自然語言處理之文本情感分類
一、概述
文本情感分析(Sentiment Analysis)是指利用自然語言處理和文本挖掘技術,對帶有情感色彩的主觀性文本進行分析、處理和抽取的過程。情感分析任務按其分析的粒度可以分為篇章級,句子級,詞或短語級;按其處理文本的類別可分為基於產品評論的情感分析和基於新聞評論的情感分析;按其研究的任務類型,可分為情感分類,情感檢索和情感抽取等子問題。文本情感分析的基本流程如下圖所示,包括從原始文本爬取,文本預處理,語料庫和情感詞庫構建以及情感分析結果等全流程。

情感分類又稱情感傾向性分析,是對帶有感情色彩的主觀性文本進行分析、推理的過程,即分析對說話人的態度,傾向正面,還是反面。它與傳統的文本主題分類又不相同,傳統主題分類是分析文本討論的客觀內容,而情感分類是要從文本中得到它是否支援某種觀點的資訊。比如,「日媒:認為殲-31能夠抗衡F-35,這種說法頗具恭維的意味。」傳統主題分類是要將其歸為類別為「軍事」主題,而情感分類則要挖掘出日媒對於「殲-31能夠抗衡F-35」這個觀點,持反面態度。這是一項具有較大實用價值的分類技術,可以在一定程度上解決網路評論資訊雜亂的現象,方便用戶準確定位所需資訊。按照處理文本的粒度不同,情感分析可分為詞語級、短語級、句子級、篇章級以及多篇章級等幾個研究層次。按照處理文本的類別不同,可分為基於新聞評論的情感分析和基於產品評論的情感分析。縱觀目前主觀性文本情感傾向性分析的研究工作,主要研究思路分為基於語義的情感詞典方法和基於機器學習的方法。
二、基於情感詞典的情感分類方法
2.1 基於詞典的情感分類步驟
基於情感詞典的方法,先對文本進行分詞和停用詞處理等預處理,再利用先構建好的情感詞典,對文本進行字元串匹配,從而挖掘正面和負面資訊。如圖:

2.2 文本預處理及自動分詞
文本的預處理
由網路爬蟲等工具爬取到的原始語料,通常都會帶有我們不需要的資訊,比如額外的Html標籤,所以需要對語料進行預處理。在《文本情感分類(一):傳統模型》一文中,筆者使用Python作為我們的預處理工具,其中的用到的庫有Numpy和Pandas,而主要的文本工具為正則表達式。經過預處理,原始語料規範為如下表,其中我們用-1標註消極情感評論,1標記積極情感評論。
句子自動分詞
為了判斷句子中是否存在情感詞典中相應的詞語,我們需要把句子準確切割為一個個詞語,即句子的自動分詞。
2.3 情感詞典
情感詞典包含正面詞語詞典、負面詞語詞典、否定詞語詞典、程度副詞詞典等四部分。一般詞典包含兩部分,詞語和權重。

情感詞典在整個情感分析中至關重要,所幸現在有很多開源的情感詞典,如BosonNLP情感詞典,它是基於微博、新聞、論壇等數據來源構建的情感詞典,以及知網情感詞典等。當然也可以通過語料來自己訓練情感詞典。
2.4 情感詞典文本匹配演算法
基於詞典的文本匹配演算法相對簡單。逐個遍歷分詞後的語句中的詞語,如果詞語命中詞典,則進行相應權重的處理。正面詞權重為加法,負面詞權重為減法,否定詞權重取相反數,程度副詞權重則和它修飾的詞語權重相乘。如圖:

利用最終輸出的權重值,就可以區分是正面、負面還是中性情感了。
2.5 缺點
基於詞典的情感分類,簡單易行,而且通用性也能夠得到保障。但仍然有很多不足:
1)精度不高:語言是一個高度複雜的東西,採用簡單的線性疊加顯然會造成很大的精度損失。詞語權重同樣不是一成不變的,而且也難以做到準確。
2)新詞發現: 對於新的情感詞,比如給力,牛逼等等,詞典不一定能夠覆蓋。
3)詞典構建難: 基於詞典的情感分類,核心在於情感詞典。而情感詞典的構建需要有較強的背景知識,需要對語言有較深刻的理解,在分析外語方面會有很大限制。
三、基於機器學習的情感分類方法
基於機器學習的情感分類即為分類問題,文本分類中的各方法均可採用,文本分類問題可查看我的另外一篇文章《自然語言處理之文本分類》。
常見的分類演算法有,基於統計的Rocchio演算法、貝葉斯演算法、KNN演算法、支援向量機方法,基於規則的決策樹方法,和較為複雜的神經網路。這裡我們介紹兩種用到的分類演算法:樸素貝葉斯和支援向量機。情感分類模型的構建方法也很多,這裡我們對《自然語言處理系列篇–情感分類》中的建模方法進行總結。
3.1 分類演算法
3.1.1 樸素貝葉斯
貝葉斯公式:$P(C|X)=P(X|C)P(C)/P(X)$
先驗概率P(C)通過計算訓練集中屬於每一個類的訓練樣本所佔的比例,類條件概率P(X|C)的估計—樸素貝葉斯,假設事物屬性之間相互條件獨立,$P(X|C)=\prod P(x_{i}|c_{i})$。樸素貝葉斯有兩用常用的模型,概率定義略有不同,如下:設某文檔d=(t1,t2,…,tk),tk是該文檔中出現過的單詞,允許重複。
- 多項式模型:
先驗概率P(c)= 類c下單詞總數/整個訓練樣本的單詞總數。
條件概率P(tk|c)=(類c下單詞tk在各個文檔中出現過的次數之和+1)/( 類c下單詞總數+|V|)
- 伯努利模型:
先驗概率P(c)= 類c下文件總數/整個訓練樣本的文件總數。
條件概率P(tk|c)=(類c下包含單詞tk的文件數+1)/(類c下單詞總數+2)
通俗點解釋兩種模型不同點在於:計算後驗概率時,對於一個文檔d,多項式模型中,只有在d中出現過的單詞,才會參與後驗概率計算,伯努利模型中,沒有在d中出現,但是在全局單詞表中出現的單詞,也會參與計算,不過是作為「反例」參與的。
3.1.2 支援向量機模型SVM
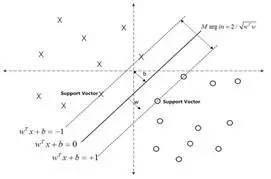
SVM展開來說較為複雜,這裡藉助兩張圖幫助概念性地解釋一下。對於線性可分的數據,可以用一超平面f(x)=w*x+b將這兩類數據分開。如何確定這個超平面呢?從直觀上而言,這個超平面應該是最適合分開兩類數據的直線。而判定「最適合」的標準就是這條直線離直線兩邊的數據的間隔最大。
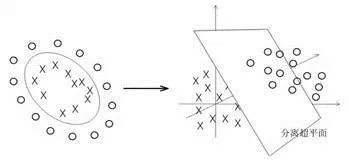
而對於線性不可分的數據,則將其映射到一個更高維的空間里,在這個空間里建立尋找一個最大間隔的超平面。怎麼映射呢?這就是SVM的關鍵:核函數。
現在常用的核函數有:線性核,多項式核,徑向基核,高斯核,Sigmoid核。如果想對SVM有更深入的了解,請參考《支援向量機通俗導論(理解SVM的三層境界)》一文。
3.2 情感分類系統的實現
情感分類主要處理一些類似評論的文本,這類文本有以下幾個特點:時新性、短文本、不規則表達、資訊量大。我們在系統設計、演算法選擇時都會充分考慮到這些因素。情感分灰系統分為在線、離線兩大流程,在線流程將用戶輸出的語句進行特徵挖掘、情感分類、並返回結果。離線流程則負責語料下載、特徵挖掘、模型訓練等工作,系統結構如圖3-1所示:
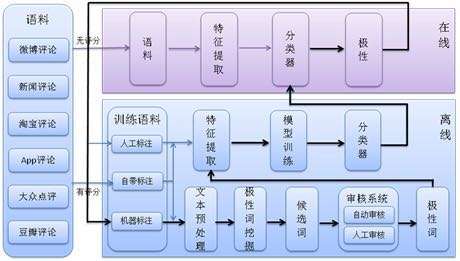
圖3-1 情感分類系統框架圖
3.2.1 語料庫建設
語料的積累是情感分類的基石,特徵挖掘、模型分類都要以語料為材料。而語料又分為已標註的語料和未標註的語料,已標註的語料如對商家的評論、對產品的評論等,這些語料可通過星級確定客戶的情感傾向;而未標註的語料如新聞的評論等,這些語料在使用前則需要分類模型或人工進行標註,而人工對語料的正負傾向,又是仁者見仁、智者見智,所以一定要與標註的同學有充分的溝通,使標註的語料達到基本可用的程度。
3.2.2極性詞挖掘
情感分類中的極性詞挖掘,有一種方法是「全詞表法」,即將所有的詞都作為極性詞,這樣的好處是單詞被全面保留,但會導致特徵維度大,計算複雜性高。我們採用的是「極性詞表法」,就是要從文檔中挖掘出一些能夠代表正負極性的詞或短語。如已知正面語料「@jjhuang:微信電話本太贊了!能免費打電話,推薦你使用哦~」,這句話中我們需要挖掘出「贊」、「推薦」這些正極性詞。分為以下兩步:
1)文本預處理 語料中的有太多的噪音,我們在極性詞挖掘之前要先對文本預處理。文本預處理包含了分詞、去噪、最佳匹配等相關技術。分詞功能向大家推薦騰訊TE199的分詞系統,功能強大且全面,擁有短語分詞、詞性標註等強大功能。去噪需要去掉文檔中的無關資訊如「@jjhuang」、html標籤等,和一些不具有分類意義的虛詞、代詞如「的」、「啊」、「我」等,以起到降維的作用。最佳匹配則是為了確保提出的特徵能夠正確地反映正負傾向,如「逍遙法外」一詞,如果提取出的是「逍遙」一詞,則會被誤認為是正面情感特徵,而「逍遙法外」本身是一個負面情感詞,這裡一般可以採用最長匹配的方法。
2)極性詞選擇 文本預處理之後,我們要從眾多詞語中選出一些詞作為極性詞,用以訓練模型。我們對之前介紹的TF-IDF方法略作變化,用以降維。因為我們訓練和處理的文本都太短,DF和TF值大致相同,我們用一個TF值就可以。另外,我們也計算極性詞在反例中出現的頻率,如正極性詞「贊」必然在正極性語料中的TF值大於在負極性語料中的TF值,如果二者的差值大於某個域值,我們就將該特徵納入極性詞候選集,經過人工審核後,就可以正式作為極性詞使用。
3.2.3極性判斷
極性判斷的任務是判斷語料的正、負、中極性,這是一個複雜的三分類問題。為了將該問題簡化,我們首先對語料做一個主客觀判斷,客觀語料即為中性語料,主觀語料再進行正、負極性的判斷。這樣,我們就將一個複雜三分類問題,簡化成了兩個二分類問題。如下:
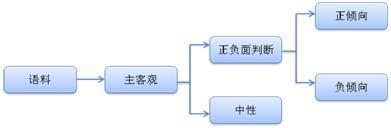
在分類器選擇中,主客觀判斷我們使用了上節介紹的支援向量機模型。而極性判斷中,我們同時使用了樸素貝葉斯和支援向量機模型。其中樸素貝葉斯使用人工審核過的極性詞作特徵,而支援向量機模型則使用全詞表作為特徵。兩個模型會對輸入的語料分別判斷,給出正、負極性的概率,最後由決策模組給出語料的極性。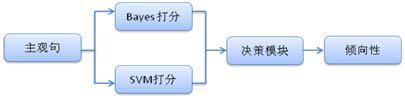
在樸素貝葉斯模型中,我們比較了多項式模型和伯努力模型的效果。伯努力模型將全語料中的單詞做為反例計算,因為評測文本大多是短文本,導致反例太多。進而伯努力模型效果稍差於多項式模型,所以我們選擇了多項式模型。
支援向量機模型中,我們使用的是台灣大學林智仁開發的SVM工具包LIBSVM,這是一個開源的軟體包,可以解決模式識別、函數逼近和概率密度估計等機器學習基本問題,提供了線性、多項式、徑向基和S形函數四種常用的核函數供選擇。LIBSVM 使用的一般步驟是:
- 按照LIBSVM軟體包所要求的格式準備數據集;
- 對數據進行簡單的縮放操作;
- 考慮選用RBF 核函數;
- 採用交叉驗證選擇最佳參數C與g;
- 採用最佳參數C與g 對整個訓練集進行訓練獲取支援向量機模型;
- 利用獲取的模型進行測試與預測。
上述介紹的是我們通用的情感分類系統,面對的是通用的主觀評論語料。但在一些領域中,某些非極性詞也充分表達了用戶的情感傾向,比如下載使用APP時,「卡死了」、「下載太慢了」就表達了用戶的負面情感傾向;股票領域中,「看漲」、「牛市」表達的就是用戶的正面情感傾向。所以我們要在垂直領域中,挖掘出一些特殊的表達,作為極性詞給情感分類系統使用:
垂直極性詞 = 通用極性詞 + 領域特有極性詞
該系統即為垂直領域的情感分類系統。
3.3 系統優化
情感分類的工作,在現在和未來還可以做更多的工作來對系統進行優化:
- 挖掘更多的極性詞(多領域)
- 嘗試不同的分類器,調優現有的模型
- 句式識別:否定句,轉折句,排比句等……
- 語料清洗:識別水軍評論和用戶評論
- 極性詞擴展:採用近義詞、反義詞等方法,將挖掘的極性詞擴展更多
參考:
//blog.csdn.net/weixin_42398658/article/details/85222547
//blog.csdn.net/weixin_41657760/article/details/93163519
//zhuanlan.zhihu.com/p/25868008