上萬字詳解Spark Core(建議收藏)
🧡先來一個問題,也是面試中常問的:
Spark為什麼會流行?
原因1:優秀的數據模型和豐富計算抽象
Spark 產生之前,已經有MapReduce這類非常成熟的計算系統存在了,並提供了高層次的API(map/reduce),把計算運行在集群中並提供容錯能力,從而實現分散式計算。
雖然MapReduce提供了對數據訪問和計算的抽象,但是對於數據的復用就是簡單的將中間數據寫到一個穩定的文件系統中(例如HDFS),所以會產生數據的複製備份,磁碟的I/O以及數據的序列化,所以在遇到需要在多個計算之間復用中間結果的操作時效率就會非常的低。而這類操作是非常常見的,例如迭代式計算,互動式數據挖掘,圖計算等。
認識到這個問題後,學術界的 AMPLab 提出了一個新的模型,叫做 RDD。RDD 是一個可以容錯且並行的數據結構(其實可以理解成分散式的集合,操作起來和操作本地集合一樣簡單),它可以讓用戶顯式的將中間結果數據集保存在記憶體中,並且通過控制數據集的分區來達到數據存放處理最優化.同時 RDD也提供了豐富的 API (map、reduce、filter、foreach、redeceByKey…)來操作數據集。後來 RDD被 AMPLab 在一個叫做 Spark 的框架中提供並開源。
簡而言之,Spark 借鑒了 MapReduce 思想發展而來,保留了其分散式並行計算的優點並改進了其明顯的缺陷。讓中間數據存儲在記憶體中提高了運行速度、並提供豐富的操作數據的API提高了開發速度。
原因2:完善的生態圈-fullstack
目前,Spark已經發展成為一個包含多個子項目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子項目。
Spark Core:實現了 Spark 的基本功能,包含RDD、任務調度、記憶體管理、錯誤恢復、與存儲系統交互等模組。
Spark SQL:Spark 用來操作結構化數據的程式包。通過 Spark SQL,我們可以使用 SQL操作數據。
Spark Streaming:Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API。
Spark MLlib:提供常見的機器學習(ML)功能的程式庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據導入等額外的支援功能。
GraphX(圖計算):Spark中用於圖計算的API,性能良好,擁有豐富的功能和運算符,能在海量數據上自如地運行複雜的圖演算法。
集群管理器:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計算。
StructuredStreaming:處理結構化流,統一了離線和實時的API。
Spark VS Hadoop
| Hadoop | Spark | |
|---|---|---|
| 類型 | 基礎平台, 包含計算, 存儲, 調度 | 分散式計算工具 |
| 場景 | 大規模數據集上的批處理 | 迭代計算, 互動式計算, 流計算 |
| 價格 | 對機器要求低, 便宜 | 對記憶體有要求, 相對較貴 |
| 編程範式 | Map+Reduce, API 較為底層, 演算法適應性差 | RDD組成DAG有向無環圖, API 較為頂層, 方便使用 |
| 數據存儲結構 | MapReduce中間計算結果存在HDFS磁碟上, 延遲大 | RDD中間運算結果存在記憶體中 , 延遲小 |
| 運行方式 | Task以進程方式維護, 任務啟動慢 | Task以執行緒方式維護, 任務啟動快 |
💖注意:
儘管Spark相對於Hadoop而言具有較大優勢,但Spark並不能完全替代Hadoop,Spark主要用於替代Hadoop中的MapReduce計算模型。存儲依然可以使用HDFS,但是中間結果可以存放在記憶體中;調度可以使用Spark內置的,也可以使用更成熟的調度系統YARN等。
實際上,Spark已經很好地融入了Hadoop生態圈,並成為其中的重要一員,它可以藉助於YARN實現資源調度管理,藉助於HDFS實現分散式存儲。
此外,Hadoop可以使用廉價的、異構的機器來做分散式存儲與計算,但是,Spark對硬體的要求稍高一些,對記憶體與CPU有一定的要求。
Spark Core
一、RDD詳解
1. 為什麼要有RDD?
在許多迭代式演算法(比如機器學習、圖演算法等)和互動式數據挖掘中,不同計算階段之間會重用中間結果,即一個階段的輸出結果會作為下一個階段的輸入。但是,之前的MapReduce框架採用非循環式的數據流模型,把中間結果寫入到HDFS中,帶來了大量的數據複製、磁碟IO和序列化開銷。且這些框架只能支援一些特定的計算模式(map/reduce),並沒有提供一種通用的數據抽象。
AMP實驗室發表的一篇關於RDD的論文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》就是為了解決這些問題的。
RDD提供了一個抽象的數據模型,讓我們不必擔心底層數據的分散式特性,只需將具體的應用邏輯表達為一系列轉換操作(函數),不同RDD之間的轉換操作之間還可以形成依賴關係,進而實現管道化,從而避免了中間結果的存儲,大大降低了數據複製、磁碟IO和序列化開銷,並且還提供了更多的API(map/reduec/filter/groupBy…)。
2. RDD是什麼?
RDD(Resilient Distributed Dataset)叫做彈性分散式數據集,是Spark中最基本的數據抽象,代表一個不可變、可分區、裡面的元素可並行計算的集合。
單詞拆解:
- Resilient :它是彈性的,RDD裡面的中的數據可以保存在記憶體中或者磁碟裡面
- Distributed :它裡面的元素是分散式存儲的,可以用於分散式計算
- Dataset: 它是一個集合,可以存放很多元素
3. RDD主要屬性
進入RDD的源碼中看下:

在源碼中可以看到有對RDD介紹的注釋,我們來翻譯下:
-
A list of partitions :
一組分片(Partition)/一個分區(Partition)列表,即數據集的基本組成單位。
對於RDD來說,每個分片都會被一個計算任務處理,分片數決定並行度。
用戶可以在創建RDD時指定RDD的分片個數,如果沒有指定,那麼就會採用默認值。 -
A function for computing each split :
一個函數會被作用在每一個分區。
Spark中RDD的計算是以分片為單位的,compute函數會被作用到每個分區上。 -
A list of dependencies on other RDDs :
一個RDD會依賴於其他多個RDD。
RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似於流水線一樣的前後依賴關係。在部分分區數據丟失時,Spark可以通過這個依賴關係重新計算丟失的分區數據,而不是對RDD的所有分區進行重新計算。(Spark的容錯機制) -
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):
可選項,對於KV類型的RDD會有一個Partitioner,即RDD的分區函數,默認為HashPartitioner。 -
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):
可選項,一個列表,存儲存取每個Partition的優先位置(preferred location)。
對於一個HDFS文件來說,這個列表保存的就是每個Partition所在的塊的位置。按照”移動數據不如移動計算”的理念,Spark在進行任務調度的時候,會儘可能選擇那些存有數據的worker節點來進行任務計算。
總結
RDD 是一個數據集的表示,不僅表示了數據集,還表示了這個數據集從哪來,如何計算,主要屬性包括:
- 分區列表
- 計算函數
- 依賴關係
- 分區函數(默認是hash)
- 最佳位置
分區列表、分區函數、最佳位置,這三個屬性其實說的就是數據集在哪,在哪計算更合適,如何分區;
計算函數、依賴關係,這兩個屬性其實說的是數據集怎麼來的。
二、RDD-API
1. RDD的創建方式
-
由外部存儲系統的數據集創建,包括本地的文件系統,還有所有Hadoop支援的數據集,比如HDFS、Cassandra、HBase等:
val rdd1 = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt") -
通過已有的RDD經過運算元轉換生成新的RDD:
val rdd2=rdd1.flatMap(_.split(" ")) -
由一個已經存在的Scala集合創建:
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD方法底層調用了parallelize方法:

2. RDD的運算元分類
RDD的運算元分為兩類:
- Transformation轉換操作:返回一個新的RDD
- Action動作操作:返回值不是RDD(無返回值或返回其他的)
❣️注意:
1、RDD不實際存儲真正要計算的數據,而是記錄了數據的位置在哪裡,數據的轉換關係(調用了什麼方法,傳入什麼函數)。
2、RDD中的所有轉換都是惰性求值/延遲執行的,也就是說並不會直接計算。只有當發生一個要求返回結果給Driver的Action動作時,這些轉換才會真正運行。
3、之所以使用惰性求值/延遲執行,是因為這樣可以在Action時對RDD操作形成DAG有向無環圖進行Stage的劃分和並行優化,這種設計讓Spark更加有效率地運行。
3. Transformation轉換運算元
| 轉換運算元 | 含義 |
|---|---|
| map(func) | 返回一個新的RDD,該RDD由每一個輸入元素經過func函數轉換後組成 |
| filter(func) | 返回一個新的RDD,該RDD由經過func函數計算後返回值為true的輸入元素組成 |
| flatMap(func) | 類似於map,但是每一個輸入元素可以被映射為0或多個輸出元素(所以func應該返回一個序列,而不是單一元素) |
| mapPartitions(func) | 類似於map,但獨立地在RDD的每一個分片上運行,因此在類型為T的RDD上運行時,func的函數類型必須是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 類似於mapPartitions,但func帶有一個整數參數表示分片的索引值,因此在類型為T的RDD上運行時,func的函數類型必須是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根據fraction指定的比例對數據進行取樣,可以選擇是否使用隨機數進行替換,seed用於指定隨機數生成器種子 |
| union(otherDataset) | 對源RDD和參數RDD求並集後返回一個新的RDD |
| intersection(otherDataset) | 對源RDD和參數RDD求交集後返回一個新的RDD |
| distinct([numTasks])) | 對源RDD進行去重後返回一個新的RDD |
| groupByKey([numTasks]) | 在一個(K,V)的RDD上調用,返回一個(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一個(K,V)的RDD上調用,返回一個(K,V)的RDD,使用指定的reduce函數,將相同key的值聚合到一起,與groupByKey類似,reduce任務的個數可以通過第二個可選的參數來設置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 對PairRDD中相同的Key值進行聚合操作,在聚合過程中同樣使用了一個中立的初始值。和aggregate函數類似,aggregateByKey返回值的類型不需要和RDD中value的類型一致 |
| sortByKey([ascending], [numTasks]) | 在一個(K,V)的RDD上調用,K必須實現Ordered介面,返回一個按照key進行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 與sortByKey類似,但是更靈活 |
| join(otherDataset, [numTasks]) | 在類型為(K,V)和(K,W)的RDD上調用,返回一個相同key對應的所有元素對在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在類型為(K,V)和(K,W)的RDD上調用,返回一個(K,(Iterable |
| cartesian(otherDataset) | 笛卡爾積 |
| pipe(command, [envVars]) | 對rdd進行管道操作 |
| coalesce(numPartitions) | 減少 RDD 的分區數到指定值。在過濾大量數據之後,可以執行此操作 |
| repartition(numPartitions) | 重新給 RDD 分區 |
4. Action動作運算元
| 動作運算元 | 含義 |
|---|---|
| reduce(func) | 通過func函數聚集RDD中的所有元素,這個功能必須是可交換且可並聯的 |
| collect() | 在驅動程式中,以數組的形式返回數據集的所有元素 |
| count() | 返回RDD的元素個數 |
| first() | 返回RDD的第一個元素(類似於take(1)) |
| take(n) | 返回一個由數據集的前n個元素組成的數組 |
| takeSample(withReplacement,num, [seed]) | 返回一個數組,該數組由從數據集中隨機取樣的num個元素組成,可以選擇是否用隨機數替換不足的部分,seed用於指定隨機數生成器種子 |
| takeOrdered(n, [ordering]) | 返回自然順序或者自定義順序的前 n 個元素 |
| saveAsTextFile(path) | 將數據集的元素以textfile的形式保存到HDFS文件系統或者其他支援的文件系統,對於每個元素,Spark將會調用toString方法,將它裝換為文件中的文本 |
| saveAsSequenceFile(path) | 將數據集中的元素以Hadoop sequencefile的格式保存到指定的目錄下,可以使HDFS或者其他Hadoop支援的文件系統 |
| saveAsObjectFile(path) | 將數據集的元素,以 Java 序列化的方式保存到指定的目錄下 |
| countByKey() | 針對(K,V)類型的RDD,返回一個(K,Int)的map,表示每一個key對應的元素個數 |
| foreach(func) | 在數據集的每一個元素上,運行函數func進行更新 |
| foreachPartition(func) | 在數據集的每一個分區上,運行函數func |
統計操作:
| 運算元 | 含義 |
|---|---|
| count | 個數 |
| mean | 均值 |
| sum | 求和 |
| max | 最大值 |
| min | 最小值 |
| variance | 方差 |
| sampleVariance | 從取樣中計算方差 |
| stdev | 標準差:衡量數據的離散程度 |
| sampleStdev | 取樣的標準差 |
| stats | 查看統計結果 |
三、RDD的持久化/快取
在實際開發中某些RDD的計算或轉換可能會比較耗費時間,如果這些RDD後續還會頻繁的被使用到,那麼可以將這些RDD進行持久化/快取,這樣下次再使用到的時候就不用再重新計算了,提高了程式運行的效率。
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //快取/持久化
rdd2.sortBy(_._2,false).collect//觸發action,會去讀取HDFS的文件,rdd2會真正執行持久化
rdd2.sortBy(_._2,false).collect//觸發action,會去讀快取中的數據,執行速度會比之前快,因為rdd2已經持久化到記憶體中了
持久化/快取API詳解
- ersist方法和cache方法
RDD通過persist或cache方法可以將前面的計算結果快取,但是並不是這兩個方法被調用時立即快取,而是觸發後面的action時,該RDD將會被快取在計算節點的記憶體中,並供後面重用。
通過查看RDD的源碼發現cache最終也是調用了persist無參方法(默認存儲只存在記憶體中):

- 存儲級別
默認的存儲級別都是僅在記憶體存儲一份,Spark的存儲級別還有好多種,存儲級別在object StorageLevel中定義的。
| 持久化級別 | 說明 |
|---|---|
| MORY_ONLY(默認) | 將RDD以非序列化的Java對象存儲在JVM中。 如果沒有足夠的記憶體存儲RDD,則某些分區將不會被快取,每次需要時都會重新計算。 這是默認級別 |
| MORY_AND_DISK(開發中可以使用這個) | 將RDD以非序列化的Java對象存儲在JVM中。如果數據在記憶體中放不下,則溢寫到磁碟上.需要時則會從磁碟上讀取 |
| MEMORY_ONLY_SER (Java and Scala) | 將RDD以序列化的Java對象(每個分區一個位元組數組)的方式存儲.這通常比非序列化對象(deserialized objects)更具空間效率,特別是在使用快速序列化的情況下,但是這種方式讀取數據會消耗更多的CPU |
| MEMORY_AND_DISK_SER (Java and Scala) | 與MEMORY_ONLY_SER類似,但如果數據在記憶體中放不下,則溢寫到磁碟上,而不是每次需要重新計算它們 |
| DISK_ONLY | 將RDD分區存儲在磁碟上 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2等 | 與上面的儲存級別相同,只不過將持久化數據存為兩份,備份每個分區存儲在兩個集群節點上 |
| OFF_HEAP(實驗中) | 與MEMORY_ONLY_SER類似,但將數據存儲在堆外記憶體中。 (即不是直接存儲在JVM記憶體中) |
總結:
- RDD持久化/快取的目的是為了提高後續操作的速度
- 快取的級別有很多,默認只存在記憶體中,開發中使用memory_and_disk
- 只有執行action操作的時候才會真正將RDD數據進行持久化/快取
- 實際開發中如果某一個RDD後續會被頻繁的使用,可以將該RDD進行持久化/快取
四、RDD容錯機制Checkpoint
- 持久化的局限:
持久化/快取可以把數據放在記憶體中,雖然是快速的,但是也是最不可靠的;也可以把數據放在磁碟上,也不是完全可靠的!例如磁碟會損壞等。
- 問題解決:
Checkpoint的產生就是為了更加可靠的數據持久化,在Checkpoint的時候一般把數據放在在HDFS上,這就天然的藉助了HDFS天生的高容錯、高可靠來實現數據最大程度上的安全,實現了RDD的容錯和高可用。
用法:
SparkContext.setCheckpointDir("目錄") //HDFS的目錄
RDD.checkpoint
-
總結:
-
開發中如何保證數據的安全性性及讀取效率:
可以對頻繁使用且重要的數據,先做快取/持久化,再做checkpint操作。 -
持久化和Checkpoint的區別:
-
位置:
Persist 和 Cache 只能保存在本地的磁碟和記憶體中(或者堆外記憶體–實驗中)
Checkpoint 可以保存數據到 HDFS 這類可靠的存儲上。 -
生命周期:
Cache和Persist的RDD會在程式結束後會被清除或者手動調用unpersist方法
Checkpoint的RDD在程式結束後依然存在,不會被刪除。
五、RDD依賴關係
1. 寬窄依賴
- 兩種依賴關係類型:
RDD和它依賴的父RDD的關係有兩種不同的類型,即
寬依賴(wide dependency/shuffle dependency)
窄依賴(narrow dependency)

- 圖解:

- 如何區分寬窄依賴:
窄依賴:父RDD的一個分區只會被子RDD的一個分區依賴;
寬依賴:父RDD的一個分區會被子RDD的多個分區依賴(涉及到shuffle)。
2. 為什麼要設計寬窄依賴
- 對於窄依賴:
窄依賴的多個分區可以並行計算;
窄依賴的一個分區的數據如果丟失只需要重新計算對應的分區的數據就可以了。
- 對於寬依賴:
劃分Stage(階段)的依據:對於寬依賴,必須等到上一階段計算完成才能計算下一階段。
六、DAG的生成和劃分Stage
1. DAG介紹
- DAG是什麼:
DAG(Directed Acyclic Graph有向無環圖)指的是數據轉換執行的過程,有方向,無閉環(其實就是RDD執行的流程);
原始的RDD通過一系列的轉換操作就形成了DAG有向無環圖,任務執行時,可以按照DAG的描述,執行真正的計算(數據被操作的一個過程)。
- DAG的邊界
開始:通過SparkContext創建的RDD;
結束:觸發Action,一旦觸發Action就形成了一個完整的DAG。
2.DAG劃分Stage
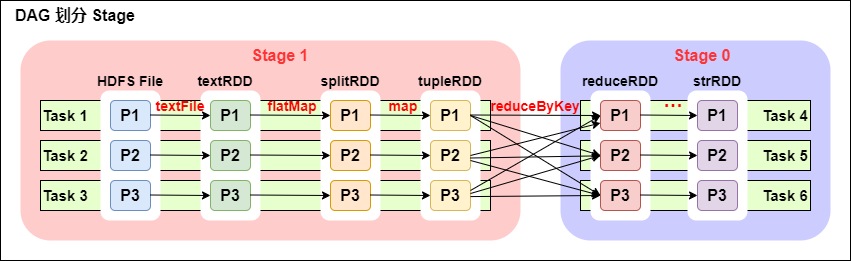
一個Spark程式可以有多個DAG(有幾個Action,就有幾個DAG,上圖最後只有一個Action(圖中未表現),那麼就是一個DAG)。
一個DAG可以有多個Stage(根據寬依賴/shuffle進行劃分)。
同一個Stage可以有多個Task並行執行(task數=分區數,如上圖,Stage1 中有三個分區P1、P2、P3,對應的也有三個 Task)。
可以看到這個DAG中只reduceByKey操作是一個寬依賴,Spark內核會以此為邊界將其前後劃分成不同的Stage。
同時我們可以注意到,在圖中Stage1中,從textFile到flatMap到map都是窄依賴,這幾步操作可以形成一個流水線操作,通過flatMap操作生成的partition可以不用等待整個RDD計算結束,而是繼續進行map操作,這樣大大提高了計算的效率。
- 為什麼要劃分Stage? –並行計算
一個複雜的業務邏輯如果有shuffle,那麼就意味著前面階段產生結果後,才能執行下一個階段,即下一個階段的計算要依賴上一個階段的數據。那麼我們按照shuffle進行劃分(也就是按照寬依賴就行劃分),就可以將一個DAG劃分成多個Stage/階段,在同一個Stage中,會有多個運算元操作,可以形成一個pipeline流水線,流水線內的多個平行的分區可以並行執行。
- 如何劃分DAG的stage?
對於窄依賴,partition的轉換處理在stage中完成計算,不劃分(將窄依賴盡量放在在同一個stage中,可以實現流水線計算)。
對於寬依賴,由於有shuffle的存在,只能在父RDD處理完成後,才能開始接下來的計算,也就是說需要要劃分stage。
總結:
Spark會根據shuffle/寬依賴使用回溯演算法來對DAG進行Stage劃分,從後往前,遇到寬依賴就斷開,遇到窄依賴就把當前的RDD加入到當前的stage/階段中
具體的劃分演算法請參見AMP實驗室發表的論文:
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
//xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se
文章推薦:
Spark底層執行原理詳細解析