MindSpore:基於本地差分隱私的 Bandit 演算法
摘要:本文將先簡單介紹Bandit 問題和本地差分隱私的相關背景,然後介紹基於本地差分隱私的 Bandit 演算法,最後通過一個簡單的電影推薦場景來驗證 LDP LinUCB 演算法。
Bandit問題是強化學習中一類重要的問題,由於它定義簡潔且有大量的理論分析,因此被廣泛應用於新聞推薦,醫學試驗等實際場景中。隨著人類進入大數據時代,用戶對自身數據的隱私性日益重視,這對機器學習演算法的設計提出了新的挑戰。為了在保護隱私的情況下解決 Bandit 這一經典問題,北京大學和華為諾亞方舟實驗室聯合提出了基於本地差分隱私的 Bandit 演算法,論文已被 NeurIPS 2020 錄用,程式碼已基於 MindSpore 開源首發。
本文將先簡單介紹 Bandit 問題和本地差分隱私的相關背景,然後介紹基於本地差分隱私的 Bandit 演算法,最後通過一個簡單的電影推薦場景來驗證 LDP LinUCB 演算法。

大家都有過這樣的經歷,在我們刷微博或是讀新聞的時候,經常會看到一些系統推薦的內容,這些推薦的內容是根據用戶對過往推薦內容的點擊情況以及閱讀時長等回饋來產生的。在這個過程里,系統事先不知道用戶對各種內容的偏好,通過不斷地與用戶進行交互(推薦內容 — 得到回饋),來慢慢學習到用戶的偏好特徵,不斷提高推薦的精準性,從而最大化用戶的價值,這就是一個典型的 Bandit 問題。
Bandit 問題有 context-free 和 contextual 兩種常見的設定,下面給出它們具體的數學定義。
【Context-Free Bandit】

【Contextual Bandit】


傳統的差分隱私技術(Differential Privacy,DP)是將用戶數據集中到一個可信的數據中心,在數據中心對用戶數據進行匿名化使其符合隱私保護的要求後,再分發給下游使用,我們將其稱之為中心化差分隱私。但是,一個絕對可信的數據中心很難找到,因此人們提出了本地差分隱私技術(Local Differential Privacy,LDP),它直接在客戶端進行數據的隱私化處理後再提交給數據中心,徹底杜絕了數據中心泄露用戶隱私的可能。
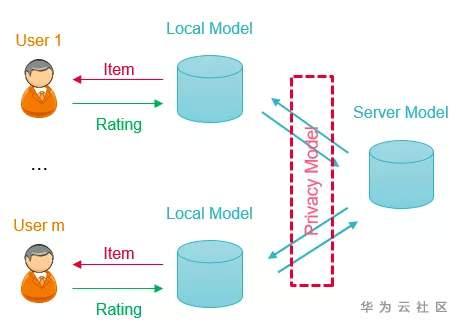


Context-Free Bandit


我們可以證明,上述演算法有如下的性能:

根據上述定理,我們只需將任一非隱私保護的演算法按照演算法 1 進行改造,就立即可以得到對應的隱私保護版本的演算法,且它的累積 regret 的理論上界和非隱私演算法只相差一個
![]()
因子,因此演算法 1 具有很強的通用性。我們將損失函數滿足不同凸性和光滑性條件下的 regret 簡單羅列如下:

上述演算法和結論可以擴展到每一輪能觀測多個動作損失值的情況,感興趣的可以參見論文(//arxiv.org/abs/2006.00701)。
Contextual Bandit


【定理】 依照至少為
![]()
的概率,LDP LinUCB 演算法的 regret 滿足如

上述演算法和結論可以擴展到 gg 不是恆等變換的情況,感興趣的可以參見論文(//arxiv.org/abs/2006.00701)。

MovieLens 是一個包含多個用戶對多部電影評分的公開數據集,我們可以用它來模擬電影推薦。我們通過src/dataset.py 來構建環境:我們從數據集中抽取一部分有電影評分數據的用戶,然後將評分矩陣通過 SVD 分解來補全評分數據,並將分數歸一化到[−1,+1]。在每次交互的時候,系統隨機抽取一個用戶,推薦演算法獲得特徵,並選擇一部電影進行推薦,MovieLensEnv會在打分矩陣中查詢該用戶對電影對評分並返回,從而模擬用戶給電影打分。
class MovieLensEnv: def observation(self): """random select a user and return its feature.""" sampled_user = random.randint(0, self._data_matrix.shape[0] - 1) self._current_user = sampled_user return Tensor(self._feature[sampled_user]) def current_rewards(self): """rewards for current user.""" return Tensor(self._approx_ratings_matrix[self._current_user])

import mindspore.nn as nn class LinUCB(nn.Cell): def __init__(self, context_dim, epsilon=100, delta=0.1, alpha=0.1, T=1e5): ... # Parameters self._V = Tensor(np.zeros((context_dim, context_dim), dtype=np.float32)) self._u = Tensor(np.zeros((context_dim,), dtype=np.float32)) self._theta = Tensor(np.zeros((context_dim,), dtype=np.float32))
每來一個用戶,LDP LinUCB 演算法根據用戶和電影的聯合特徵x基於當前的模型來選擇最優的電影a_max做推薦,並傳輸帶雜訊的更新量:

import mindspore.nn as nn class LinUCB(nn.Cell):... def construct(self, x, rewards): """compute the perturbed gradients for parameters.""" # Choose optimal action x_transpose = self.transpose(x, (1, 0)) scores_a = self.squeeze(self.matmul(x, self.expand_dims(self._theta, 1))) scores_b = x_transpose * self.matmul(self._Vc_inv, x_transpose) scores_b = self.reduce_sum(scores_b, 0) scores = scores_a + self._beta * scores_b max_a = self.argmax(scores) xa = x[max_a] xaxat = self.matmul(self.expand_dims(xa, -1), self.expand_dims(xa, 0)) y = rewards[max_a] y_max = self.reduce_max(rewards) y_diff = y_max - y self._current_regret = float(y_diff.asnumpy()) self._regret += self._current_regret # Prepare noise B = np.random.normal(0, self._sigma, size=xaxat.shape) B = np.triu(B) B += B.transpose() - np.diag(B.diagonal()) B = Tensor(B.astype(np.float32)) Xi = np.random.normal(0, self._sigma, size=xa.shape) Xi = Tensor(Xi.astype(np.float32)) # Add noise and update parameters return xaxat + B, xa * y + Xi, max_a
系統收到更新量之後,更新模型參數如下:
import mindspore.nn as nn class LinUCB(nn.Cell):... def server_update(self, xaxat, xay): """update parameters with perturbed gradients.""" self._V += xaxat self._u += xay self.inverse_matrix() theta = self.matmul(self._Vc_inv, self.expand_dims(self._u, 1)) self._theta = self.squeeze(theta)

我們測試不同的 \varepsilonε 對累積 regret 對影響:
- x 軸:交互輪數
- y 軸:累積 regret
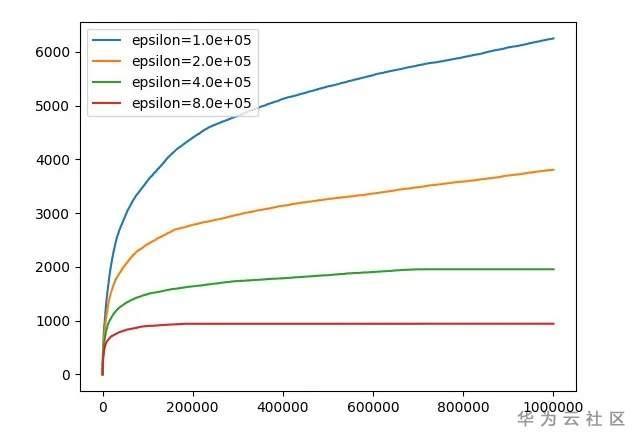
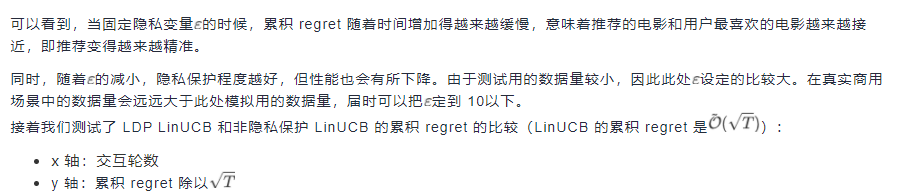
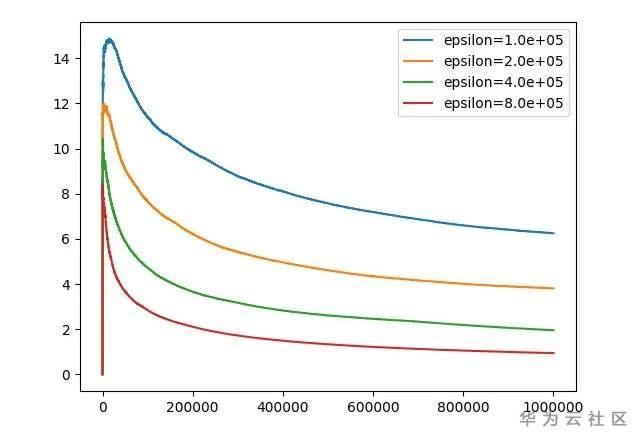

相關模型程式碼已上線 MindSpore Model Zoo://gitee.com/mindspore/mindspore/tree/master/model_zoo感興趣的可自行體驗。
1. Kai Zheng, Tianle Cai, Weiran Huang, Zhenguo Li, Liwei Wang. “Locally Differentially Private (Contextual) Bandits Learning.” Advances in Neural Information Processing Systems. 2020.
2. LDP LinUCB 程式碼:
//gitee.com/mindspore/mindspore/tree/master/model_zoo/research/rl/ldp_linucb
本文分享自華為雲社區《MindSpore 首發:隱私保護的 Bandit 演算法,實現電影推薦》,原文作者:chengxiaoli。


