有必要了解的大數據知識(二) Hadoop
前言
接上文,複習整理大數據相關知識點,這章節從MapReduce開始…
MapReduce介紹
MapReduce思想在生活中處處可見。或多或少都曾接觸過這種思想。MapReduce的思想核心是「分而治之」,適用於大量複雜的任務處理場景(大規模數據處理場景)。
Map負責「分」,即把複雜的任務分解為若干個「簡單的任務」來並行處理。可以進行拆分的前提是這些小任務可以並行計算,彼此間幾乎沒有依賴關係。
Reduce負責「合」,即對map階段的結果進行全局匯總。
MapReduce運行在yarn集群
- ResourceManager
- NodeManager
這兩個階段合起來正是MapReduce思想的體現。
MapReduce設計思想和架構
MapReduce是一個分散式運算程式的編程框架,核心功能是將用戶編寫的業務邏輯程式碼和自帶默認組件整合成一個完整的分散式運算程式,並發運行在Hadoop集群上。
Hadoop MapReduce構思:
分而治之
對相互間不具有計算依賴關係的大數據,實現並行最自然的辦法就是採取分而治之的策略。並行計算的第一個重要問題是如何劃分計算任務或者計算數據以便對劃分的子任務或數據塊同時進行計算。不可分拆的計算任務或相互間有依賴關係的數據無法進行並行計算!
統一構架,隱藏系統層細節
如何提供統一的計算框架,如果沒有統一封裝底層細節,那麼程式設計師則需要考慮諸如數據存儲、劃分、分發、結果收集、錯誤恢復等諸多細節;為此,MapReduce設計並提供了統一的計算框架,為程式設計師隱藏了絕大多數系統
層面的處理細節。
MapReduce最大的亮點在於通過抽象模型和計算框架把需要做什麼(what need to do)與具體怎麼做(how to do)分開了,為程式設計師提供一個抽象和高層的編程介面和框架。程式設計師僅需要關心其應用層的具體計算問題,僅需編寫少量的處理應用本身計算問題的程式程式碼。如何具體完成這個並行計算任務所相關的諸多系統層細節被隱藏起來,交給計算框架去處理:從分布程式碼的執行,到大到數千小到單個節點集群的自動調度使用。
構建抽象模型:Map和Reduce
MapReduce借鑒了函數式語言中的思想,用Map和Reduce兩個函數提供了高層的並行編程抽象模型
Map: 對一組數據元素進行某種重複式的處理;
Reduce: 對Map的中間結果進行某種進一步的結果整理。
Map和Reduce為程式設計師提供了一個清晰的操作介面抽象描述。MapReduce
處理的數據類型是鍵值對。
MapReduce中定義了如下的Map和Reduce兩個抽象的編程介面,由用戶去編程實現:
Map: (k1; v1) → [(k2; v2)]
Reduce: (k2; [v2]) → [(k3; v3)]
MapReduce 框架結構
一個完整的mapreduce程式在分散式運行時有三類實例進程:
- MRAppMaster 負責整個程式的過程調度及狀態協調
- MapTask 負責map階段的整個數據處理流程
- ReduceTask 負責reduce階段的整個數據處理流程
MapReduce編程規範
MapReduce 的開發一共有八個步驟, 其中 Map 階段分為 2 個步驟,Shuffle 階段 4個步驟,Reduce 階段分為 2 個步驟
Map 階段 2 個步驟
- 設置 InputFormat 類, 將數據切分為 Key-Value(K1和V1) 對, 輸入到第二步
- 自定義 Map 邏輯, 將第一步的結果轉換成另外的 Key-Value(K2和V2) 對, 輸出結果
Shuffle 階段 4 個步驟
- 對輸出的 Key-Value 對進行分區
- 對不同分區的數據按照相同的 Key 排序
- (可選) 對分組過的數據初步規約, 降低數據的網路拷貝
- 對數據進行分組, 相同 Key 的 Value 放入一個集合中
Reduce 階段 2 個步驟
- 對多個 Map 任務的結果進行排序以及合併, 編寫 Reduce 函數實現自己的邏輯, 對輸入的 Key-Value 進行處理, 轉為新的 Key-Value(K3和V3)輸出
- 設置 OutputFormat 處理並保存 Reduce 輸出的 Key-Value 數據
轉換為程式碼,例子如下
Map階段
public class WordCountMapper extends Mapper<Text,Text,Text, LongWritable> {
/**
* K1-----V1
* A -----A
* B -----B
* C -----C
*
* K2-----V2
* A -----1
* B -----1
* C -----1
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
context.write(key,new LongWritable(1));
}
}
Reduce階段
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
shuffle階段,舉一個分區的例子:
public class WordCountPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
if (text.toString().length() > 5) {
return 1;
}
return 0;
}
}
主方法
public class JobMain extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new JobMain(),args);
}
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "wordcout");
job.setJarByClass(JobMain.class);
//輸入
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/"));
//map
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//shuffle階段
job.setPartitionerClass(WordCountPartitioner.class);
job.setNumReduceTasks(2);
//reduce階段
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//輸出
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/"));
return 0;
}
}
MapTask運行機制
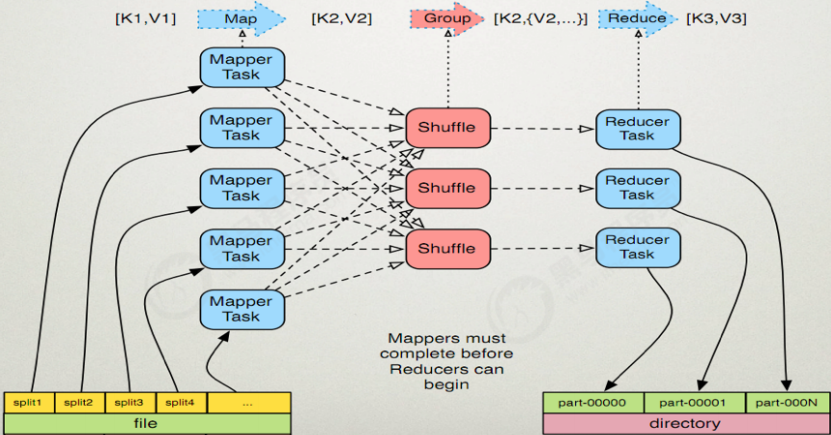
具體步驟:
- 讀取數據組件
InputFormat(默認TextInputFormat) 會通過getSplits方法對輸入目錄中文件進行邏輯切片規劃得到 splits, 有多少個 split 就對應啟動多少個MapTask.split與block的對應關係默認是一對一 - 將輸入文件切分為
splits之後, 由RecordReader對象 (默認是LineRecordReader)進行讀取, 以 \n 作為分隔符, 讀取一行數據, 返回<key,value> . Key表示每行首字元偏移值,Value表示這一行文本內容 - 讀取 split 返回 <key,value> , 進入用戶自己繼承的 Mapper 類中,執行用戶重寫的 map 函數, RecordReader 讀取一行這裡調用一次
- Mapper 邏輯結束之後, 將 Mapper 的每條結果通過 context.write 進行collect數據收集. 在 collect 中, 會先對其進行分區處理,默認使用 HashPartitioner。
MapReduce 提供 Partitioner 介面, 它的作用就是根據 Key 或 Value 及Reducer 的數量來決定當前的這對輸出數據最終應該交由哪個 Reduce task處理, 默認對 Key Hash 後再以 Reducer 數量取模. 默認的取模方式只是為了平均 Reducer 的處理能力, 如果用戶自己對 Partitioner 有需求, 可以訂製並設置到 Job 上。
- 接下來, 會將數據寫入記憶體, 記憶體中這片區域叫做環形緩衝區, 緩衝區的作用是批量收集Mapper 結果, 減少磁碟 IO 的影響. 我們的 Key/Value 對以及 Partition 的結果都會被寫入緩衝區. 當然, 寫入之前,Key 與 Value 值都會被序列化成位元組數組。
環形緩衝區其實是一個數組, 數組中存放著 Key, Value 的序列化數據和 Key,Value 的元數據資訊, 包括 Partition, Key 的起始位置, Value 的起始位置以及Value 的長度. 環形結構是一個抽象概念緩衝區是有大小限制, 默認是 100MB. 當 Mapper 的輸出結果很多時, 就可能會撐爆記憶體, 所以需要在一定條件下將緩衝區中的數據臨時寫入磁碟, 然後重新利用這塊緩衝區. 這個從記憶體往磁碟寫數據的過程被稱為 Spill, 中文可譯為溢寫. 這個溢寫是由單獨執行緒來完成, 不影響往緩衝區寫 Mapper 結果的執行緒.溢寫執行緒啟動時不應該阻止 Mapper 的結果輸出, 所以整個緩衝區有個溢寫的比例 spill.percent . 這個比例默認是 0.8, 也就是當緩衝區的數據已經達到閾值 buffer size * spill percent = 100MB * 0.8 = 80MB , 溢寫執行緒啟動,鎖定這 80MB 的記憶體, 執行溢寫過程. Mapper 的輸出結果還可以往剩下的20MB 記憶體中寫, 互不影響
- 當溢寫執行緒啟動後, 需要對這 80MB 空間內的 Key 做排序 (Sort). 排序是 MapReduce模型默認的行為, 這裡的排序也是對序列化的位元組做的排序
如果 Job 設置過 Combiner, 那麼現在就是使用 Combiner 的時候了. 將有相同 Key 的 Key/Value 對的 Value 加起來, 減少溢寫到磁碟的數據量.Combiner 會優化 MapReduce 的中間結果, 所以它在整個模型中會多次使用那哪些場景才能使用 Combiner 呢? 從這裡分析, Combiner 的輸出是Reducer 的輸入, Combiner 絕不能改變最終的計算結果. Combiner 只應該用於那種 Reduce 的輸入 Key/Value 與輸出 Key/Value 類型完全一致, 且不影響最終結果的場景. 比如累加, 最大值等. Combiner 的使用一定得慎重, 如果用好, 它對 Job 執行效率有幫助, 反之會影響 Reducer 的最終結果
- 合併溢寫文件, 每次溢寫會在磁碟上生成一個臨時文件 (寫之前判斷是否有 Combiner),如果 Mapper 的輸出結果真的很大, 有多次這樣的溢寫發生, 磁碟上相應的就會有多個臨時文件存在. 當整個數據處理結束之後開始對磁碟中的臨時文件進行 Merge 合併, 因為最終的文件只有一個, 寫入磁碟, 並且為這個文件提供了一個索引文件, 以記錄每個reduce對應數據的偏移量
ReduceTask工作機制
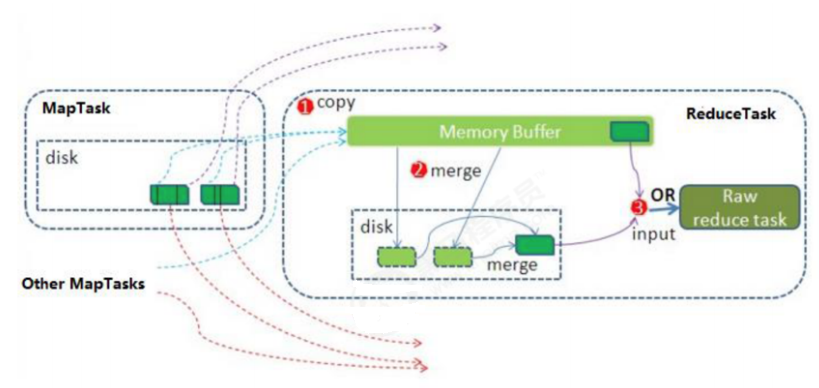
Reduce 大致分為 copy、sort、reduce 三個階段,重點在前兩個階段。copy 階段包含一個 eventFetcher 來獲取已完成的 map 列表,由 Fetcher 執行緒去 copy 數據,在此過程中會啟動兩個 merge 執行緒,分別為 inMemoryMerger 和 onDiskMerger,分別將記憶體中的數據 merge 到磁碟和將磁碟中的數據進行 merge。待數據 copy 完成之後,copy 階段就完成了,開始進行 sort 階段,sort 階段主要是執行 finalMerge 操作,純粹的 sort 階段,完成之後就是 reduce 階段,調用用戶定義的 reduce 函數進行處理
詳細步驟:
- Copy階段 ,簡單地拉取數據。Reduce進程啟動一些數據copy執行緒(Fetcher),通過HTTP方式請求maptask獲取屬於自己的文件。
- Merge階段 。這裡的merge如map端的merge動作,只是數組中存放的是不同map端copy來的數值。Copy過來的數據會先放入記憶體緩衝區中,這裡的緩衝區大小要比map端的更為靈活。merge有三種形式:記憶體到記憶體;記憶體到磁碟;磁碟到磁碟。默認情況下第一種形式不啟用。當記憶體中的數據量到達一定閾值,就啟動記憶體到磁碟的merge。與map 端類似,這也是溢寫的過程,這個過程中如果你設置有Combiner,也是會啟用的,然後在磁碟中生成了眾多的溢寫文件。第二種merge方式一直在運行,直到沒有map端的數據時才結束,然後啟動第三種磁碟到磁碟的merge方式生成最終的文件。
- 合併排序 。把分散的數據合併成一個大的數據後,還會再對合併後的數據排序。
- 對排序後的鍵值對調用reduce方法 ,鍵相等的鍵值對調用一次reduce方法,每次調用會產生零個或者多個鍵值對,最後把這些輸出的鍵值對寫入到HDFS文件中。
Shuffle具體流程
map 階段處理的數據如何傳遞給 reduce 階段,是 MapReduce 框架中最關鍵的一個流程,這個流程就叫 shuffle
shuffle: 洗牌、發牌 ——(核心機制:數據分區,排序,分組,規約,合併等過程)

- Collect階段 :將 MapTask 的結果輸出到默認大小為 100M 的環形緩衝區,保存的是key/value,Partition 分區資訊等。
- Spill階段 :當記憶體中的數據量達到一定的閥值的時候,就會將數據寫入本地磁碟,在將數據寫入磁碟之前需要對數據進行一次排序的操作,如果配置了 combiner,還會將有相同分區號和 key 的數據進行排序。
- Merge階段 :把所有溢出的臨時文件進行一次合併操作,以確保一個 MapTask 最終只產生一個中間數據文件。
- Copy階段 :ReduceTask 啟動 Fetcher 執行緒到已經完成 MapTask 的節點上複製一份屬於自己的數據,這些數據默認會保存在記憶體的緩衝區中,當記憶體的緩衝區達到一定的閥值的時候,就會將數據寫到磁碟之上。
- Merge階段 :在 ReduceTask 遠程複製數據的同時,會在後台開啟兩個執行緒對記憶體到本地的數據文件進行合併操作。
- Sort階段 :在對數據進行合併的同時,會進行排序操作,由於 MapTask 階段已經對數據進行了局部的排序,ReduceTask 只需保證 Copy 的數據的最終整體有效性即可。Shuffle 中的緩衝區大小會影響到 mapreduce 程式的執行效率,原則上說,緩衝區越大,磁碟io的次數越少,執行速度就越快
緩衝區的大小可以通過參數調整, 參數:mapreduce.task.io.sort.mb 默認100M


