C語言相關的基礎字元串函數
- 2021 年 3 月 3 日
- 筆記
C語言中沒有專門的字元串類型,所以就用字元數組和字元指針形式表示
1 char arr[]="abcdef"; //字元數組表示的字元串 2 char*arr="abcef"; //常量字元串
對字元串進行操作的函數,可以稱為字元串函數,比較常見的有:strlen,strcmp,strcpy,strcat,strncpy,strncat,strncmp,strstr,strtok,strerror
strlen
strlen是用來計算字元串長度的函數,函數的參數是指針,從指針指向位置開始計數,遇到『\0’為止,計數個數為\0前出現的字元個數(不包括’\0’)
#include <stdio.h> #include <string.h> int main() { char arr[] = "abcdef"; char p[] = { 'a', 'b', 'c', 'd' }; int i=strlen(arr); int j=strlen(arr + 1); int k = strlen(p); printf("%d %d %d", i, j,k); //結果是6 5 隨機值 //6和5表示了strlen是從指針指向的地方開始計算字元串的長度的,而不只是簡單從第一個字元開始計算。 //隨機值的出現是因為字元數組p沒有'\0'的存在,所以計數會一直進行,直到在界外遇到\0才停下 //所以參數指向的字元串必須以\0結束才能用到strlen return 0; }
strlen作為一個函數他有屬於自己的返回值類型,它的類型是unsigned int 也就是無符號的整型,所以在strlen的返回值中是不存在負數的 。這個很好理解,因為字元串的字元個數肯定是正數。但是,當遇到strlen的加減法時,也要注意這是無符號整型的加減,最後得出的結果不會是負數。
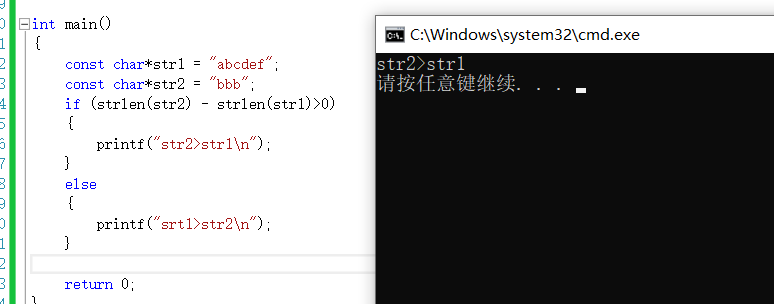
本來strlen(str2)-strlen(str1)這個結果應該是3-6,但在無符號整型中-3寫成二進位表達是10000000000000000000000000000011沒有符號位,顯然是一個龐大的正數。這是strlen的一個細節,值得注意。
模擬實現strlen函數(原來的strlen返回類型應該是unsigned int此處使用int來返回與原來不一致,但不影響運行)
三種方法:1、計數器法 2、遞歸求解 3、指針減指針
1、計數器法
int my_strlen(const char*str) { //計數器法,字元指針每走一位,計數器加一,一直到'\0'停下 assert(str); int count = 0; while (*str != '\0') { str++; count++; } return count; } int main() { char arr[] = "abcd"; int n=my_strlen(arr); printf("%d", n); return 0; }
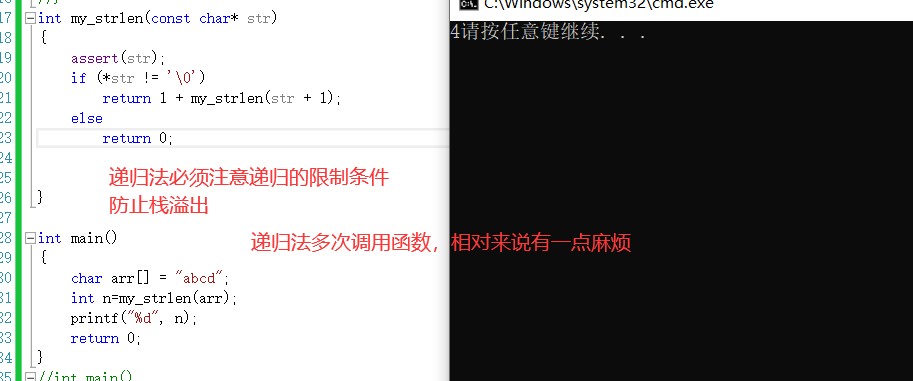
2、遞歸法
3、指針減指針
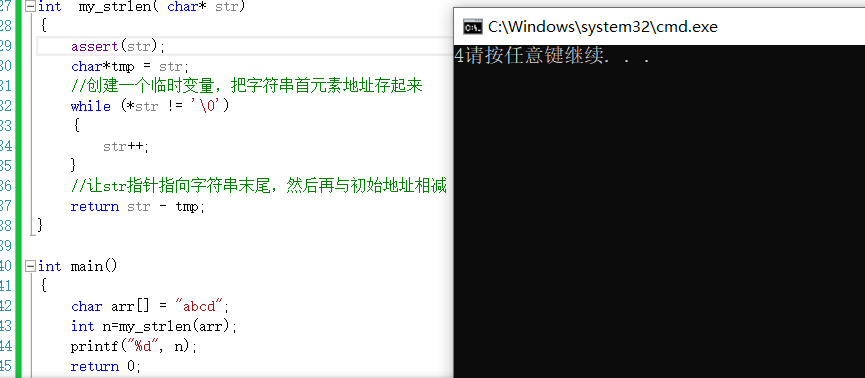
模擬實現strlen這個函數是字元串函數裡面比較基礎的內容,有助於加深對strlen的理解。
strcmp
strcmp這個函數是用來比較字元串的,可以稱為字元串比較函數。字元串之間的比較不能使用大於小於等於這種數學符號,所以C語言專門規定了一個函數叫strcmp用來比較兩個字元串。strcmp這個比較函數接受的參數是字元指針
int strcmp(const char*p1,const char*p2) //這是他的類型 //返回值是一個整數,第一個字元串大於第二個字元串,則返回大於0的數字 第一個字元串等於第二個字元串,則返回0 第一個字元串小於第二個字元串,則返回小於0的數字
字元串的比較並不是比較字元串的長度,而是比較字元的ASCII碼值,如果ASCII碼值相同就比較下一個字元的ASCII值,直到比出大小。
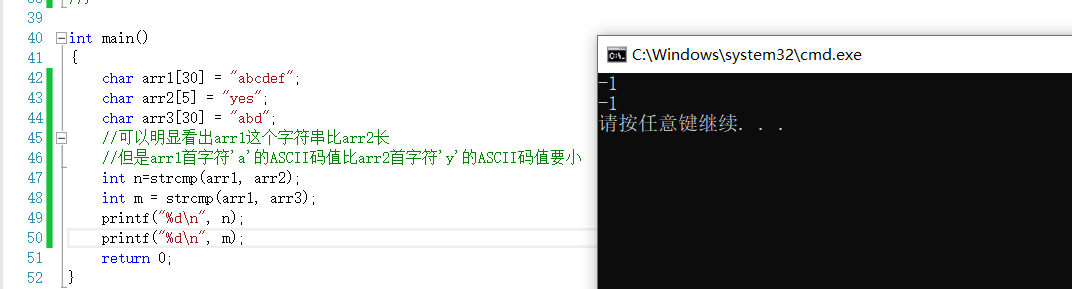
上圖展示了strcmp的比較方法,比較字元的ASCII碼值。這裡的編譯器使用了vs2013,默認返回值-1。返回值是一個負數,表示在這兩個函數中第一個字元串都小於第二個字元串。但是並不是所有編譯器都返回-1這個值,在這種情況下,只要返回值是一個負數,就是合理的。
模擬實現strcmp函數
1 int my_strcmp(const char*str1, const char* str2) 2 { 3 4 assert(str1&&str2); 5 while (*str1&&*str2 && (*str1 == *str2)) 6 { 7 //字元出現不相等或者出現字元串結束時,進入比較環節 8 str1++; 9 str2++; 10 } 11 if (*str1 > *str2) 12 return 1; 13 else if (*str1 < *str2) 14 return -1; 15 else 16 return 0; 17 18 }
此處沒有寫主函數,這只是一個模擬字元串比較函數,寫得較為簡單。基本思想就是利用指針,逐個字元對比ASCII碼值大小。
相應的,對於不是字元串的類型也可以在記憶體中進行類似的操作,這時候要用到函數memcmp。(這是記憶體函數並非字元串函數)
int memcmp ( const void * ptr1,const void * ptr2,size_t num );
基本模型如上。比較的是ptr1和ptr2指針開始的num個位元組,返回值類似於strcmp,返回大於0的數就是ptr1指向的數據有更大的值,返回0就是前num個位元組相等,返回小於0的數就是ptr1指向的數據在記憶體中值比ptr2所指向的更小。
strcpy,strncpy
strcpy是字元串拷貝函數,即將一個字元串的內容拷貝到另一個字元串中。
char* strcpy(char * destination, const char * source );
這是strcpy的基本模型,返回值類型是字元指針。參數寫的也很清楚,第一個是目的地字元串,也就是用來存放拷貝內容的字元串,第二個是來源字元串,就是把這個字元串的內容拷貝到目的地中。
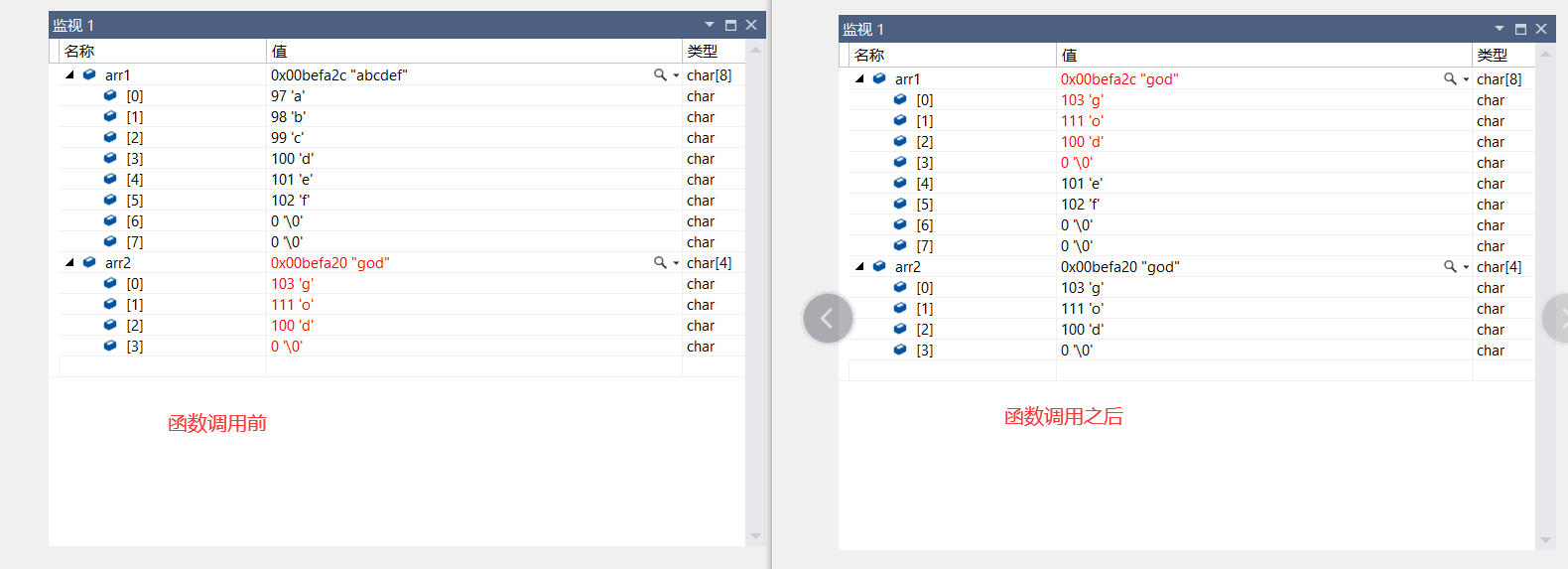
明顯可見,函數調用時把arr2的『\0』也拷貝了過來。這裡要注意的是,來源字元串必須以\0』結束,這樣才能被正常拷貝。其次便是,目標空間必須足夠大,目標空間必須可變。
模擬實現strcpy函數
1 char*my_strcpy(char*dest, const char* src) 2 { 3 assert(dest&&src); 4 char* ret = dest; 5 while (*src != '\0') 6 { 7 *dest = *src; 8 dest++; 9 src++; 10 }//循環結束,src指向'\0',再把'\0'拷貝進去函數就完成了 11 *dest = *src; 12 return ret; 13 } 14 char*my_strcpy(char*dest, const char* src) 15 { 16 assert(dest&&src);//更為簡潔的寫法 17 while (*dest++ = *src++)//直接在條件裡面賦值 18 { 19 ; 20 } 21 }
strncpy就是把來源字元串的前n個字元拷貝到目的字元串中,如果來源字元串字元個數小於n,拷貝的字元後面自動補0
char* strncpy(char * destination, const char * source ,size_t num);
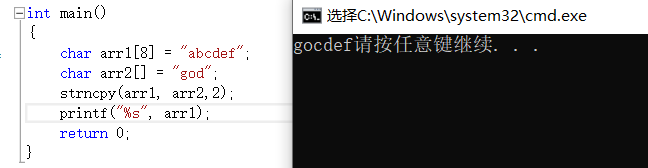
面對非字元串類型的數據,可以用memcpy來進行拷貝(這是記憶體函數並非字元串函數)
void * memcpy ( void * destination, const void * source, size_t num )
基本模型如上。這個函數把num個位元組的內容從來源拷貝到目的處。但是函數在遇到『\0’時並不會停下來。如果來源和目的有任何重疊,這個結果都是未定義的。
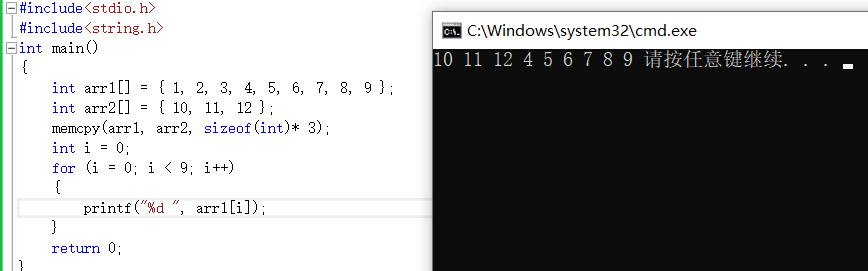
整型數組的拷貝,把來源數組前12個位元組的數據拷貝過來替換了目的數組的前3個數字,後面的數字不變。
模擬實現memcpy
void* my_memcpy(void*dest, void* src, int num) { assert(dest&&src); void* ret = dest; int i = 0; for (i = 0; i < num; i++) { *(char*)dest = *(char*)src;//每一個位元組進行拷貝 ((char*)src)++;//void*指針不能進行加減操作,轉成char*指針可以每次移動一個位元組 ((char*)dest)++;//要在++之前整體加上一個括弧,不然指針先和++結合,強制類型轉換無效 } return ret; }
當出現記憶體重疊,有時候不能使用memcpy函數,這時候就有函數memmove可以使用(這是記憶體函數並非字元串函數)
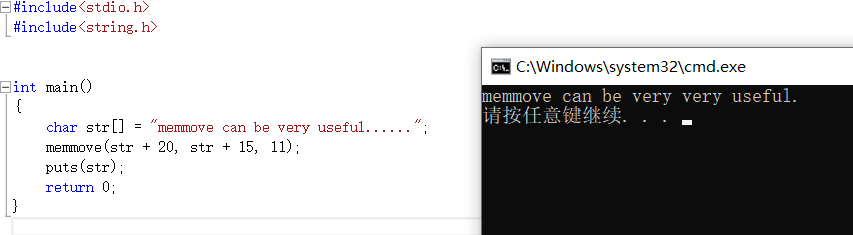
模擬實現memmove
1 void* my_memmove(void* dest, void* src, int count) 2 { 3 assert(dest&&src); 4 void* ret = dest; 5 if (dest < src)//分析從前向後拷貝還是從後向前拷貝 6 //如果dest在src前面只能從前向後拷貝,和memcpy類似 7 //dest在src後面且dest<src+count只能從後向前拷貝(當然void*不能進行加減,此處只是注釋而已) 8 { 9 while (count--) 10 { 11 *(char*)dest = *(char*)src; 12 ((char*)src)++; 13 ((char*)dest)++; 14 } 15 } 16 else 17 { 18 while (count--) 19 { 20 *(((char*)dest) + count - 1) = *(((char*)src) + count - 1); 21 } 22 } 23 return ret; 24 25 } 26 int main() 27 { 28 int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; 29 my_memmove(arr1 , arr1+2, 16); 30 int i = 0; 31 for (i = 0; i < 9; i++) 32 { 33 printf("%d ", arr1[i]); 34 } 35 return 0; 36 }
strcat、strncat
strcat是字元串追加函數,就是將來源字元串追加到目的字元串的『\0’之後(目的字元串的『\0’被替換成來源字元串首字元),追加這個過程一定程度上類似於拷貝,也就是把來源字元串拷貝到了目的字元串的後面。同樣的要注意,目的字元串必須足夠大,目的字元串也必須可變。來源字元串要以『\0’結束。這幾點和剛才的strcpy一樣。
特別地,strcat不能用來自身追加,因為這個函數需要先找到目的字元串的『\0』,然後進行類似於拷貝的操作。如果用於自身追加,『\0’在拷貝時候被替代,這也就等同於來源字元串被改變了,此時來源字元串也就不是以’\0’結束,追加便出現問題了。
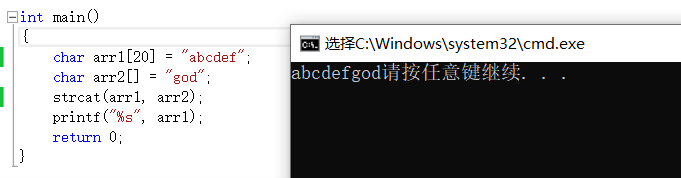
模擬實現strcat函數
char*my_strcat(char*dest, const char* src) { assert(dest&&src); char* ret = dest; while (*dest != '\0') { dest++; }//先找到目的字元串中的'\0' while (*dest++ = *src++) { ; }//追加字元串,此操作同strcpy return ret; }
strncat是追加來源字元串的前n個字元,變化類似於剛才 的strcpy和strncpy。
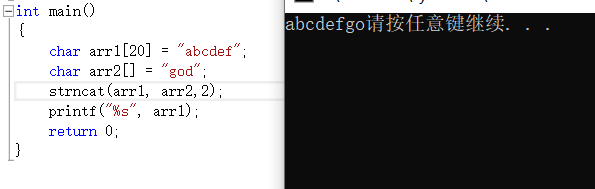
strstr
strstr是搜索子字元串的函數。
char*strstr(const char*str1,const char*str2)
函數基本模型如上。函數返回類型是char*也就是一個指針。當str2不是str1的字串時,就返回空指針。當存在子串時,返回的是第一個字串的首字元地址。
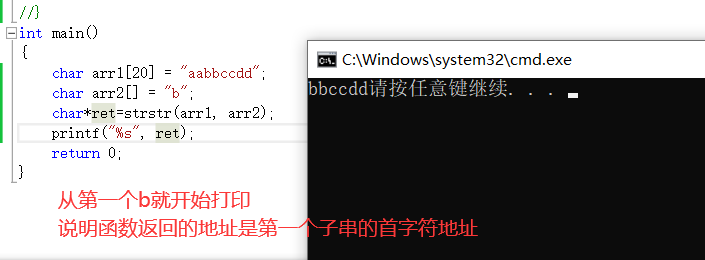
模擬實現strstr
1 char*my_strstr(const char*str1, const char* str2) 2 { 3 assert(str1&&str2); 4 char*cur = (char*) str1; 5 char*s1 = (char*)str1; 6 char*s2 = (char*)str2; 7 //使用cur指針來記錄首字元相同的地址 8 //創建s1和s2變數是為了和cur指針不發生衝突 9 while (*cur) 10 { 11 s1 = cur; 12 s2 = (char*)str2; 13 while (*s1&&*s2 && (*s1==*s2)) 14 { 15 s1++; 16 s2++; 17 } 18 if (*s2 == '\0') 19 return cur; 20 cur++; 21 } 22 return NULL; 23 //這種寫法保證了出現重複字元時也能正確找到子串 24 25 26 } 27 int main() 28 { 29 char arr1[20] = "aabbbccdd"; 30 char arr2[] = "bbc"; 31 char*ret=my_strstr(arr1, arr2); 32 printf("%s", ret); 33 return 0; 34 }
strtok
strtok是用來提取被分割的字元串的。函數模型如下
char*strtok(char*str,const char* sep)
第一個參數是被操作的原字元串,第二個參數是分隔符形成的字元串。
strtok會找到原字元串中的下一個標記,然後用’\0’結尾,然後返回一個指向這個標記的指針。
當函數的第一個參數不是NULL時,strtok會查找第一個標記,並且保存這個標記的位置。當函數第一個參數是NULL時,strok從被保存位置開始查找下一個標記。當字元串不存在更多標記時,會返回NULL。
以上描述比較抽象,不大好理解,可以看以下程式碼。
int main() { char arr[] = "[email protected]"; char*p = "@."; char buf[1024] = { 0 }; strcpy(buf, arr); char*ret = NULL; char *ret = strtok(arr, p);//第一次使用函數,找到@將其變為'\0'然後返回a的地址,列印字元串 printf("%s\n", ret); ret = strtok(NULL, p);//第二次使用函數,找到剛才的保存位置,尋找下一個標記 .將其變成'\0'然後返回d的地址,列印字元串 printf("%s\n", ret); ret = strtok(NULL, p);//第三次使用函數,找到剛才的保存位置,尋找下一個標記,找到『\0',列印字元串 printf("%s\n", ret); return 0; }
當然實際上不會這麼寫程式碼,因為這樣必須知道分隔符個數,要知道調用幾次函數。可以用for循環來實現
int main() { char arr[] = "[email protected]"; char*p = "@."; char buf[1024] = { 0 }; strcpy(buf, arr); char*ret = NULL; for (ret = strtok(arr, p); ret != NULL; ret = strtok(NULL, p)) { //巧妙在於第一步初始化ret的值,for循環進來只用一次初值,而正好strtok(arr,p)只用一次 //判斷條件是ret不返回空指針,如果返回空指針就說明字元串不存在更多標記了,不用繼續往下循環了 //每走完一次循環ret值都會變化,也就是去查找下一處標記 printf("%s\n", ret); } return 0; }
strerror
這個函數是用來判斷錯誤的,返回相應的錯誤碼
char* strerror(int num)//參數是錯誤碼
這是函數的基本模型,一般會用到errno來判斷錯誤碼。要引用頭文件<errno.h>
strerror(errno)
寫法如上。

