C++如何解析函數調用
C語言是一個簡單的語言。用戶針對每一個函數,只能設置一個唯一的函數簽名。但是C++而言,就給了我們很多的靈活性:
- 你可以將多個函數設置為相同的名字(overloading)
- 你可以使用內置操作符重載(built-in operators),例如
+以及== - 你可以使用函數模版(function templates)
- 你也可以使用命名空間(namespaces)避免命名衝突
針對C++提供的這些特性,你可以實現str1 + str2返回兩個字元串的拼接;同樣,你也可以在一對2D點操作的基礎上,實現3D點對的操作,重載dot(a, b)來處理不同的類型。你可以寫一堆的數組類,並且實現一個sort函數模版,在所有的類上都適用。
但是,在我們充分利用這些特性時,往往很容易將事情推向錯誤的一面。在某些情況下,編譯器在接受我們的程式碼時,會給出如下的報錯:
error C2666: 'String::operator ==': 2 overloads have similar conversions
note: could be 'bool String::operator ==(const String &) const'
note: or 'built-in C++ operator==(const char *, const char *)'
note: while trying to match the argument list '(const String, const char *)'
和很多C++程式設計師一樣,我也經常苦惱與這樣的問題。每次出現這樣的報錯,我總是大腦一片空白,在網上查詢更好的理解,然後修改程式碼知道程式可以運行。在最近的一些項目開發中,我再次被這樣的問題阻擾;它變得和我認知中這類問題的理解完全對立,我因此意識到我對於這類問題的理解還不夠充分,仍有缺失。
幸運的是,如今是2021年了,網路資訊如此發達;在此,我尤其感謝cppreference.com,如今我知道我對於此類問題缺失的理解:一個隱藏演算法的清晰全貌,用來在編譯時的每一次函數調用。
這也是給定編譯器,一個函數調用表達式,準確計算出哪一個函數被調用:

上圖這些步驟隱藏在C++標準的背後,每一個C++編譯器都要遵循這些規則,並且這一系列的函數調用所涉及的程式表達式計算,都發生在編譯時。這也是C++能夠支援上面種種特性的原因。
我個人猜想,上圖整個演算法的意圖就是—-實施程式設計師所希望的操作,並且在某種程度上,它是成功的。作為程式設計師,在大部分時間和開發場景上,是完全可以忽略這些背後的演算法;但是,如果涉及開發一個庫,你最好了解這些規則。
所以,讓我們從入門到放棄(開玩笑)的了解這些背後的演算法機制,對於很多有經驗的C++程式設計師,本文聊到的內容都是相當熟悉的東西。此外,我也希望拋磚引玉,給大家帶來一些新穎的C++子話題,例如:參數獨立查詢和SFINAE,但是我們不會特別的深入探討這些字話題。因此,本文的定位,是給大家帶來C++函數調用在編譯時的一些列操作策略。
命名查詢
我們的旅途始於一個函數調用表達式,例如,採用這個表達式blast(ast, 100),這個表達式很明顯是調用一個函數叫做blast,但是實際是哪一個呢?
namespace galaxy {
struct Asteroid {
float radius = 12;
};
void blast(Asteroid* ast, float force);
}
struct Target {
galaxy::Asteroid* ast;
Target(galaxy::Asteroid* ast) : ast{ast} {}
operator galaxy::Asteroid*() const { return ast; }
};
bool blast(Target target);
template <typename T> void blast(T* obj, float force);
void play(galaxy::Asteroid* ast) {
blast(ast, 100);
}
回答這個問題的第一步叫做:命名查詢。在這一步,編譯器在編譯當下此時此刻,查詢出所有具有所給定查詢名稱的函數、函數模版和其他可被引用的標識符,如下圖。

如上述流圖所示,有三個主要被查詢的名稱類型,每一個都有各自的規則。
- 成員名稱查詢:發生在使用
.或者->的情況下,例如:foo->bar。這一類的查詢發生在類內局部成員中。 - 有修飾的名稱查詢:發生在一個名稱有
::符號進行修飾,例如:std::sort。這一類的名稱是確定的,只要到::符號的左邊範圍內去查詢右邊的名稱成員。 - 無修飾的名稱查詢:當編譯器看到一個沒有修飾的名稱,例如:
blast。編譯器在此時的上下文中查詢各種範圍內的匹配名稱,具體也有詳細的查詢規則。
我們的例子中,給出一個沒有修飾的名稱。那麼,當運算一個函數調用表達式,從而查詢一個名稱操作時,編譯器就可能找到多個聲明,我們把這些多個聲明都叫做候選。上述事例中,編譯器可以找到三個候選:

上圖中,圈出的第一個候選需要額外關注,因為它表明一個簡單的C++特性,也就是:參數依賴查詢—-ADL。正常情況下,你不希望這個函數作為候選,因為它是聲明在galaxy命名空間,而實際所調用的函數來自於galaxy外部的命名空間。並且,程式中沒有“using namespace galaxy“`指令使得此命名空間內的函數可見,所以,為什麼這樣的候選成立?
原因就是, 任何時刻,當你使用一個沒有修飾符的名稱在一個函數調用過程中,並且這個名稱不是引用一個類成員,此時ADL引入,可以更加廣泛的查詢符合的候選。特別的,在一般使用情況下,編譯器會在參數類型的命名空間中查詢合適的候選函數,也就符合「參數依賴查詢」的意思。

完整的ADL規則,有著更加詳細的差異描述,但是,可以確定的是,ADL只適用於無修飾的名稱。對於有修飾的名稱,也就是在單個範圍內查詢,那麼使用ADL規則是沒有意義的。ADL同樣適用於重載內置操作符,例如:+和==。有趣的是,很多情況下,成員名稱查詢可以找很多未修飾的名稱候選,詳細看這篇博文。
函數模版的特殊具柄
通過名稱查詢的一些候選是函數,另外則是函數模版。對於函數模版存在一個問題:我們無法調用它們,我們只能調用函數。因此,在名稱查詢後,編譯器遍歷每一個候選,並試圖將每一個函數模版轉為函數。
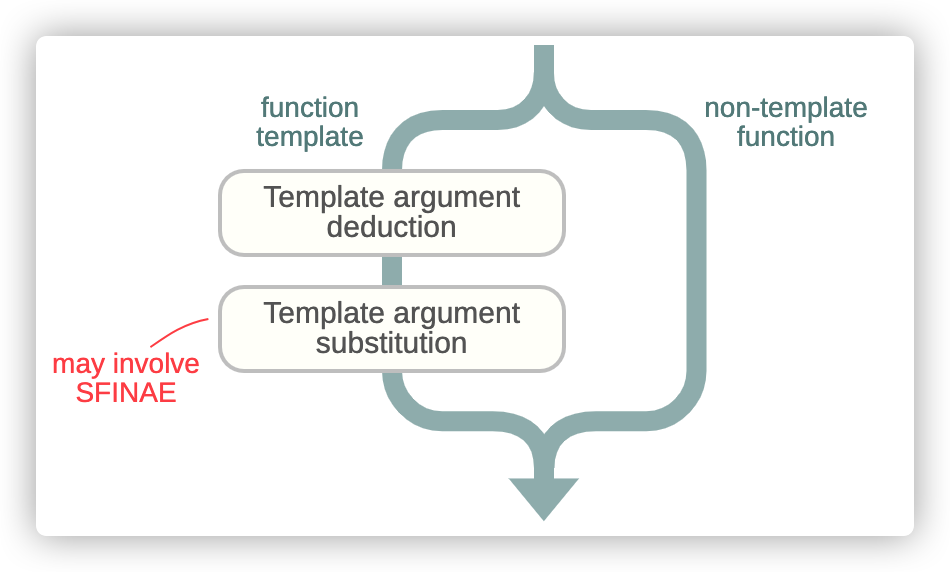
上面,我們給出的示例中,存在一個候選就是函數模版:
template <typename T> void blast(T* obj, float force);
這個函數模版僅有一個模版參數T,因此,當調用者blast(ast, 100)沒有指定任何模版參數,但是,編譯器又必須將函數模版轉為函數,所以需要搞清楚類型T,這也就是模版參數推理。在這一步,編譯器將由調用者傳入的函數參數和函數模版所期望的函數參數所對比;如果任何未指定的模版參數被引用了,例如:T,那麼,編譯器就嘗試使用左邊的資訊去推理它。
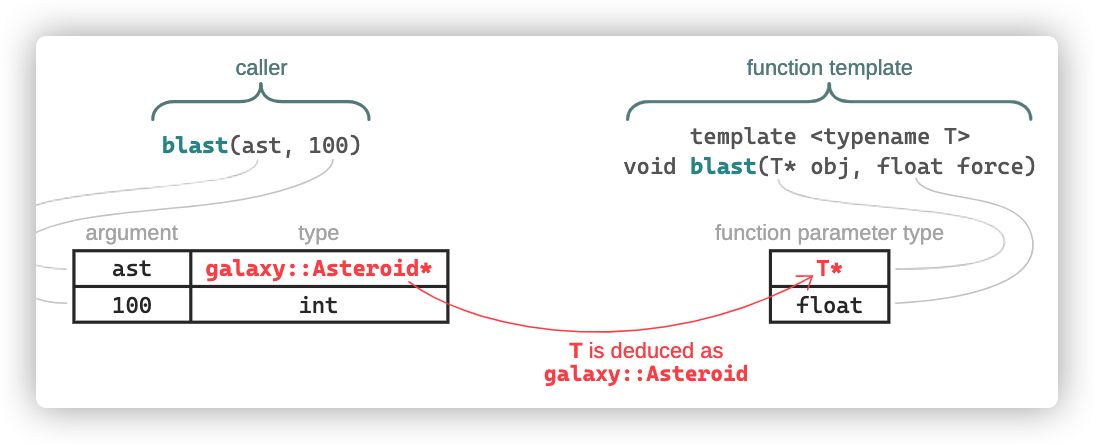
上圖中,編譯器將T推理為galaxy::Asteroid,因為只有這樣做,可以將多一個函數參數T*匹配到參數ast。模版參數推理規則總結,詳細的介紹了相關內容。但是,在一些情況下,如果模版推理不能有效進行,也就是編譯器找不到合適的模版參數匹配到調用者參數類型,那麼函數模版就被從候選者列表中移除。
在候選列表中的所有函數模版生命周期到這一步結束:模版參數替換。在這一步,編譯器接受函數模版聲明,並用對應的模版參數替換掉每個模版參數出現的地方。在我們的例子中,模版參數T被它所推理的galaxy::Asteroid類型替換掉,如果這一步成功實施,我們最終可以獲得能夠被調用的函數簽名—-而不在是函數模版。

當然,存在一些情況下,模版參數替換失敗。假設下面的情況,相同的函數模版接受一個第三個參數:
template <typename T> void blast(T* obj, float force, typename T::units mass=5000);
那麼,編譯器會使用galaxy::Asteroid來替換T::units中的T。而結果表達式就是,galaxy::Asteroid::Units,這樣是無效的,因為galaxy::Asteroid沒有一個叫做Units的成員,因此,此次的模版參數替換失敗。
當模版參數替換失敗,那麼函數模版就被移除出候選列表;在C++歷史中的某些時刻,人們意識到這樣的特性是可以挖掘利用的,這樣的發現導致了整個模版元編程技術的出現,常被稱作SFINAE(substitution failure is not an error)。
重載解析
在這個階段,通過名稱查詢的所有函數模版都已經消失,我們獲得了一組乾淨、漂亮的候選函數,它們也同樣被稱為重載組。下面就是我們例子中的重載組:

接下來兩步就是縮小這個集合,通過決定哪個候選函數可以保留,也就是說,哪一個候選函數可以處理函數調用。
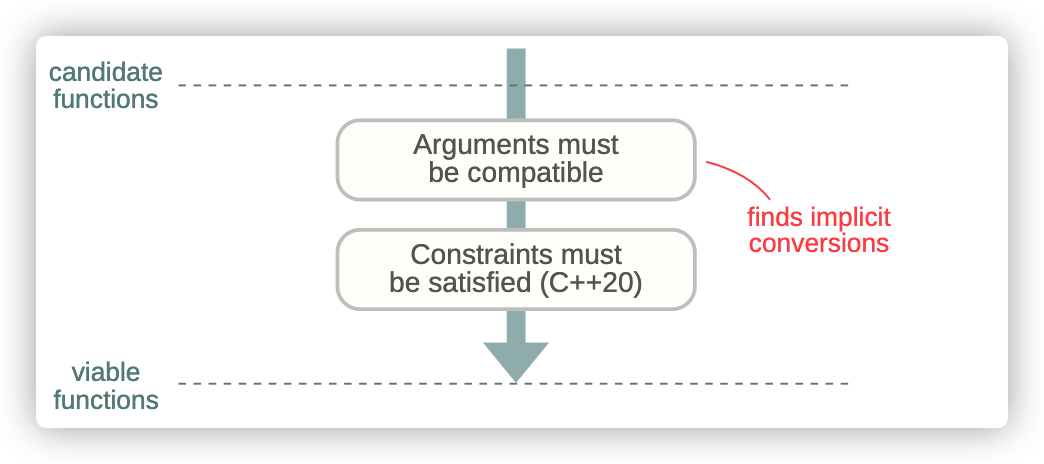
或許,最顯而易見的要求就是,參數必須匹配;這也就是說,一個保留函數,應該能夠接受調用者的參數。如果,調用者的參數類型和實際的函數參數類型不匹配,它至少是可以實現隱式轉換每個參數到與之要對應的參數類型。讓我們看看給出的例子中的候選函數,是否有與之匹配的參數:

候選1
調用者第一個參數類型是galaxy::Asteroid*,可以實現完全匹配。調用者第二個參數類型是int,可以通過隱式轉化實現到float類型的轉化,因此,候選1的參數是匹配的。
候選2
調用者第一個參數類型是galaxy::Asteroid*,可以隱式的轉為函數參數類型Taeget,因為Target有一個轉化構造函數,可以接受galaxy::Asteroid*類型的參數。然而,調用者傳入了兩個參數,候選2隻可以接受一個參數,可以候選2被剔除。
候選3
候選3的參數類型等同於候選1,所以,它也是匹配的。
最後的決策
在這一步,我們的例子只剩下最後兩個保留的函數:

實際上,如果上圖兩個候選中,任意一個被保留下來,那麼它就是最後執行函數調用的具柄。但是由於最後還有兩個候選,編譯器必須在多個候選中進一步進行操作:它必須決定哪一個是更好的候選函數。為了成為最好的候選函數,它們當中必須有一個更加的匹配,這就是由決勝者規則序列決定的:

下面給出三條決勝者規則:
首要決勝者:參數最匹配者勝出
C++強調了調用者參數類型和函數參數類型匹配程度的重要性,寬泛來說,編譯器傾向選擇函數需要較少隱式類型轉換的的候選函數。這條規則決定了我們在使用std::vector中的const和non-const版本的選擇。
在我們的例子中,由於兩個候選函數的參數類型都一致,所以,第一條規則都滿足。
第二決勝者:非模版參數勝出
如果第一條規則沒有決出勝負,那麼C++傾向於調用非模版函數。在我們的例子中,由於候選1是非模版函數,而候選2是模版函數,因此,我們的最優函數就是:
void galaxy::blast(galaxy::Asteroid* ast, float force)
值得重申的是,如果有一個模版函數在參數類型上更加匹配,那麼該模版函數勝出,也就是說,決勝者規則的優先順序是按順序遞降的。
第三決勝者:更加特定的模版勝出
我們的例子中,最優的候選函數已經獲得,但是如果沒有得的話,那麼我們就要參考第三決勝者規則。這條規則中,C++傾向於調用「更加特定」的模版函數,例如,考慮下面兩個函數模版:
template <typename T> void blast(T obj, float force);
template <typename T> void blast(T* obj, float force);
在進行模版參數推理步驟時,第一個函數模版接受任意類型作為它的第一個參數,而第二個函數模版僅僅接受指針類型。因此,第二個函數模版被稱為更加特定。因此,編譯器傾向於選擇第二個候選函數作為最優函數。
函數調用解析之後
在此時,編譯器已經準確知道了哪一個函數應該作為表達式blast(ast, 100)的句柄了。在許多例子中,雖然,編譯器在解析函數調用後還有很多工作要完成:
- 如果被調用的函數是一個類成員,編譯器必須檢查類成員的訪問修飾符,來判斷是否有權訪問調用者。
- 如果被調用函數是一個模版函數,編譯器必須實例化這個模版函數。
- 如果被調用的函數是虛函數,編譯器需要生成特殊的機器指令,實現在運行時保證重載準確調用。


