JUnit5學習之七:參數化測試(Parameterized Tests)進階
- 2021 年 2 月 28 日
- 筆記
歡迎訪問我的GitHub
//github.com/zq2599/blog_demos
內容:所有原創文章分類匯總及配套源碼,涉及Java、Docker、Kubernetes、DevOPS等;
關於《JUnit5學習》系列
《JUnit5學習》系列旨在通過實戰提升SpringBoot環境下的單元測試技能,一共八篇文章,鏈接如下:
- 基本操作
- Assumptions類
- Assertions類
- 按條件執行
- 標籤(Tag)和自定義註解
- 參數化測試(Parameterized Tests)基礎
- 參數化測試(Parameterized Tests)進階
- 綜合進階(終篇)
本篇概覽
- 本文是《JUnit5學習》系列的第七篇,前文咱們對JUnit5的參數化測試(Parameterized Tests)有了基本了解,可以使用各種數據源控制測試方法多次執行,今天要在此基礎上更加深入,掌握參數化測試的一些高級功能,解決實際問題;
- 本文由以下章節組成:
- 自定義數據源
- 參數轉換
- 多欄位聚合
- 多欄位轉對象
- 測試執行名稱自定義
源碼下載
- 如果您不想編碼,可以在GitHub下載所有源碼,地址和鏈接資訊如下表所示:
| 名稱 | 鏈接 | 備註 |
|---|---|---|
| 項目主頁 | //github.com/zq2599/blog_demos | 該項目在GitHub上的主頁 |
| git倉庫地址(https) | //github.com/zq2599/blog_demos.git | 該項目源碼的倉庫地址,https協議 |
| git倉庫地址(ssh) | [email protected]:zq2599/blog_demos.git | 該項目源碼的倉庫地址,ssh協議 |
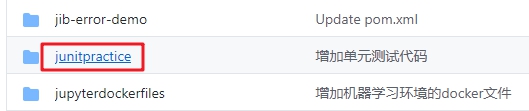
- 這個git項目中有多個文件夾,本章的應用在junitpractice文件夾下,如下圖紅框所示:
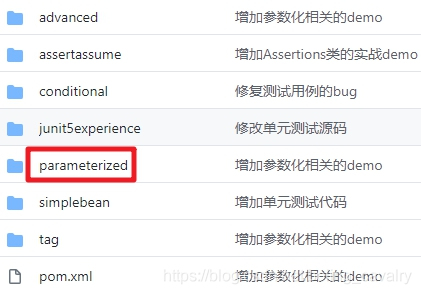
- junitpractice是父子結構的工程,本篇的程式碼在parameterized子工程中,如下圖:
自定義數據源
- 前文使用了很多種數據源,如果您對它們的各種限制不滿意,想要做更徹底的個性化訂製,可以開發ArgumentsProvider介面的實現類,並使用@ArgumentsSource指定;
- 舉個例子,先開發ArgumentsProvider的實現類MyArgumentsProvider.java:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.api.extension.ExtensionContext;
import org.junit.jupiter.params.provider.Arguments;
import org.junit.jupiter.params.provider.ArgumentsProvider;
import java.util.stream.Stream;
public class MyArgumentsProvider implements ArgumentsProvider {
@Override
public Stream<? extends Arguments> provideArguments(ExtensionContext context) throws Exception {
return Stream.of("apple4", "banana4").map(Arguments::of);
}
}
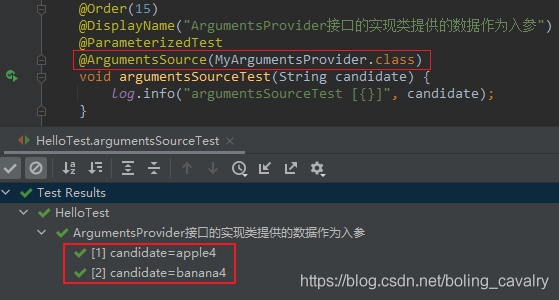
- 再給測試方法添加@ArgumentsSource,並指定MyArgumentsProvider:
@Order(15)
@DisplayName("ArgumentsProvider介面的實現類提供的數據作為入參")
@ParameterizedTest
@ArgumentsSource(MyArgumentsProvider.class)
void argumentsSourceTest(String candidate) {
log.info("argumentsSourceTest [{}]", candidate);
}
- 執行結果如下:
參數轉換
- 參數化測試的數據源和測試方法入參的數據類型必須要保持一致嗎?其實JUnit5並沒有嚴格要求,而事實上JUnit5是可以做一些自動或手動的類型轉換的;
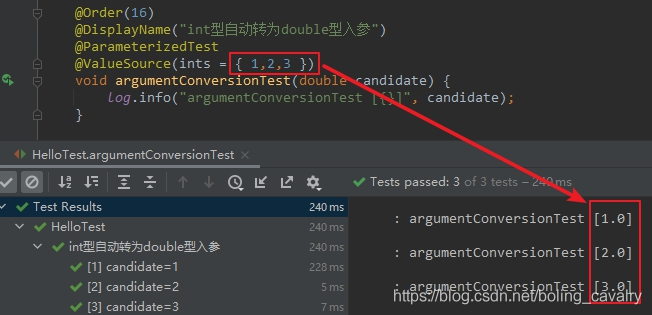
- 如下程式碼,數據源是int型數組,但測試方法的入參卻是double:
@Order(16)
@DisplayName("int型自動轉為double型入參")
@ParameterizedTest
@ValueSource(ints = { 1,2,3 })
void argumentConversionTest(double candidate) {
log.info("argumentConversionTest [{}]", candidate);
}
- 執行結果如下,可見int型被轉為double型傳給測試方法(Widening Conversion):
- 還可以指定轉換器,以轉換器的邏輯進行轉換,下面這個例子就是將字元串轉為LocalDate類型,關鍵是@JavaTimeConversionPattern:
@Order(17)
@DisplayName("string型,指定轉換器,轉為LocalDate型入參")
@ParameterizedTest
@ValueSource(strings = { "01.01.2017", "31.12.2017" })
void argumentConversionWithConverterTest(
@JavaTimeConversionPattern("dd.MM.yyyy") LocalDate candidate) {
log.info("argumentConversionWithConverterTest [{}]", candidate);
}
- 執行結果如下:

欄位聚合(Argument Aggregation)
- 來思考一個問題:如果數據源的每條記錄有多個欄位,測試方法如何才能使用這些欄位呢?
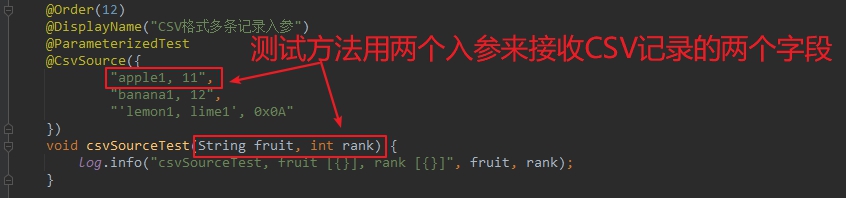
- 回顧剛才的@CsvSource示例,如下圖,可見測試方法用兩個入參對應CSV每條記錄的兩個欄位,如下所示:
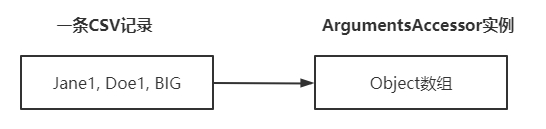
3. 上述方式應對少量欄位還可以,但如果CSV每條記錄有很多欄位,那測試方法豈不是要定義大量入參?這顯然不合適,此時可以考慮JUnit5提供的欄位聚合功能(Argument Aggregation),也就是將CSV每條記錄的所有欄位都放入一個ArgumentsAccessor類型的對象中,測試方法只要聲明ArgumentsAccessor類型作為入參,就能在方法內部取得CSV記錄的所有欄位,效果如下圖,可見CSV欄位實際上是保存在ArgumentsAccessor實例內部的一個Object數組中:
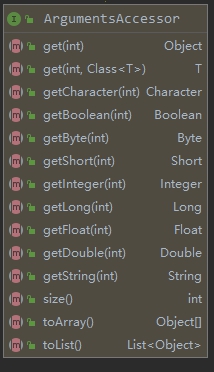
4. 如下圖,為了方便從ArgumentsAccessor實例獲取數據,ArgumentsAccessor提供了獲取各種類型的方法,您可以按實際情況選用:
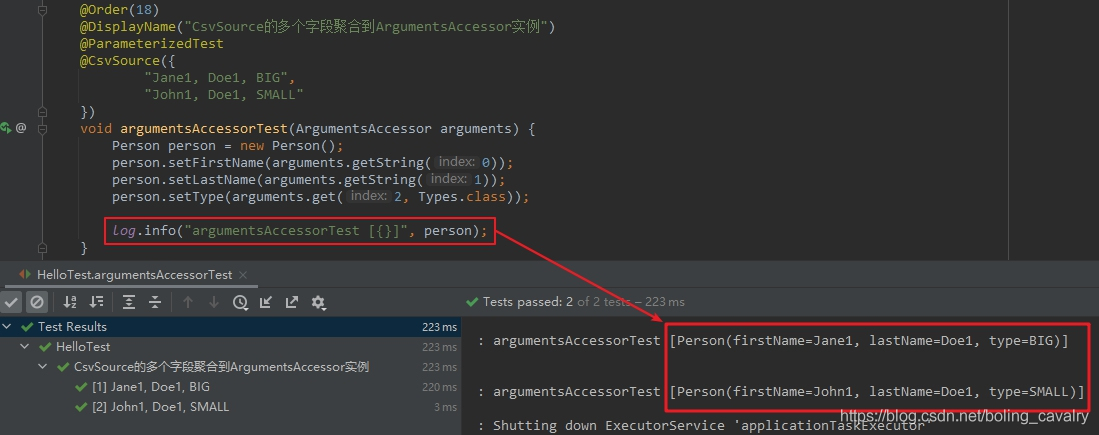
- 下面的示例程式碼中,CSV數據源的每條記錄有三個欄位,而測試方法只有一個入參,類型是ArgumentsAccessor,在測試方法內部,可以用ArgumentsAccessor的getString、get等方法獲取CSV記錄的不同欄位,例如arguments.getString(0)就是獲取第一個欄位,得到的結果是字元串類型,而arguments.get(2, Types.class)的意思是獲取第二個欄位,並且轉成了Type.class類型:
@Order(18)
@DisplayName("CsvSource的多個欄位聚合到ArgumentsAccessor實例")
@ParameterizedTest
@CsvSource({
"Jane1, Doe1, BIG",
"John1, Doe1, SMALL"
})
void argumentsAccessorTest(ArgumentsAccessor arguments) {
Person person = new Person();
person.setFirstName(arguments.getString(0));
person.setLastName(arguments.getString(1));
person.setType(arguments.get(2, Types.class));
log.info("argumentsAccessorTest [{}]", person);
}
- 上述程式碼執行結果如下圖,可見通過ArgumentsAccessor能夠取得CSV數據的所有欄位:
更優雅的聚合
- 前面的聚合解決了獲取CSV數據多個欄位的問題,但依然有瑕疵:從ArgumentsAccessor獲取數據生成Person實例的程式碼寫在了測試方法中,如下圖紅框所示,測試方法中應該只有單元測試的邏輯,而創建Person實例的程式碼放在這裡顯然並不合適:
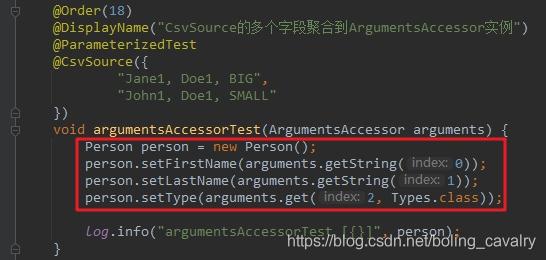
2. 針對上面的問題,JUnit5也給出了方案:通過註解的方式,指定一個從ArgumentsAccessor到Person的轉換器,示例如下,可見測試方法的入參有個註解@AggregateWith,其值PersonAggregator.class就是從ArgumentsAccessor到Person的轉換器,而入參已經從前面的ArgumentsAccessor變成了Person:
@Order(19)
@DisplayName("CsvSource的多個欄位,通過指定聚合類轉為Person實例")
@ParameterizedTest
@CsvSource({
"Jane2, Doe2, SMALL",
"John2, Doe2, UNKNOWN"
})
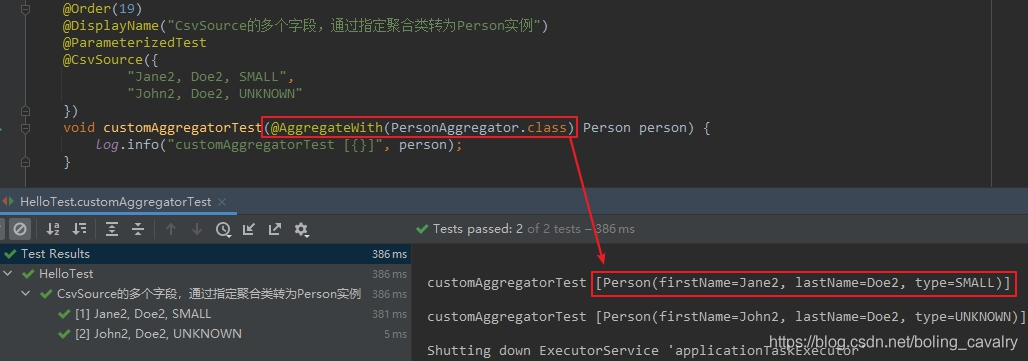
void customAggregatorTest(@AggregateWith(PersonAggregator.class) Person person) {
log.info("customAggregatorTest [{}]", person);
}
- PersonAggregator是轉換器類,需要實現ArgumentsAggregator介面,具體的實現程式碼很簡單,也就是從ArgumentsAccessor示例獲取欄位創建Person對象的操作:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.api.extension.ParameterContext;
import org.junit.jupiter.params.aggregator.ArgumentsAccessor;
import org.junit.jupiter.params.aggregator.ArgumentsAggregationException;
import org.junit.jupiter.params.aggregator.ArgumentsAggregator;
public class PersonAggregator implements ArgumentsAggregator {
@Override
public Object aggregateArguments(ArgumentsAccessor arguments, ParameterContext context) throws ArgumentsAggregationException {
Person person = new Person();
person.setFirstName(arguments.getString(0));
person.setLastName(arguments.getString(1));
person.setType(arguments.get(2, Types.class));
return person;
}
}
- 上述測試方法的執行結果如下:
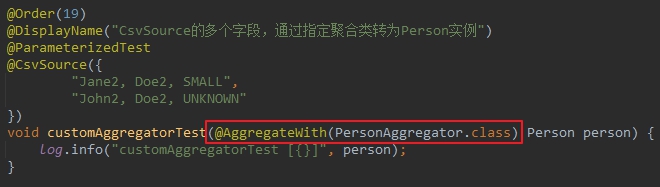
進一步簡化
- 回顧一下剛才用註解指定轉換器的程式碼,如下圖紅框所示,您是否回憶起JUnit5支援自定義註解這一茬,咱們來把紅框部分的程式碼再簡化一下:
2. 新建註解類CsvToPerson.java,程式碼如下,非常簡單,就是把上圖紅框中的@AggregateWith(PersonAggregator.class)搬過來了:
package com.bolingcavalry.parameterized.service.impl;
import org.junit.jupiter.params.aggregator.AggregateWith;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.PARAMETER)
@AggregateWith(PersonAggregator.class)
public @interface CsvToPerson {
}
- 再來看看上圖紅框中的程式碼可以簡化成什麼樣子,直接用@CsvToPerson就可以將ArgumentsAccessor轉為Person對象了:
@Order(20)
@DisplayName("CsvSource的多個欄位,通過指定聚合類轉為Person實例(自定義註解)")
@ParameterizedTest
@CsvSource({
"Jane3, Doe3, BIG",
"John3, Doe3, UNKNOWN"
})
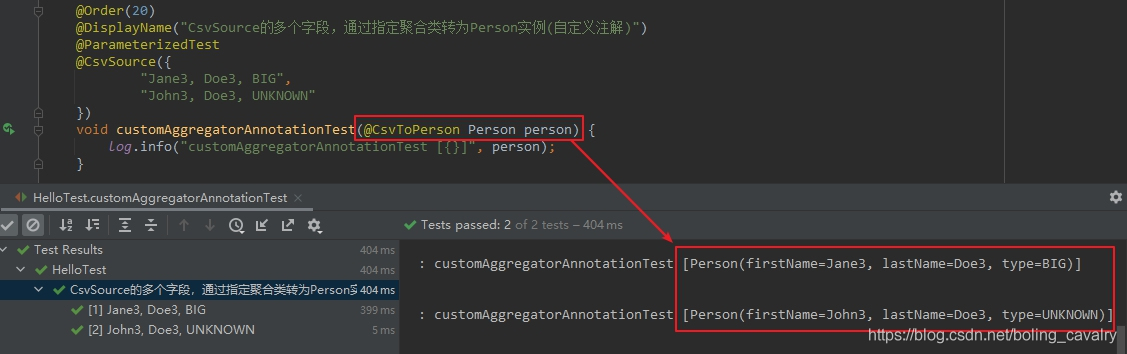
void customAggregatorAnnotationTest(@CsvToPerson Person person) {
log.info("customAggregatorAnnotationTest [{}]", person);
}
- 執行結果如下,可見和@AggregateWith(PersonAggregator.class)效果一致:
測試執行名稱自定義
- 文章最後,咱們來看個輕鬆的知識點吧,如下圖紅框所示,每次執行測試方法,IDEA都會展示這次執行的序號和參數值:
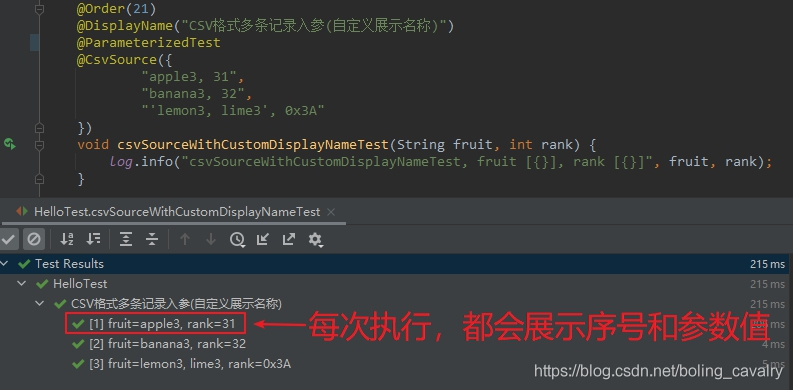
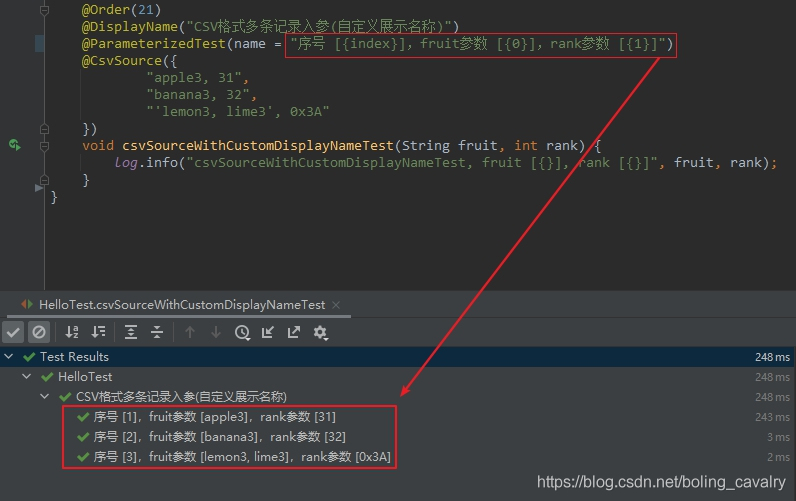
- 其實上述紅框中的內容格式也可以訂製,格式模板就是@ParameterizedTest的name屬性,修改後的測試方法完整程式碼如下,可見這裡改成了中文描述資訊:
@Order(21)
@DisplayName("CSV格式多條記錄入參(自定義展示名稱)")
@ParameterizedTest(name = "序號 [{index}],fruit參數 [{0}],rank參數 [{1}]")
@CsvSource({
"apple3, 31",
"banana3, 32",
"'lemon3, lime3', 0x3A"
})
void csvSourceWithCustomDisplayNameTest(String fruit, int rank) {
log.info("csvSourceWithCustomDisplayNameTest, fruit [{}], rank [{}]", fruit, rank);
}
- 執行結果如下:
- 至此,JUnit5的參數化測試(Parameterized)相關的知識點已經學習和實戰完成了,掌握了這麼強大的參數輸入技術,咱們的單元測試的程式碼覆蓋率和場景範圍又可以進一步提升了;
你不孤單,欣宸原創一路相伴
歡迎關注公眾號:程式設計師欣宸
微信搜索「程式設計師欣宸」,我是欣宸,期待與您一同暢遊Java世界…
//github.com/zq2599/blog_demos


