calcite 概念和架構
1. 前言
Flink使用Calcite構造SQL引擎,那麼他們 是怎麼合作的? drill, hive,storm 和其他的一干apache 大數據引擎也用calcite , 那麼對於同一個sql 語句(statement) , 無論複雜簡單與否,他們和Flink產生的執行計劃是不是一樣的? 如果不一樣, 區別是怎麼產生的? 應該在哪裡實施優化和發力?優化的手段和原則有那些,等等? 本文不會對calcite 面面做具到的介紹,重點是SQL執行計劃的優化框架,流程和策略, 對執行計划進行優化是calcite 的主要業務。為了有助於理解優化框架,對於必要的概念會有介紹, 比如關係,關係代數,關係演算,等價原理,謂詞邏輯等。
2. calcite 架構
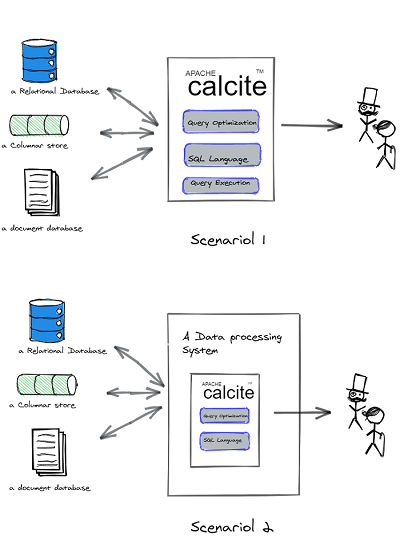
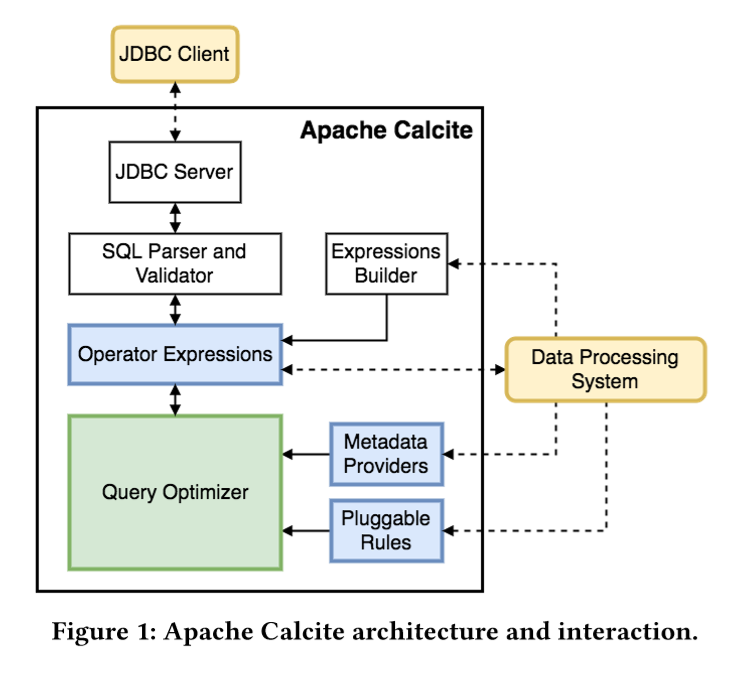

3. 一些關係的概念
Calcite 只支援於關係型數據模型(不支援層次,網狀,對象資料庫的模型), 那麼什麼是關係型資料庫呢 ? 建議讀一下引用5中的那本書 ,雖然我也沒讀完 。下面解釋一下一些比較容易混淆的概念 。
關係:關係一詞來自離散數學裡的集合論,根據維基百科的的定義,給定任意集合A和B,若 (笛卡爾乘積),則稱R為從A到B的二元關係,特別在A=B時,稱R為A上的二元關係。如果一個有N列的二維表, 每一列的取值範圍為Ai 則該表是定義在A1x..Ai..xAn上的N元關係。可見,關係(Relation)是N元有序序列的集合。關係在資料庫的概念里稱作表(Table),關係的每一個有序序列叫做元組或行(Row), 元組的每一個量叫分量或列(Column)。
(笛卡爾乘積),則稱R為從A到B的二元關係,特別在A=B時,稱R為A上的二元關係。如果一個有N列的二維表, 每一列的取值範圍為Ai 則該表是定義在A1x..Ai..xAn上的N元關係。可見,關係(Relation)是N元有序序列的集合。關係在資料庫的概念里稱作表(Table),關係的每一個有序序列叫做元組或行(Row), 元組的每一個量叫分量或列(Column)。
關係模式(Schema):是對關係或表的描述。包括關係名稱(Table Name),列名以及列的定義域(Domain)。
關係模型(Model):指的是一系列關係模式的集合, 概念上對應資料庫。
維度(Dimension):通常是指列離散定義域的列。定義域上的每一個值稱為基(cardinality), 一個關係已經使用的所有的基的個數成為基數 (cardinal number) , 也就是 distinct count , 也成 NDV (Number of Distinct Value) 。
關係代數:是由 Edgar F. Codd提出一種利用具有良好語義的代數結構用於對數據建模和定義查詢的理論。代數結構是在一種或多種運算下封閉的一個或多個集合,那麼關係代數在閉合關係上的良好語義的運算的集合。通俗的說,關係代數是一種通過由代數運算和輸入關係組成的表達式來表達輸出關係的理論。 比如 圖-3中,SQL 產生的關係可以多個樹形的表達式表示,樹的形狀和節點的排列順序代表運算的過程(從下到上) 。關係代數是面向過程的。
4. calcite的概念

| 概念 | 解釋 | 例子 |
| RelNode | 關係代數中的關係和運算的基類。RelNode 有很多繼承者, 見舉例。 | TableScan對應一個數據源的一個關係,Filter對應Filter運算 。Filter有一些系列的繼承者, 每一個繼承者對應一個CallingConvention, 也對應一個優化階段的使用的數據結構 。 比如Join<-LogicalJoin<-FlinkLocalJoin<-FlinkBatchExecJoin, FlinkExecStreamJoin 。 |
| RelDataType | 代表域,是關係中列的定義域 | 整數,日期,浮點數,定點數,字元串 |
| RexNode | 代表Project里Filter中表達式 | 比如下面關係里一個分量(InputRef),一個常量值(Literal),一個或多個分量函數(RexCall, 加、減、乘、除、CAST 等) |
| RelTrait | 代表關係運算的物理特性,這個應該是calcite 里最讓人迷惑的概念了。但Trait, set, subset 是 volcanoPlanner 最依賴的概念。 關係的物理特性是跟關係代數沒有關係的一些特性,所以只有跟物理執行系統比較臨近的關係運算才會有物理特性,比如FlinkBatchExecFilter 有物理特性, 它是被翻譯成FlinkJobGraph的輸入計劃的節點類型。而LogicalFilter觀完全邏輯上的關係觀念,因此不會有任何物理特性。 Calcite 有三種類型的特性, 類型叫做TraitDef 。
|
比如Flink中的節點BatchExecJoin在BATCH_PHYSICAL 調用習慣中的運算節點。 |
| AbstractConverter | 當關係表達式的 Convention 發生變化的時候, VolcanoPlanner 會在Relset 里創建Relsubset 代表這種traits, 隨後創建AbstractConverter用於轉化成真正的表達式。 ExpendConventionRule 配備AbstractConverter, 將它轉化成合適的節點, 比如 BroadcastExchange, Sort 等 。 | 參考FlinkExpandConversionRule, calcite: AbstractConverter, Relset.addAbstractConverter。 |
| RelOptRule | 所有的優化規則的基類, 它構造函數第一個參數就是關係運算的類型(比如, Join, Filter 等),(還有一些別的, 不展開了)。當Planner 遍歷表達式圖的每一個節點時,他會調用匹配這個節點類型的規則 。除了匹配類型,VolcanoPlanner 還會給規則設置優先順序,級別高的會別先調用。每一個規則有兩個函數: matches() 繼續深度判斷改規則是否真的應該調用。 onMatch 執行規則實際的動作:根據測量增、減、改變、升級表達式的節點。 優化規則有的會通過元數據提供者查詢元數據資訊,從而做相應的措施。有的不會。從規則的角度來看,planner 都是無區別的。 所以除了少量的例外(比如前面提到的ExpendConvensionRule),大部分都可以被HepPlanner 和 VocanoPlanner 調用的。 |
例子有很多, 比如有名的謂詞下推,子查詢替換,join-recorder, 常量替換等。google里搜索一下, 會很多介紹 。 想看全面的, 請參考 org.apache.calcite.rel.rules裡面的規則, 或 FlinkBatchRuleSets.scala裡面的使用的規則。 |
| RelMetadataProvider RelOptCost |
前文多次提到的統計數據提供者,他是一個能handle不同統計類型數據的handler的集合。比如 RelMdRowCount是提供關係運算產生的rowCount估計, RelMdDistinctRowCount 提供某個列的cardinal number 估計 。RelMdSelectivity 提供關係運算後的rowcount 原來的比例 估計。 RelOptCost是代價模型, calcite 的代價模型是對關係的行數,通常是考慮IO(disk IO + network IO) 和CPU使用率, memory, 和 關係規模(rowcount)的一個綜合衡量。 |
Calcite 里有DefaultRelMetadataProvider 提供了各種Handle 預設計算方法。ReflectiveRelMetadataProvider 由於接受DPS端實現的Provider , 比如 Flink里實現的FlinkDefaultRelMetadataProvider . 還有一個JaninoRelMetadataProvider, 看起來是通過動態編譯的生成Provider ? Handler的元數據的估計演算法請閱引用5的第13章。 |
| Schema Table Lattice ,Tile |
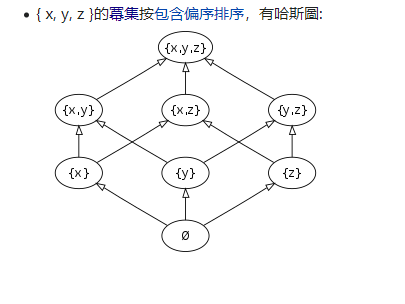
Schema和table的概念全面說過。 Lattice(格) 是除了關係、關係代數之外,另一個來自於數學領域的名詞。看起來calcite 是真的很想提升廣大數據程式設計師的數學格調。 格同關係代數一樣是一種代數結構(集合+一種二元關係),集合的成員的二元關係是反自反, 和傳遞的, 而且這個關係有明確的上下界, 則稱這種代數結構為格。 很抽象, 可以看引用8中的哈斯圖理解 。{ x, y, z }的冪集按包含偏序排序就是一個格。 這個和多維cube聚合計算的物化視圖的結構很像。 物化視圖裡的每一個頂點都是一個tile , 最上面的tile 包含了所有的維度, 最下面的維度為空, 維度集合以及包含關係組成了一個格。 格從上到下是是降維的過程,則低維聚合計算可由高維聚合導出 。所以lattice , Tile 是為 物化視圖引入的, 只不過換了一個文藝的名字而已 。 物化視圖是一個預計算的結果,物化在硬碟或記憶體里,如果把查詢計劃里能夠利用物化視圖,執行的很定會飛快 。 |
來自引用8 |
| HepVertex HepProgram HepPlanner |
HepVertex是HepProgram里用於組成計劃圖的頂點。HepProgram 是一些優化規則的集合,HepPlanner 利用HepVertex建立將計劃樹轉化成計劃圖, 然後利用HepProgram按照一定順序遍歷其中的優化規則。 HepPlanner 調用流程如右側程式碼所示。
HepPlanner的尋優 是一個一種貪心的演算法,就是當前迭代步會用上一次迭代結果的作為當前最優結果繼續優化,如果上一步做錯了,下一步也會錯下去。只有將迭代運行多次,才有可能避免改正錯誤。 |
//build program val builder = new HepProgramBuilder() builder .addMatchLimit(10) .addRuleInstance(SubQueryRemoveRule.FILTER) .addRuleInstance(SubQueryRemoveRule.JOIN) .addMatchOrder(HepMatchOrder.BOTTOM_UP) val hepProgram = builder.build() //create planner val planner = new HepPlanner(hepProgram, ...) //build new operator expression graph planner.setRoot(root) planner.changeTraits(desiredTraits) //apply rules in programs to optimize the operator expression planner.findBestExp
|
| Relset RelSubset VolcanoProgram ValcanoPlanner |
RelSubset 代表一個目標物理特性, 比如BATCH_PHYSICAL.Broadcast.ANY, 代表一個BATCH_PHYSICAL convention 等價 子計劃,行發布方式是廣播, 列排序方式為任意。BATCH_PHYSICAL.Hash.ANY,是另為一個subet 。 Relset 是所有具有不同物理特性的等價的RelSubset的集合這些, 比如BATCH_PHYSICAL.Broadcast.[]和 BATCH_PHYSICAL.Hash.[]是等價的。 Relset 還是所有等價關係的集合,比如HashExchange+SortMergeJoin,HashExchange+HashJoin, BroadcastExchange+Hash, ASC sort + SingleExchange+Hash 都是等價關係表達式。 RelSubset 會在從等價關係集合里選擇符合自身trait的最便宜的作為他的best 。從上到下的best組成最終的計劃圖 。
|
5. 優化器流程
HepPlanner 的尋優流程很簡單,setRoot重建planGraph, findBestExp 就是按照指定的順序將HelpProgram里的規則觸發一遍。 如果擔心有問題貪心演算法的問題,可以將這兩步多做幾次。
VocanoPlanner 的尋優流程如前所述。 TraitSet 通常包含了 Convension, distribution, collation 三個維度 , 這三個維度不同的基的組成的組合(subset)都是等價的但是cost不相等,但並不是代價把最低的subset 輸入給上游總代價就會最低的。最低的代價需要綜合考把慮上游和下游的情況,尋找最搭配的搭檔。所以這個尋優過程需要一個動態規劃的方式來求解。在使用動態規劃(也就是遞歸的方法, volcanoPlanner 的命名就來自這裡吧 )求解之前, 我們需要把各種可能的計劃的每一層的滿足需要trait的subset, 以及對應關係求出來。 而滿足要求的subset, 而且在考慮到輸入的組合,狀態轉移公式大概如下。
BestExp(subset)) = argmin( cost(rel1 ), cost(rel2), ... ) cost (rel ) = algoCost(rel.self) + cost(BestExp(rel.input1)) + cost(BestExp(rel.input2))
第一行中,rel1, rel2 是滿足traits 的等價表達式,表示當前subet的最佳表達式是他們之中里cost最低的表達式。
第二行中, 表示表達式的cost 等於最上層節點自身演算法代價估計 和下層輸入subset的最佳表達式向上輸入的累計的綜合代價 。TableScan 的下層輸入就是磁碟IO的代價,底層關係的RowCount相關 。這裡的加號代表代價計算要綜合考慮的因素並不是簡單的算數相加 。比如hashJion和sortMergeJoin自身演算法的代價不一樣(CPU, 記憶體代價), join的兩路輸入方式不同代價不一樣(IO代價)。
SELECT * from store_sales join date_dim on store_sales.ss_sold_date_sk = date_dim.d_date_sk and date_dim.d_year=2002
1 |
這個表達式里主要有一個HashJoin 和兩個TableScan 組成, 如果對HashJoin 的 requriedTraits 是 BATCH_PHYSICAL.ANY.[], HashJoin 對store_sales 和 date_dim的要求分別是BATCH_PYSICAL.forward.[] 和 BATCH_PYSICAL.broadcast.[], 那麼上面的公式以下的形式 。
BestExp(join.BATCH_PHYSICAL.ANY.[]) = argmin( cost(shuffledHashjoin), cost(broadcastHashJoin), cost(shuffledSortMergeJoin),... ) cost(broadcastHashJoin)= cost(BestExp(tablenscan_store_sales.BATCH_PHYSICAL.forward.[])) + cost(BestExp(tablenscan_date_dim.BATCH_PHYSICAL.broadcast.[])) + algoCost(HashJoin)

畫個圖表示一下 relSet, relSubset, 和besExp 還有trait之間的關係吧, 還有這個類似火山噴發的形狀。
7. 引用
| 序號 | 描述 | 鏈接 |
| 1 | Calcite 論文 | dl.acm.org/doi/10.1145/3183713.3190662 |
| 2 | Calcite 官方文檔 | calcite.apache.org/docs/ |
| 3 | 關係代數 | en.wikipedia.org/wiki/Relational_algebra |
| 4 | 關係演算 | //en.wikipedia.org/wiki/Relational_calculus |
| 5 | 資料庫系統概念第6版 Abraham Silberschatz 等著 | |
| 6 | 官渡之戰 | //zh.wikipedia.org/wiki/%E5%AE%98%E6%B8%A1%E4%B9%8B%E6%88%98 |
| 7 | SQL on everything, in memory by Julian Hyde | www.slideshare.net/julianhyde/calcite-stratany2014 |
| 8 | 哈斯圖 | zh.wikipedia.org/wiki/%E5%93%88%E6%96%AF%E5%9C%96 |


