gRPC-go源碼(2):ClientConn
摘要
在上一篇文章中,我們聊了聊gRPC是怎麼管理一條從Client到Server的連接的。
我們聊到了gRPC擁有Resolver,用來解析地址;擁有Balancer,用來做負載均衡。
在這一篇文章中,我們將從程式碼的角度來分析gRPC是怎麼設計Resolver和Balancer的,並會從頭到尾的梳理一遍連接是怎麼建立的。
1 DialContext
DialContext是客戶端建立連接的入口函數,我們看看在這個函數裡面做了哪些事情:
func DialContext(ctx context.Context, target string, opts ...DialOption) (conn *ClientConn, err error) {
// 1.創建ClientConn結構體
cc := &ClientConn{
target: target,
...
}
// 2.解析target
cc.parsedTarget = grpcutil.ParseTarget(cc.target, cc.dopts.copts.Dialer != nil)
// 3.根據解析的target找到合適的resolverBuilder
resolverBuilder := cc.getResolver(cc.parsedTarget.Scheme)
// 4.創建Resolver
rWrapper, err := newCCResolverWrapper(cc, resolverBuilder)
// 5.完事
return cc, nil
}
顯而易見,在省略了億點點細節之後,我們發現建立連接的過程其實也很簡單,我們梳理一遍:
因為gRPC沒有提供服務註冊,服務發現的功能,所以需要開發者自己編寫服務發現的邏輯:也就是Resolver——解析器。
在得到了解析的結果,也就是一連串的IP地址之後,需要對其中的IP進行選擇,也就是Balancer。
其餘的就是一些錯誤處理、兜底策略等等,這些內容不在這一篇文章中講解。
2 Resolver的獲取
我們從Resolver開始講起。
cc.parsedTarget = grpcutil.ParseTarget(cc.target, cc.dopts.copts.Dialer != nil)
關於ParseTarget的邏輯我們用簡單一句話來概括:獲取開發者傳入的target參數的地址類型,在後續查找適合這種類型地址的Resolver。
然後我們來看查找Resolver的這部分操作,這部分程式碼比較簡單,我在程式碼中加了一些注釋:
resolverBuilder := cc.getResolver(cc.parsedTarget.Scheme)
func (cc *ClientConn) getResolver(scheme string) resolver.Builder {
// 先查看是否在配置中存在resolver
for _, rb := range cc.dopts.resolvers {
if scheme == rb.Scheme() {
return rb
}
}
// 如果配置中沒有相應的resolver,再從註冊的resolver中尋找
return resolver.Get(scheme)
}
// 可以看出,ResolverBuilder是從m這個map裡面找到的
func Get(scheme string) Builder {
if b, ok := m[scheme]; ok {
return b
}
return nil
}
看到這裡我們可以推測:對於每個ResolverBuilder,是需要提前註冊的。
我們找到Resolver的程式碼中,果然發現他在init()的時候註冊了自己。
func init() {
resolver.Register(&passthroughBuilder{})
}
// 註冊Resolver,即是把自己加入map中
func Register(b Builder) {
m[b.Scheme()] = b
}
至此,我們已經研究完了Resolver的註冊和獲取。
3 ResolverWrapper的創建
回到ClientConn的創建過程中,在獲取到了ResolverBuilder之後,進行下一步的操作:
rWrapper, err := newCCResolverWrapper(cc, resolverBuilder)
gRPC為了實現插件式的Resolver,因此採用了裝飾器模式,創建了一個ResolverWrapper。
我們看看在創建ResolverWrapper的細節:
func newCCResolverWrapper(cc *ClientConn, rb resolver.Builder) (*ccResolverWrapper, error) {
ccr := &ccResolverWrapper{
cc: cc,
done: grpcsync.NewEvent(),
}
// 根據傳入的Builder,創建resolver,並放入wrapper中
ccr.resolver, err = rb.Build(cc.parsedTarget, ccr, rbo)
return ccr, nil
}
好,到了這裡我們可以暫停一下。
我們停下來思考一下我們需要實現的功能:為了解耦Resolver和Balancer,我們希望能夠有一個中間的部分,接收到Resolver解析到的地址,然後對它們進行負載均衡。因此,在接下來的程式碼閱讀過程中,我們可以帶著這個問題:Resolver和Balancer的通訊過程是什麼樣的?
再看上面的程式碼,ClientConn的創建已經結束了。那麼我們可以推測,剩下的邏輯就在rb.Build(cc.parsedTarget, ccr, rbo)這一行程式碼裡面。
4 Resolver的創建
其實,Build並不是一個確定的方法,他是一個介面。
type Builder interface {
Build(target Target, cc ClientConn, opts BuildOptions) (Resolver, error)
}
在創建Resolver的時候,我們需要在Build方法裡面初始化Resolver的各種狀態。並且,因為Build方法中有一個target的參數,我們會在創建Resolver的時候,需要對這個target進行解析。
也就是說,創建Resolver的時候,會進行第一次的域名解析。並且,這個解析過程,是由開發者自己設計的。
到了這裡我們會自然而然的接著考慮,解析之後的結果應該保存為什麼樣的數據結構,又應該怎麼去將這個結果傳遞下去呢?
我們拿最簡單的passthroughResolver來舉例:
func (*passthroughBuilder) Build(target resolver.Target, cc resolver.ClientConn, opts resolver.BuildOptions) (resolver.Resolver, error) {
r := &passthroughResolver{
target: target,
cc: cc,
}
// 創建Resolver的時候,進行第一次的解析
r.start()
return r, nil
}
// 對於passthroughResolver來說,正如他的名字,直接將參數作為結果返回
func (r *passthroughResolver) start() {
r.cc.UpdateState(resolver.State{Addresses: []resolver.Address{{Addr: r.target.Endpoint}}})
}
我們可以看到,對於一個Resolver,需要將解析出的地址,傳入resolver.State中,然後調用r.cc.UpdateState方法。
那麼這個r.cc.UpdateState又是什麼呢?
他就是我們上面提到的ccResolverWrapper。
這個時候邏輯就很清晰了,gRPC的ClientConn通過調用ccResolverWrapper來進行域名解析,而具體的解析過程則由開發者自己決定。在解析完畢後,將解析的結果返回給ccResolverWrapper。
5 Balancer的選擇
我們因此也可以進行推測:在ccResolverWrapper中,會將解析出的結果以某種形式傳遞給Balancer。
我們接著往下看:
func (ccr *ccResolverWrapper) UpdateState(s resolver.State) {
...
// 將Resolver解析的最新狀態保存下來
ccr.curState = s
// 對狀態進行更新
ccr.poll(ccr.cc.updateResolverState(ccr.curState, nil))
}
關於poll方法這裡就不提了,重點我們看ccr.cc.updateResolverState(ccr.curState, nil)這部分。
這裡的ccr.cc中的cc,就是我們創建的ClientConn對象。
也就是說,此時Resolver解析的結果,最終又回到了ClientConn中。
注意,對於updateResolverState方法,在源碼中邏輯比較深,主要是為了處理各種情況。在這裡我直接把核心的那部分貼出來,所以這部分的程式碼你可以理解為是偽程式碼實現,和原本的程式碼是有出入的。如果你希望看到具體的實現,你可以去閱讀gRPC的源碼。
func (cc *ClientConn) updateResolverState(s resolver.State, err error) error {
var newBalancerName string
// 假設已經配置好了balancer,那麼使用配置中的balancer
if cc.sc != nil && cc.sc.lbConfig != nil {
newBalancerName = cc.sc.lbConfig.name
}
// 否則的話,遍歷解析結果中的地址,來判斷應該使用哪種balancer
else {
var isGRPCLB bool
for _, a := range addrs {
if a.Type == resolver.GRPCLB {
isGRPCLB = true
break
}
}
if isGRPCLB {
newBalancerName = grpclbName
} else if cc.sc != nil && cc.sc.LB != nil {
newBalancerName = *cc.sc.LB
} else {
newBalancerName = PickFirstBalancerName
}
}
// 具體的balancer邏輯
cc.switchBalancer(newBalancerName)
// 使用balancerWrapper更新Client的狀態
bw := cc.balancerWrapper
uccsErr := bw.updateClientConnState(&balancer.ClientConnState{ResolverState: s, BalancerConfig: balCfg})
return ret
}
我們再來康康switchBalancer到底做了什麼:
func (cc *ClientConn) switchBalancer(name string) {
...
builder := balancer.Get(name)
cc.curBalancerName = builder.Name()
cc.balancerWrapper = newCCBalancerWrapper(cc, builder, cc.balancerBuildOpts)
}
是不是有一種似曾相識的感覺?
沒錯,這部分的程式碼,跟ResolverWrapper的創建過程很接近。都是獲取到對應的Builder Name,然後通過name來獲取對應的Builder,然後創建wrapper。
func newCCBalancerWrapper(cc *ClientConn, b balancer.Builder, bopts balancer.BuildOptions) *ccBalancerWrapper {
ccb := &ccBalancerWrapper{
cc: cc,
scBuffer: buffer.NewUnbounded(),
done: grpcsync.NewEvent(),
subConns: make(map[*acBalancerWrapper]struct{}),
}
go ccb.watcher()
ccb.balancer = b.Build(ccb, bopts)
return ccb
}
這裡的ccb.watcher我們先不管他,這個是跟連接的狀態有關的內容,我們將在下一篇文章在進行分析。
同樣的,Build具體的Balancer的過程,也是由開發者自己決定的。
在Balancer的創建過程中,涉及到了連接的管理。我們同樣的把這部分內容放在下一篇中。在這篇文章中我們的主線任務還是Resolver和Balancer的交互是怎麼樣的。
在創建完相應的BalancerWrapper之後,就來到了bw.updateClientConnState這行了。
注意,這裡的bw就是我們上面創建的balancer。也就是說這裡又來到了真正的Balancer邏輯。
但是這其中的程式碼我們在這篇文章中先不進行介紹,gRPC對於真正的HTTP/2連接的管理邏輯也比較的複雜,我們下篇文章見。
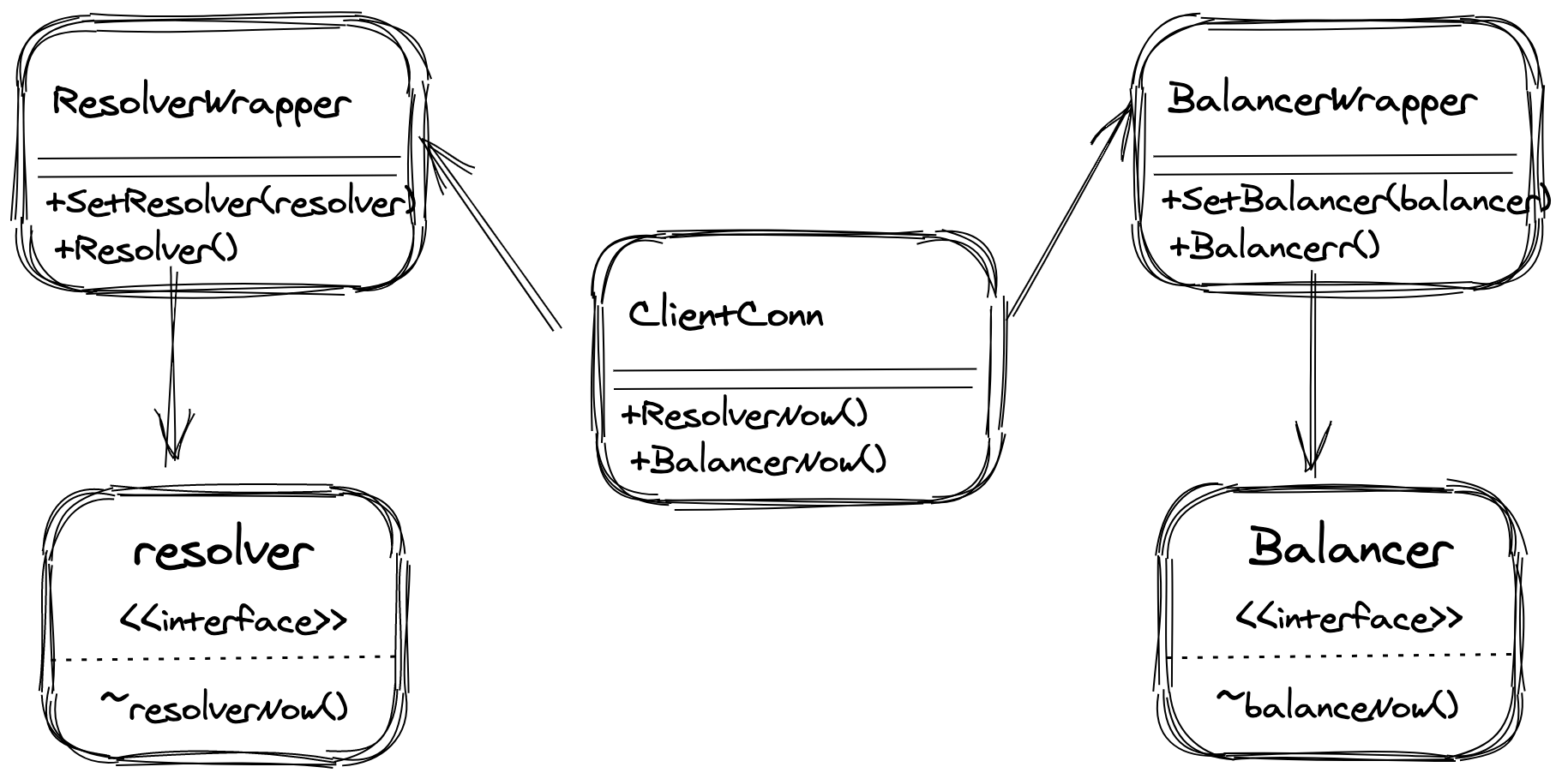
6 小結
到這裡我們來總結一下:創建ClientConn的時候創建ResolverWrapper,由ClientConn通知ResolverWrapper進行域名解析。
此時,ResolverWrapper會將這個請求交給真正的Resolver,由真正的Resolver來處理域名解析。
解析完畢後,Resolver會將結果保存在ResolverWrapper中,ResolverWrapper再將這個結果返回給ClientConn。
當ClientConn發現解析的結果發生了改變,那麼他就會去通知BalancerWrapper,重新進行負載均衡。
此時BalancerWrapper又會去讓真正的Balancer做這件事,最終將結果返回給ClientConn。
我們畫張圖來展示這個過程:
寫在最後
首先,謝謝你能看到這裡。
這是一篇純源碼解讀的文章,作為上一篇純理論文章的補充。建議兩篇文章配合一起食用:)
如果在這個過程中,你有任何的疑問,都可以留言給我,或者在公眾號「紅雞菌」中找到我。
在下一篇文章中,我將向你介紹Balancer中的具體細節,也就是gRPC的底層連接管理。同樣的,我應該也會用一篇文章來介紹應該怎麼設計,然後再用一篇文章來介紹具體的實現,我們下篇文章再見。
再次感謝你的閱讀!


