正則表達式取值方法歸納
如,某站點介面請求返回值如下:
{"Code":0,"Msg":"獲取成功","Data":
{"Total":1,"DataList":
[{"Id":11564XXXX4368,
"TopIsAgent":false,
"IsAnchor":true,
"FirstTwitterId":1156XXX368,
"FirstTwitterName":"貝克漢姆",
"FirstTwitterRemark":"小貝960",
"FirstTwitterTelephone":"1867XXXX640",
"IsTwitter":true,
"HeadImgUrl":"//wx.qlogo.cn/mmopen/vi_32/DYAIOgqXXXXyXXX2ov4UzAxA/132",
"NickName":"貝克漢姆",
"Remark":"小貝960",
"WxRemark":null,
"Telephone":"1867XXXX640",
"LastBuyTime":"2021-03-06 11:25:38",
"Source":1,
"MemberSourceStr":"小程式授權登錄",
"TotalPoints":185200,
"TotalFee":10030866.84,
"TotalFeeNum":292,
"SingleFee":34352.283698630136986301369863,
"CustomerType":"會員",
"Tags":[{"Id":11668,"Name":"規格","TagType":2}],
"SystemTagType":"成交客戶",
"Cards":[{"Id":987,"Name":"會員卡測試會員卡測"}],
"CustomerTime":"2019-07-25 13:59:28","IsExistBlackList":false}]},
"TraceFlag":null,"ErrorDetail":null,"Pname":null}
案例1:直取法取”NickName”後的值」貝克漢姆「,但是輸出會帶「 」雙引號,value = eval(value)可去掉引號
value = re.findall('"NickName":(.*?),', response, re.S)[0]
或者直接在程式碼中把引號去除
value = re.findall('"NickName":」(.*?)「,', response, re.S)[0]
案列2:前後匹配法取”NickName”後的值」貝克漢姆「,經觀察,」貝克漢姆「值前面為FirstTwitterName”:”「,後面為”FirstTwitterRemark,則表達式可寫成如下
value = re.findall('FirstTwitterName":"(.+?)","FirstTwitterRemark', response, re.S)[0]
同理,也可以取出HeadImgUrl參值網址中的任意一段內容,如取」wx.qlogo.cn「,寫法如下
value = re.findall("//(.+?)/mmopen", response, re.S)[0]
爬蟲中經常要取」href「里的內容,也可以通過案例2中的前後匹配法取值,如取下圖html內的href內容,但是要注意中間的空格、換行字元

這裡面我們看不到任何空格和換行字元,但如果先取出class=」tal「內的數據,就可以看的出來了,寫法如下
value = re.findall('<td class="tal" id="">(.+?)</td', response, re.S)
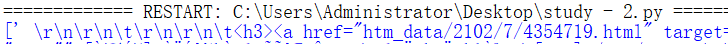
返回內容,可見href前有\r\n,還有空格等數據,所以基於這些數據,把正則再完善一下
value = re.findall('<td class="tal" id=""> \r\n\r\n\t\r\n\r\n\t<h3><a href="(.+?)" target=', response, re.S)
如此,便取出了想要的數據
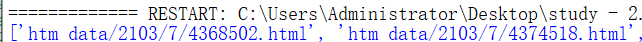
案例3:如果返回值內即包含中文又包含數字,我們只需要數字或者中文呢?如”FirstTwitterRemark”:”小貝960″,取出960或者小貝
首先,取出數字
value = re.findall('"FirstTwitterRemark":"(.*?)",', response, re.S)[0] num = re.sub(r'\D', "", value) print(value) print(num)
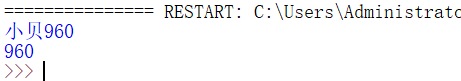
然後,取出中文
value = re.findall('"FirstTwitterRemark":"(.*?)",', response, re.S)[0] zhong = re.findall('[\u4e00-\u9fa5]+', value) print(value) print(zhong[0])

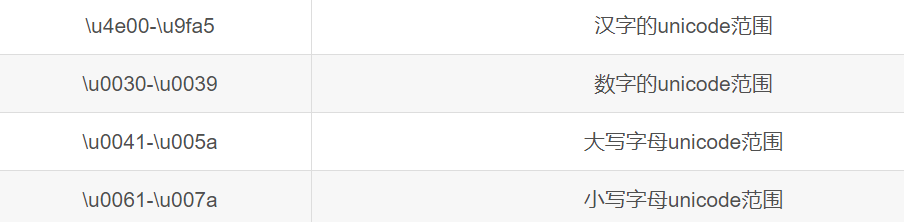
如上,取中間,是通過寫入漢字的unicode範圍來取值,那麼替換成下表格內諸如數字和字母的範圍,同理也可以取出對應的內容
未完待續。。。

