python進階(9)多執行緒
什麼是執行緒?
執行緒也叫輕量級進程,是作業系統能夠進行運算調度的最小單位,它被包涵在進程之中,是進程中的實際運作單位。執行緒自己不擁有系統資源,只擁有一點兒在運行中必不可少的資源,但它可與同屬一個進程的其他執行緒共享進程所擁有的全部資源。一個執行緒可以創建和撤銷另一個執行緒,同一個進程中的多個執行緒之間可以並發執行
為什麼要使用多執行緒?
執行緒在程式中是獨立的、並發的執行流。與分隔的進程相比,進程中執行緒之間的隔離程度要小,它們共享記憶體、文件句柄 和其他進程應有的狀態。 因為執行緒的劃分尺度小於進程,使得多執行緒程式的並發性高。進程在執行過程之中擁有獨立的記憶體單元,而多個執行緒共享 記憶體,從而極大的提升了程式的運行效率。 執行緒比進程具有更高的性能,這是由於同一個進程中的執行緒都有共性,多個執行緒共享一個進程的虛擬空間。執行緒的共享環境包括進程程式碼段、進程的共有數據等,利用這些共享的數據,執行緒之間很容易實現通訊。 作業系統在創建進程時,必須為進程分配獨立的記憶體空間,並分配大量的相關資源,但創建執行緒則簡單得多。因此,使用多執行緒來實現並發比使用多進程的性能高得要多。
多執行緒優點
進程之間不能共享記憶體,但執行緒之間共享記憶體非常容易。作業系統在創建進程時,需要為該進程重新分配系統資源,但創建執行緒的代價則小得多。因此使用多執行緒來實現多任務並發執行比使用多進程的效率高 python語言內置了多執行緒功能支援,而不是單純地作為底層作業系統的調度方式,從而簡化了python的多執行緒編程。
單執行緒執行
import time
def hello():
print("你好,世界")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
hello()
運行結果
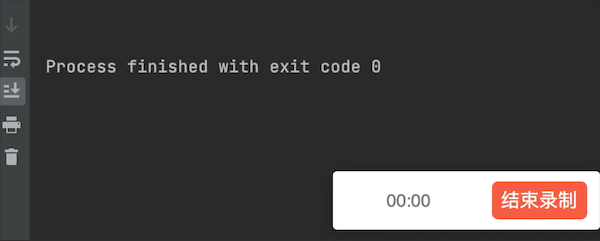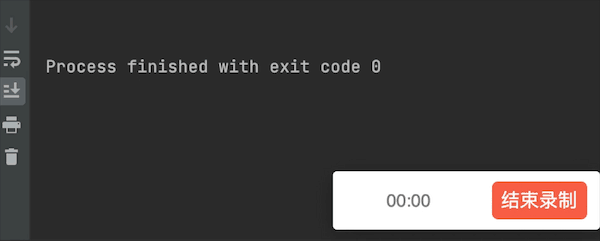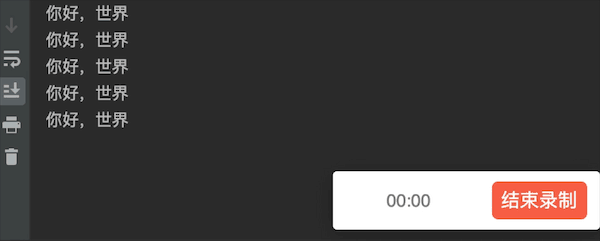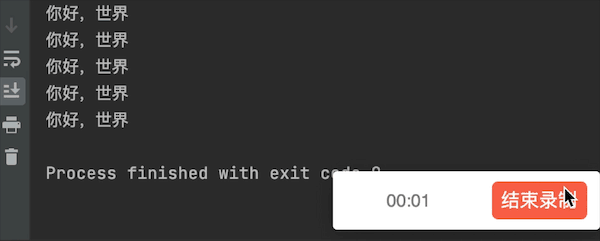
多執行緒執行
import threading
import time
def saySorry():
print("你好,世界")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=saySorry) # 創建執行緒對象,此時還未啟動子執行緒
t.start() # 啟動執行緒,即讓執行緒開始執行
運行結果
執行速度對比
- 可以明顯看出使用了多執行緒並發的操作,花費時間要短
- 當調用start()時,才會真正的創建執行緒,並且開始執行
函數式創建多執行緒
python中多執行緒使用threading模組,threading模組調用Thread類
self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None
- group:默認為None;預留給將來擴展ThreadGroup時使用類實現。不常用,可以忽略
- target:代表要執行的函數名,不是函數
- name:執行緒名,默認情況下的格式是”Thread-N”,其中N是一個小的十進位數
- args:函數的參數,以元組的形式表示
- kwargs:關鍵字參數字典
小例子
import threading
from time import sleep
from datetime import datetime
def write(name):
for i in range(3):
print("{}正在寫字{}".format(name, i))
sleep(1)
def draw(name):
for i in range(3):
print("{}正在畫畫{}".format(name, i))
sleep(1)
if __name__ == '__main__':
print(f'---開始---:{datetime.now()}')
t1 = threading.Thread(target=write, args=('Jack', ))
t2 = threading.Thread(target=draw, args=('Tom', ))
t1.start()
t2.start()
print(f'---結束---:{datetime.now()}')
查看執行緒數量threading.enumerate()
import threading
from datetime import datetime
from time import sleep
def write():
for i in range(3):
print(f"正在寫字...{i}")
sleep(1)
def draw():
for i in range(3):
print(f"正在畫畫...{i}")
sleep(1)
if __name__ == '__main__':
print(f'---開始---:{datetime.now()}')
t1 = threading.Thread(target=write)
t2 = threading.Thread(target=draw)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
print(f'當前運行的執行緒數為:{length}')
if length <= 1:
break
sleep(0.5)
結果
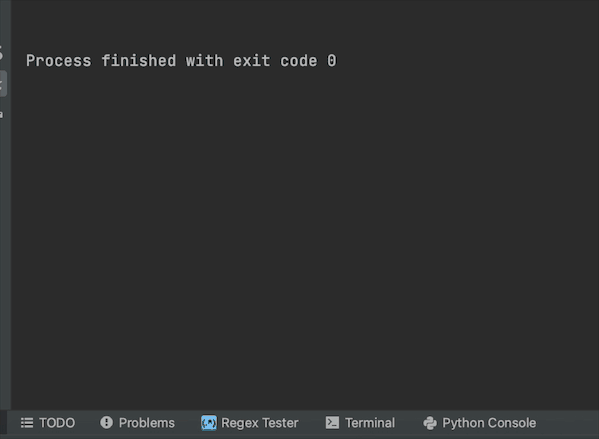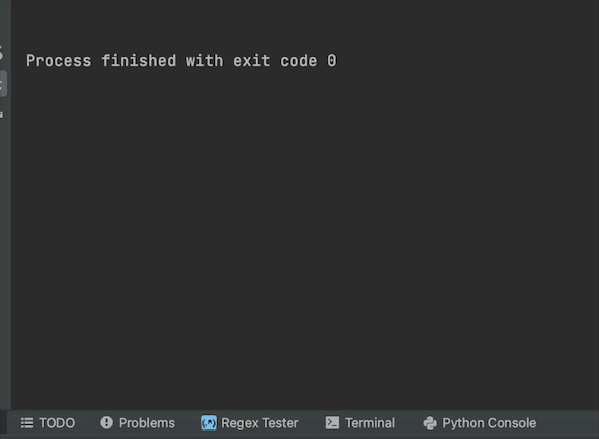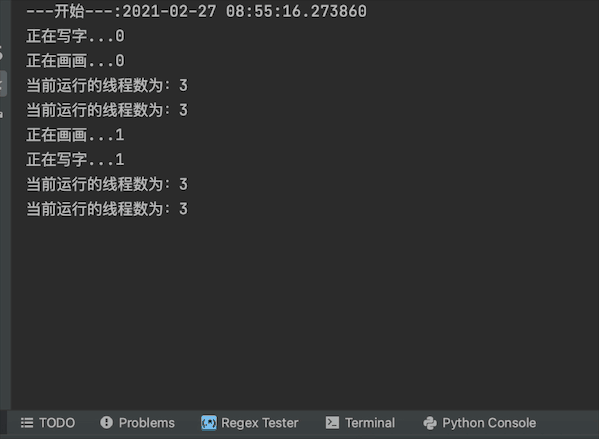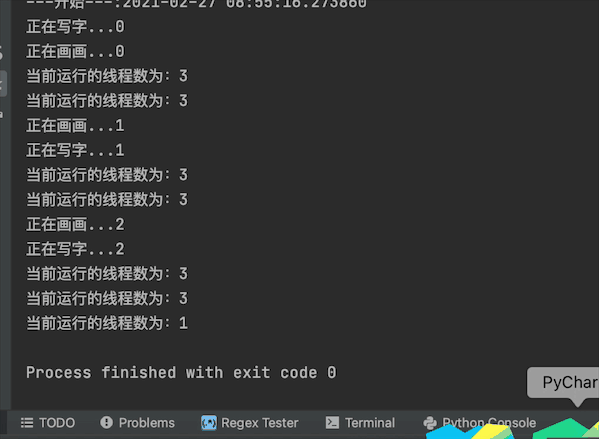
最開始列印執行緒數為3個,一個主執行緒+2個子執行緒t1,t2
最後列印執行緒數為1個,是因為子執行緒都結束了,就剩主執行緒了
自定義執行緒
繼承threading.Thread來定義執行緒類,其本質是重構Thread類中的run方法
為什麼執行run方法,就會啟動執行緒呢?之前寫函數時,調用的是start()方法
因為run方法里默認執行了start()方法
import threading
from time import sleep
class MyThread(threading.Thread):
def run(self):
for i in range(5):
sleep(1)
msg = "I'm " + self.name + ' @ ' + str(i) # name屬性中保存的是當前執行緒的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()
結果
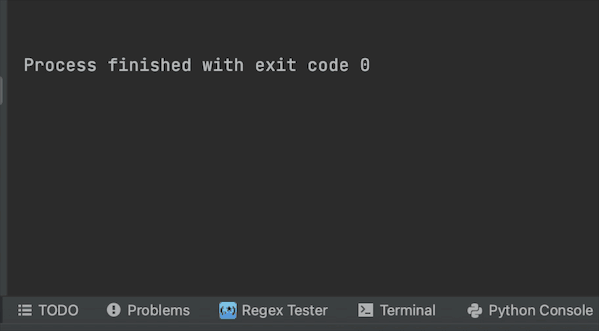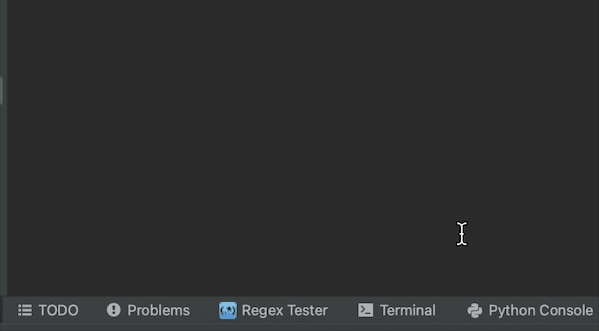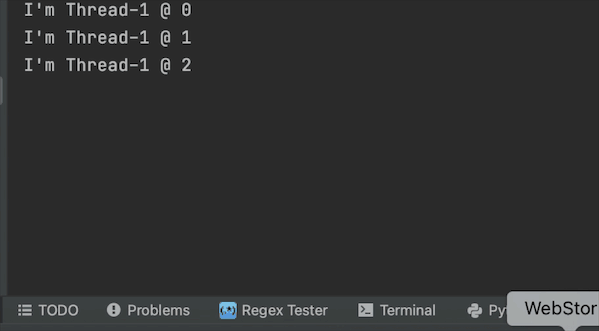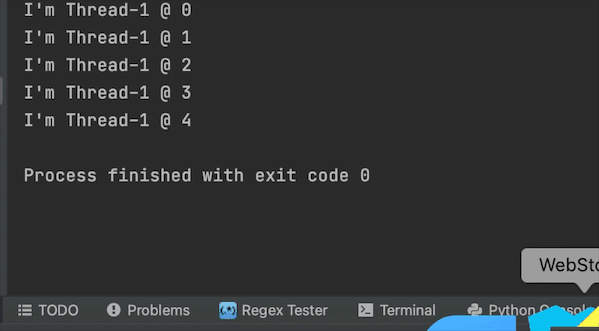
守護執行緒
'''
這裡使用setDaemon(True)把所有的子執行緒都變成了主執行緒的守護執行緒,
因此當主執行緒結束後,子執行緒也會隨之結束,所以當主執行緒結束後,整個程式就退出了。
所謂』執行緒守護』,就是主執行緒不管該執行緒的執行情況,只要是其他子執行緒結束且主執行緒執行完畢,主執行緒都會關閉。也就是說:主執行緒不等待該守護執行緒的執行完再去關閉。
'''
import threading
import time
def run(n):
print('task', n)
time.sleep(1)
print('3s')
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
if __name__ == '__main__':
t = threading.Thread(target=run, args=('t1',))
t.setDaemon(True)
t.start()
print('end')
結果
task t1
end
通過執行結果可以看出,設置守護執行緒之後,當主執行緒結束時,子執行緒也將立即結束,不再執行
主執行緒等待子執行緒結束(join)
為了讓守護執行緒執行結束之後,主執行緒再結束,我們可以使用join方法,讓主執行緒等待子執行緒執行
import threading
import time
def run(n):
print('task', n)
time.sleep(1)
print('3s')
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
if __name__ == '__main__':
t = threading.Thread(target=run, args=('t1',))
t.setDaemon(True) # 把子執行緒設置為守護執行緒,必須在start()之前設置
t.start()
t.join() # 設置主執行緒等待子執行緒結束
print('end')
結果
task t1
3s
2s
1s
end
執行緒共享變數
'''
多執行緒共享全局變數
執行緒時進程的執行單元,進程時系統分配資源的最小執行單位,所以在同一個進程中的多執行緒是共享資源的
'''
import threading
import time
g_num = 0
def work1(num):
global g_num
for i in range(num):
g_num += 1
print("----in work1, g_num is %d---"%g_num)
def work2(num):
global g_num
for i in range(num):
g_num += 1
print("----in work2, g_num is %d---"%g_num)
print("---執行緒創建之前g_num is %d---"%g_num)
t1 = threading.Thread(target=work1, args=(1000000,))
t1.start()
t2 = threading.Thread(target=work2, args=(1000000,))
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2個執行緒對同一個全局變數操作之後的最終結果是:%s" % g_num)
結果
---執行緒創建之前g_num is 0---
----in work2, g_num is 1451293---
----in work1, g_num is 1428085---
2個執行緒對同一個全局變數操作之後的最終結果是:1428085
先來看結果,為什麼不是200000呢?
原因是多執行緒共用同一個變數,可能會出現資源競爭的問題,導致數據不準確,那有什麼解決辦法嗎?下面介紹互斥鎖
互斥鎖
由於執行緒之間是進行隨機調度,並且每個執行緒可能只執行n條執行之後,當多個執行緒同時修改同一條數據時可能會出現臟數據,所以出現了執行緒鎖,即同一時刻允許一個執行緒執行操作。執行緒鎖用於鎖定資源,可以定義多個鎖,像下面的程式碼,當需要獨佔 某一個資源時,任何一個鎖都可以鎖定這個資源,就好比你用不同的鎖都可以把這個相同的門鎖住一樣。
由於執行緒之間是進行隨機調度的,如果有多個執行緒同時操作一個對象,如果沒有很好地保護該對象,會造成程式結果的不可預期,我們因此也稱為執行緒不安全。
為了防止上面情況的發生,就出現了互斥鎖(Lock)
import threading
import time
g_num = 0
# 創建一個互斥鎖
# 默認是未上鎖的狀態
lock = threading.Lock()
def test1(num):
global g_num
for i in range(num):
lock.acquire() # 上鎖
g_num += 1
lock.release() # 解鎖
print("---test1---g_num=%d"%g_num)
def test2(num):
global g_num
for i in range(num):
lock.acquire() # 上鎖
g_num += 1
lock.release() # 解鎖
print("---test2---g_num=%d"%g_num)
# 創建2個執行緒,讓他們各自對g_num加1000000次
p1 = threading.Thread(target=test1, args=(1000000,))
p1.start()
p2 = threading.Thread(target=test2, args=(1000000,))
p2.start()
# 等待計算完成
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2個執行緒對同一個全局變數操作之後的最終結果是:%s" % g_num)
結果
---test2---g_num=1961182
---test1---g_num=2000000
2個執行緒對同一個全局變數操作之後的最終結果是:2000000
上鎖解鎖過程
當一個執行緒調用鎖的acquire()方法獲得鎖時,鎖就進入locked狀態。 每次只有一個執行緒可以獲得鎖。如果此時另一個執行緒試圖獲得這個鎖,該執行緒就會變為blocked狀態,稱為「阻塞」,直到擁有鎖的執行緒調用鎖的release()方法釋放鎖之後,鎖進入unlocked狀態。 執行緒調度程式從處於同步阻塞狀態的執行緒中選擇一個來獲得鎖,並使得該執行緒進入運行(running)狀態。
鎖的好處
- 確保了某段關鍵程式碼只能由一個執行緒從頭到尾完整地執行
鎖的壞處
- 阻止了多執行緒
並發執行,包含鎖的某段程式碼實際上只能以單執行緒模式執行,效率就大大地下降了 - 由於可以存在多個鎖,不同的執行緒持有不同的鎖,並試圖獲取對方持有的鎖時,可能會造成
死鎖
GIL全局解釋器
在非python環境中,單核情況下,同時只能有一個任務執行。多核時可以支援多個執行緒同時執行。但是在python中,無論有多少個核同時只能執行一個執行緒。究其原因,這就是由於GIL的存在導致的。
GIL的全程是全局解釋器,來源是python設計之初的考慮,為了數據安全所做的決定。某個執行緒想要執行,必須先拿到GIL,我們可以把GIL看做是「通行證」,並且在一個python進程之中,GIL只有一個。拿不到執行緒的通行證,並且在一個python進程中,GIL只有一個,拿不到通行證的執行緒,就不允許進入CPU執行。GIL只在cpython中才有,因為cpython調用的是c語言的原生執行緒,所以他不能直接操作cpu,而只能利用GIL保證同一時間只能有一個執行緒拿到數據。而在pypy和jpython中是沒有GIL的
python在使用多執行緒的時候,調用的是c語言的原生過程。
python針對不同類型的程式碼執行效率也是不同的
CPU密集型程式碼(各種循環處理、計算等),在這種情況下,由於計算工作多,ticks技術很快就會達到閥值,然後出發GIL的 釋放與再競爭(多個執行緒來回切換當然是需要消耗資源的),所以python下的多執行緒對CPU密集型程式碼並不友好。
IO密集型程式碼(文件處理、網路爬蟲等設計文件讀寫操作),多執行緒能夠有效提升效率(單執行緒下有IO操作會進行IO等待, 造成不必要的時間浪費,而開啟多執行緒能在執行緒A等待時,自動切換到執行緒B,可以不浪費CPU的資源,從而能提升程式的執行 效率)。所以python的多執行緒對IO密集型程式碼比較友好。
主要要看任務的類型,我們把任務分為I/O密集型和計算密集型,而多執行緒在切換中又分為I/O切換和時間切換。如果任務屬於是I/O密集型,若不採用多執行緒,我們在進行I/O操作時,勢必要等待前面一個I/O任務完成後面的I/O任務才能進行,在這個等待的過程中,CPU處於等待狀態,這時如果採用多執行緒的話,剛好可以切換到進行另一個I/O任務。這樣就剛好可以充分利用CPU避免CPU處於閑置狀態,提高效率。但是,如果多執行緒任務都是計算型,CPU會一直在進行工作,直到一定的時間後採取多執行緒時間切換的方式進行切換執行緒,此時CPU一直處於工作狀態, 此種情況下並不能提高性能,相反在切換多執行緒任務時,可能還會造成時間和資源的浪費,導致效能下降。這就是造成上面兩種多執行緒結果不能的解釋。
結論:I/O密集型任務,建議採取多執行緒,還可以採用多進程+協程的方式(例如:爬蟲多採用多執行緒處理爬取的數據);對於計算密集型任務,python此時就不適用了。


