Oracle 優化器_表連接
- 2019 年 10 月 3 日
- 筆記
概述
在寫SQL的時候,有時候涉及到的不僅只有一個表,這個時候,就需要表連接了。Oracle優化器處理SQL語句時,根據SQL語句,確定表的連接順序(誰是驅動表,誰是被驅動表及 哪個表先和哪個表做鏈接)、連接方法(下文有詳細介紹)及訪問單表的方法(是否走索引,及走哪個索引)。
類型
表連接的類型分為兩種:內連接和外連接。表連接的類型不同,得到的結果也不相同。不同的SQL語句使用不同的表連接。演示表連接我們用兩個表t1和t2 。建表語句及數據如下:
-- 建表語句 CREATE TABLE T1(col1 number,col2 VARCHAR2(1)); CREATE TABLE T2(col2 VARCHAR2(1),col3 VARCHAR2(2)); -- 表1數據 INSERT INTO t1 VALUES(1,'A'); INSERT INTO t1 VALUES(2,'B'); INSERT INTO t1 VALUES(3,'C'); -- 表2 數據 INSERT INTO t2 VALUES('A','A2'); INSERT INTO t2 VALUES('B','B2'); INSERT INTO t2 VALUES('D','D2');
內連接
內連接,表的連接只包含滿足條件的記錄,Oracle資料庫默認的鏈接方式,只要在SQL語句中沒有(+),這裡的(+)是Oracle特有的連接符號。或者 left outer join 、 right outer join 、full outer join 那麼SQL的連接類型就是內連接。
內連接的寫法:
1.Oracle自帶(最常用):
SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2 = t2.col2;
得到結果如下:

2.標準SQL寫法:
SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1 JOIN T2 ON (t1.col2= t2.col2);
結果如下:

3.標準SQL寫法2:(這裡需要注意的是SQL語句的紅色部分,col2 欄位前不能加表名)
SELECT T1.COL1,COL2,T2.COL3 FROM t1 join t2 using (col2);
結果如下:
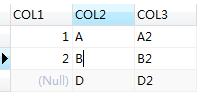
可以看出,三種內連接的寫法得到的結果是一樣的。運行執行計劃,得出的執行計劃也是相同的 :
Plan hash value: 1838229974 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 30 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN | | 3 | 30 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."COL2"="T2"."COL2")
關於join using 標準SQL中有一種特殊的join using ,寫法如下:
SELECT t1.col1,col2,t2.col3 FROM t1 NATURAL JOIN t2;
它在當前表結構下,執行結果跟上面的SQL語句執行結果一樣,執行計劃也相同,但是在其他情況下就不一定相同了。因為它是取兩個表中所有表名相同的列進行內連接,有可能有的列僅僅是命名相同,但是我們並不希望按照欄位中內容進行過濾,那麼這樣寫的話,就有可能得到一個錯誤的結果。所以開發中並不常用。
外連接
外連接是對內連接的擴展,執行時,除了將滿足內連接條件的值查出來之外,還會包含驅動表中所有不滿足連接條件的記錄。外連接分為:左外連接、右外連接、全連接三種。下面分別介紹下:
左外連接
語法:
目標表1 left outer join 目標表2 on (連接條件) 或 目標表1 left outer join 目標表2 using(連接列集合)
SQL舉例:
SELECT t1.col1,t1.col2,t2.col3 from t1 left outer join t2 on (t1.col2 = t2.col2); -- 或 SELECT t1.col1,col2,t2.col3 from t1 left outer join t2 using (col2); -- 或 SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2 = t2.col2(+);
這裡的第三種寫法是Oracle特有的寫法。這三種寫法的執行結果一樣:

執行計劃也相同:
Plan hash value: 1823443478 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 60 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."COL2"="T2"."COL2"(+))
這裡因為表1作為驅動表,而表2中不包含col2 為C 的數據,所以在第三行結果中,col3 的值為null。
右外鏈接
右外鏈接跟左外連接類似,語法為:
目標表1 right outer join 目標表2 on (連接條件) 或 目標表1 right outer join 目標表2 using(連接列集合)
SQL 舉例:
SELECT t1.col1,t2.col2,t2.col3 from t1 right outer join t2 on (t2.col2 = t1.col2); -- 或 SELECT t1.col1,col2,t2.col3 from t1 right outer join t2 using (col2); -- 或 SELECT T1.COL1,T2.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2(+) = t2.col2;
SQL查詢得到的結果和執行計劃也是一致的:
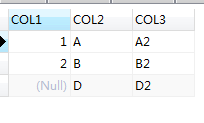
執行計劃:
Plan hash value: 1426054487 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 60 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."COL2"(+)="T2"."COL2")
全連接
語法為:
目標表1 full outer join 目標表2 on (連接條件) 或 目標表1 full outer join 目標表2 using(連接列集合)
SQL舉例:
SELECT t1.col1,t1.col2,t2.col3 from t1 full outer join t2 on (t1.col2 = t2.col2); -- 或 SELECT t1.col1,col2,t2.col3 from t1 full outer join t2 using (col2);
執行結果為:

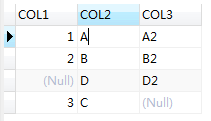
因為第一個語句限定了col2段的值為t1表,所以第三條結果的col2 欄位為空。
執行計劃相同:
Plan hash value: 53297166 ---------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 54 | 6 (0)| 00:00:01 | | 1 | VIEW | VW_FOJ_0 | 3 | 54 | 6 (0)| 00:00:01 | |* 2 | HASH JOIN FULL OUTER| | 3 | 60 | 6 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL | T2 | 3 | 15 | 3 (0)| 00:00:01 | ---------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("T1"."COL2"="T2"."COL2")
全連接的效果為左連接+右鏈接,SQL如下:
SELECT t1.col1,t1.col2,t2.col3 from t1 right outer join t2 on (t1.col2 = t2.col2) union SELECT t1.col1,t1.col2,t2.col3 from t1 left outer join t2 on (t1.col2 = t2.col2);
執行結果如下;

可以看出得到的執行結果順序不同,內容一致。但是,執行的時候,資料庫的執行計劃並不是這樣的,下面是這條SQL的執行計劃,通過對比跟全連接SQL的執行計劃,可以看出,當前SQL是先查出左連接,再查出右連接,最後做了一個取並集的操作。而全連接是在取數據的時候,直接做的是取外連接的操作。
Plan hash value: 2747422401 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 6 | 120 | 14 (15)| 00:00:01 | | 1 | SORT UNIQUE | | 6 | 120 | 14 (15)| 00:00:01 | | 2 | UNION-ALL | | | | | | |* 3 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | | 5 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | |* 6 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 | | 7 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | | 8 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("T1"."COL2"(+)="T2"."COL2") 6 - access("T1"."COL2"="T2"."COL2"(+))
·特例:natural 在外連接中同樣適用,和內連接的方法和弊端也相同。
反連接
見下文
半連接
見下文
方法
在Oracle優化器確定執行計劃中表連接的類型之後,就會決定表連接的方法。表連接的方法有四種:1.排序合併連接、2.嵌套循環連接、3.哈希連接、4.笛卡爾積連接。下面我們分別介紹下這四種連接:
1.排序合併連接
排序合併連接,兩個表做連接時,用排序和合併兩種操作來得到結果集的連接方法。
sql舉例(當前SQL只是為了演示排序合併連接而寫的SQL,我還沒有想好具體的使用場景,歡迎大家給出):
select t1.col1 ,t1.col2,t2.col2,t2.col3 from t2,t1 where t1.col2>t2.col2
執行結果:
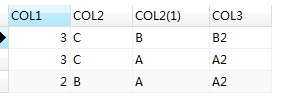
執行計劃:
Plan hash value: 412793182 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 30 | 8 (25)| 00:00:01 | | 1 | MERGE JOIN | | 3 | 30 | 8 (25)| 00:00:01 | | 2 | SORT JOIN | | 3 | 15 | 4 (25)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | |* 4 | SORT JOIN | | 3 | 15 | 4 (25)| 00:00:01 | | 5 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 | ---------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 4 - access(INTERNAL_FUNCTION("T1"."COL2")>INTERNAL_FUNCTION("T2"."COL 2")) filter(INTERNAL_FUNCTION("T1"."COL2")>INTERNAL_FUNCTION("T2"."COL 2"))
通過執行計劃可以看出,排序合併連接執行過程為(先執行t1還是t2的排序跟具體情況相關,當前SQL的執行順序取決於from 關鍵字後 t1和t2的位置):
①首先對t1表中的數據按照where條件中的連接列來進行排序(Id 為4 那行的 SORT 操作),排序得到結果集1;
②然後對t2 執行類似的操作(Id 為2 那行的 SORT 操作)。
③最後,對兩個結果集進行合併操作(Id為 1 的行的 MERGE 操作),將滿足條件的記錄作為最終結果。
2.嵌套循環連接
循環嵌套連接,兩個表做連接的時候,靠兩層嵌套循環(內循環和外循環)來得到連接結果的表連接方法。
舉例:
-- 首先,創建一個索引在t2表 create index idx_t2 on t2(col2); -- 然後執行SQL select /*+ ordered use_n1(t2)*/ t1.col1 ,t1.col2,t2.col3 from t1,t2 where t1.col2= t2.col2
得到執行結果:
Plan hash value: 1054738919 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 30 | 6 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 3 | 30 | 6 (0)| 00:00:01 | | 2 | NESTED LOOPS | | 3 | 30 | 6 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | T1 | 3 | 15 | 3 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | IDX_T2 | 1 | | 0 (0)| 00:00:01 | | 5 | TABLE ACCESS BY INDEX ROWID| T2 | 1 | 5 | 1 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 4 - access("T1"."COL2"="T2"."COL2")
其執行過程類似於兩個for循環的感覺 :
①首先,確定哪個表做外循環,哪個表做內循環。
②然後,訪問外循環的表數據,得到結果集1;
③最後,遍歷結果集1中的每一條記錄,然後每條記錄作為匹配條件去遍歷一遍表2去查看是否有存在匹配的數據。得到返回的數據。
總結:
對於嵌套循環連接,外循環中有多少條記錄,內循環就要做多少次遍曆數據的操作。適用於外循環的結果集較少,同時內循環建立有索引,且索引選擇率較高的場景。
嵌套循環可以快速響應,它可以第一時間返回滿足條件的記錄,而不用等整個循環執行完畢。
3.哈希連接
哈希鏈接可以簡單理解為(t1,t2表為例):
①根據謂語條件判斷兩個表哪個表的結果集較小就作為驅動表。
②根據驅動表的列,計算出一個哈希值,進行快取。
③計算被驅動表,每一行對應列的哈希值,判斷是否在快取中存在該哈希值,如果存在,進一步判斷是否對應列內容一致。
⑤將對應的內容輸出。
哈希鏈接實際情況要更加複雜,這裡只是大概介紹下。
4.笛卡爾連接
兩個表的積成,在兩個表做連接時,沒有任何連接條件時的表連接方法。
SQL舉例:
select t1.col1 ,t1.col2,t2.col3 from t1,t2
執行結果:

執行計劃:
Plan hash value: 787647388 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 9 | 72 | 9 (0)| 00:00:01 | | 1 | MERGE JOIN CARTESIAN| | 9 | 72 | 9 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | T1 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | BUFFER SORT | | 3 | 9 | 6 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL | T2 | 3 | 9 | 2 (0)| 00:00:01 | ----------------------------------------------------------------------------- Note
執行步驟:
①訪問表t1,得到結果集1
②訪問表t2,得到結果集2
③對結果集1和結果集2做合併操作。因為沒有表連接條件,所以每一條結果集2都可以合併結果集1中的每一條數據,所以得到的結果集總數為:t1錶行數* t2錶行數
註:笛卡爾積一般都是因為SQL語句中where條件漏寫導致的。笛卡爾積中兩表數據很大那麼SQL效率會受到嚴重影響。
反連接
反連接,一種特殊連接類型。查詢出表1中不等於表2中某些欄位數據的值。
SQL舉例:
-- not in select * from t1 where col2 not in (select col2 from t2); -- <> all select * from t1 where col2 <> all (select col2 from t2); -- not exists select * from t1 where not exists (select 1 from t2 where col2= t1.col2);
執行計劃分別為:
-- not in Plan hash value: 1275484728 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN ANTI NA | | 1 | 7 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("COL2"="COL2") Note
-- <> all Plan hash value: 1275484728 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN ANTI NA | | 1 | 7 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("COL2"="COL2")
-- not exists Plan hash value: 2706079091 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 | |* 1 | HASH JOIN ANTI | | 1 | 7 | 6 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("COL2"="T1"."COL2")
對比執行計劃,可以看出,not in 和 <> all 的寫法,執行計劃完全一樣,雖然 not exists 的寫法的執行計劃id為1的行沒有NA的字元。但是他們都有 HASH JOIN ANTI 的關鍵字。說明Oracle都將他們轉化為了 如下的等價形式:
select t1.* from t1,t2 where t1.col2 anti= t2.col2;
這裡的NA的區別為:當表欄位中出現null值後,兩者的返回結果就不一致了。
在t1表添加一行:
INSERT into t1 VALUES (4,null); commit;
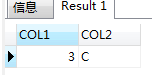
執行結果:
not in 和 not exists
not exists
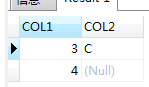
這是因為,前兩個對null敏感,一旦遇到null,則當前行記錄直接認為不符合。而not exists 對null不敏感,將null作為普通數據處理。
半連接
半連接的關鍵詞為:in any exists ;
SQL舉例:
-- in select * from t1 where col2 in (select col2 from t2); -- any select * from t1 where col2 = any (select col2 from t2); --exists select * from t1 where exists (select 1 from t2 where col2= t1.col2);
執行結果都是

半連接邏輯:
①掃描t1,得到結果集1
②根據結果集1的每條記錄掃描t2,只要在t2中找到符合條件的結果,那麼立馬停止掃描t2,將結果放入待返回的結果集
③ 返回結果集
註:當前部落格Oracle 版本為11g,其他版本執行計劃可能不一致。
