如何設計一個高並發系統?
- 2019 年 10 月 3 日
- 筆記
面試題
如何設計一個高並發系統?
面試官心理分析
說實話,如果面試官問你這個題目,那麼你必須要使出全身吃奶勁了。為啥?因為你沒看到現在很多公司招聘的 JD 里都是說啥,有高並發就經驗者優先。
如果你確實有真才實學,在互聯網公司里干過高並發系統,那你確實拿 offer 基本如探囊取物,沒啥問題。面試官也絕對不會這樣來問你,否則他就是蠢。
假設你在某知名電商公司干過高並發系統,用戶上億,一天流量幾十億,高峰期並發量上萬,甚至是十萬。那麼人家一定會仔細盤問你的系統架構,你們系統啥架構?怎麼部署的?部署了多少台機器?快取咋用的?MQ 咋用的?資料庫咋用的?就是深挖你到底是如何扛住高並發的。
因為真正干過高並發的人一定知道,脫離了業務的系統架構都是在紙上談兵,真正在複雜業務場景而且還高並發的時候,那系統架構一定不是那麼簡單的,用個 redis,用 mq 就能搞定?當然不是,真實的系統架構搭配上業務之後,會比這種簡單的所謂「高並發架構」要複雜很多倍。
如果有面試官問你個問題說,如何設計一個高並發系統?那麼不好意思,一定是因為你實際上沒幹過高並發系統。面試官看你簡歷就沒啥出彩的,感覺就不咋地,所以就會問問你,如何設計一個高並發系統?其實說白了本質就是看看你有沒有自己研究過,有沒有一定的知識積累。
最好的當然是招聘個真正干過高並發的哥兒們咯,但是這種哥兒們人數稀缺,不好招。所以可能次一點的就是招一個自己研究過的哥兒們,總比招一個啥也不會的哥兒們好吧!
所以這個時候你必須得做一把個人秀了,秀出你所有關於高並發的知識!
面試題剖析
其實所謂的高並發,如果你要理解這個問題呢,其實就得從高並發的根源出發,為啥會有高並發?為啥高並發就很牛逼?
我說的淺顯一點,很簡單,就是因為剛開始系統都是連接資料庫的,但是要知道資料庫支撐到每秒並發兩三千的時候,基本就快完了。所以才有說,很多公司,剛開始乾的時候,技術比較 low,結果業務發展太快,有的時候系統扛不住壓力就掛了。
當然會掛了,憑什麼不掛?你資料庫如果瞬間承載每秒 5000/8000,甚至上萬的並發,一定會宕機,因為比如 mysql 就壓根兒扛不住這麼高的並發量。
所以為啥高並發牛逼?就是因為現在用互聯網的人越來越多,很多 app、網站、系統承載的都是高並發請求,可能高峰期每秒並發量幾千,很正常的。如果是什麼雙十一之類的,每秒並發幾萬幾十萬都有可能。
那麼如此之高的並發量,加上原本就如此之複雜的業務,咋玩兒?真正厲害的,一定是在複雜業務系統里玩兒過高並發架構的人,但是你沒有,那麼我給你說一下你該怎麼回答這個問題:
可以分為以下 6 點:
- 系統拆分
- 快取
- MQ
- 分庫分表
- 讀寫分離
- ElasticSearch
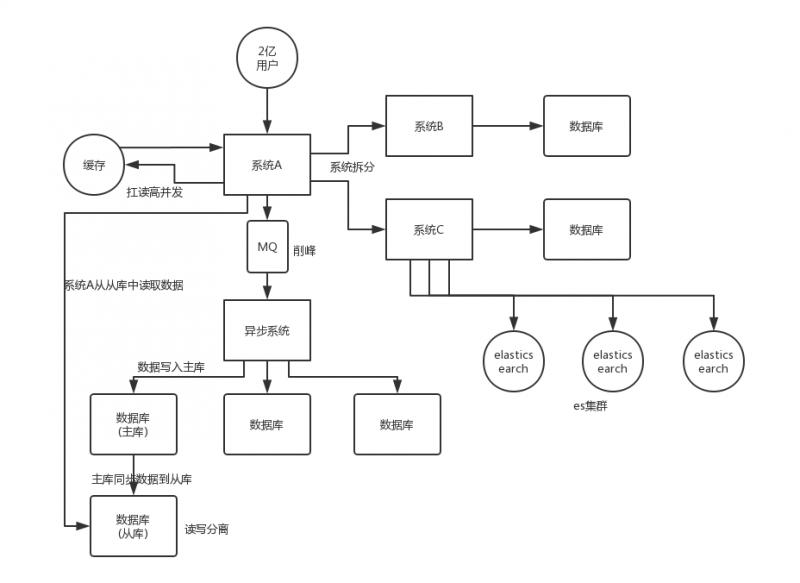
系統拆分
將一個系統拆分為多個子系統,用 dubbo 來搞。然後每個系統連一個資料庫,這樣本來就一個庫,現在多個資料庫,不也可以扛高並發么。
快取
快取,必須得用快取。大部分的高並發場景,都是讀多寫少,那你完全可以在資料庫和快取里都寫一份,然後讀的時候大量走快取不就得了。畢竟人家 redis 輕輕鬆鬆單機幾萬的並發。所以你可以考慮考慮你的項目里,那些承載主要請求的讀場景,怎麼用快取來抗高並發。
MQ
MQ,必須得用 MQ。可能你還是會出現高並發寫的場景,比如說一個業務操作里要頻繁搞資料庫幾十次,增刪改增刪改,瘋了。那高並發絕對搞掛你的系統,你要是用 redis 來承載寫那肯定不行,人家是快取,數據隨時就被 LRU 了,數據格式還無比簡單,沒有事務支援。所以該用 mysql 還得用 mysql 啊。那你咋辦?用 MQ 吧,大量的寫請求灌入 MQ 里,排隊慢慢玩兒,後邊系統消費後慢慢寫,控制在 mysql 承載範圍之內。所以你得考慮考慮你的項目里,那些承載複雜寫業務邏輯的場景里,如何用 MQ 來非同步寫,提升並發性。MQ 單機抗幾萬並發也是 ok 的,這個之前還特意說過。
分庫分表
分庫分表,可能到了最後資料庫層面還是免不了抗高並發的要求,好吧,那麼就將一個資料庫拆分為多個庫,多個庫來扛更高的並發;然後將一個表拆分為多個表,每個表的數據量保持少一點,提高 sql 跑的性能。
讀寫分離
讀寫分離,這個就是說大部分時候資料庫可能也是讀多寫少,沒必要所有請求都集中在一個庫上吧,可以搞個主從架構,主庫寫入,從庫讀取,搞一個讀寫分離。讀流量太多的時候,還可以加更多的從庫。
ElasticSearch
Elasticsearch,簡稱 es。es 是分散式的,可以隨便擴容,分散式天然就可以支撐高並發,因為動不動就可以擴容加機器來扛更高的並發。那麼一些比較簡單的查詢、統計類的操作,可以考慮用 es 來承載,還有一些全文搜索類的操作,也可以考慮用 es 來承載。
上面的 6 點,基本就是高並發系統肯定要乾的一些事兒,大家可以仔細結合之前講過的知識考慮一下,到時候你可以系統的把這塊闡述一下,然後每個部分要注意哪些問題,之前都講過了,你都可以闡述闡述,表明你對這塊是有點積累的。
說句實話,畢竟你真正厲害的一點,不是在於弄明白一些技術,或者大概知道一個高並發系統應該長什麼樣?其實實際上在真正的複雜的業務系統里,做高並發要遠遠比上面提到的點要複雜幾十倍到上百倍。你需要考慮:哪些需要分庫分表,哪些不需要分庫分表,單庫單表跟分庫分表如何 join,哪些數據要放到快取里去,放哪些數據才可以扛住高並發的請求,你需要完成對一個複雜業務系統的分析之後,然後逐步逐步的加入高並發的系統架構的改造,這個過程是無比複雜的,一旦做過一次,並且做好了,你在這個市場上就會非常的吃香。
其實大部分公司,真正看重的,不是說你掌握高並發相關的一些基本的架構知識,架構中的一些技術,RocketMQ、Kafka、Redis、Elasticsearch,高並發這一塊,你了解了,也只能是次一等的人才。對一個有幾十萬行程式碼的複雜的分散式系統,一步一步架構、設計以及實踐過高並發架構的人,這個經驗是難能可貴的。
本文在米兜公眾號鏈接:
https://mp.weixin.qq.com/s/9p-XPL_FRqN5nhbiwmOXSw
歡迎關注米兜Java,一個注在共享、交流的Java學習平台。

