關於 HTTP 後端人員需要了解的 20+ 圖片!
- 2021 年 2 月 27 日
- 筆記
- MoreThanJava
前言
當您網上衝浪時,HTTP 協議無處不在。當您瀏覽網頁、獲取一張圖片、一段影片時,HTTP 協議就正在發生。
本篇將儘可能用簡短的例子和必要的說明來讓您了解基礎的 HTTP 知識。
目錄:
- 什麼是 HTTP?
- HTTP 簡史;
- HTTP 與 HTTPS;
Part 1. 什麼是 HTTP?
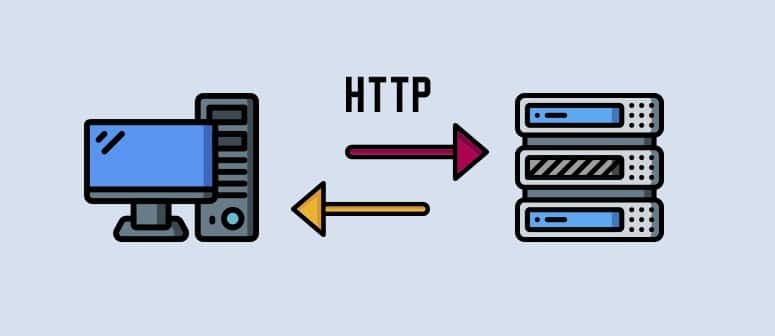
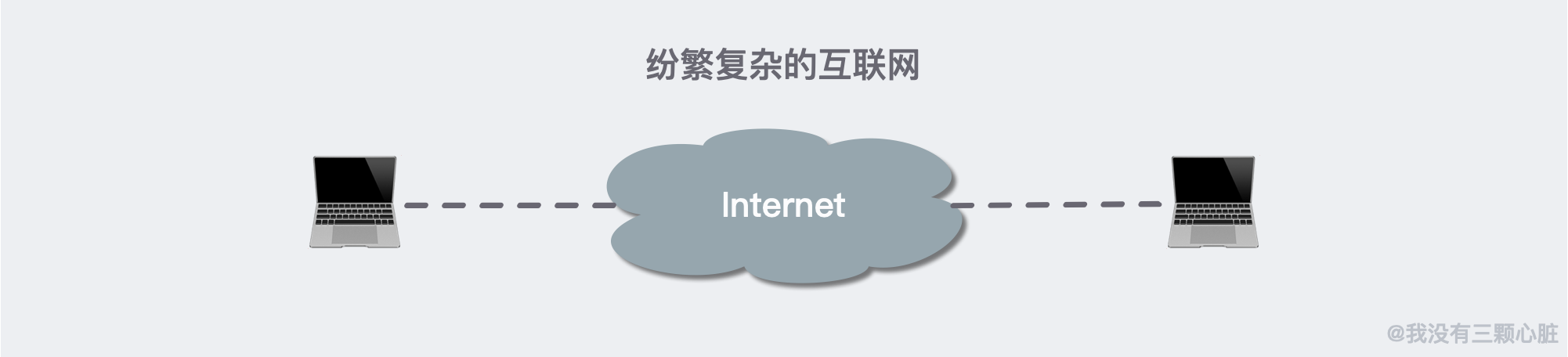
互聯網是有關 web 客戶端和 web 伺服器之間的通訊。
HTTP(HyperText Transfer Protocol)又叫超文本傳輸協議。本質上就是一個協定好雙方如何進行交流溝通的約定。
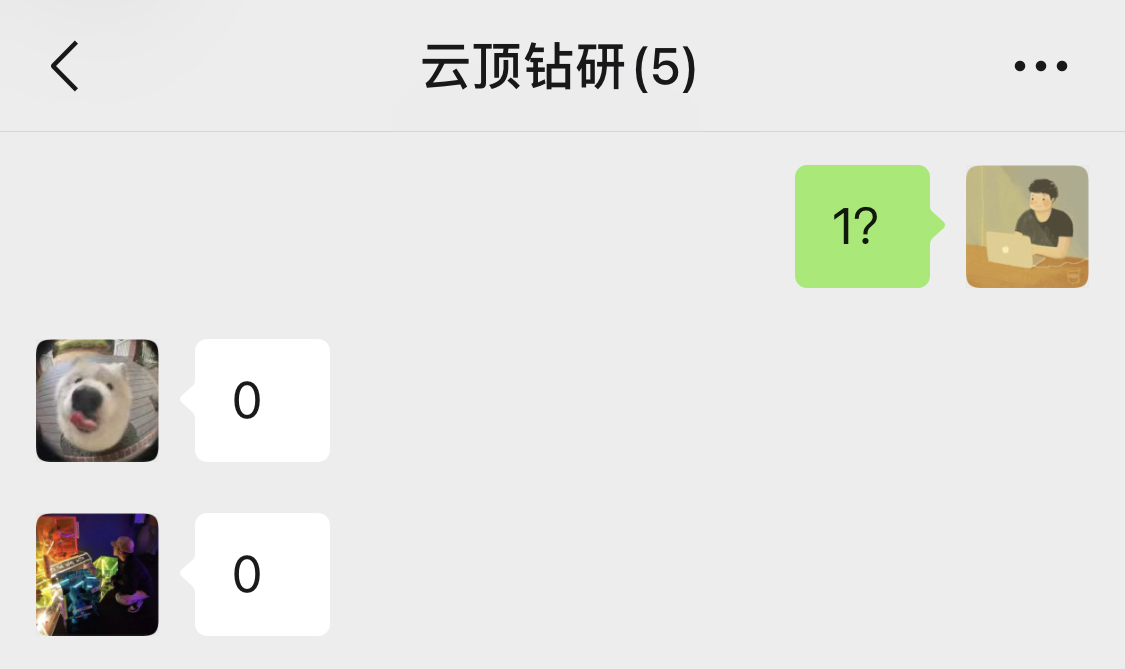
這就好比我在一起玩遊戲的朋友群里發送一條 「1?」 的消息,朋友們就立即知道是在詢問今晚是不是要一起遊戲的意思。
但是如果我給其他人發送 「1?」 就可能出現問題:他們不知道我在說什麼。
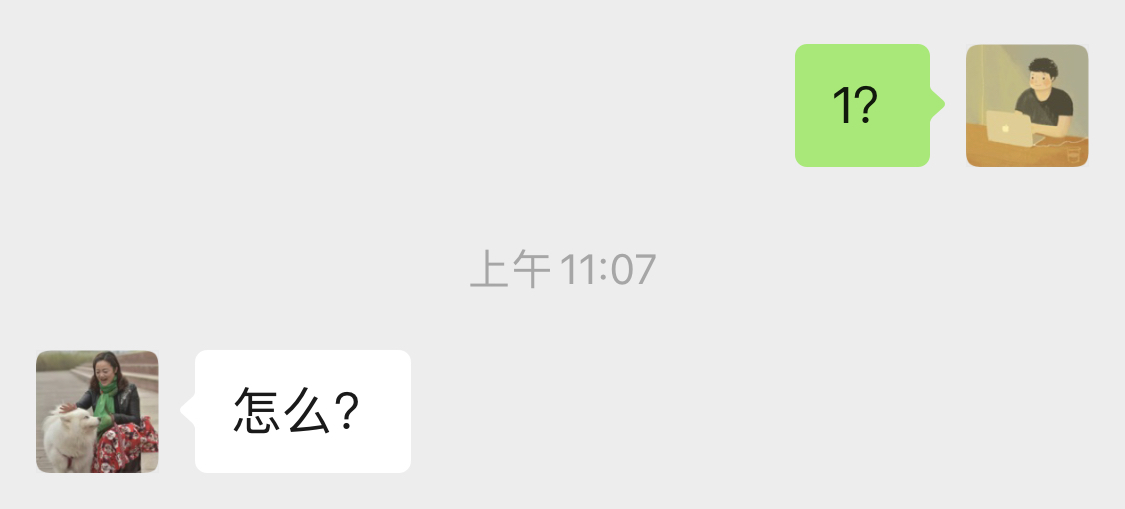
本質上,這就是 HTTP 協議所代表的含義。我們已經同意,如果我們以特定的方式發送消息,則伺服器就會理解消息的意圖並作出回應。
Part 2. HTTP 簡史
1989 年 3 月,互聯網還只屬於少數人。在這一互聯網的黎明期,HTTP 誕生了。
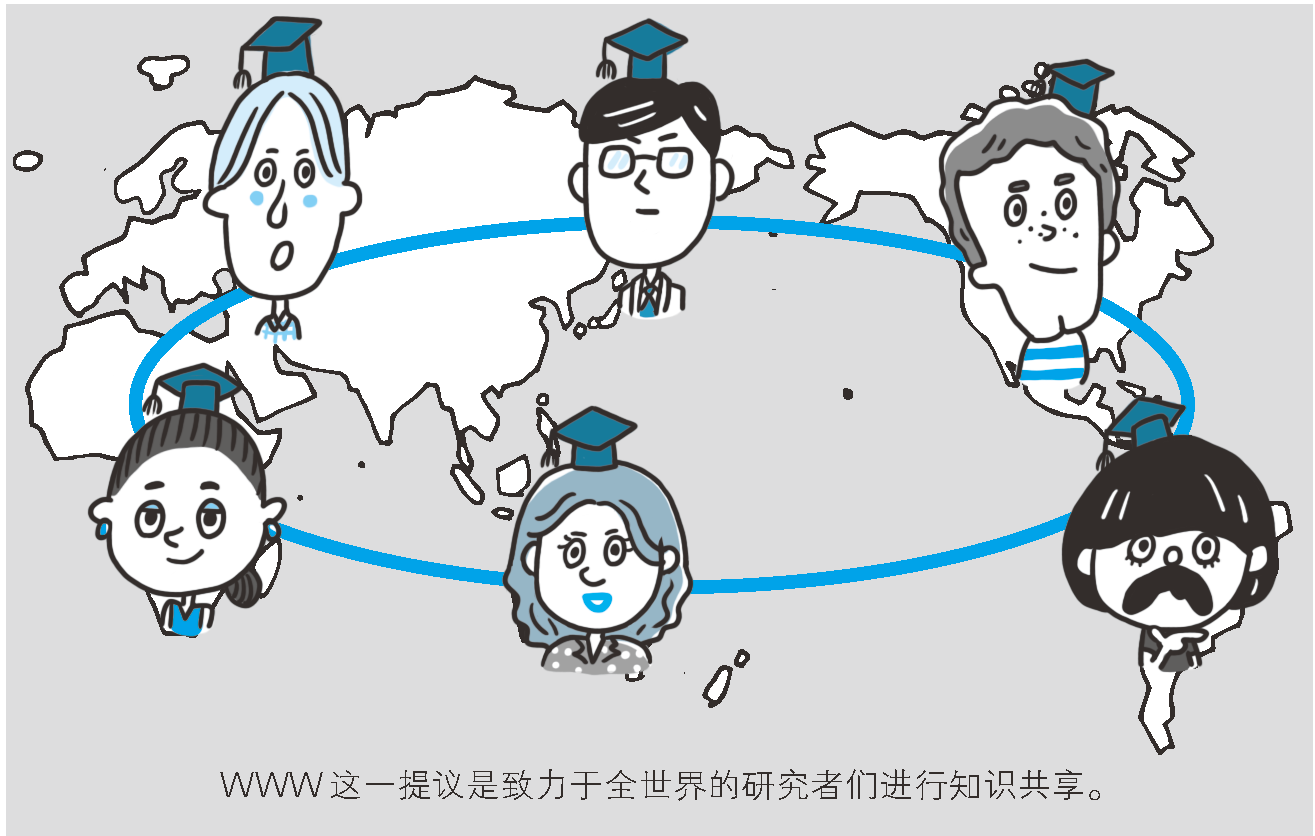
HTTP / 0.9 – 單行協議
1989年,當時還在歐洲核子研究組織(CERN)工作的蒂姆·伯納斯·李(Tim Berners-Lee)提出了一種能讓遠隔兩地的研究者們共享知識的設想。

最開始稱為 Mesh,後來在 1990 年實施期間將其重命名為 World Wide Web(萬維網)。它基於現有的 TCP/IP 協議構建,包括 4 個部分:
- 一種表示超文本文檔的文本格式,即超文本標記語言(HTML);
- 一種用於交換這些文檔的簡單協議,即 HyperText 傳輸協議(HTTP);
- 一個客戶端可以顯示這些文檔,第一個 Web 瀏覽器稱為 WorldWideWeb。
- 一個可以訪問文檔的伺服器;
這四部分在 1990 年底完成。雖然此時 Web 頁面只能顯示單純的文本內容,瀏覽器也只能顯示呆板的文字資訊,不過這已經基本滿足了建立 Web 站點的初衷,實現了資訊資源共享。
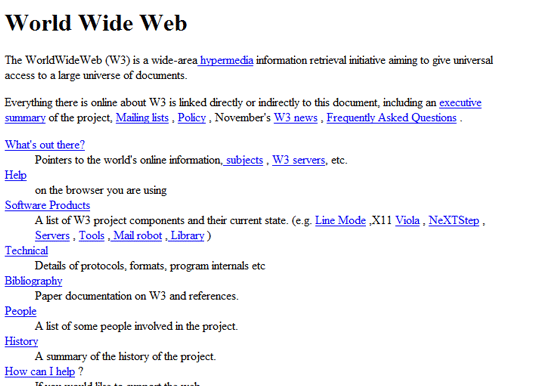
以下就是 HTTP/0.9 的請求內容:
GET /page.html
用唯一可用的 GET 方法向目標伺服器獲取指定的文檔。(一旦連接到伺服器,協議、伺服器、埠號這些都不是必須的)
響應也極其簡單:只包含文檔本身。
<HTML>
網頁的內容
</HTML>
這意味著 HTTP/0.9 只能夠傳輸 HTML 文件。一旦出現問題,一個特殊的包含問題描述資訊的 HTML 文件將被發回,供人們查看。
HTTP/1.0 – 構建可擴展性
由於 HTTP/0.9 協議的應用十分有限,加之 HTTP 使用量和 HTML 的高速發展,瀏覽器和伺服器迅速擴展其內容使其用途更廣:
- 協議版本資訊會隨著每一次請求發送;
----------HTTP/0.9請求----------
GET /page.html
----------HTTP/1.0請求----------
GET /page.html HTTP/1.0 -> 新增協議版本
- 伺服器在響應時回復狀態碼,使瀏覽器能了解請求執行成功或失敗,並相應調整行為(如更新或失敗);
----------HTTP/0.9響應----------
<HTML>
....
</HTML>
----------HTTP/1.0響應----------
200 OK -> 新增狀態碼
<HTML>
....
</HTML>
- 引入了 HTTP 頭的概念,無論是請求還是響應,允許傳輸其他資訊,使協議更靈活以及更具擴展性;

- 在 HTTP 頭的幫助下,具備了除傳輸純文本的 HTML 文件以外,還可以傳輸其他類型文檔的能力(歸功於
Content-Type頭);

HTTP/0.9 規範大約只有一頁,而 HTTP/1.0 在 RFC-1945 中定義的規範則足足有 60 頁。這說明 HTTP 已經成長為一個重要的工具。
儘管 HTTP/1.0 從 HTTP/0.9 有了很大的飛躍,但仍然存在許多必須解決的已知缺陷。例如與 TCP 協議交互不良、沒有充分考慮快取等問題。
拿與 TCP 協議交互不良舉例。由於 HTTP 是基於 TCP 建立的,所以通訊之前需要建立連接,通訊結束之後需要斷開連接。
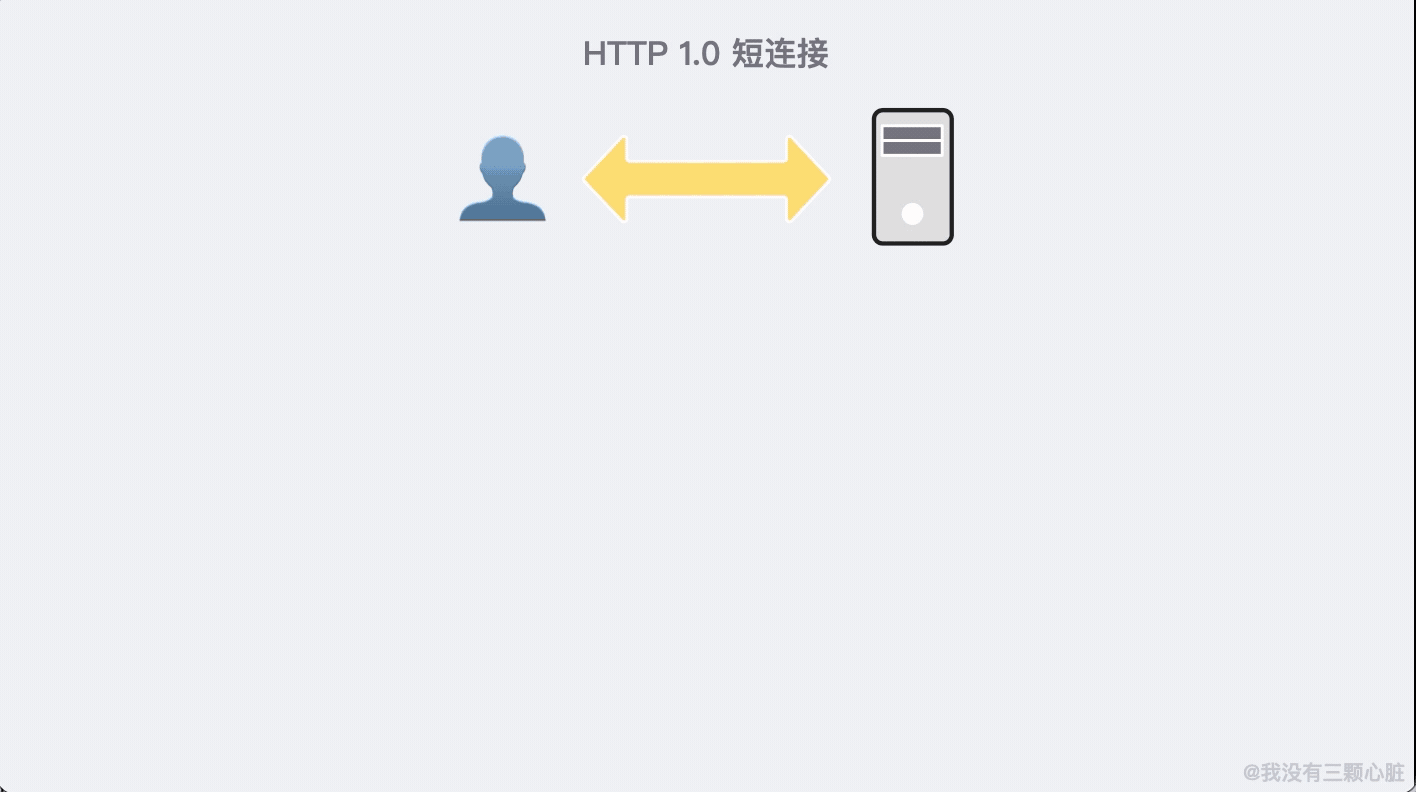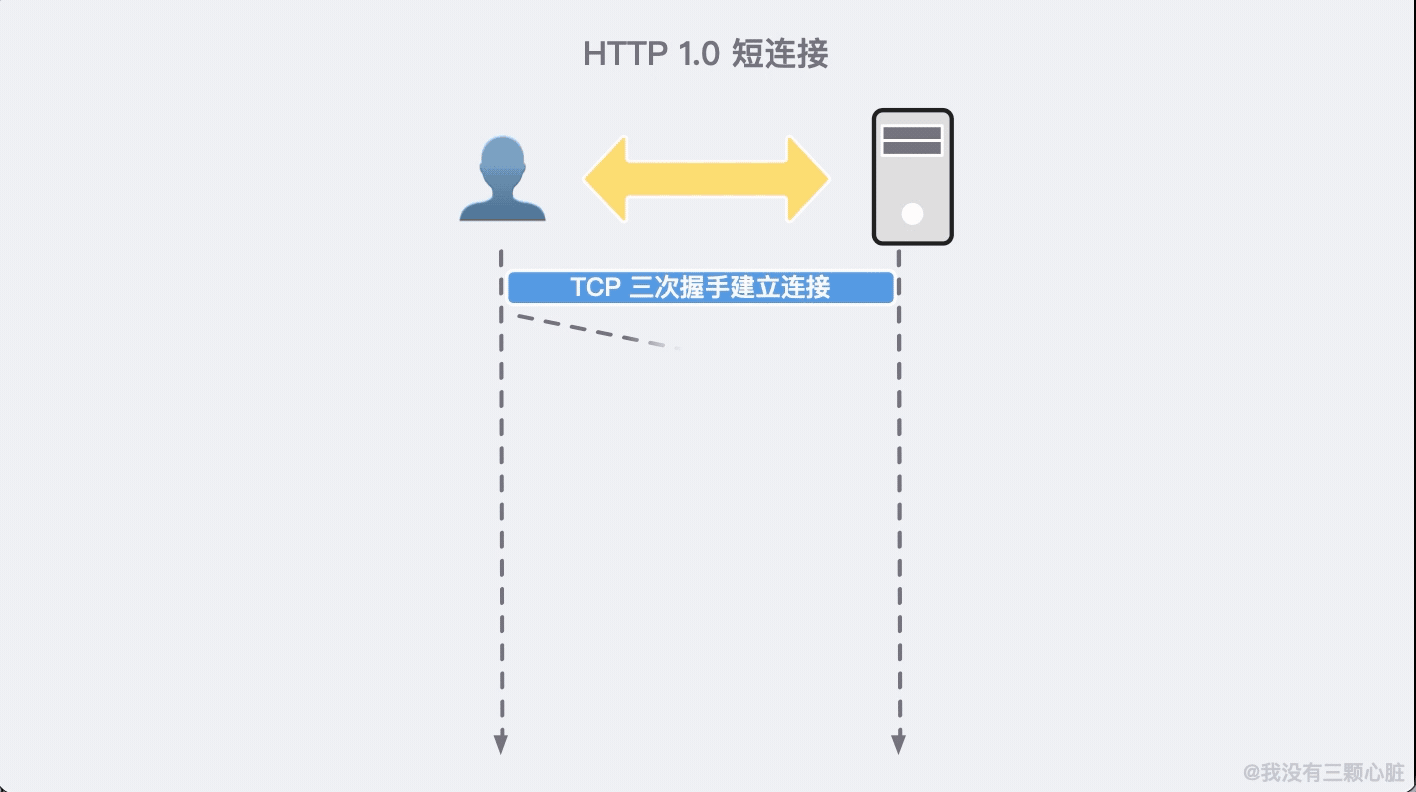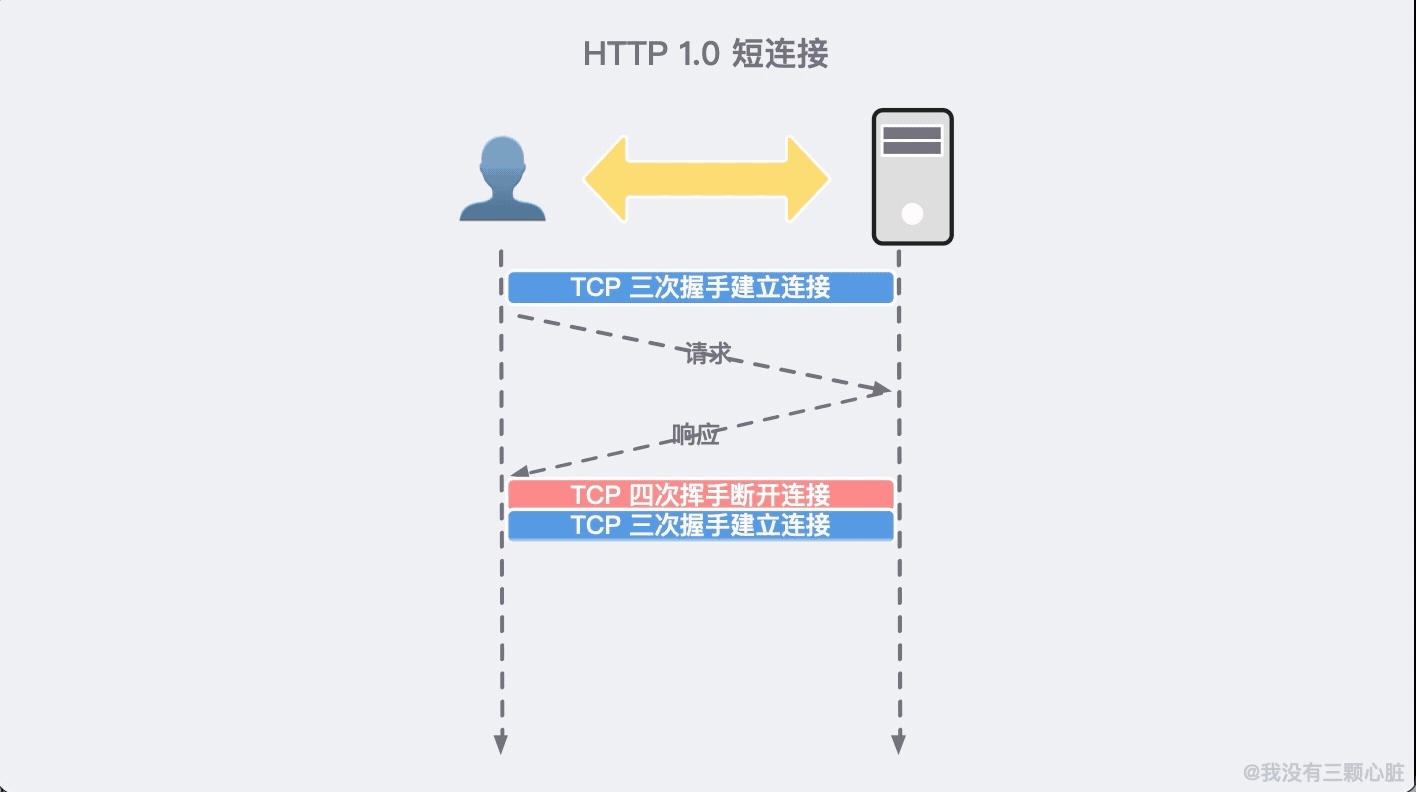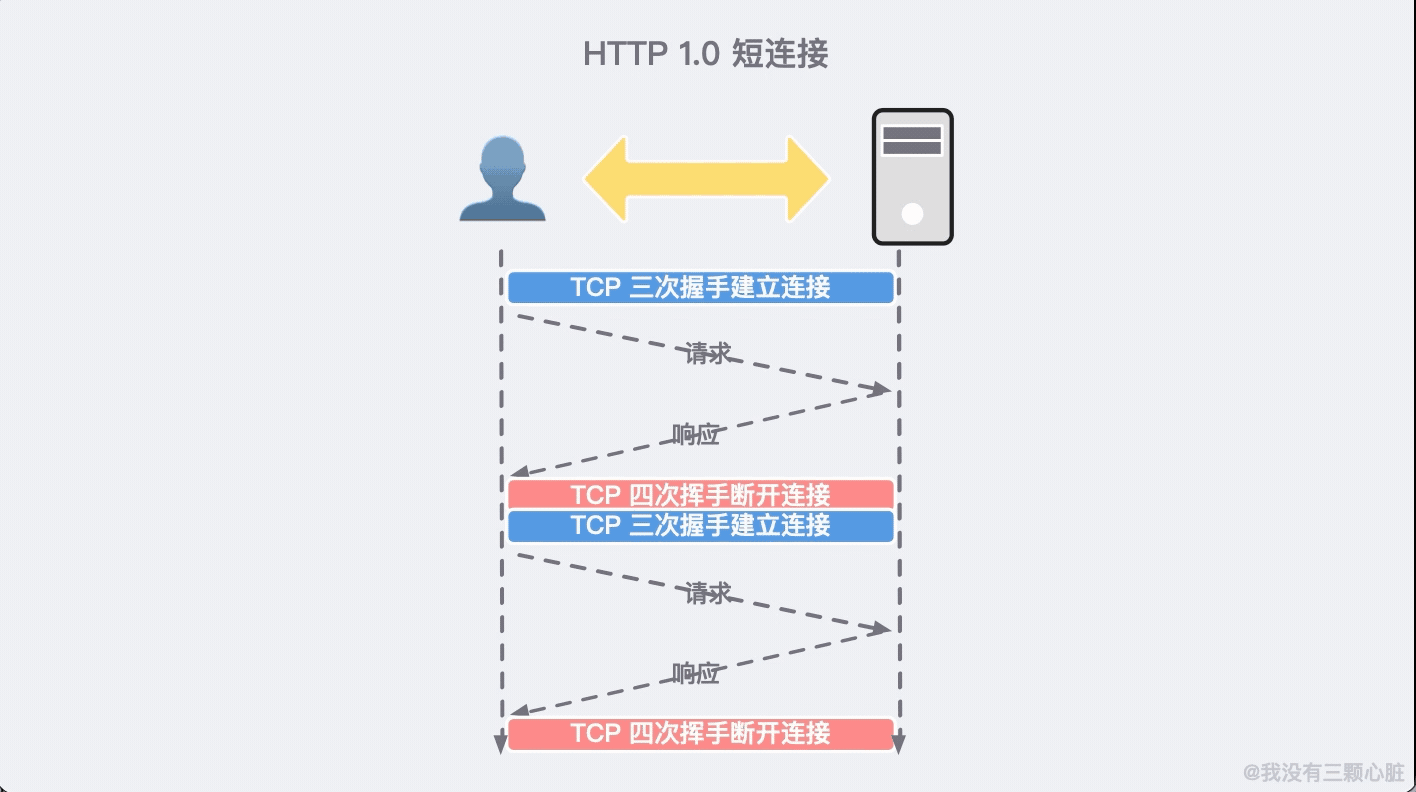
HTTP/1.0 每一次的通訊都需要建立並斷開連接,這無疑增加了無謂的通訊開銷。
HTTP/1.1 – 標準化的協議
文檔 RFC 1945 定義了 HTTP/1.0,但它是狹義的,並不是官方標準。所以實際運用起來非常地混亂。所以實際上自 1995 年開始,即 HTTP/1.0 文檔發布的下一年,就開始修訂 HTTP 的第一個標準化版本。
HTTP/1.1 在 1997 年 1 月以 RFC 2068 文件發布。HTTP/1.1 消除了大量歧義內容並引入了多項改進:
- 連接可以復用,節省了多次打開 TCP 連接載入網頁文檔資源的時間;

- 增加管線化技術,允許在第一個應答被完全發送之前就發送第二個請求,以降低通訊延遲;

- 支援響應分塊;
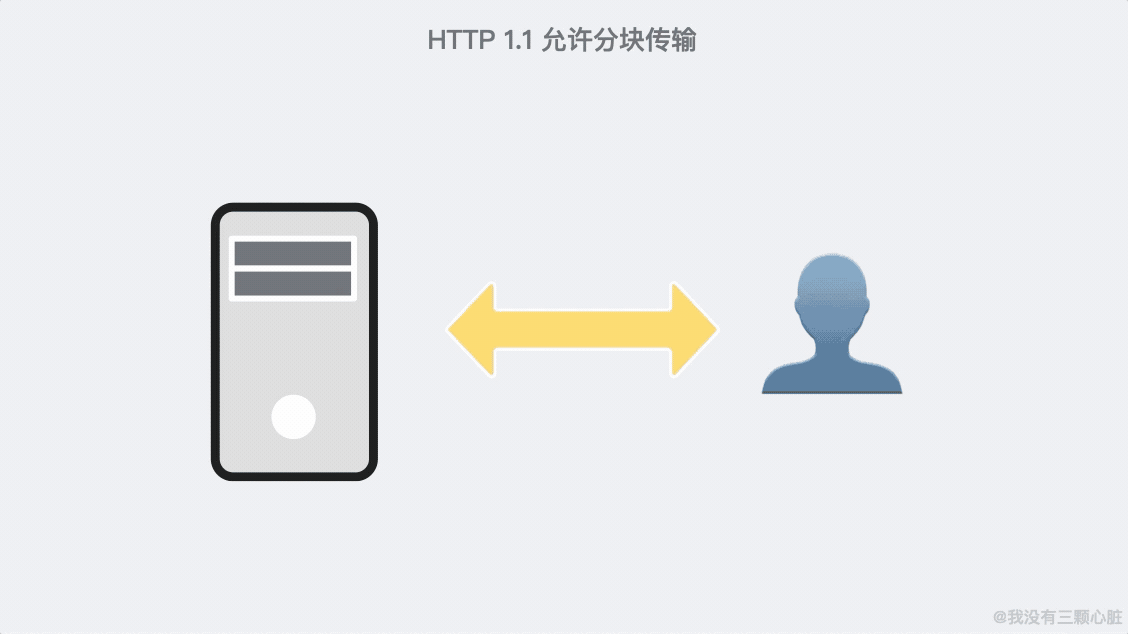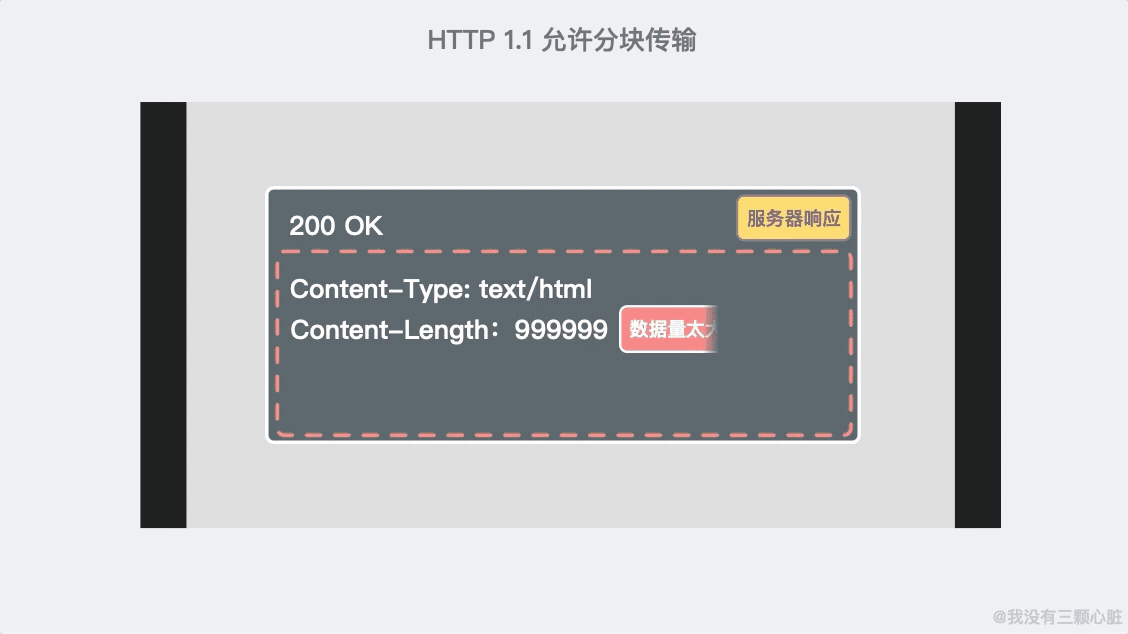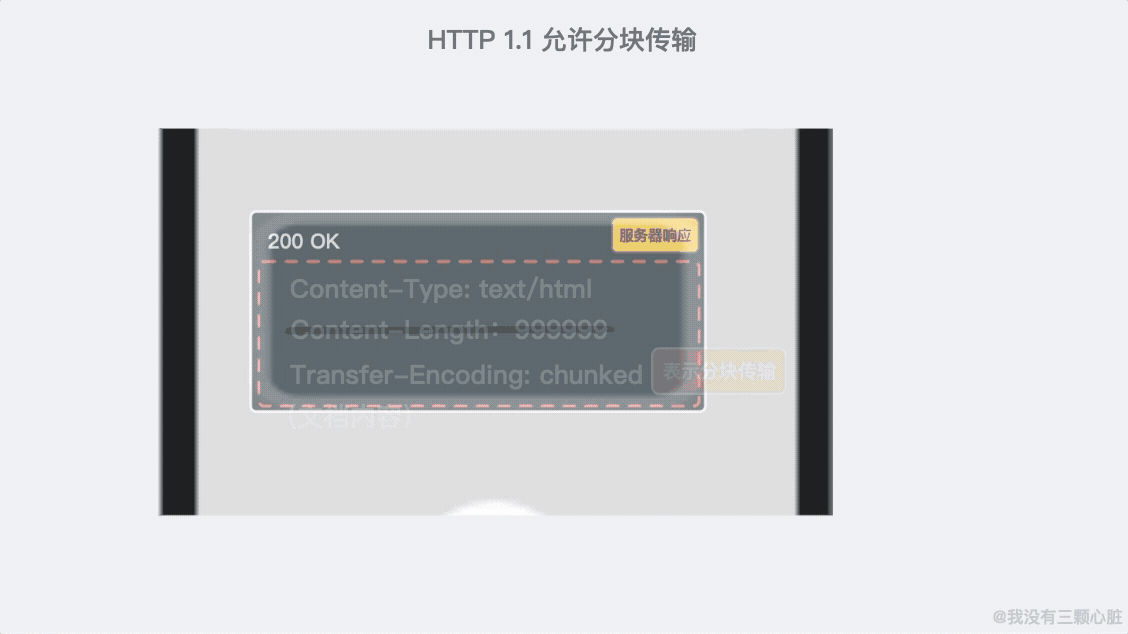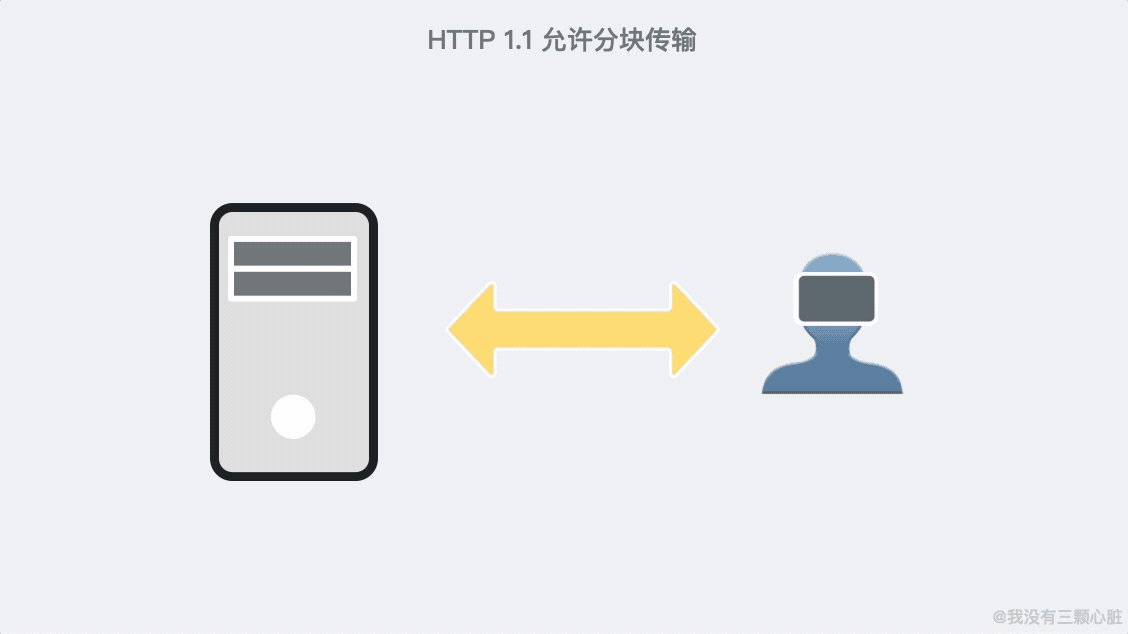
-
引入額外的快取控制機制,在 HTTP
Cache-Control標頭中引入了很多可以選擇的選項; -
引入內容協商機制,包括語言,編碼,類型等,並允許客戶端和伺服器之間約定以最合適的內容進行交換;
-
能夠使不同域名配置在同一個 IP 地址的伺服器上。
一個典型的請求流程, 所有請求都通過一個連接實現,看起來就像這樣:
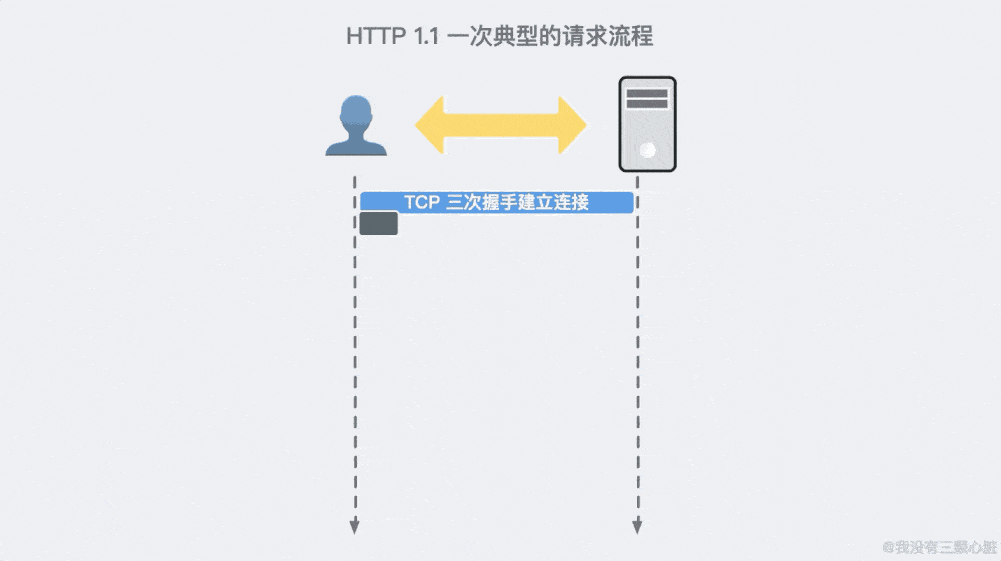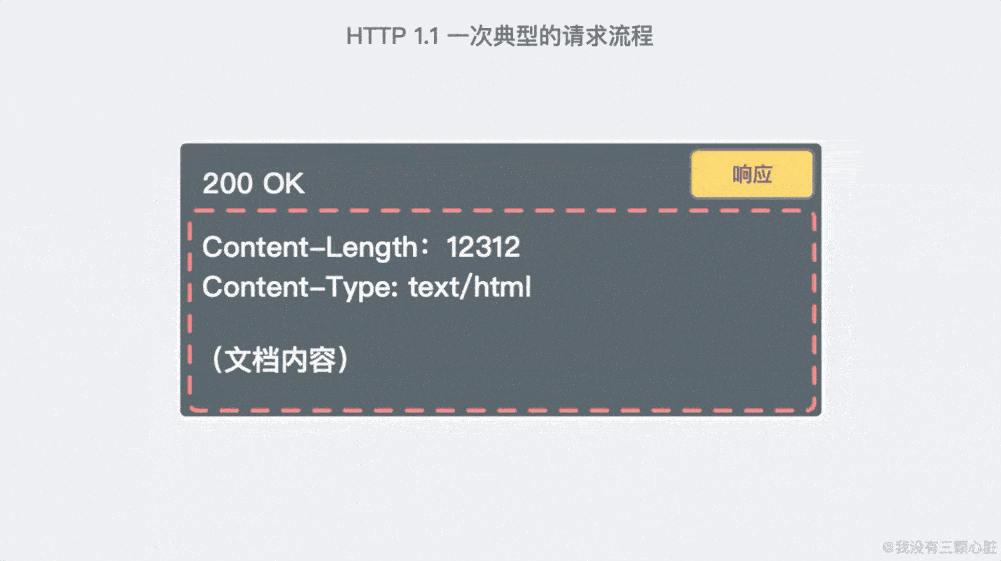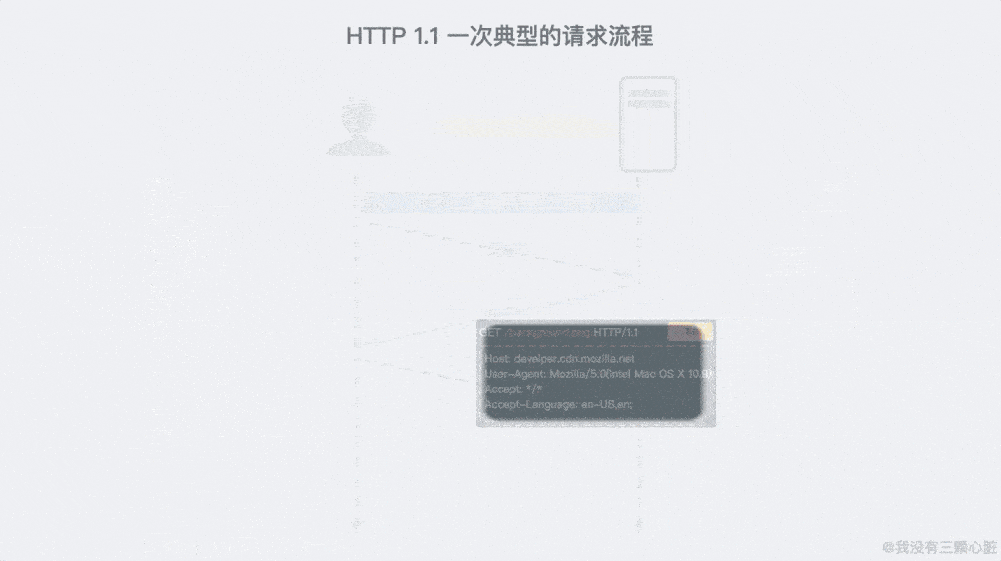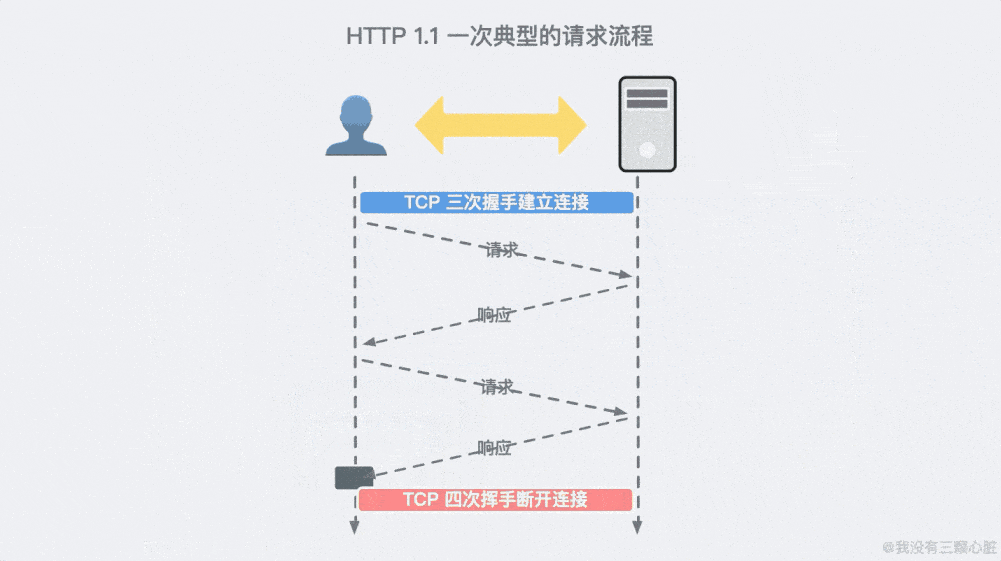
超過 15 年的擴展
由於 HTTP 的可擴展性——創建新的頭部和方法是很容易的——HTTP 協議穩定使用了超過 15 年。期間不斷對 HTTP/1.1 協議進行修訂(RFC 2616、RFC 7230、RFC 7235),為 HTTP/2.0 作了十足的鋪墊。
HTTP/2.0 – 為更優異的表現
這些年來,網頁愈漸變得複雜,甚至演變成了獨有的應用,可見媒體的播放量,增進交互的腳本大小也增加了許多:更多的數據通過 HTTP 請求被傳輸。
在 2010 年到 2015 年,Google通過實踐證明了實驗性的 SPDY 協議的可行性,這成為了後來 HTTP/2 協議的基礎。
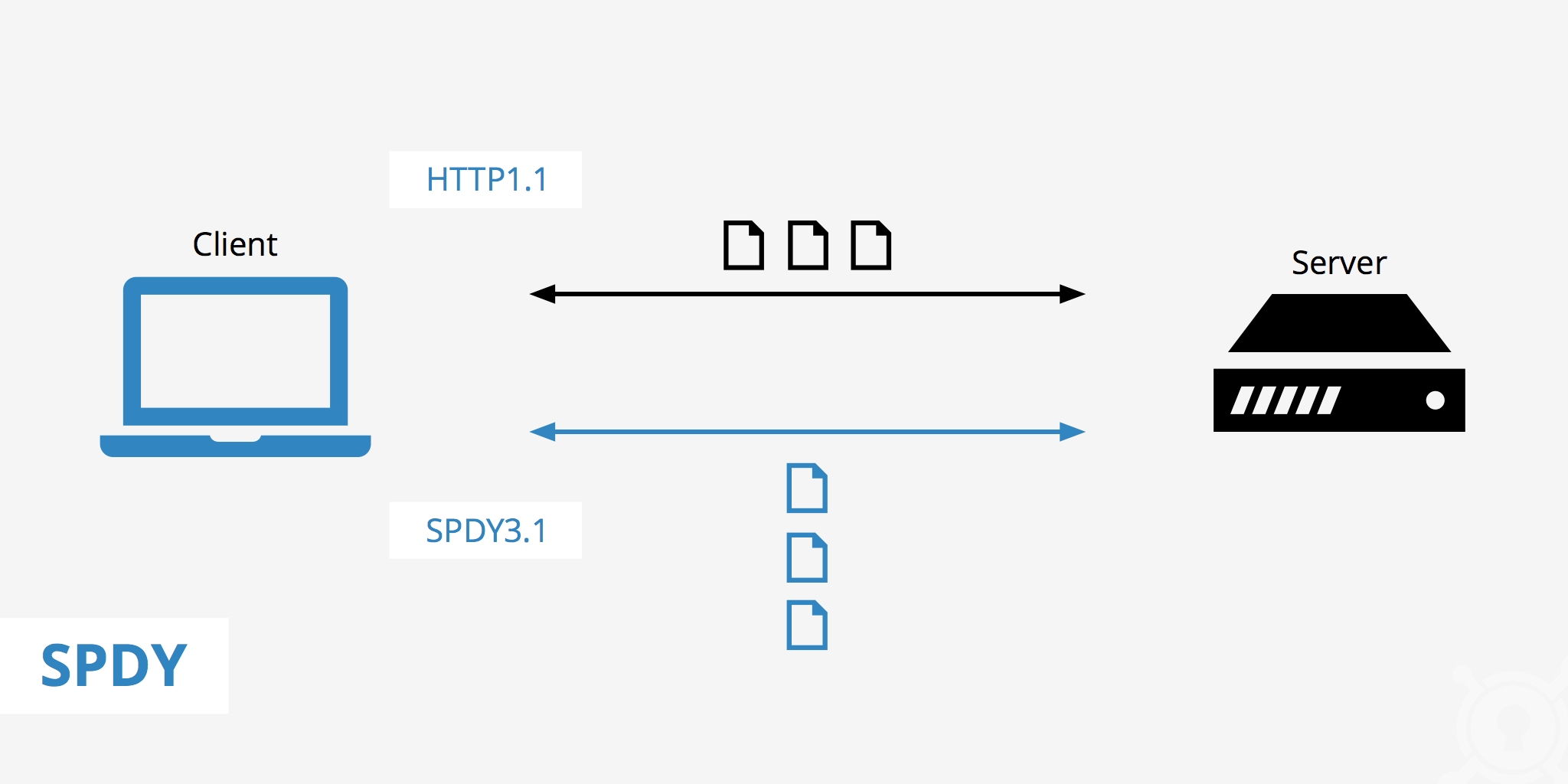
HTTP/2 在 HTTP/1.1 有幾處基本的不同:
- HTTP/2 是二進位協議而不是文本協議,不再可讀。頭資訊和數據體都是二進位(體積更小),並且統稱為幀(frame)。
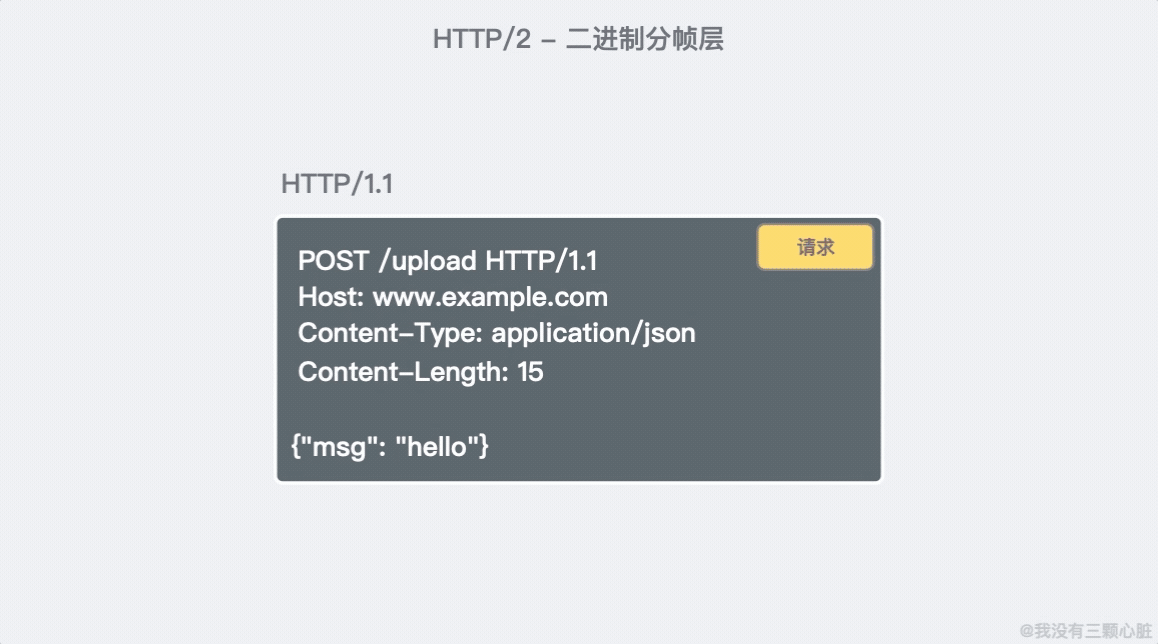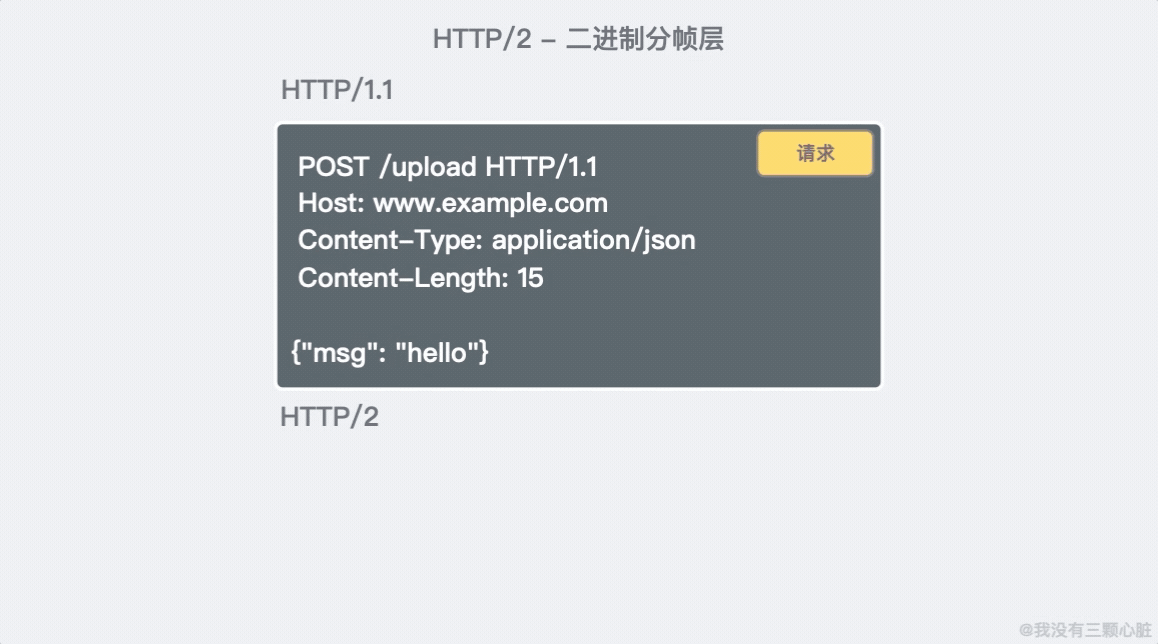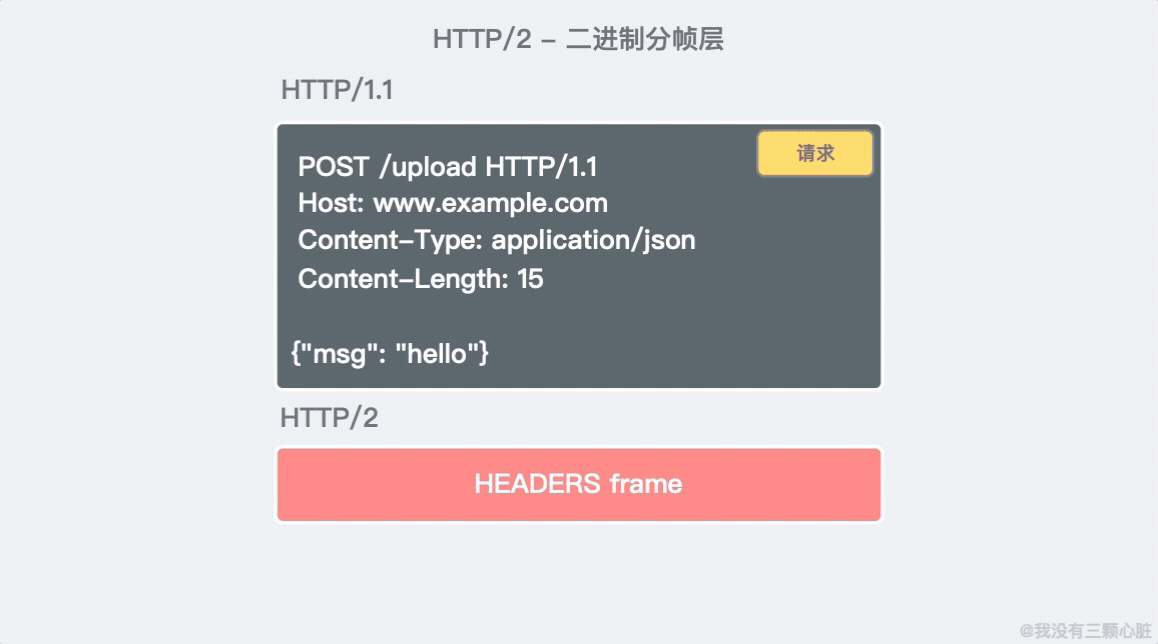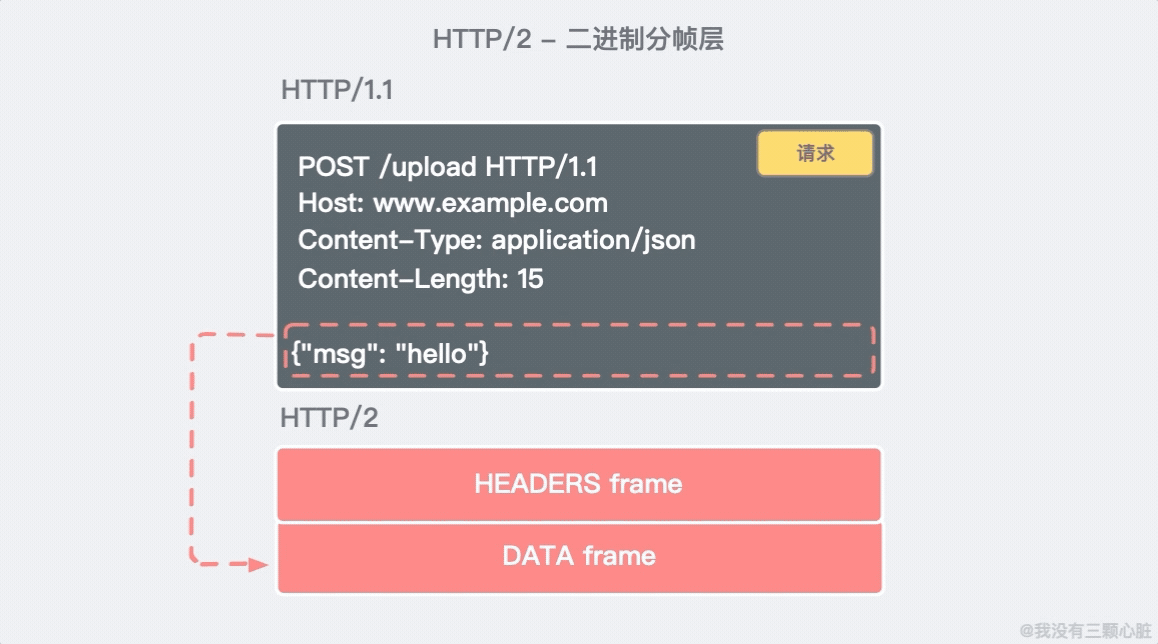
- 這是一個復用協議,可以多路復用。並行的請求能在同一個鏈接中處理,移除了 HTTP/1.x 中順序和阻塞的約束;

*註:這裡 HTTP/2 並不是合併成一個包,而是分成多個 Stream 發送,這裡只是為了繪畫方便。
大家可以通過點擊這裡直觀感受到 HTTP/2 比 HTTP/1.1 快了多少。
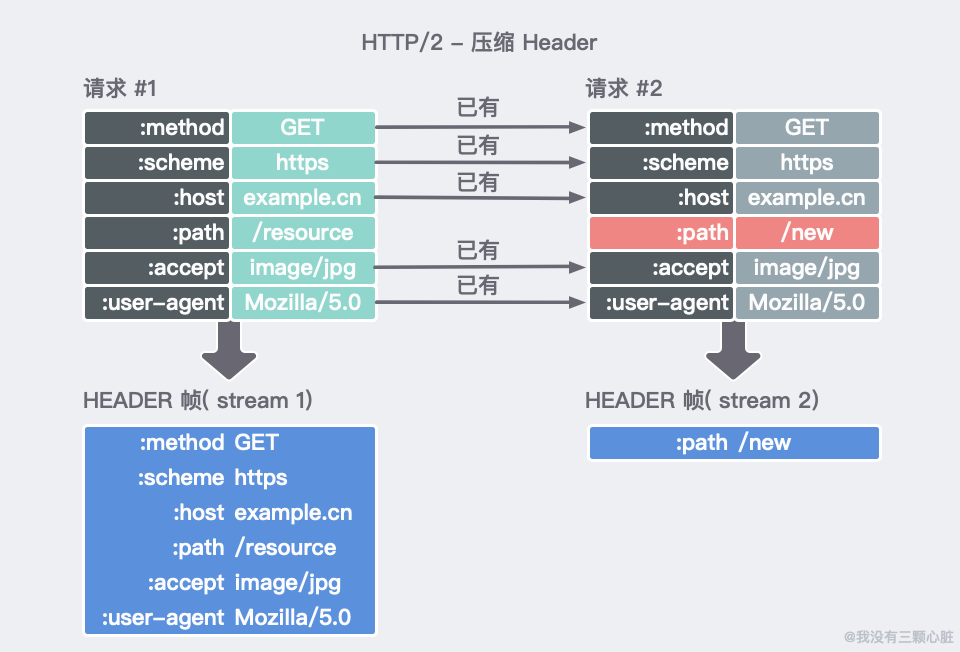
- 壓縮了 Headers。因為 Headers 在一系列請求中常常是相似的,其移除了重複和傳輸重複數據的成本。實現這一功能的演算法被稱為 HPACK 演算法;
- 其允許伺服器在客戶端快取中填充數據,通過一個叫伺服器推送的機制來提前請求;
詳細的 HTTP/2 優秀的地方可以參看下 4 鏈接
在 2015 年 5 月正式標準化後,HTTP/2 取得了極大的成功,在 2016 年 7 月前,8.7% 的站點已經在使用它。高流量的站點最迅速普及,在數據傳輸上節省了可觀的成本和支出。
這種迅速的普及率很可能是因為 HTTP2 不需要站點和應用做出改變:使用 HTTP/1.1 和 HTTP/2 對他們來說是透明的。
擁有一個最新的伺服器和新點的瀏覽器進行交互就足夠了。只有一小部分群體需要做出改變,而且隨著陳舊的瀏覽器和伺服器的更新,而不需 Web 開發者做什麼,用的人自然就增加了。
後 HTTP/2 進化
隨著 HTTP/2 的發布,就像先前的 HTTP/1.x 一樣,HTTP 沒有停止進化。HTTP 的擴展性依然被用來添加新的功能。
HTTP 的進化證實了它良好的擴展性和簡易性,釋放了很多應用程式的創造力並且情願使用這個協議。
HTTP/3 – 更好的未來
HTTP/3 是即將到來的第三個主要版本的 HTTP 協議。與前任協議不同,在 HTTP/3 中,將棄用 TCP 協議,改為使用 UDP 協議和 QUIC 協議實現。
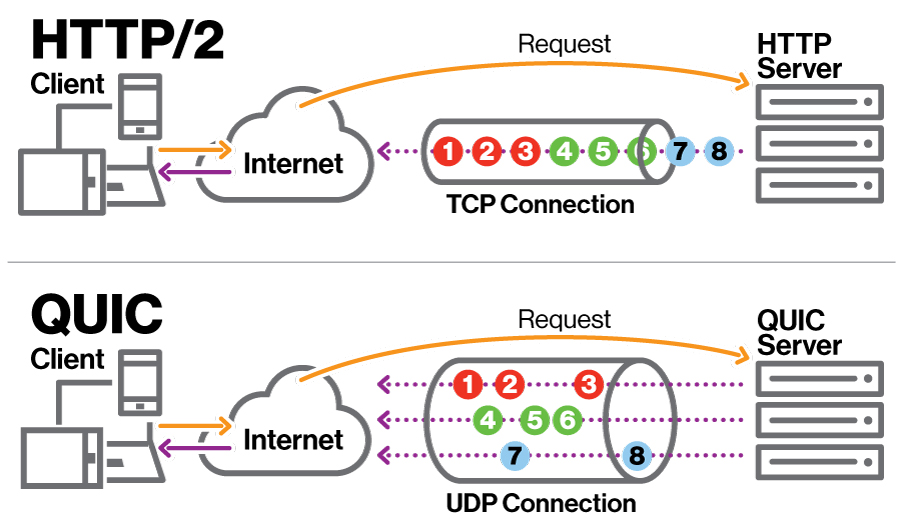
此變化主要為了解決 HTTP/2 中存在的隊頭阻塞問題。由於 HTTP/2 在單個 TCP 連接上使用了多路復用,受到 TCP 擁塞控制的影響,少量的丟包就可能導致整個 TCP 連接上的所有流被阻塞。
截至 2021 年 1 月,HTTP/3 仍然是草案狀態。
小結
- HTTP/0.9 只能傳輸單一的 HTML 純文本,不夠靈活;
- HTTP/1.x 有連接無法復用、隊頭阻塞、協議開銷大和安全因素等多個缺陷;
- HTTP/2 通過多路復用、二進位流、Header 壓縮等等技術,極大地提高了性能,但是還是存在著問題的;
- QUIC 基於 UDP 實現,是 HTTP/3 中的底層支撐協議,該協議基於 UDP,又取了 TCP 中的精華,實現了即快又可靠的協議;
Part 3. HTTP 與 HTTPS

為什麼需要 HTTPS
HTTP 協議在設計之初就沒有充分考慮安全性的問題。所以基於 HTTP 的這些應用都承擔著如下的幾個風險:
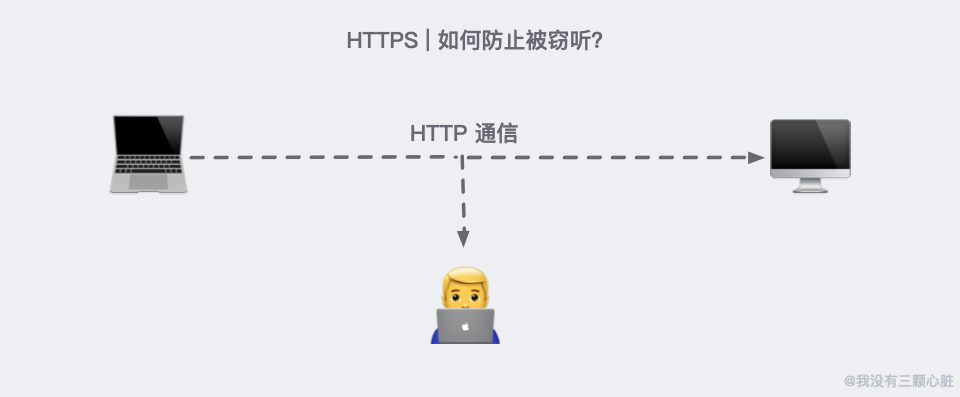
- 使用明文(不加密)進行通訊,內容可能會被竊聽;
- 不驗證通訊方的身份,通訊方的身份有可能是偽裝的;
- 無法驗證資訊的完整性,也就是說資訊可能是被篡改過的;
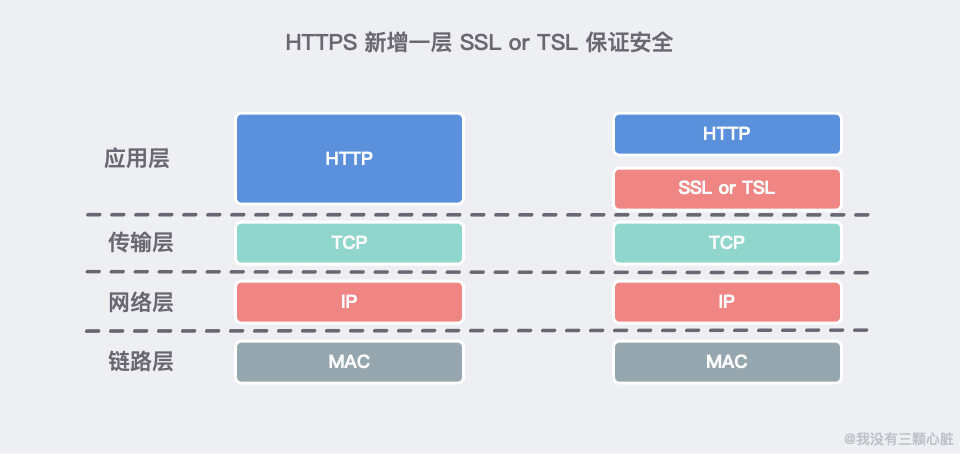
HTTPS(HTTP over SSL)採取嵌套新一層安全套接字層(Secure Socket Layer,SSL)來解決網路傳輸的安全性問題。
如何防止被竊聽?
加密是很容易聯想到的解決方法。但如何保證傳輸加密方法的過程不被竊聽呢?
這時候非對稱加密的出現解決了這一大難題。它把密碼革命性地分成公鑰和私鑰,由於兩個秘鑰並不相同,所以稱為非對稱加密。
舉個例子,假設我們現在需要加密的字元是 520,我們加密的方法是把這個數乘以 91,並把結果的最後三位公布出來:
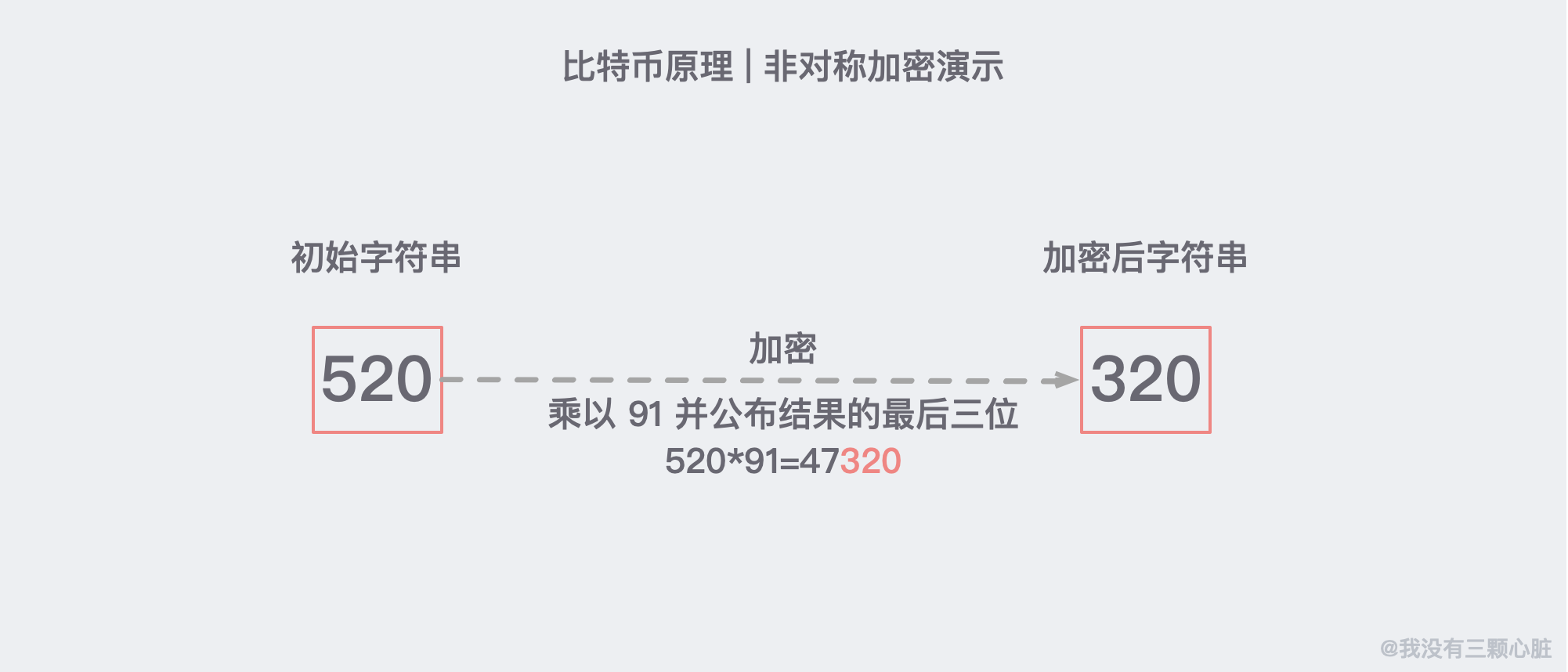
註:這裡的 91 相當於公鑰,任何人都可以知道。
解密我們當然不能通過除以 91 來完成,而是通過 x11,取出結果後三位來還原:
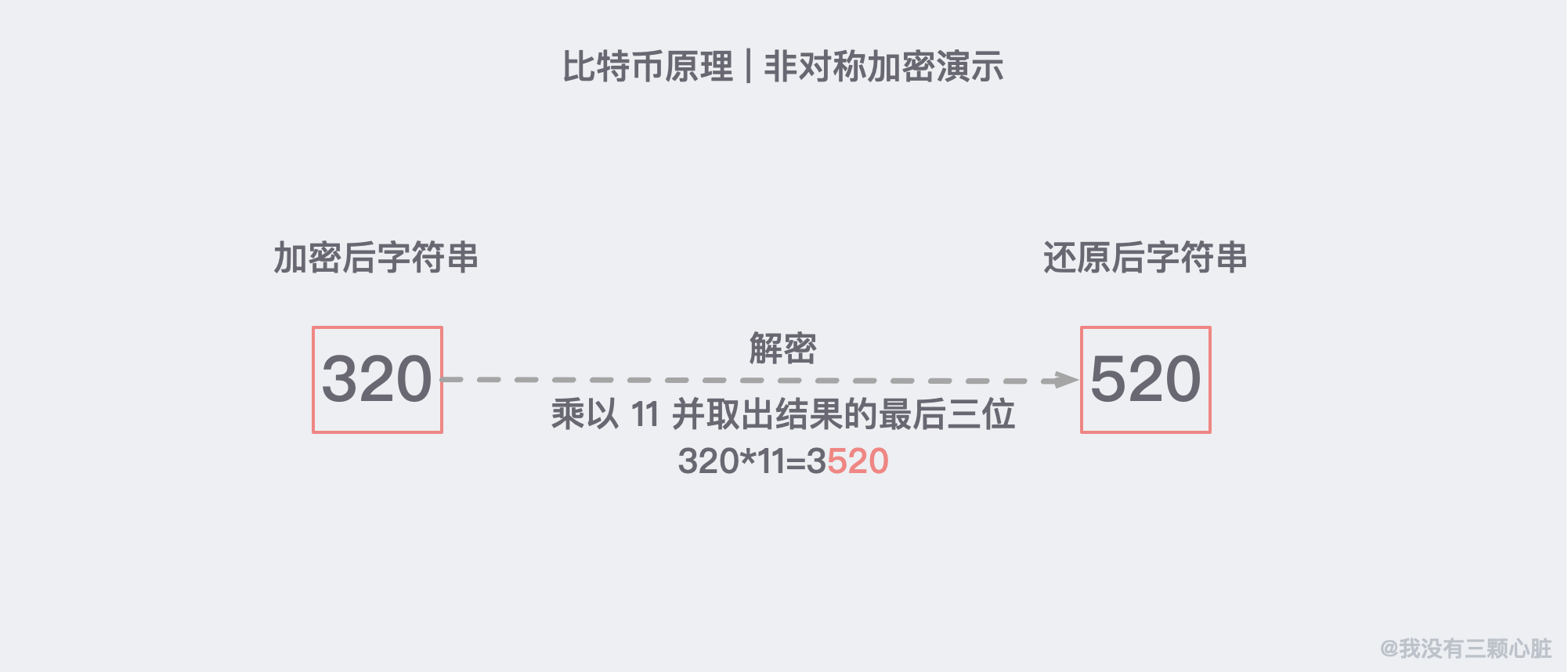
註:這裡的 x11 相當於私鑰,只有解密方才知道。
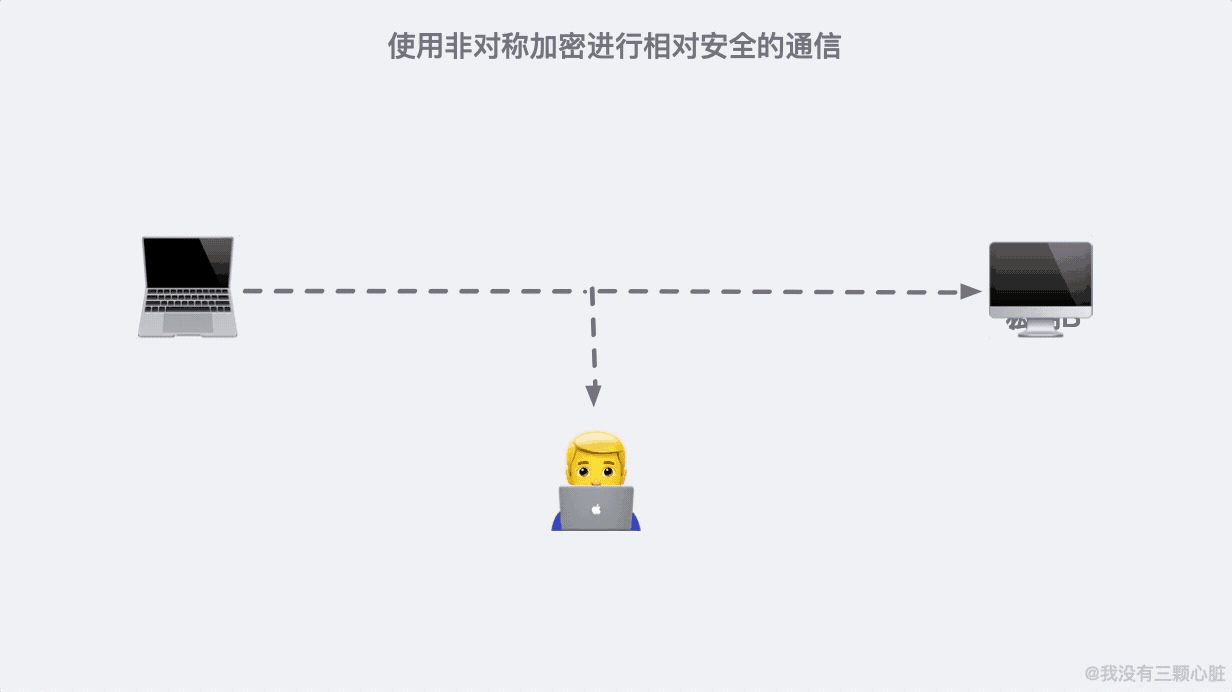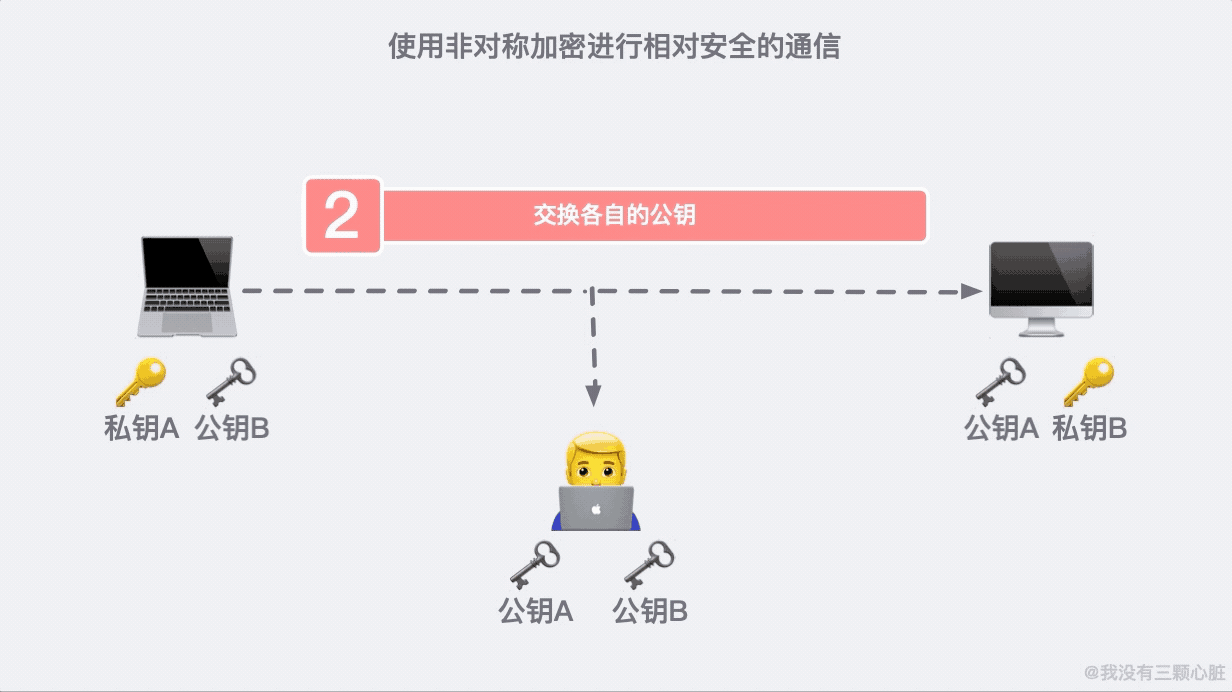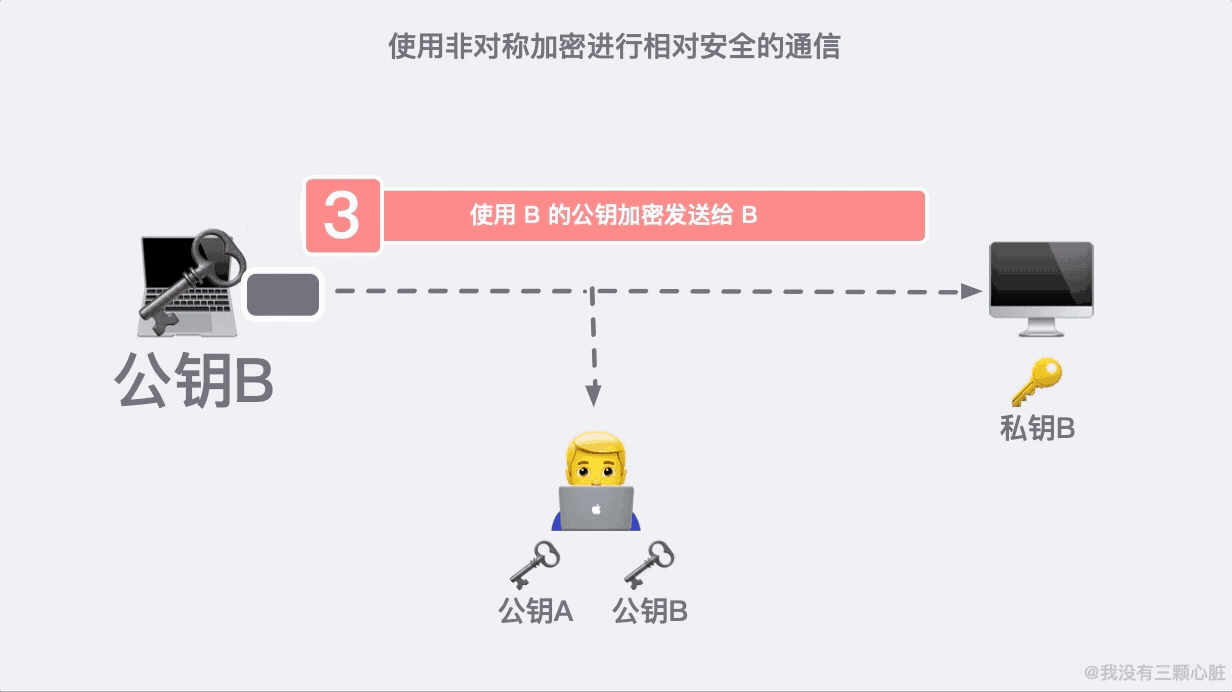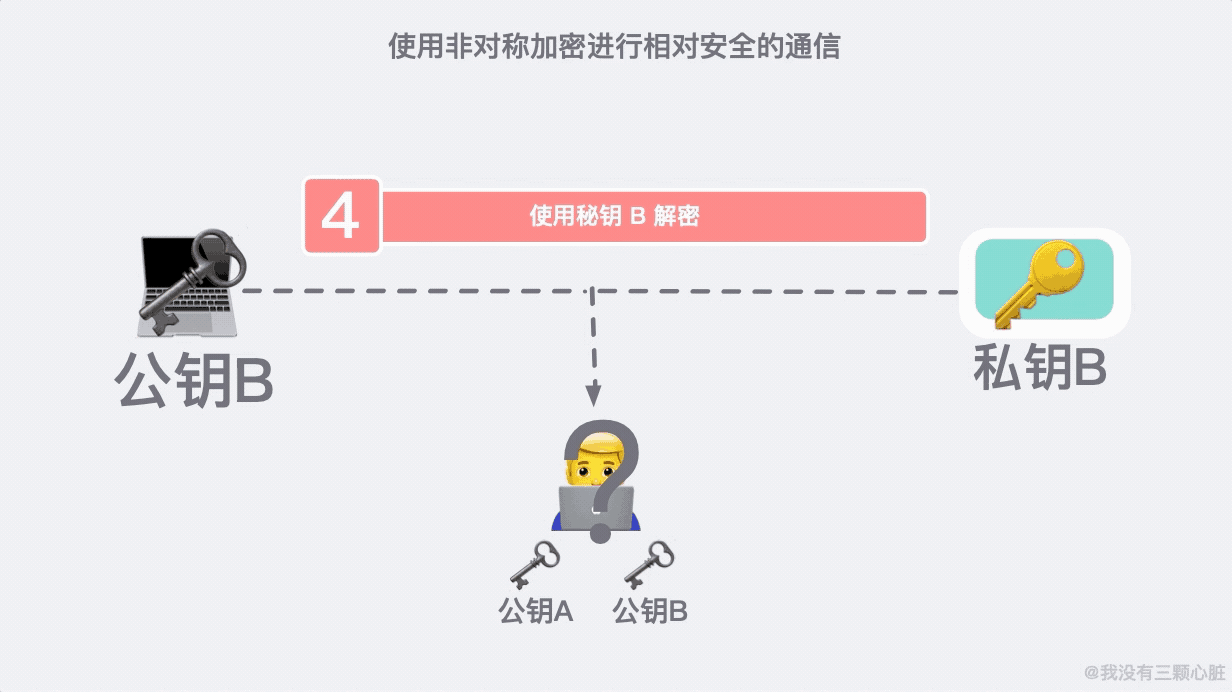
這是因為 91*11=1001,任何一個三位數乘以 1001 顯然後三位是不會變的。這大概就是非對稱加密的原理了,基於這個原理我們通訊的雙方就可以各自生成自己的公鑰私鑰並進行相對安全的通訊了。
如何驗證對方身份?
上面的過程看似無懈可擊,但在 TCP/IP 的端到端的通訊里,路途遙遠,夜長夢多。
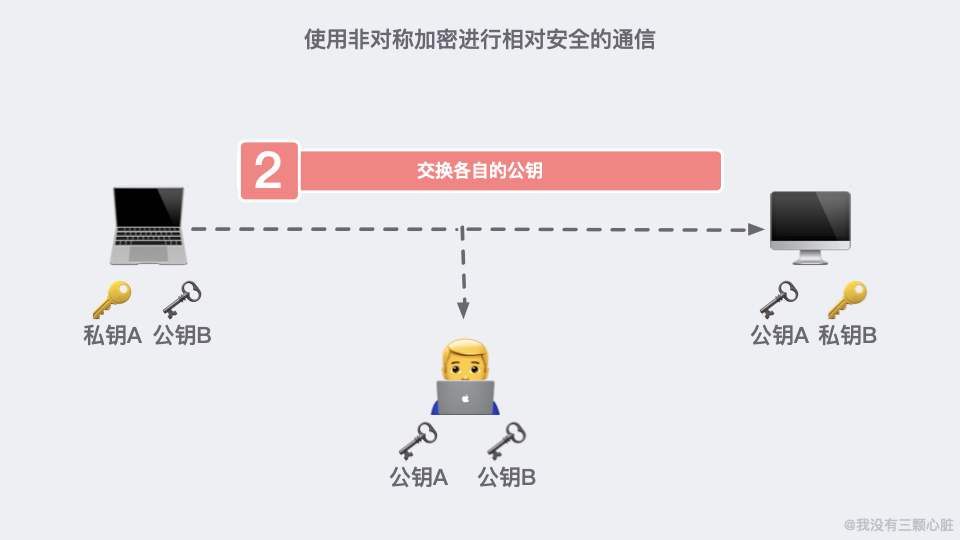
如果在第二步的時候,資訊被黑客截取,在嚴刑拷打之下知道了這是傳輸公鑰的資訊。那麼完全可以自己生成一對密鑰和公鑰,冒充是彼此來傳輸自己的秘鑰。
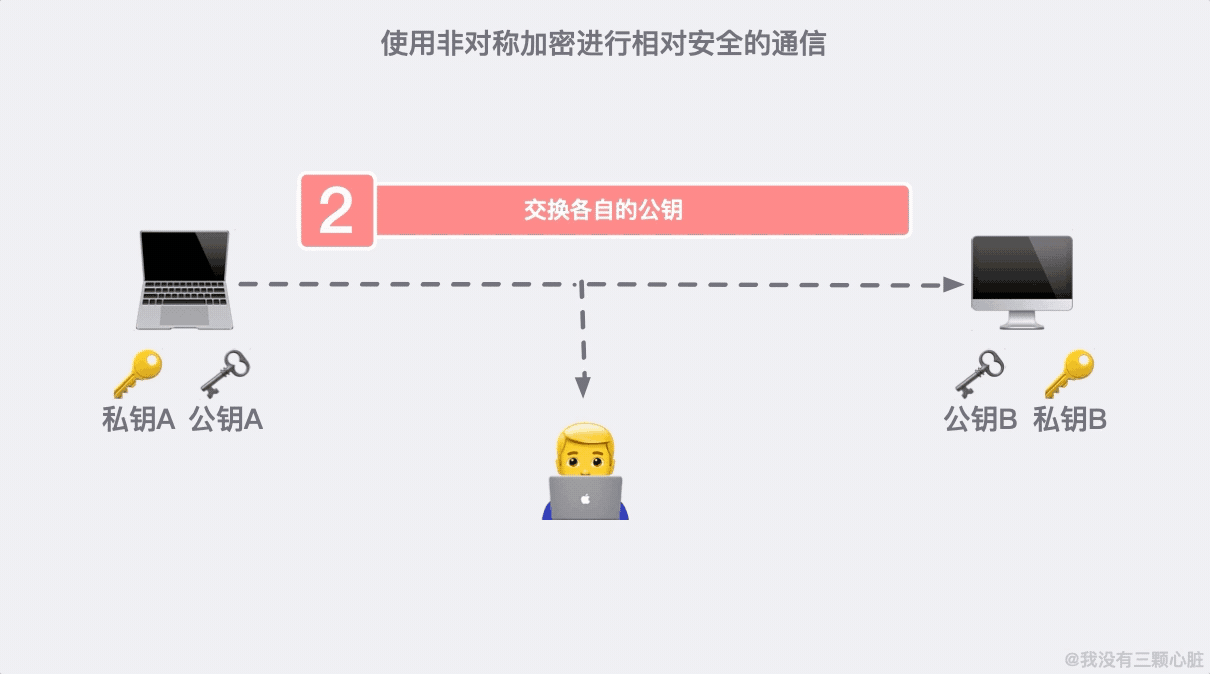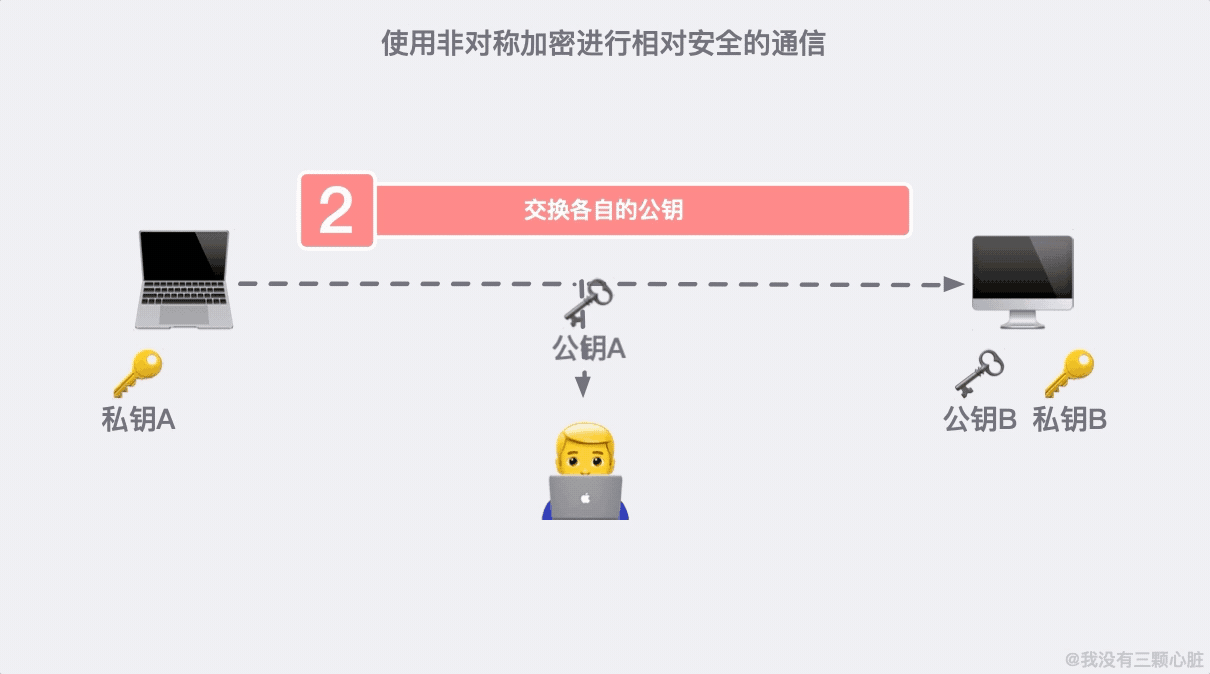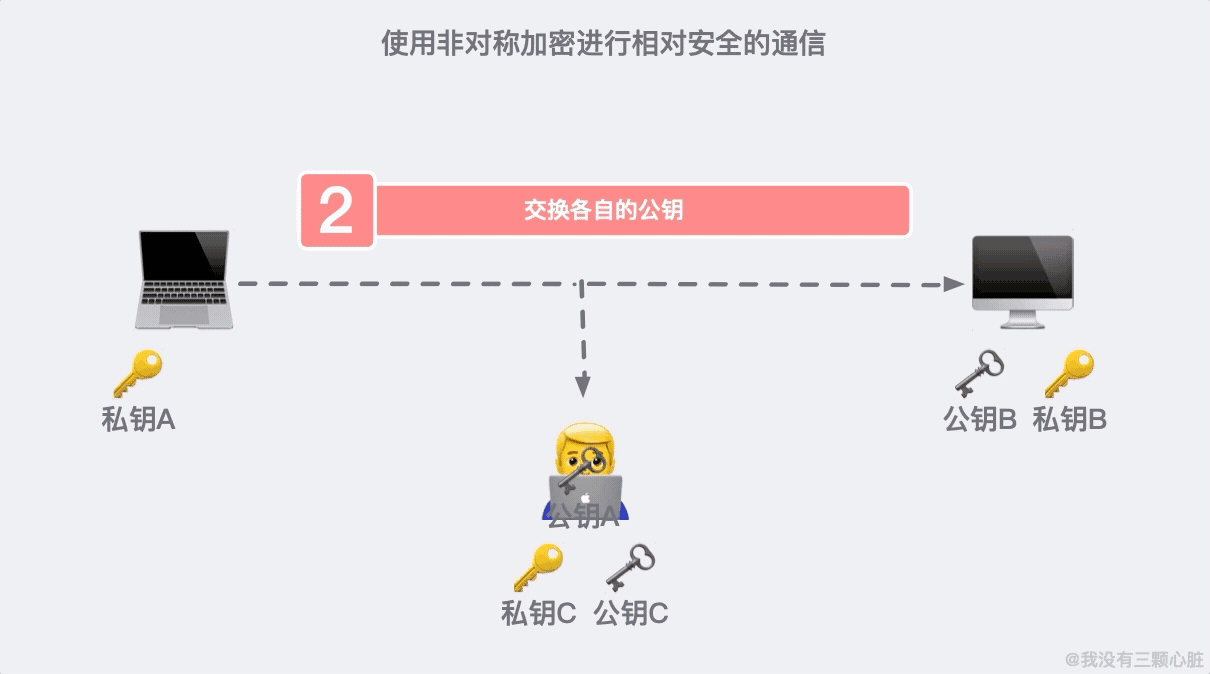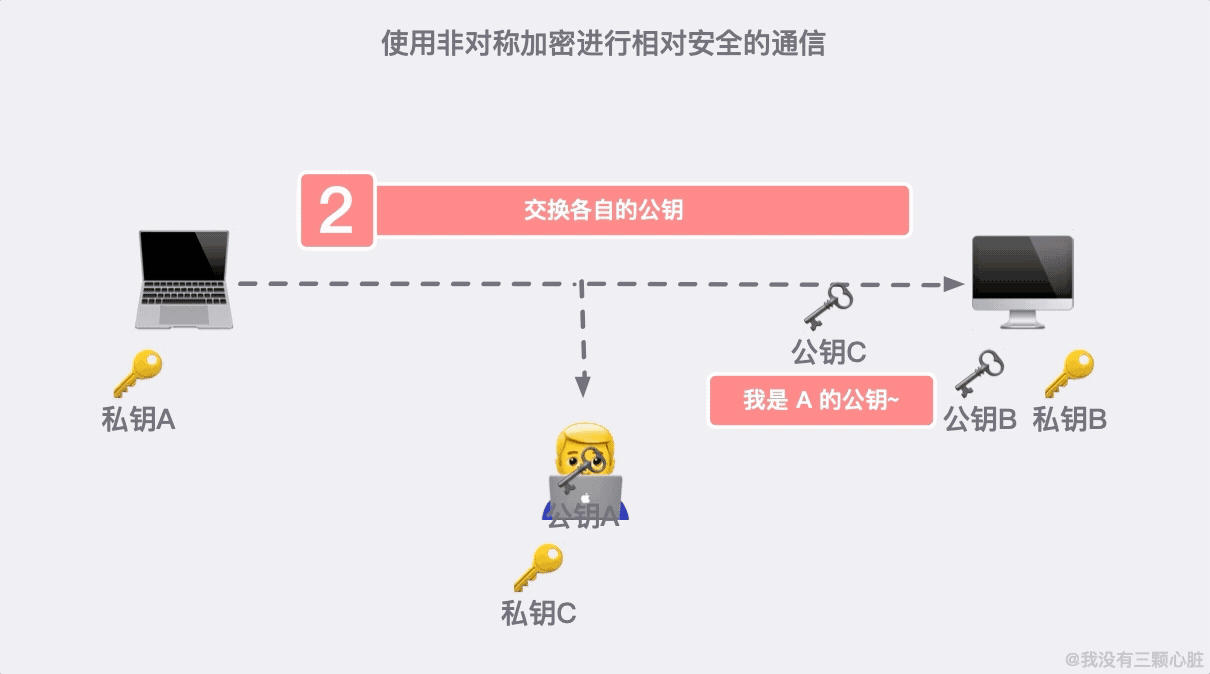
加密危機之後,又產生了信任危機。我們需要一個有公信力的組織來證明身份,這個問題就得到了解決。
這個可信的組織就是頒發 HTTPS 證書的組織 CA(Certificate Authority)。每次有客戶端或者服務端想要公開自己的公鑰時,都需要向 CA 做出申請,通過後 CA 會頒發一個與公開公鑰綁定的數字證書。(了解更多證書)

進行 HTTPS 通訊時,伺服器會把證書發送給客戶端,客戶端取得其中的公開密鑰之後,先進行驗證,如果驗證通過,就可以開始通訊。
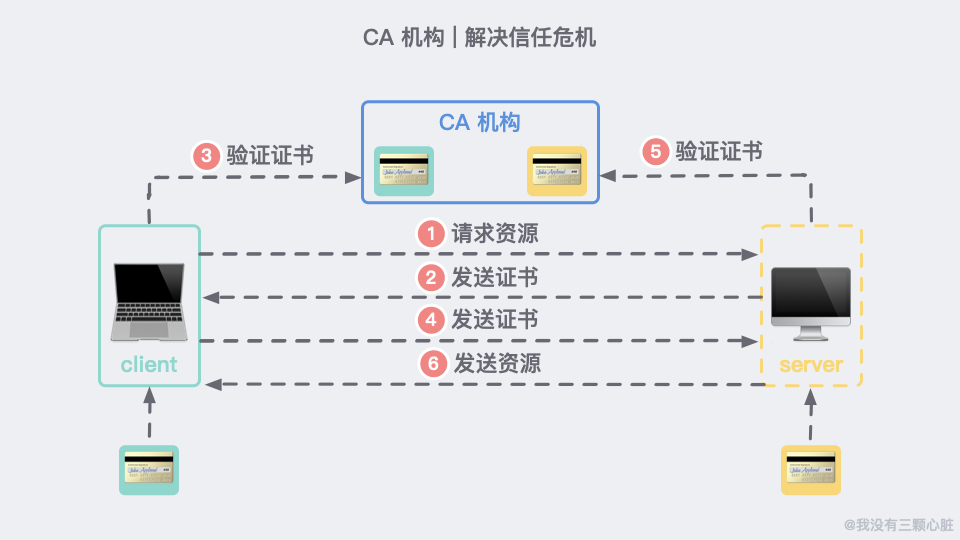
如何防止被篡改?
在之前介紹比特幣原理的時候,我們提到過一種哈希演算法。它的作用是能把任意長度的輸入編程固定長度的二進位輸出。
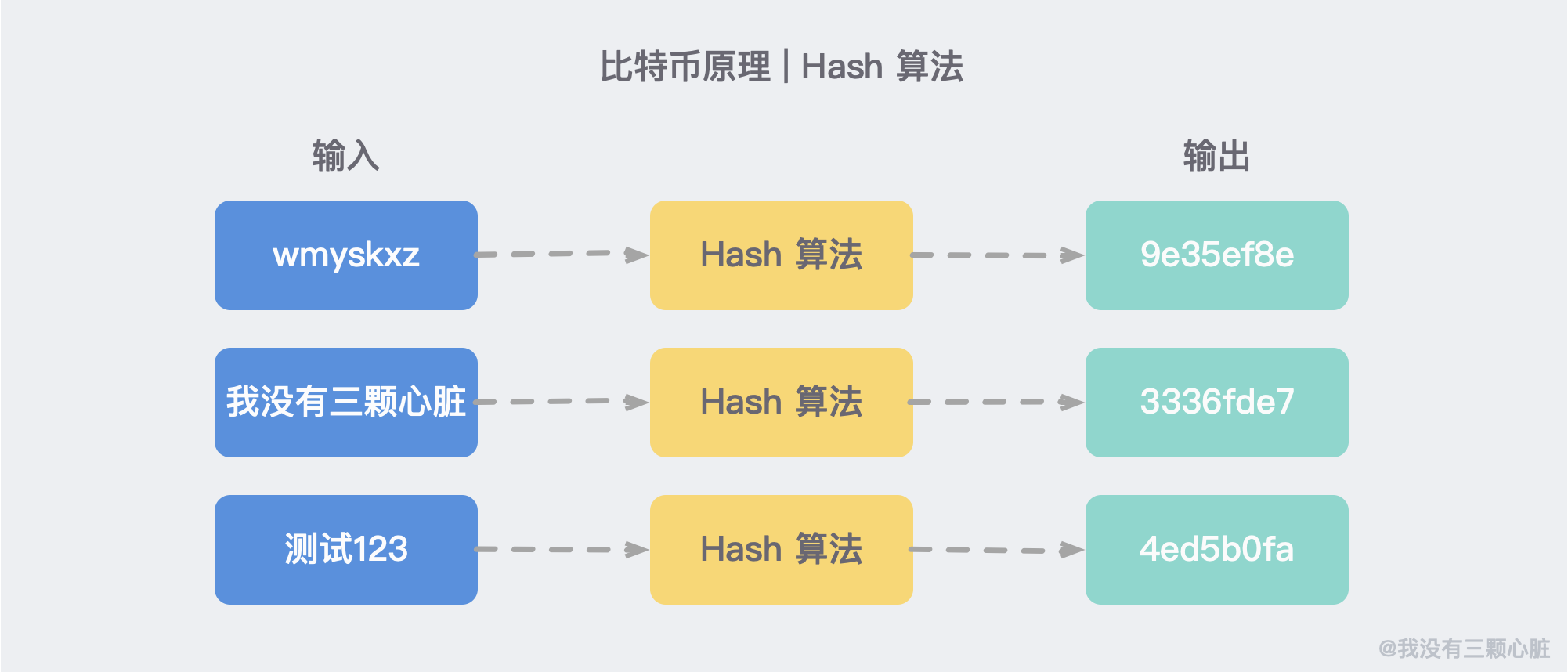
註:為了簡化右邊為 16 進位數
在 HTTPS 中,有一種新的摘要演算法,可以簡單理解為是對於內容的一種壓縮。所以但凡內容變化一丁點,哪怕是一個標點符號,壓縮之後的數字哈希也不對。
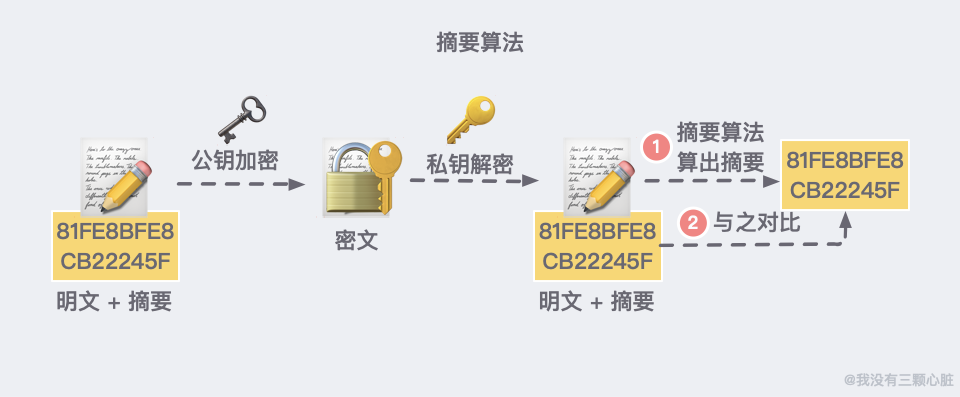
客戶端在發送明文之前會通過摘要演算法算出明文的 「指紋」,發送的時候把 「指紋 + 明文」 一同加密成密文後,發送給伺服器。
伺服器解密後,用相同的摘要演算法算出發送過來的明文,通過比較客戶端攜帶的 「指紋」 和當前算出的 「指紋」 做比較,若 「指紋」 相同,說明數據是完整的。
HTTP 與 HTTPS 有什麼不同?
儘管聽上去 HTTPS 就是更安全的 HTTP,但也有許多細節方面的不同:
- HTTP 明文傳輸,存在安全風險的問題。HTTPS 則解決 HTTP 不安全的缺陷,在 TCP 和 HTTP 網路層之間加入了 SSL/TLS 安全協議,使得報文能夠加密傳輸;
- HTTP 連接建立相對簡單, TCP 三次握手之後便可進行 HTTP 的報文傳輸。而 HTTPS 在 TCP 三次握手之後,還需進行 SSL/TLS 的握手過程,才可進入加密報文傳輸;
- HTTP 的埠號是 80,HTTPS 的埠號是 443;
- HTTPS 協議需要向 CA(證書權威機構)申請數字證書,來保證伺服器的身份是可信的;
後記
HTTP 協議是紛繁複雜的網路世界的基礎,它保證了各個應用之間的”交流無阻礙”。本篇也儘可能使用動圖的形式清晰地表達,希望大家能用餐愉快。

至此,我們對 HTTP 協議已經有了相當的了解了。後續也會繼續跟大家一起學習電腦網路的基礎知識,也會嘗試著跟著後端學習路線圖的腳步跟著大家一起學習進階。
參考資料
- How HTTP Works and Why it’s Important – Explained in Plain English – //www.freecodecamp.org/news/how-the-internet-works/
- Evolution of HTTP – //developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
- The Evolution of HTTP – //www.oreilly.com/library/view/learning-http2/9781491962435/ch01.html
- xxxxHub 都用上了 HTTP/2 ,它牛逼在哪? | 小林Coding – //mp.weixin.qq.com/s/TvGAmKKrKrcWlsV2cfC34g
- 一文讀懂 HTTP/2 及 HTTP/3 特性 – //blog.fundebug.com/2019/03/07/understand-http2-and-http3/
(完)
精彩推薦
這裡是我沒有三顆心臟,歡迎關注公眾號 wmyskxz,正在每周分享一周的學習和收穫,2021,與您在 Be Better 的路上共同成長!


