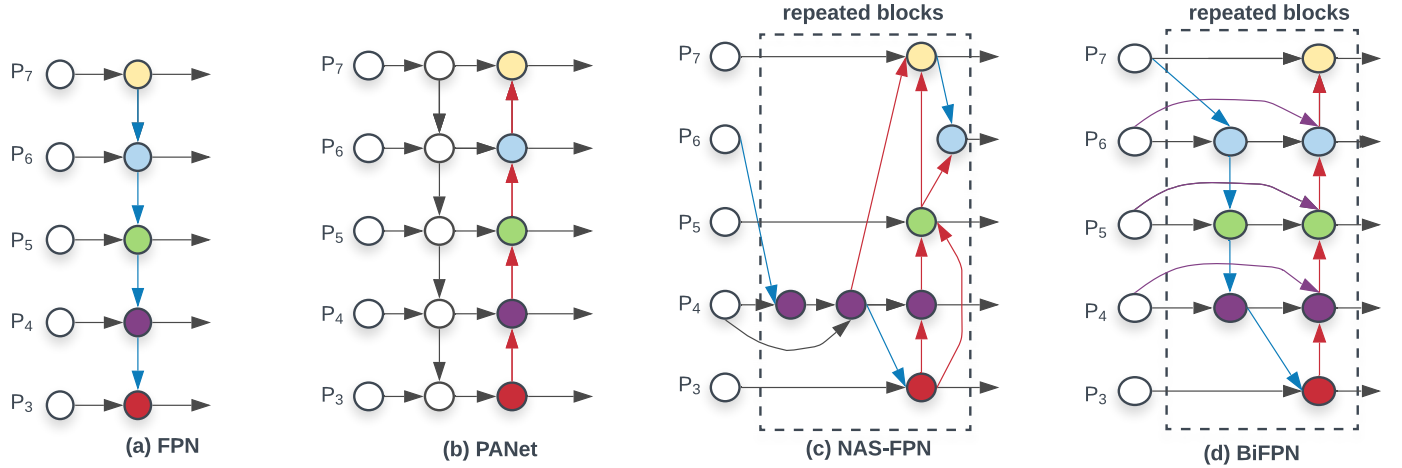
如上圖,經典的 FPN 就是取了 level 3-7 的特徵圖作為輸入 \(\vec{P}^{in} = (P^{in}_{3},\dots,P^{in}_{7})\) 其中 \(P^{in}_i\) 裡面的 \(i\) 代表其解析度為輸入圖片的 \(1/2^i\)。將上圖中的 (a) 用公式表達則是:
P^{out}_{7} &= Conv(P^{in}_{7}) \\
P^{out}_{6} &= Conv(P^{in}_{6} + Resize(P^{out}_{7})) \\
& \dots \\
P^{out}_{3} &= Conv(P^{in}_{3} + Resize(P^{out}_{4})) \\
\end{aligned}
\]
Resize 一般採用的上取樣或者下取樣,因此特徵圖的尺寸不一樣所以需要調整後才能融合。但是注意在融合的時候 \(P^{in}_{6}\) 和 \(Resize(P^{out}_{7})\) 前面的係數都是 1,也是文章提到的無差別融合。很容易能夠發現傳統的 FPN 被只有一條資訊流所限制,因此 PANet 添加了一條額外的自底而上的路徑進行融合。
因此針對跨尺度連接:首先去除了只有一個輸入的 node,因為一個 node 只有一個輸入並沒有特徵融合,那麼它對於針對不同特徵融合的特徵網路的貢獻就比較少(可見(d)圖的 \(P_2,P_7\))。第二,新加了一條從原始輸入到輸出的邊(即殘差連接),這樣的連接並不會消耗太多。
關於有權重的特徵融合
這就是在最開始提的不同解析度的特徵圖進行融合時,按照它們對輸出應該有不同的貢獻分配不同的權重,而不是像 FPN 和 PANet 一樣無差別的融合。因此,文章討論了幾種權重融合的方式:
-
Unbounded fusion: \(O = \sum_i w_i \dot I_i\)
上式中的權重時可以學習的參數。這種方式能以最少的計算資源能到達與其它方式相同的準確度,但是這種權重時無邊界的,因此訓練極為不穩定。 -
Softmax-based fusion: \(O = \sum_i \frac{e^{w_i}}{\sum_j e^{w_j}}\)
很簡單,應用 softmax 函數將權重歸一化到了 0 到 1 之間,不過在文章的 ablation 實驗表明,其非常消耗 GPU 資源。 -
Fast normalized fusion: \(O = \sum_i \frac{w_i}{\epsilon + \sum_j w_j}\)
對每個權重應用 Relu 函數可以保證 \(w_i\) 大於 0,然後再使用 \(\epsilon\) 保證數值穩定,這樣做也能使最終的權重介於 0 到 1 之間,而且這種方式比較簡單,運行起來也比較有效率,因此叫做快速歸一融合。
因此作為例子,BiFPN 的第六層就可以有下式計算,首先利用下一層的特徵和第六層的輸入計算第六層中間的結點:
\]
然後再利用第六層的輸入、中間結點的輸出與上一層的輸出計算第六層的最終結果:
\]
其他層的融合方式與上述類似,並且為了改善效率,文章使用了深度可分離卷積並對於每一個卷積添加了 BN 和激活函數。
EfficientDet 結構
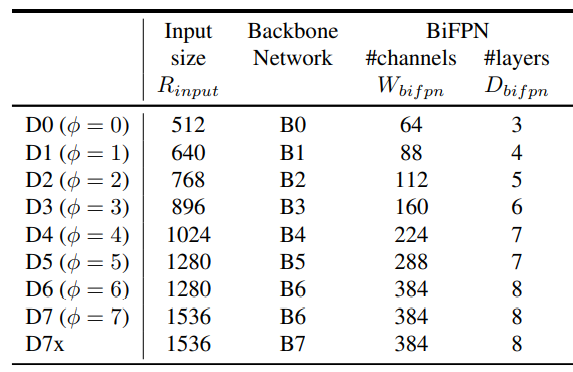
對於 EfficienDet 採用 EfficientNet-B0 到 B6 作為 backbone,而 neck 部分肯定是使用新提出了 BiFPN,而且對於 BiFPN 依然使用網格搜索得到一個最優的縮放因子,同樣由 \(\phi\) 來進行控制:
\]
\(W_{bifpn}\) 為通道數,並以 1.35 倍增長,\(D_{bifpn}\) 則為重複的次數。關於 head 部分,則不是我們關注的重點。而對輸入圖片的解析度,則由下式控制:
\]
計算結果如下
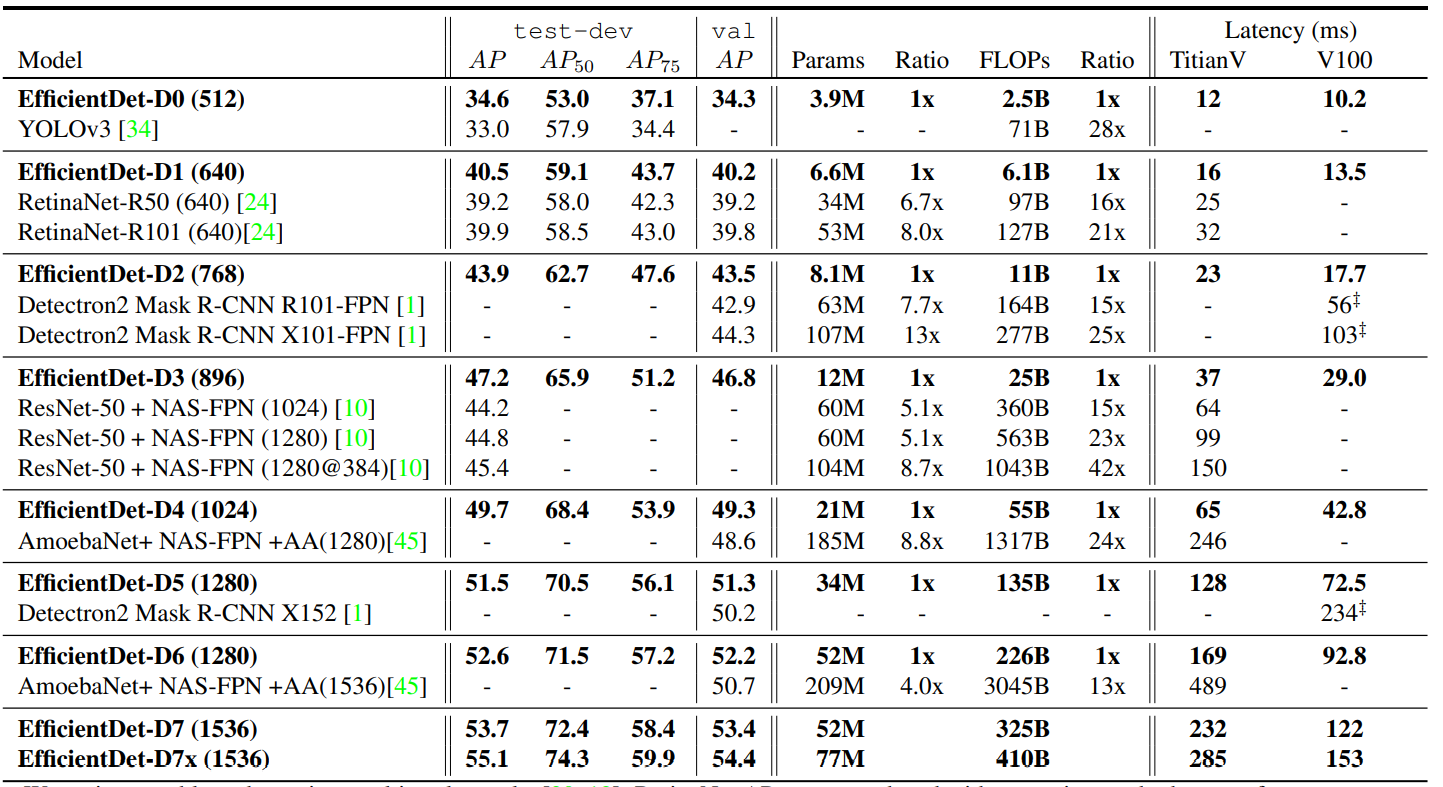
最後 EfficientDet 的對比實驗結果如下:
EfficientNet-V2 To Be Continued~


